使用 RedPajama 进行动态主题建模:一种理解分层内容的新方法
社区文章 发布于 2024 年 11 月 23 日

有关此数据集的个人旅程和动机,请查阅数据集创建者撰写的《教会 AI 如何像我一样书签网页并分组》。
 *动态主题建模的可视化*
*动态主题建模的可视化*引言
在大语言模型时代,大规模主题建模带来了独特的挑战。尽管传统的 LDA(潜在狄利克雷分配)等方法已广为人知,但在处理现代内容的复杂性和规模时,它们往往力不从心。今天,我很高兴能介绍一个将分层主题建模引入大语言模型时代的新数据集:Dynamic-Topic-RedPajama-Data-1T-100k-SubSample-max-1k-tokens。
数据集概述
该数据集包含从 RedPajama-1T 数据集中精心挑选的 100,000 个样本,每个样本都标注有三级分层主题结构。
{
"text": "Original document content...",
"topic_level_1": "Subject Topic", # Broad domain
"topic_level_2": "High-Level Topic", # Specific focus
"topic_level_3": "Niche Topic" # Detailed theme
}
关键统计数据:
- 文档数量:100,000
- 每个文档的最大 token 数量:1,024
- 唯一一级主题:25,178
- 唯一二级主题:71,024
- 唯一三级主题:92,568
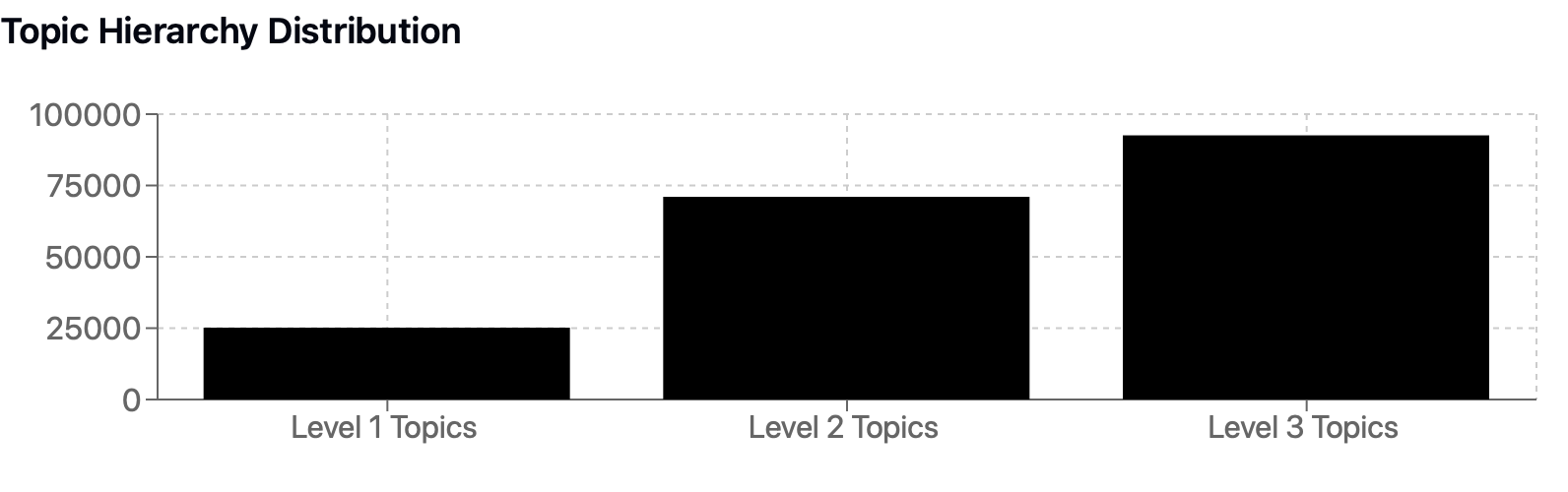 *不同层级主题分布图*
*不同层级主题分布图*技术实现
文档处理流程
from transformers import AutoTokenizer
import torch
def prepare_documents(texts, max_length=1024):
tokenizer = AutoTokenizer.from_pretrained("gpt2")
processed_docs = []
for text in texts:
# Truncate and tokenize
encoded = tokenizer(
text,
truncation=True,
max_length=max_length,
return_tensors="pt"
)
processed_docs.append(encoded)
return processed_docs
主题生成过程
主题是使用 GPT-4o-mini 通过结构化提示方法生成的。
def generate_topics(text):
prompt = f"""
Given the following text, generate three hierarchical topics:
Text: {text}
1. Broad subject domain:
2. Specific focus area:
3. Detailed thematic element:
"""
# Generation logic here
return topics
应用和用例
模型微调
- 训练更小、更高效的主题分类器
- 开发分层分类系统
内容组织
- 自动化文档分类
- 内容推荐系统
- 知识库结构化
研究应用
- 研究大型语料库中的主题演变
- 跨领域知识迁移
- 语义关系分析
开始使用
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("AmanPriyanshu/Dynamic-Topic-RedPajama-Data-1T-100k-SubSample-max-1k-tokens")
# Basic exploration
print(f"Dataset size: {len(dataset['train'])}")
print(f"Sample entry:\n{dataset['train'][0]}")
未来方向
- 跨语言扩展:扩展到多语言主题建模
- 时间分析:整合基于时间的主题演变
- 交互式工具:开发可视化和探索界面
- 模型压缩:创建高效的主题建模架构
引用
@misc{dynamic-topic-redpajama,
author = {Aman Priyanshu},
title = {Dynamic Topic RedPajama Data 1T 100k SubSample},
year = {2024},
publisher = {HuggingFace}
}
社区与贡献
我欢迎社区的贡献和反馈。无论您是对扩展数据集、改进主题生成过程还是在此基础上构建应用程序感兴趣,请查看 Huggingface 数据集发布或加入社区论坛讨论。
致谢
本数据集建立在 RedPajama 数据集团队和更广泛的开源人工智能社区的工作基础上。