用10亿训练对训练一个句子嵌入模型


句子嵌入是一种将句子映射到实数向量的方法。理想情况下,这些向量能够捕捉句子的语义并具有高度通用性。这样的表示可以用于许多下游应用,例如聚类、文本挖掘或问答。
作为项目“用10亿训练对训练有史以来最好的句子嵌入模型”的一部分,我们开发了最先进的句子嵌入模型。该项目在Hugging Face组织的使用JAX/Flax进行NLP和CV社区周期间进行。我们得益于高效的硬件基础设施来运行项目:7个TPU v3-8,以及来自Google的Flax、JAX和Cloud团队成员关于高效深度学习框架的指导!
训练方法
模型
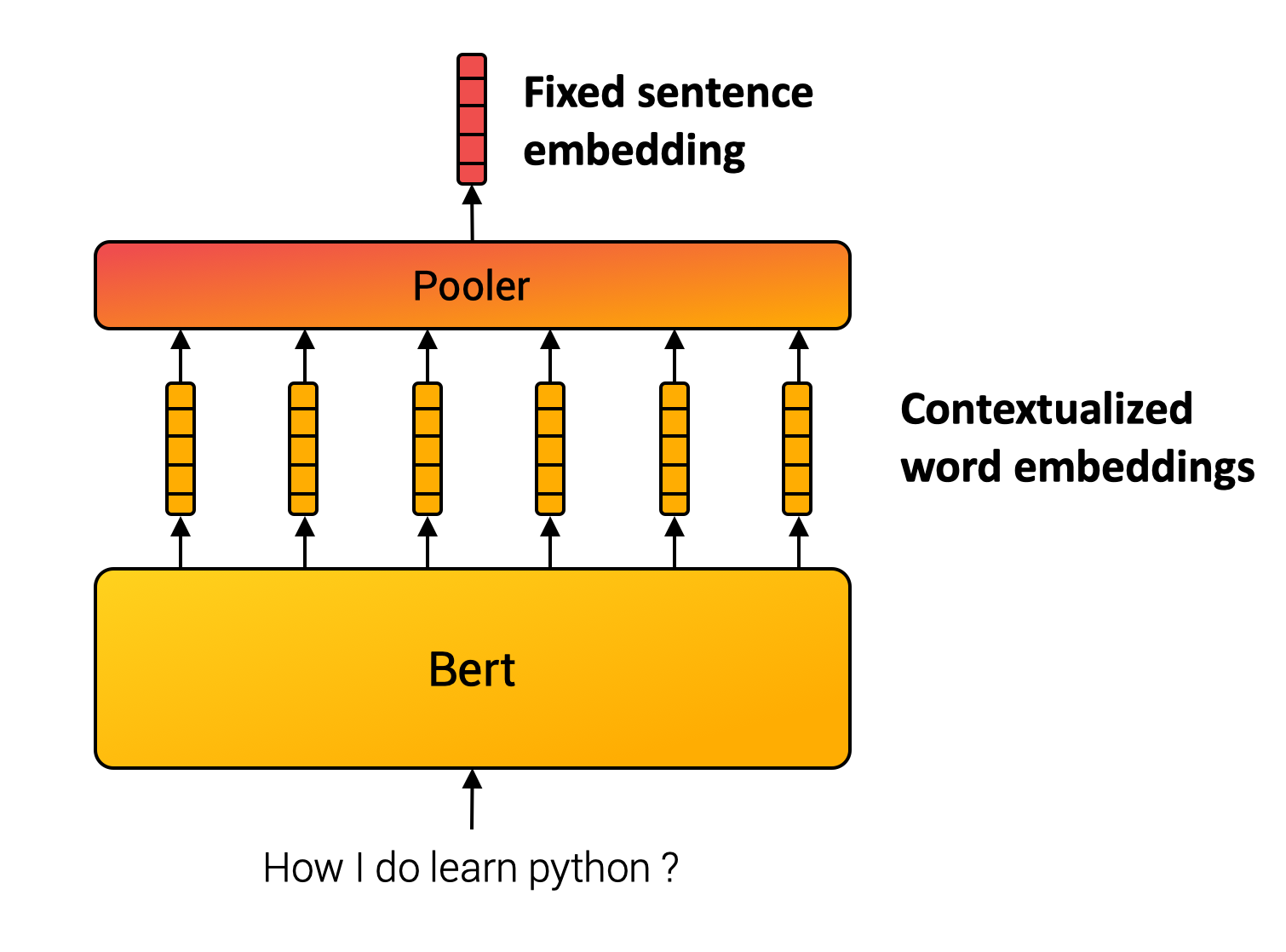
与单词不同,我们无法定义一个有限的句子集合。因此,句子嵌入方法通过组合内部单词来计算最终表示。例如,SentenceBert模型(Reimers and Gurevych, 2019)使用Transformer(许多NLP应用的基石),然后对上下文词向量进行池化操作。(见下图。)
多重负样本排序损失
组合模块的参数通常使用自监督目标进行学习。对于该项目,我们使用了下图所示的对比训练方法。我们构建了一个包含句子对 的数据集,使得句子的含义相近。例如,我们考虑(查询,答案段落)、(问题,重复问题)、(论文标题,引用论文标题)等配对。然后,我们训练模型将配对 映射到相近的向量,同时将不匹配的配对 映射到嵌入空间中较远的向量。这种训练方法也称为批内负样本训练,InfoNCE或NTXentLoss。
形式上,给定一批训练样本,模型优化以下损失函数
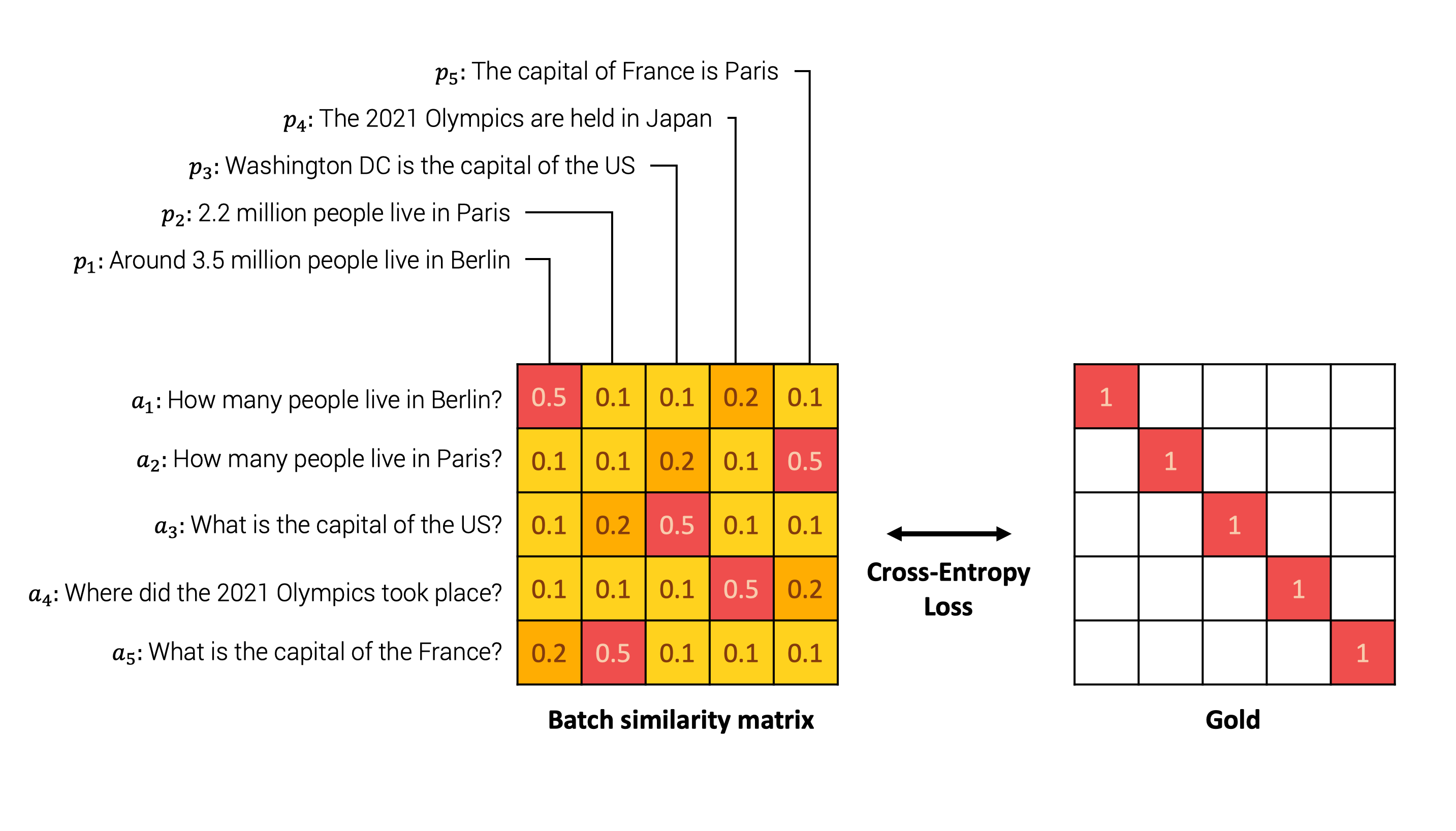
一个说明性的例子如下。模型首先嵌入批处理中每个句子对中的每个句子。然后,我们计算每对可能的 之间的相似度矩阵。然后,我们将相似度矩阵与表示原始配对的真值进行比较。最后,我们使用交叉熵损失进行比较。
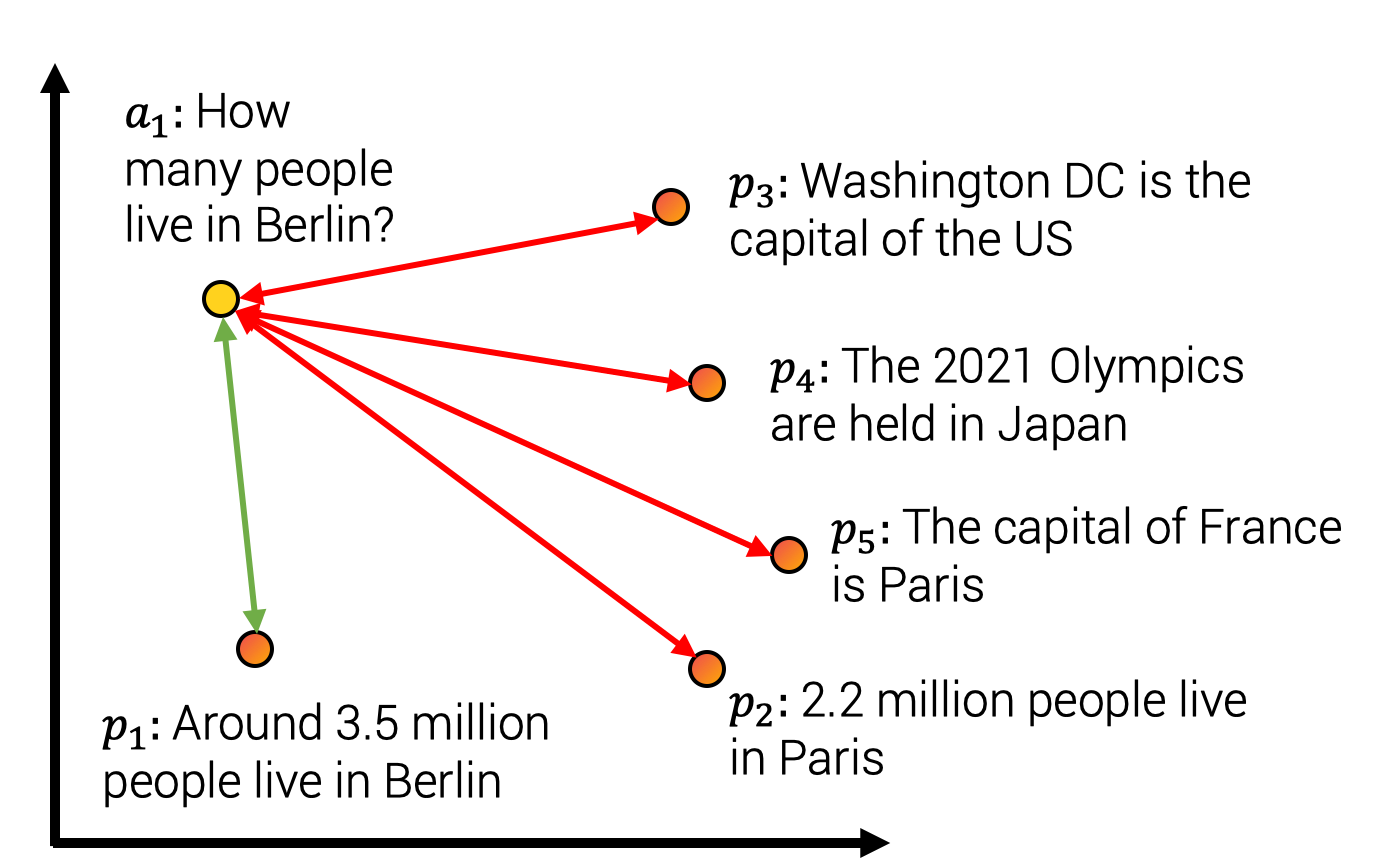
直观地讲,模型应该将句子“柏林有多少人居住?”和“大约有350万人居住在柏林”分配高相似度,而将其他负面答案(例如“法国的首都是巴黎”)分配低相似度,如下图所示。
在损失方程中,sim 表示 之间的相似度函数。相似度函数可以是余弦相似度或点积运算。这两种方法各有优缺点,总结如下(Thakur et al., 2021,Bachrach et al., 2014)
| 余弦相似度 | 点积 |
|---|---|
| 向量与其自身相似度最高,因为 。 | 其他向量可以具有更高的点积 。 |
| 对于归一化向量,它等于点积。最大向量长度等于1。 | 对于某些近似最近邻方法,它可能较慢,因为最大向量未知。 |
| 对于归一化向量,它与欧几里得距离成正比。适用于k均值聚类。 | 它不适用于k均值聚类。 |
实践中,我们使用了缩放相似度,因为分数差异往往过小,并应用缩放因子 ,使得 ,通常 (Henderson et al., 2020,Radford et al., 2021)。
通过更好的批次提高质量
在我们的方法中,我们构建样本对 的批次。我们将批次中的所有其他样本,即 ,视为负样本对。因此,批次组成是关键的训练方面。根据该领域的文献,我们主要关注批次的三个主要方面。
1. 批次大小很重要
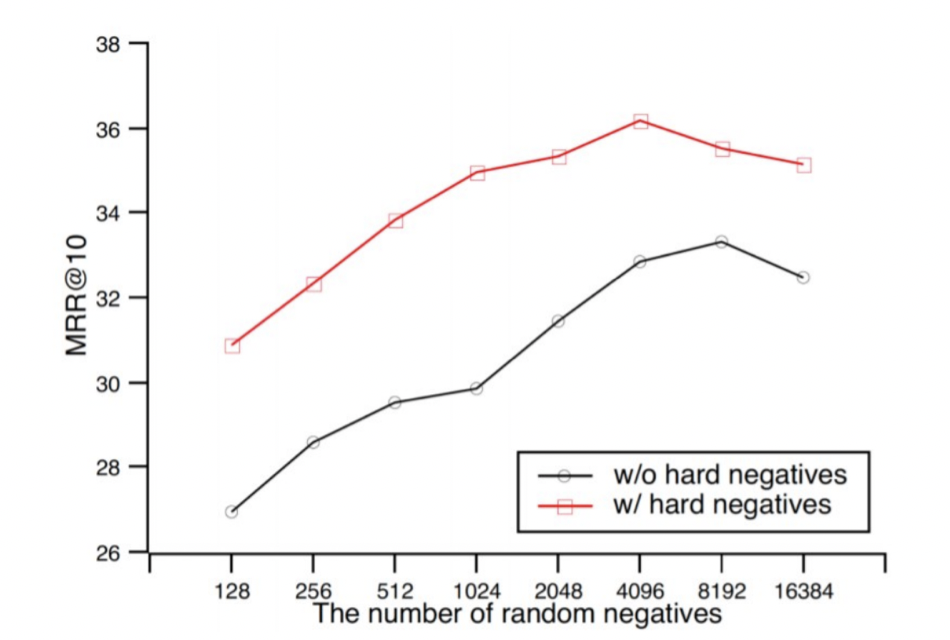
在对比学习中,较大的批次大小意味着更好的性能。如从Qu et al., (2021)中提取的图中所示,较大的批次大小可以提高结果。
2. 难负样本
在同一张图中,我们观察到包含难负样本也能提高性能。难负样本是指很难与 区分的样本 。在我们的例子中,它可能是“法国的首都是什么?”和“美国的首都是什么?”这样的配对,它们语义内容相近,需要精确理解整个句子才能正确回答。相反,“法国的首都是什么?”和“有多少部星球大战电影?”这样的样本则较容易区分,因为它们不属于同一主题。
3. 跨数据集批次
我们连接了多个数据集来训练我们的模型。我们构建了一个大型批次,并从同一批次数据集中收集样本,以限制主题分布并倾向于难负样本。然而,我们还在批次中混合了至少两个数据集,以学习主题之间的全局结构,而不仅仅是主题内的局部结构。
训练基础设施和数据
如前所述,数据量和批次大小直接影响模型性能。作为项目的一部分,我们得益于高效的硬件基础设施。我们在TPU上训练模型,TPU是谷歌开发的计算单元,对于矩阵乘法非常高效。TPU有一些硬件特性,可能需要一些特定的代码实现。
此外,我们在一个大型语料库上训练了模型,我们连接了多达10亿个句子对数据集!所有使用的模型数据集都详细列在模型卡片中。
结论
您可以在我们的HuggingFace仓库中找到我们在挑战期间创建的所有模型和数据集。我们训练了20个通用句子转换器模型,例如Mini-LM(Wang et al., 2020)、RoBERTa(liu et al., 2019)、DistilBERT(Sanh et al., 2020)和MPNet(Song et al., 2020)。我们的模型在多个通用句子相似度评估任务中达到了最先进的水平。我们还共享了8个数据集,专门用于问答、句子相似度和性别评估。
通用句子嵌入可用于多种应用。我们构建了一个Spaces演示来展示多种应用
- 句子相似度模块比较主文本与您选择的其他文本的相似度。在后台,演示提取每个文本的嵌入,并使用余弦相似度计算源句子与其他文本之间的相似度。
- 非对称问答将给定查询的答案可能性与您选择的候选答案进行比较。
- 搜索/聚类返回与查询相近的答案。例如,如果输入“python”,它将使用点积距离检索最接近的句子。
- 性别偏见评估通过随机抽样句子来报告训练集中固有的性别偏见。给定一个锚文本,其中未提及目标职业的性别,以及两个带有性别代词的命题,我们比较模型是否为给定命题分配更高的相似度,从而评估其偏向特定性别的比例。
使用JAX/Flax进行NLP和CV社区周是一次紧张而收获丰厚的体验!Google的Flax、JAX和Cloud以及Hugging Face团队成员的指导质量和他们的存在帮助我们所有人学到了很多。我们希望所有项目都像我们自己的项目一样充满乐趣。如果您有任何问题或建议,请随时与我们联系!

