偏见分类法:AI 系统中隐藏偏见实地指南,每个开发者都应该了解



AI 偏见的基础:随手涂鸦而成
2022 年,我坐在新奥尔良计算机视觉与模式识别大会 (CVPR New Orleans) 拥挤的大厅里,听谷歌研究人员讲授算法公平性的课程。那一刻,我的世界观被颠覆了。多年来设计机器学习系统的经验告诉我,数据并非中立,它蕴含着我们的偏见、成见和社会盲点。
那一刻,我幡然醒悟。
我之前的文章介绍了“YOU 偏见”,探讨了生成模型中的个性化偏见。现在,我将视野放大。这份综合指南通过案例研究和行业失败案例,为任何构建、审计或与 AI 系统交互的人员提供了一份精确、可操作的路线图。
无论您是机器学习工程师、数据科学家、政策制定者、初创公司创始人还是爱好者,请将此视为一份开发强大、道德、偏见感知 AI 系统的生存手册,而不仅仅是缺陷清单。
AI 系统中的偏见蓝图
我们常常将模型性能视为单一指标。但偏见在训练之前很久和之后很久都会悄然出现。我是这样组织它的:
1. 数据偏见
- 历史偏见
- 代表性偏见
- 测量/标签偏见
2. 算法偏见
- 聚合偏见
- 优化偏见
- 反馈循环偏见
3. 评估偏见
- 基准偏见
- 指标盲点
4. 生成式与交互偏见
- 刻板印象输出
- 内容审核漏洞
5. 社会和文化偏见
- 性别、种族、社会经济、文化
偏见不仅仅是数据问题。它是系统设计上的缺陷。
数据偏见:我们选择从何处学习

数据偏见的类型:随手涂鸦而成
历史偏见:当数据反映了系统性不平等或过时的社会规范时。
- 示例:亚马逊的内部 AI 招聘工具根据过去的成功简历进行训练,而这些简历大多来自男性。结果,该系统会惩罚包含“女性”等词的简历(例如,“女子象棋俱乐部”),并降低女子学院毕业生的评级。这并非编码错误;它反映了历史歧视被编码到数据中。
代表性偏见:当训练数据中某些群体被欠采样或排除时。
- 示例 1:2015 年,谷歌相册因缺少深色皮肤人脸的训练数据,将黑人错误分类为“大猩猩”。谷歌随后彻底禁用了该标签。
- 示例 2:Joy Buolamwini 和 Timnit Gebru 的“性别阴影”研究发现,商用人脸识别系统对深色皮肤女性的错误率高达 34%,而对浅色皮肤男性的错误率仅为 1%。训练数据缺乏多样性导致对某些人群的识别结果危险地不可靠。
测量/标签偏见:当训练中使用的标签或特征未能准确捕捉目标概念时。
- 示例:一个美国医疗保健算法使用“医疗费用”作为患者需求的代理。由于黑人患者在历史上获得的医疗服务较少,该算法低估了他们的需求,尽管医疗状况相同,但在护理项目中分配给他们的关注较少。
算法偏见:我们优化了什么

算法偏见的类型:随手涂鸦而成
聚合偏见:当模型对所有群体应用相同的规则,而没有考虑群体特定的模式时。
模型不仅学习你告诉它们的东西;它们还优化你奖励的东西。
- 示例:COMPAS,一种用于美国法院的风险评估工具,被发现将黑人被告错误地标记为高风险的概率几乎是白人被告的两倍,尽管整体预测准确性相似。该模型通过忽略群体层面基线率和背景差异来放大不平等。
优化偏见:当算法为多数群体或强化偏见的参与/成功指标进行优化时。
- 示例:Facebook 的广告投放系统主要向男性展示技术和管理职位的招聘广告,即使定位是性别中立的。该算法从点击数据中得知男性更可能参与,从而强化了有偏见的曝光。
反馈循环偏见:当有偏见的输出随着时间的推移自我强化时。
- 示例:Spotify 的“发现周刊”播放列表引擎推荐了更多男性艺术家。由于用户与这些艺术家互动,系统在未来推荐男性艺术家时变得更加自信,减少了女性创作者的曝光——这是一个经典的偏见回音室。
评估偏见:我们假装有效的东西
评估偏见的类型:随手涂鸦而成
基准偏见:当评估数据不能代表真实世界的人群或使用情境时。
- 示例:早期人脸识别模型显示出 95% 以上的准确率——但这仅限于 LFW 等主要由白人男性面孔组成的数据集。直到多样化基准测试(如 NIST 2019 年的审计)出现,基于种族和性别的错误激增才变得明显。
指标盲点:当成功指标掩盖了子组的失败时。
- 示例:高盛发行的 Apple Card 给予女性较低的信用额度,即使财务状况相似。底层模型优化的是整体信用度,而非跨性别的公平性。这直到用户公开比较结果后才被发现。
生成式偏见:我们强化了什么
代表性刻板印象:当生成模型复制并放大社会刻板印象时。
- 示例 1:DALL·E 2 生成的“CEO”图像中,近 97% 为白人男性。该模型反映了其训练数据中存在的偏见。
- 示例 2:GPT-3 在以“Muslim…”开头的句子补全中,66% 的情况将穆斯林与恐怖主义联系起来,这突出显示了刻板印象关联是如何从有偏见的互联网数据中学习到的。
内容审核漏洞:当生成模型在没有护栏的情况下部署时。
- 示例:微软聊天机器人 Tay 经过推特互动训练后,在用户蓄意操纵其回复后,迅速变得**种族主义、性别歧视和反犹太主义**。在发布 16 小时内,它不得不被下线。
- 示例:Meta 的视频标注系统曾在一个显示黑人男性的视频上,询问用户是否想“观看更多关于灵长类动物的视频”。这种愤怒导致该功能被停用并公开道歉。
交互偏见:用户如何影响输出
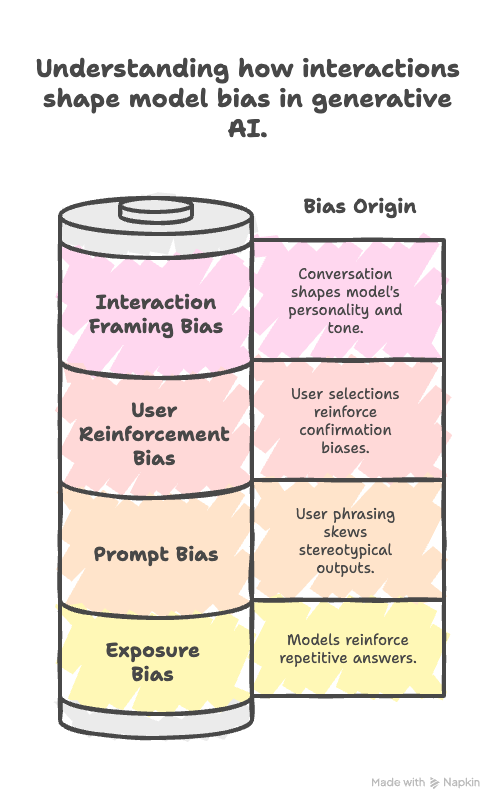
交互偏见
这些偏见源于用户与 AI 系统的交互方式
- 提示偏见: 用户措辞提示的方式可能导致生成模型中出现偏差或刻板印象输出。例如,“写一篇关于医生和护士的文章”可能会产生性别假设,除非提示更加中性化。
- 暴露偏见: 经过以前版本通过常见用户查询生成输出训练的模型,可能会强化狭隘或重复的答案,随着时间的推移限制创造性或公平的响应。
- 用户强化偏见: 用户的点击、点赞或选择充当系统优化的反馈。随着时间的推移,这会导致推荐系统中的确认偏见、两极分化和浅薄的个性化循环。
- 交互框架偏见: 用户常常在不知不觉中通过他们交谈的方式塑造模型的个性和语气,导致语言模型模仿用户偏见、情感语气或意识形态框架。
社会偏见:我们规范了什么
社会偏见的类型:随手涂鸦而成
性别偏见:
- 示例 1:谷歌翻译在性别中立的语言中,将医生默认翻译为“他”,护士默认翻译为“她”。
- 示例 2:LinkedIn 的早期排名算法在搜索结果中将男性个人资料排在更靠前的位置,从而强化了招聘偏见。
种族偏见:
- 示例:YouTube 字幕系统等语音转文本工具难以处理非洲裔美国人白话英语 (AAVE),将非标准语法错误分类为有毒或不可理解。
社会经济偏见:
- 示例:教育技术系统根据参与历史优化学习资源,从而偏爱那些初始活动较多、来自富裕地区的学生,边缘化那些资源较少或学习模式不同的学生。
这不仅仅是一个边缘案例
人工智能正在迅速扩张。失败也随之而来。这些并非罕见的失败。这些都是迹象。我们正在构建反映过去权力结构的系统,并将其部署到未来。
而这正发生在招聘、住房、警务和医疗保健领域。如果人工智能要运行世界,它就应该代表世界上的所有。
接下来:我们的角色,我们的责任
我相信是时候在机器学习领域进行文化转型了。每位工程师、研究员和产品负责人必须对他们所构建的意外后果负责。我们不仅在优化功能,还在影响生活。偏见不是一个错误指标或研究问题,而是一个系统设计问题。我们所做的每一个选择,从包含哪些数据、如何标注数据以及优化哪些指标,都会产生后果。它是一个人类影响指标。
关于本系列
在本博客系列《对抗偏见:系统、信号和修复》中,我首先绘制了问题图谱。从“YOU 偏见”到本实地指南,目标一直是命名我们未测量的内容。
“你”的茧房:YOU 偏见简介
作者:Sai Vineeth K R
medium.com
在本系列的后续文章中,我们将从发现问题转向设计解决方案。敬请期待深入探讨:
- 对偏见缓解算法最有影响力的研究进行简洁的综合
- 设计默认具有偏见感知能力的实用策略
- 系统级干预:哪些审计、监控管道和治理机制在生产中有效?
- 最后,一个引人深思的想法:如果偏见不仅仅需要缓解,而是一个可以围绕其进行设计的信号呢?偏见本身能否成为 AI 开发流程中的一流输入?
互动实验:亲自测试 AI 偏见
尝试使用 ChatGPT 或 DALL·E 等模型进行提示。要求它使用不同的身份、职业或文化生成图像或文本。
🗣️ 在下方评论: 您发现了哪些偏见?分享您的提示和见解。让我们共同提高对 AI 偏见的理解和策略。