Jensen Huang,你认真的吗?!在AI工作流中测试NVIDIA RTX 5090


尽管供应严重受限,我们仍有幸获得多块NVIDIA GeForce RTX 5090 GPU,并对其中一块进行了基准测试。其性能并不像Nvidia最初承诺的那样直截了当,但测试结果令人着迷,并预示着这款GPU在AI/模型工作流中的巨大潜力。
平台配置
设置相当简单:我们取来一台装有4090的服务器系统,将其移除,然后换上5090。由此我们得到了以下配置:Intel Core i9-14900K,128GB RAM,2TB NVMe SSD,当然还有一块配备32GB显存的GeForce RTX 5090。

如果你在想“那些电源接口呢?”,在这里一切都显得很稳定——连接器在运行过程中从未超过65摄氏度。我们使用原装风冷散热器运行显卡,热性能结果可以在下一节找到。

这张显卡的功耗比GeForce RTX 4090高得多。我们整个系统峰值功耗达到830瓦,因此一个强大的电源至关重要。幸运的是,我们现有的电源有足够的余量,所以不需要更换。
软件
我们将在Ubuntu 22.04中运行并基准测试所有内容。流程包括安装操作系统,然后使用我们的神奇自定义脚本安装驱动程序和CUDA。Nvidia-smi确认运行正常,我们的“GPU怪兽”正在消耗足以媲美整个家庭用电的电量。截图显示了负载下的温度和功耗,其中CPU利用率仅为40%。
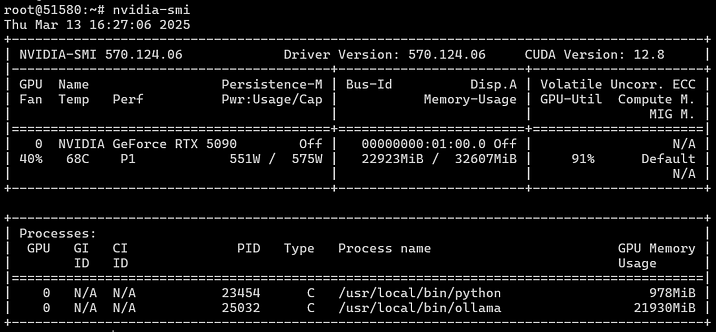
操作系统运行后,我们安装了Docker,配置了Nvidia GPU直通到容器,然后直接在操作系统中安装了Ollama,并以Docker容器形式安装了OpenWebUI。一切运行就绪后,我们开始了基准测试套件。
基准测试
首先,我们决定评估各种神经网络模型的速度。为了方便,我们选择将OpenWebUI与Ollama结合使用。需要说明的是,直接使用Ollama通常会更快,并需要更少的资源。然而,我们只能通过API从测试中提取数据,我们的目标是了解5090与上一代(4090)相比速度快了多少,以及快了多少。
在同一系统中的RTX 4090作为我们的对照卡进行比较。所有测试均使用预加载模型进行,记录的值为十次独立运行的平均值。
让我们从Q4格式的DeepSeek R1 14B开始,使用32,768个token的上下文窗口大小。该模型在独立线程中处理思想,并消耗相当多的资源,但它对于显存小于16GB的消费级GPU仍然很受欢迎。此测试确保我们消除了存储、RAM或CPU速度的潜在影响,因为所有计算都在显存内处理。
此模型需要11GB显存才能运行。

我们使用了以下提示:“编写一个简单的HTML和JS贪吃蛇游戏代码”。我们收到了大约2,000个token的输出。
| RTX 5090 32 GB | RTX 4090 24 GB | |
| 响应速度(每秒Token数) | 104,5 | 65,8 |
| 响应时间(秒) | 20 | 40 |
如所示,5090的性能提升高达40%。这甚至在流行框架和库完全为Blackwell架构优化之前就已实现,尽管CUDA 12.8已经利用了关键改进。
下一项基准测试:我们之前提到过使用基于AI的翻译代理进行文档工作流,所以我们很想知道5090是否能加速我们的流程。
对于此测试,我们采用以下系统提示将英语翻译成土耳其语
You are native translator from English to Turkish.
I will provide you with text in Markdown format for translation. The text is related to IT.
Follow these instructions:
- Do not change Markdown format.
- Translate text, considering the specific terminology and features.
- Do not provide a description of how and why you made such a translation.
- Keep on English box, panels, menu and submenu names, buttons names and other UX elements in tags '** **' and '\~\~** **\~\~'.
- Use the following Markdown constructs: '!!! warning "Dikkat"', '!!! info "Bilgi"', '!!! note "Not"', '??? example'. Translate 'Password" as 'Şifre'.
- Translate '## Deployment Features' as '## Çalıştırma Özellikleri'.
- Translate 'Documentation and FAQs' as 'Dokümantasyon ve SSS'.
- Translate 'To install this software using the API, follow [these instructions](../../apidocs/index.md#instant-server-ordering-algorithm-with-eqorder_instance).' as 'Bu yazılımı API kullanarak kurmak için [bu talimatları](https://hostkey.com/documentation/apidocs/#instant-server-ordering-algorithm-with-eqorder_instance) izleyin.'我们发送该文档页面的内容作为回复。
| RTX 5090 32 GB | RTX 4090 24 GB | |
| 响应速度(每秒Token数) | 88 | 55 |
| 响应时间(秒) | 60 | 100 |
在输出方面,我们平均得到5K个token,总共10K个(提醒一下,我们的上下文长度目前设置为32K)。正如您在此处所见,5090速度更快,甚至在预期30%的改进范围内。
接下来是“更大的”模型,我们将使用新的Gemma3 27B。我们将其输入上下文大小设置为16,384个token。在5090上,该模型消耗26 GB显存。

这次,我们尝试为一家服务器租赁公司生成一个Logo(以防我们决定更换旧的HOSTKEY Logo)。提示将是:“为服务器租赁公司设计一个复杂的SVG Logo。”
这是输出
| RTX 5090 32 GB | RTX 4090 24 GB | |
| 响应速度(每秒Token数) | 48 | 7 |
| 响应时间(秒) | 44 | 270 |
RTX 4090以失败告终。检查GPU使用率,我们发现17%被中央处理器和系统内存占用,这必然导致速度下降。此外,由于这个原因,总资源使用量也有所增加。RTX 5090上的32GB板载显存对于这种大小的模型确实有帮助。

Gemma3是一个多模态模型,这意味着它可以识别图像。我们选择一张图片,并要求它找出图片中的所有动物:“找出图片中的所有动物。”我们将上下文大小保持在16K。
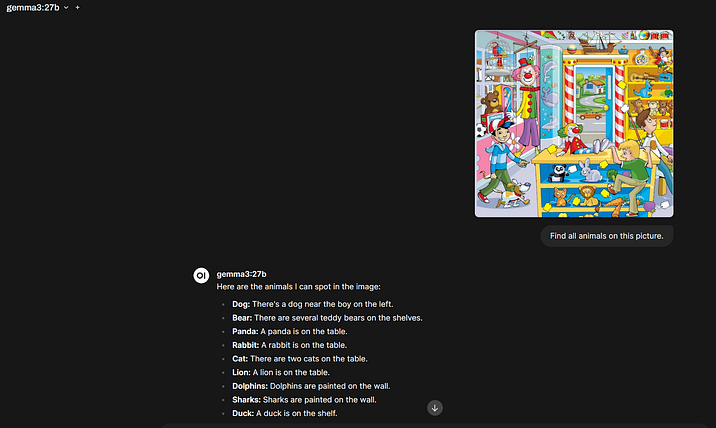
使用4090,事情就不那么简单了。在这种输出上下文大小下,模型停滞不前。将其减少到8K降低了显存消耗,但似乎在CPU上处理图像,即使只占5%的时间,也不是最好的方法。

因此,所有4090的结果都是在2K上下文下获得的,这使得这张显卡在起跑线上占优,因为Gemma3只使用了20GB显存。

作为比较,括号中的数字显示了5090在2K上下文下获得的结果。
| RTX 5090 32 GB | RTX 4090 24 GB | |
| 响应速度(每秒Token数) | 49 (78) | 39 |
| 响应时间(秒) | 10 (4) | 6 |
接下来要测试的又是“ChatGPT杀手”,这次是DeepSeek,但参数达到了320亿。该模型在5090上占用25GB显存,在4090上占用26GB并部分利用CPU。


我们将通过要求神经网络编写基于浏览器的俄罗斯方块进行测试。我们将上下文设置为2K,考虑到之前测试中的问题。我们故意给它一个信息量不足的提示:“用HTML编写俄罗斯方块”,然后等待结果。有几次,我们甚至得到了可玩的结果。
| RTX 5090 32 GB | RTX 4090 24 GB | |
| 响应速度(每秒Token数) | 57 | 17 |
| 响应时间(秒) | 45 | 180 |
关于令人失望之处
当我们尝试在处理矢量数据库时比较显卡性能时,首次出现了警报:创建嵌入并搜索考虑这些嵌入的结果。我们无法创建新的知识库。之后,OpenWebUI中的网页搜索也无法工作。
然后我们决定测试图形生成的速度,使用Stable Diffusion 3.5 Medium模型设置ComfyUI。开始生成后,我们收到了以下消息
CUDA error: no kernel image is available for execution on the device嗯,我们想,也许我们有旧版本的CUDA(没有),或者驱动程序(没有),或者PyTorch。我将后者更新到 nightly 版本,启动它,得到了相同的消息。
我们深入研究了其他用户在写什么以及是否有解决方案,结果发现问题是缺乏针对Blackwell架构和CUDA 12.8的PyTorch构建。除了手动从源代码使用必要的密钥重新构建所有内容外,没有其他解决方案。
根据抱怨来看,与其他“紧密”与CUDA交互的库也存在类似问题。只能等待。
那么,底线是什么?
主要发现:Jensen Huang 没有误导人——在AI应用中,5090的性能比上一代更快,而且通常快得多。增加的显存容量使其能够运行27/32B模型,即使在最大上下文大小下也是如此。然而,有一个“但是”——32GB显存仍然有点不足。是的,它是一款游戏卡,我们正在等待配备64GB或更多显存的专业版本来取代A6000系列(RTX PRO 6000,配备96GB显存刚刚发布)。
我们认为NVIDIA在这里有点吝啬,本可以轻易地在顶级型号中包含48GB而不会对成本造成太大影响(或者发布4090 Ti供爱好者使用)。至于软件未正确适配的事实:NVIDIA再次表明它经常“忽视”与社区的合作,因为发布时PyTorch或TensorFlow无法正常工作(由于新版CUDA也存在类似问题)简直是耻辱。但这就是社区存在的意义——解决并相当快地解决此类问题,我们认为软件支持情况将在几周内有所改善。