5090 更多?问题更多?双路 NVIDIA GPU 配置测试



在我们之前的文章中,我们详细介绍了测试一台配备单个 RTX 5090 服务器的经验。现在,我们决定在该服务器上安装两块 RTX 5090 GPU。这给我们带来了一些挑战,但结果是值得的。
我们更换了两块 GPU——安装了两块 GPU
为了简化和加快流程,我们最初决定将服务器中已有的两块 4090 GPU 更换为 5090。服务器配置最终如下:Core i9-14900KF 6.0GHz (24 核)/ 192GB RAM / 2TB NVMe SSD / 2xRTX 5090 32GB。
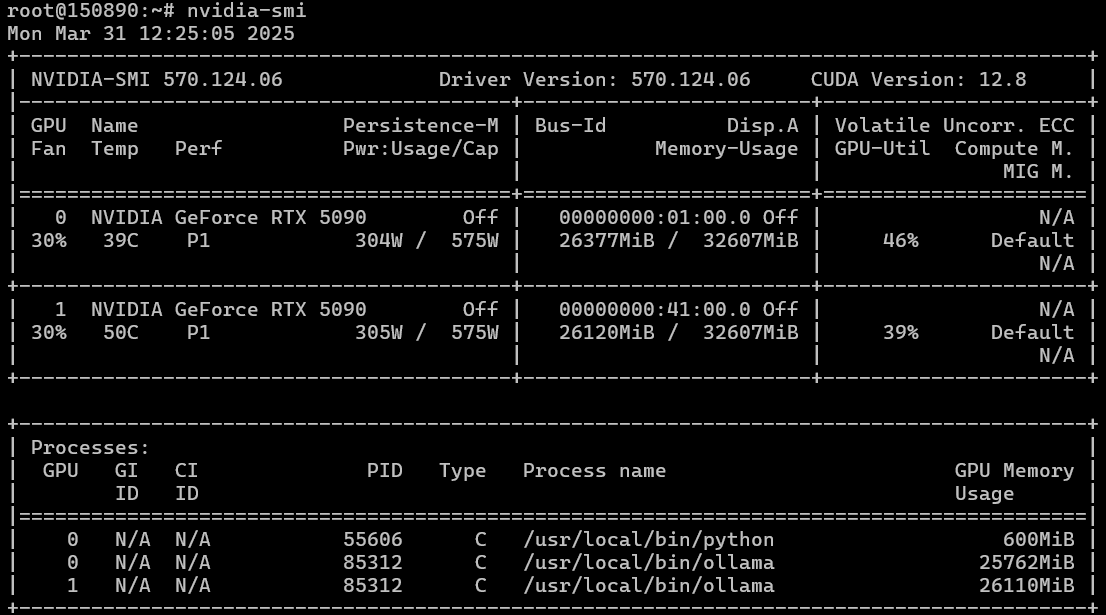
我们部署了 Ubuntu 22.04,使用我们的“魔法脚本”安装了驱动程序,安装过程没有遇到任何问题,CUDA 也一样。nvidia-smi 显示了两块 GPU。电源似乎能承受高达 1.5 千瓦的负载。
人工智能平台:预装人工智能和 LLM 模型的 GPU 服务器
为您的 AI 项目租用一台配备专业级和游戏级 NVIDIA 显卡的 GPU 服务器。预装软件在服务器部署后即可立即使用。
我们安装了 Ollama,下载了一个模型并运行它——结果发现 Ollama 在 CPU 上运行,没有识别出 GPU。我们尝试使用 CUDA 的 GPU 编号直接指定 CUDA 设备来启动 Ollama
CUDA_VISIBLE_DEVICES=0,1 ollama serve但我们仍然得到相同的结果:Ollama 无法在两块 GPU 上初始化。我们尝试在单 GPU 模式下运行,设置 `CUDA_VISIBLE_DEVICE=0` 和 `CUDA_VISIBLE_DEVICE=1`——情况相同。
我们尝试安装 Ubuntu 24.04——也许新的 CUDA 12.8 在“较旧的”Ubuntu 上与多 GPU 配置不兼容?是的,GPU 可以单独工作。

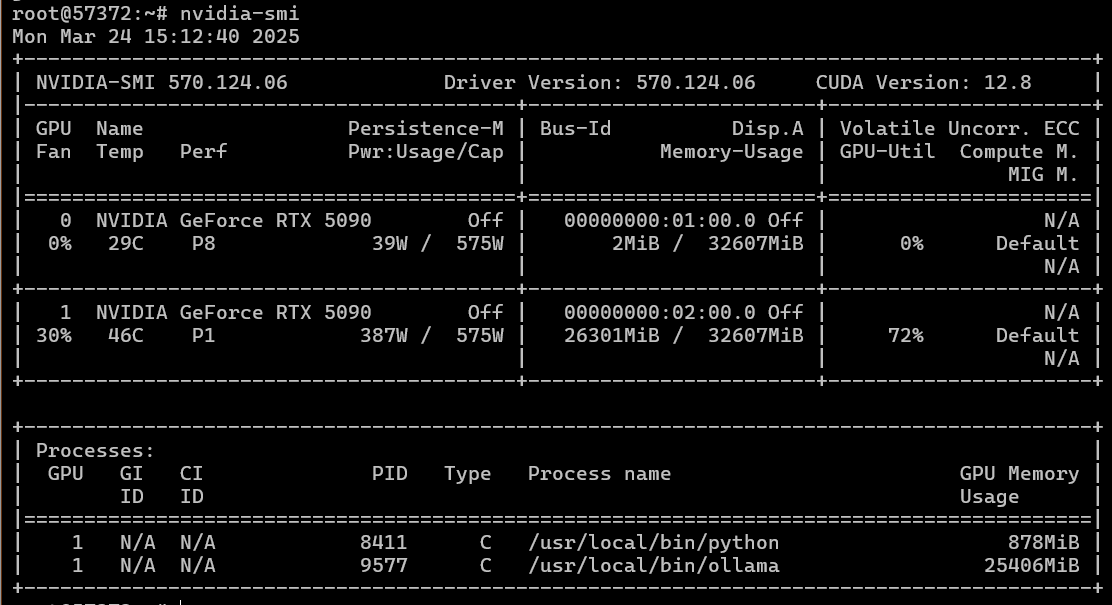
然而,尝试在两块 GPU 上运行 Ollama 仍然导致相同的 CUDA 初始化错误。
考虑到 Ollama 在多 GPU 上运行可能存在问题,我们尝试了 PyTorch。请记住,对于 RTX 50xx 系列,我们需要安装支持 CUDA 12.8 的最新兼容版本 2.7。
pip install torch torchvision torchaudio我们运行了以下测试
import torch
if torch.cuda.is_available():
device_count = torch.cuda.device_count()
print(f"CUDA is available! Device count: {device_count}")
for i in range(min(device_count, 2)): # Limit to 2 GPUs
device = torch.device(f"cuda:{i}")
try:
print(f"Successfully created device: {device}")
x = torch.rand(10,10, device=device)
print(f"Successfully created tensor on device {device}")
except Exception as e:
print(f"Error creating device or tensor: {e}")
else:
print("CUDA is not available.")当在两块 GPU 上运行时,我们收到错误;而在传递 CUDA 使用变量时,每块 GPU 都能成功运行。
为了可靠性,我们决定按照本指南安装并验证 CuDNN,并使用了这些测试:https://github.com/NVIDIA/nccl-tests。
两块 GPU 的测试也失败了。然后我们更换了 GPU,更换了转接卡,并单独测试了每块 GPU——均无结果。
新服务器,最后进行测试。
我们怀疑问题可能出在硬件难以支持两块 5090 上。我们将两块 GPU 转移到另一个系统:AMD EPYC 9354 3.25GHz (32 核) / 1152GB RAM / 2TB NVMe SSD / PSU + 2xRTX 5090 32GB。我们重新安装了 Ubuntu 22.04,将内核更新到版本 6,更新了驱动程序、CUDA、Ollama,并运行了模型……
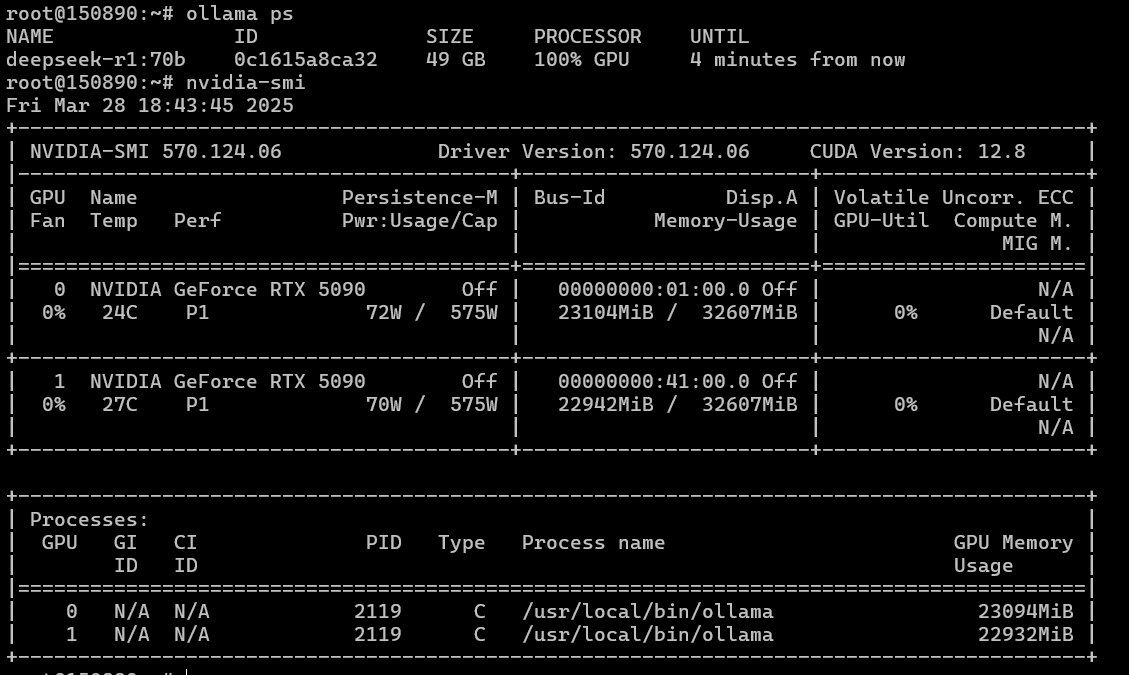
太棒了!——一切都开始正常工作了。Ollama 可以在两块 GPU 上进行扩展,这意味着其他框架也应该可以工作。我们以防万一检查了 NCCL 和 PyTorch。
NCCL 测试
./build/all_reduce_perf -b 8 -e 256M -f 2 -g 2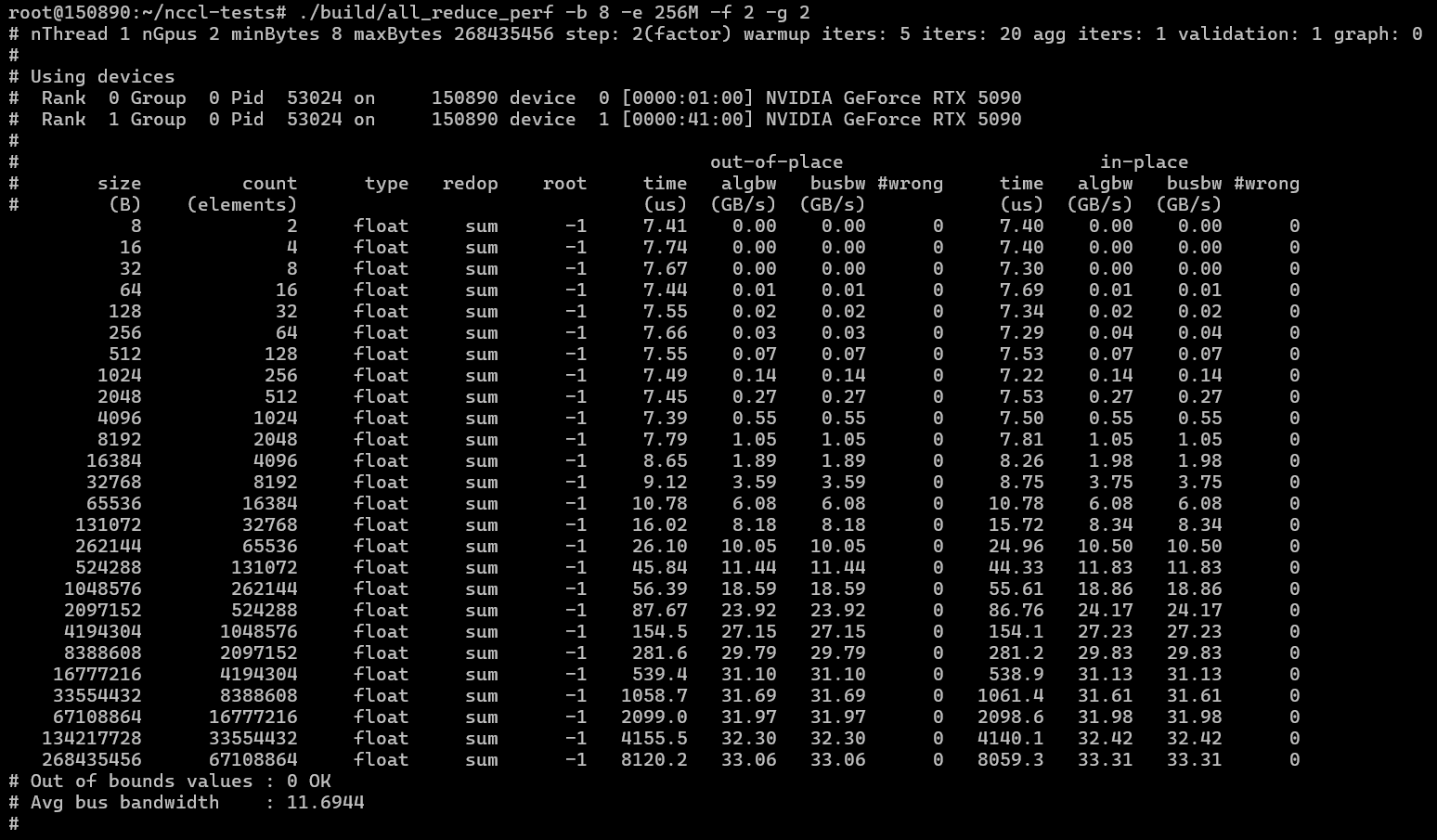
PyTorch 与前面提到的测试
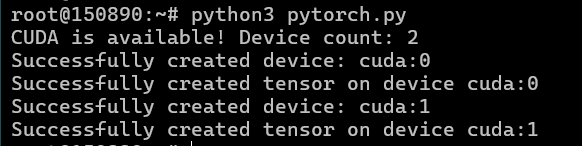
我们正在测试神经网络模型,以使用 Ollama 和 OpenWebUI 组合将它们的性能与双 4090 配置进行比较。
为了与 5090 配合使用,我们还在 OpenWebUI Docker 容器中更新了 PyTorch,使其支持 Blackwell 和 CUDA 12.8 的最新版本 2.7。
docker exec -it open-webui bash
pip install --upgrade torch torchvision torchaudioDeepSeek R1 14 B
上下文大小:32768 tokens。提示:“用 HTML 和 JS 编写一个简单的贪吃蛇游戏代码”。
模型占用一个 GPU

响应速度:110 tokens/秒,相比双 4090 配置的 65 tokens/秒。响应时间分别为 18 秒和 34 秒。
DeepSeek R14 70B
我们使用 32K token 的上下文大小测试了该模型。该模型已经占用 64GB GPU 内存,因此在 2x4090 配置的 48GB 总 GPU 内存中无法容纳。在两块 5090 上,即使上下文大小很大,也可以容纳。

如果使用 8K 上下文,GPU 内存利用率会更低。
我们进行了 32K 上下文的测试,并使用了相同的提示“用 HTML 和 JS 编写一个简单的贪吃蛇游戏代码。” 平均响应速度为每秒 26 个 token,请求在大约 50-60 秒内处理完毕。
如果我们将上下文大小减小到 16K,并使用例如“用 HTML 编写俄罗斯方块”的提示,两块 GPU 将占用 49GB 的 GPU 内存。

减小上下文大小不会影响响应速度,响应速度仍为每秒 26 个令牌,处理时间约为 1 分钟。因此,上下文大小只会影响 GPU 内存利用率。
生成图形
接下来,我们将在 ComfyUI 中测试图形生成。我们使用 1024x1024 分辨率的 Stable Diffusion 3.5 Large 模型。
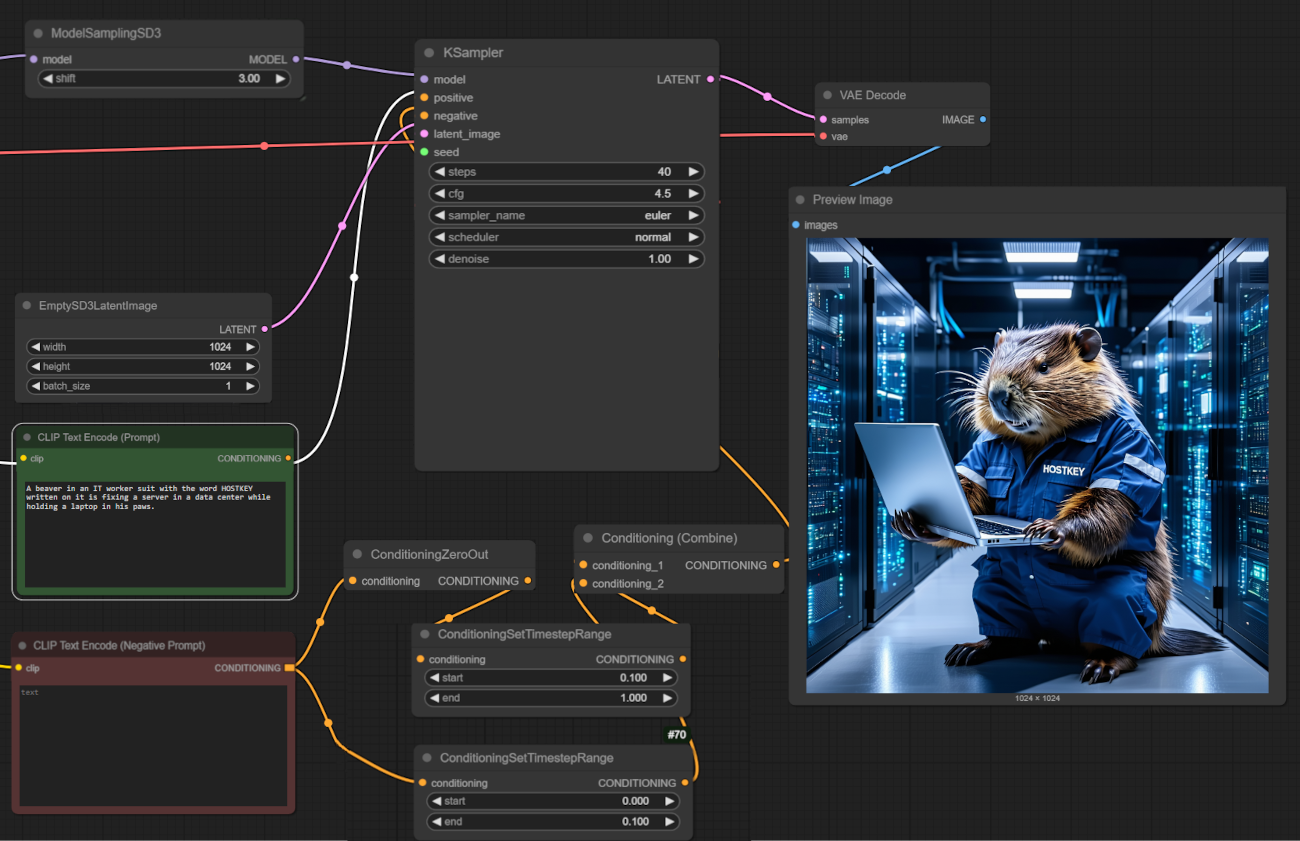
平均而言,在这个模型上,GPU 每张图像花费 15 秒,占用单个 GPU 的 22.5GB 显存。在 4090 上,相同的参数需要 22 秒。

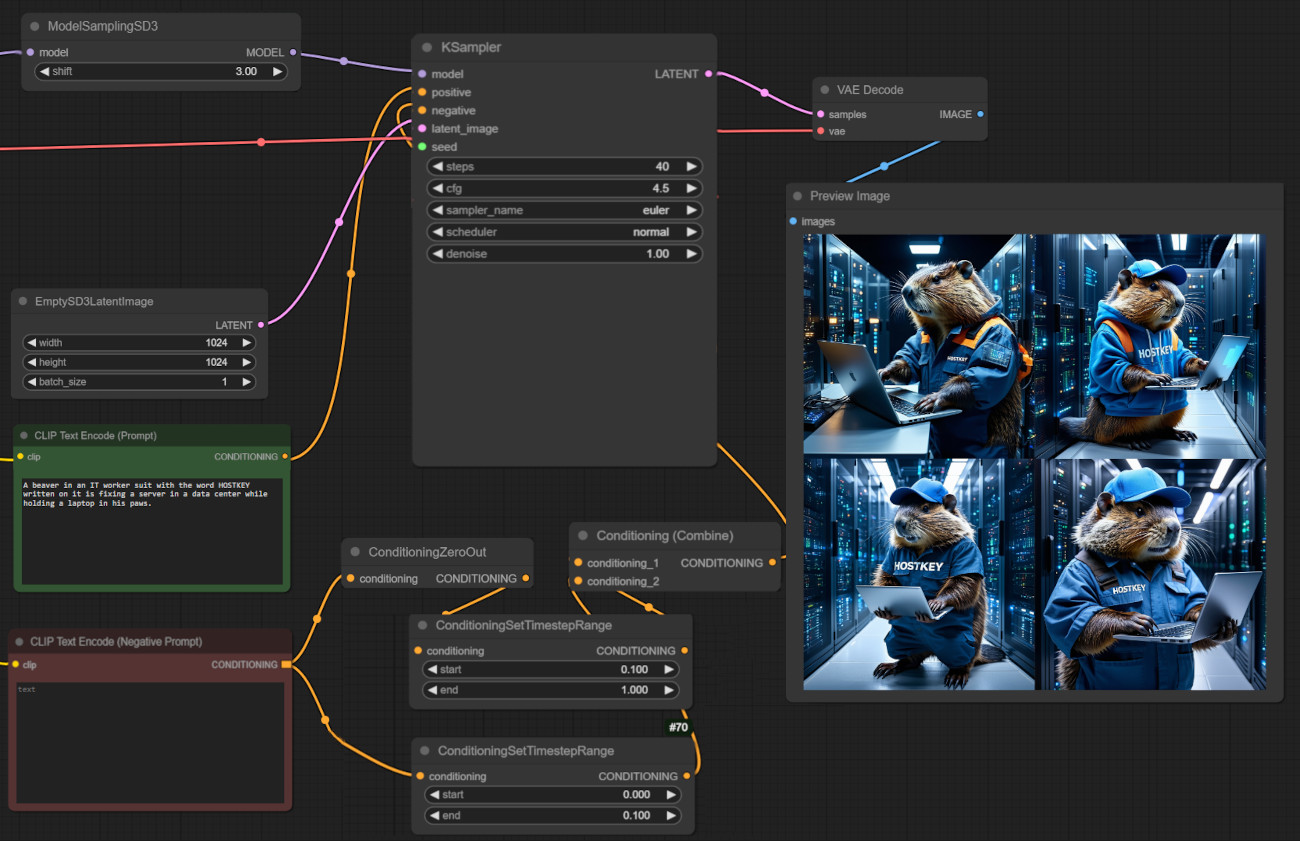
如果我们设置批处理生成(四张 1024x1024 图像),总共花费 60 秒。ComfyUI 不会并行处理工作,但会利用更多 GPU 内存。

结论
双路 NVIDIA RTX 5090 配置在需要大量 GPU 内存且软件能够并行处理任务并利用多 GPU 的任务中表现出色。在速度方面,双 5090 设置比双 4090 更快,并且由于更快的内存和 Tensor 核心性能,在某些任务(如推理)中可以提供高达双倍的性能。然而,这会增加功耗,并且并非所有服务器配置都能处理双 5090 设置。更多的 GPU?可能不会,因为在这些场景中,A100/H100 等专用 GPU 占据主导地位。