LLM数据工程3——数据采集魔法:获取顶级训练数据





本文是DataTager团队大型模型数据10万字总结系列文章《从数据到AGI:解锁大型模型智能的秘密》中的一篇。以下是同步查阅文章的链接
https://huggingface.co/blog/JessyTsu1/data-collect-zh
https://datatager.com/blog/data_collect
https://zhuanlan.zhihu.com/p/700613165
ChatGPT问世一年多以来,人们逐渐了解了大模型运行的逻辑,并积极探索其应用场景。我们坚信大模型领域是**以数据为中心,而非以模型为中心**的。因此,在大模型时代的探索中,我们积累了丰富的数据相关经验和见解,并将其汇编成系列文章《**从数据到AGI:解锁大型语言模型秘密**》。基于这些经验,我们还开发了产品**DataTager**,即将推出。
数据在大模型中的作用不言而喻。合理地采集数据,以及选择采集哪些数据,都是非常重要的话题。接下来,我们将详细探讨几种主要的数据采集方法,分析它们的优缺点和实际应用。
一、网络爬虫
当我们在网站上发现合适的数据时,首先想到的就是将其全部下载到本地系统进行模型训练,因此就有了网络爬虫。
概念与原则
- 网络爬虫是一种自动化程序,它能够系统地浏览互联网并从中提取数据。它们通过模拟用户行为来访问网页并检索所需信息。
优点
- 大规模数据获取:网络爬虫可以从大量网站获取海量数据,为模型训练提供丰富的语料库。
- 高频更新:爬虫可以定期抓取最新数据,保证数据的时效性和新鲜度。
传统工具
- Scrapy:一个强大的Python网络爬虫框架,适用于大规模爬取项目。
- 特点:模块化设计,支持多线程,具备强大的抓取和处理能力。
- 应用场景:适用于从电商平台、新闻门户等网站抽取大量数据。
pip install scrapy
cat > myspider.py <<EOF
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://www.zyte.com/blog/']
def parse(self, response):
for title in response.css('.oxy-post-title'):
yield {'title': title.css('::text').get()}
for next_page in response.css('a.next'):
yield response.follow(next_page, self.parse)
EOF
scrapy runspider myspider.py
Beautiful Soup:一个用于解析HTML和XML文档的Python库,适用于小规模数据抓取。
- 特点:易学易用,能够快速解析和处理HTML内容。
- 应用场景:适用于结构简单、数据量较小的网站。
Selenium:一个自动化网页浏览的工具,能够处理动态加载的网页内容。
- 特点:支持JavaScript渲染,可以模拟用户操作。
- 应用场景:适用于需要处理动态内容的网站,如实时数据更新页面。
新AI爬虫
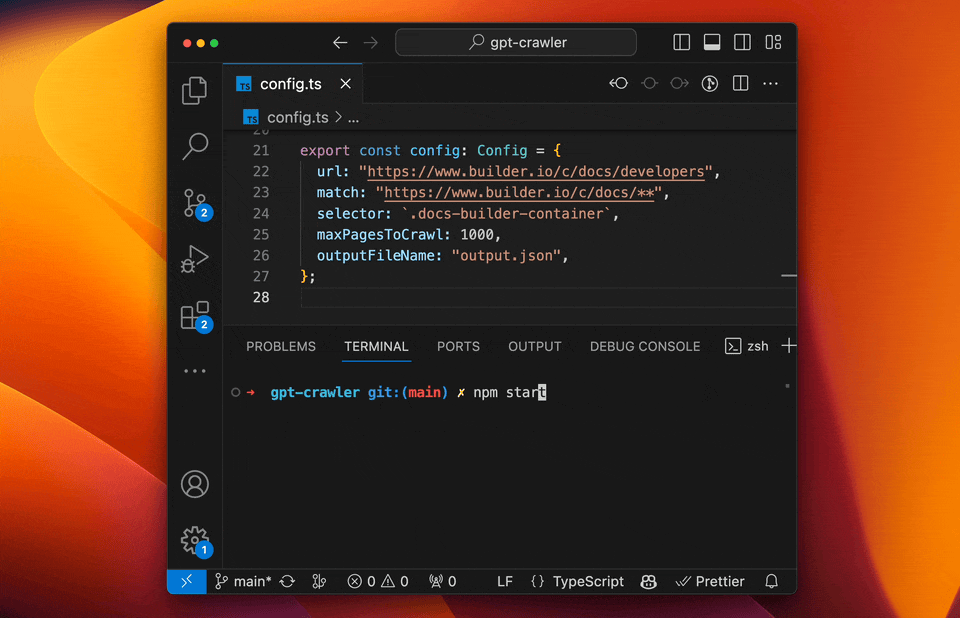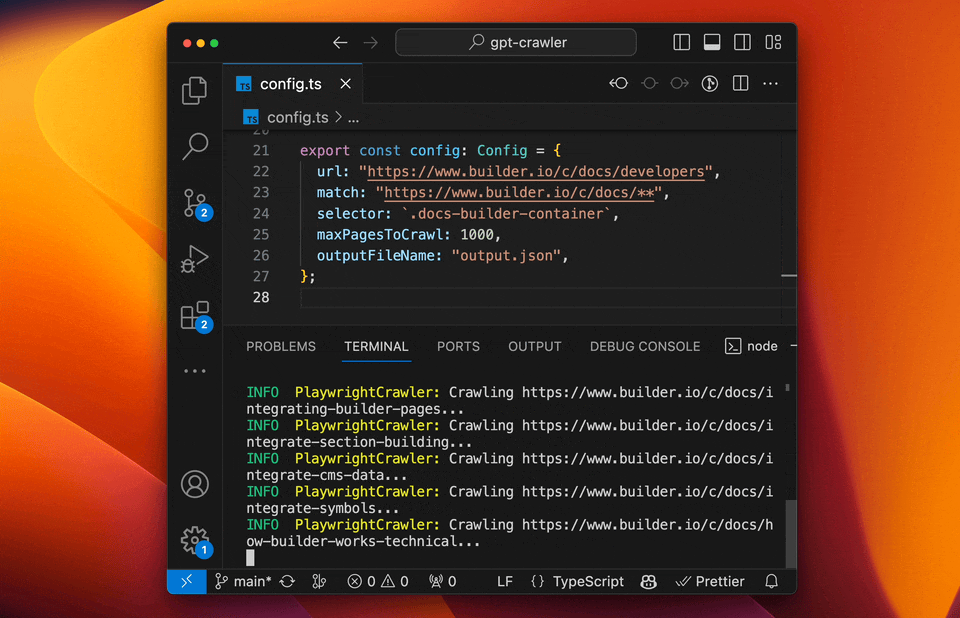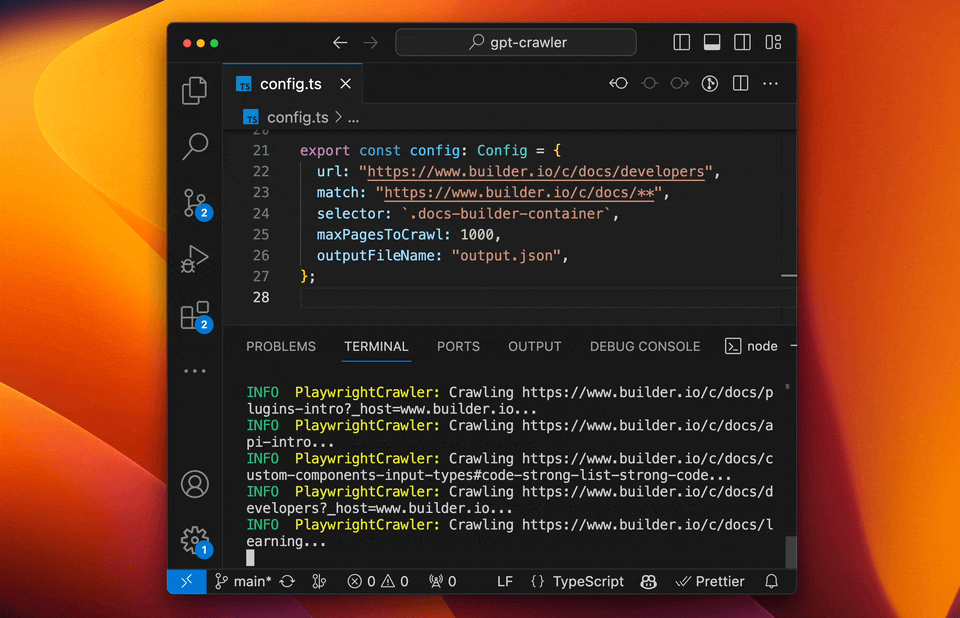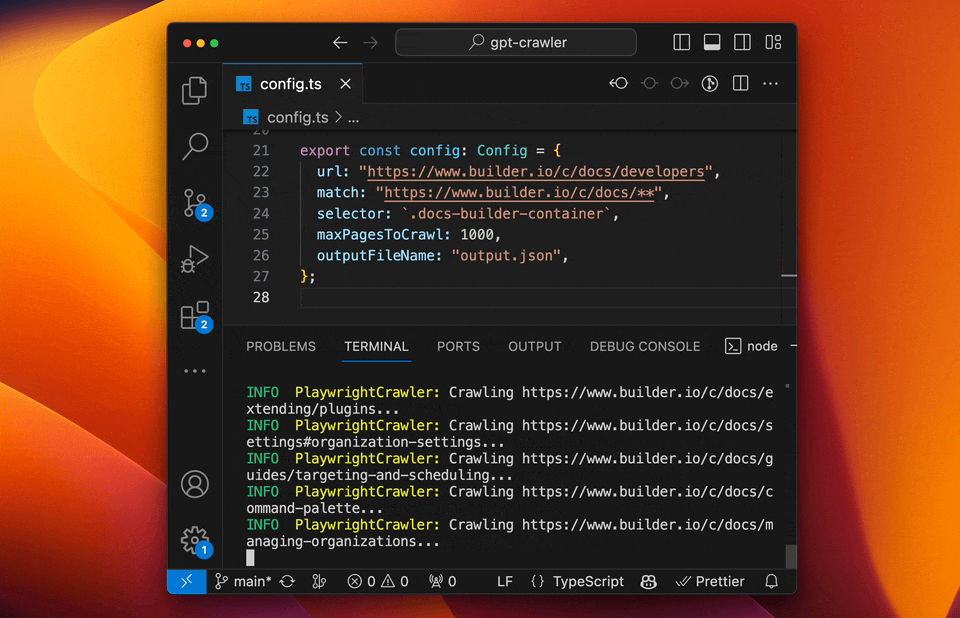
- GPT-Crawler(BuilderIO):一款结合了GPT-3能力的爬虫工具,能够理解和处理复杂的网页结构。
- 特点:强大的自然语言处理能力,自动化程度高,具备语境理解能力。
- 应用场景:适用于结构复杂、需要深度理解的网站。
- 示例:使用GPT-Crawler爬取科技博客,自动分类和摘要内容。
- Scrapegraph-AI(VinciGit00):利用图神经网络进行数据提取,适用于复杂数据整合。
- 特点:处理复杂关系数据,高效整合多来源数据。
- 应用场景:适用于需要从多个数据源提取关系信息的网站。
- 示例:使用Scrapegraph-AI爬取社交网络数据,分析用户关系和互动。

- MarkdownDown:专注于从网页内容生成结构化Markdown文件,方便数据组织和使用。
- 特点:生成结构化文档,方便编辑和分享。
- 应用场景:适用于需要将网页内容转换为可读性文档的网站。
- 示例:使用MarkdownDown爬取技术文档网站,将内容转换为Markdown文件供内部使用。

- Jina Reader:利用AI技术从网页中提取和总结关键信息,提高数据采集效率和准确性。
- 特点:自动化信息提取,智能摘要。
- 应用场景:适用于需要快速获取和总结信息的网站。
- 示例:使用Jina Reader爬取财经新闻网站,提取并总结市场动态。

| 类别 | Scrapy | Beautiful Soup | Selenium | GPT-Crawler | Scrapegraph-AI | MarkdownDown | Jina Reader |
|---|---|---|---|---|---|---|---|
| 概念与原则 | 一个强大的Python网络爬虫框架,适用于大规模爬取项目。 | 一个用于解析HTML和XML文档的Python库,适用于小规模数据抓取。 | 一个自动化网页浏览的工具,能够处理动态加载的网页内容。 | 一个结合了GPT-3能力的爬虫工具,能够理解和处理复杂的网页结构。 | 利用图神经网络进行数据提取,适用于复杂数据整合。 | 专注于从网页内容生成结构化Markdown文件,方便数据组织和使用。 | 利用AI技术从网页中提取和总结关键信息,提高数据采集效率和准确性。 |
| 优点 | 模块化设计,支持多线程,抓取和处理能力强。 | 易学易用,能够快速解析和处理HTML内容。 | 支持JavaScript渲染,可以模拟用户操作。 | 强大的自然语言处理能力,自动化程度高,具备语境理解能力。 | 处理复杂关系数据,高效整合多来源数据。 | 生成结构化文档,方便编辑和分享。 | 自动化信息提取,智能摘要。 |
| 缺点 | 需要编写大量代码,对初学者不友好。 | 处理大规模数据效率低,不支持异步操作。 | 速度慢,资源消耗大。 | 可能需要更多计算资源和前期配置。 | 技术复杂,初期学习成本高。 | 仅适用于提取特定格式的数据。 | 依赖AI模型的准确性和性能。 |
| 用例 | 大规模数据抓取,如电商、新闻门户。 | 结构简单、数据量较小的网站。 | 动态内容网站,如实时数据更新页面。 | 结构复杂、需要深度理解的网站。 | 多数据源数据提取和整合。 | 需要将网页内容转换为可读性文档的网站。 | 需要快速获取和总结信息的网站。 |
| 实际案例 | 使用Scrapy爬取亚马逊产品数据,分析市场趋势。 | 使用Beautiful Soup爬取博客文章内容进行文本分析。 | 使用Selenium爬取动态加载的新闻网站,获取最新新闻文章。 | 使用GPT-Crawler爬取科技博客,自动分类和摘要内容。 | 使用Scrapegraph-AI爬取社交网络数据,分析用户关系和互动。 | 使用MarkdownDown爬取技术文档网站,将内容转换为Markdown文件供内部使用。 | 使用Jina Reader爬取财经新闻网站,提取并总结市场动态。 |
传统爬虫与新AI爬虫的比较
| 类别 | 传统爬虫工具 | 新AI爬虫工具 |
|---|---|---|
| 理解能力 | 依赖预定义的规则和结构,处理复杂网页可能困难。 优点:高效处理简单网页。 缺点:处理复杂或动态内容能力有限,需要人工配置。 |
利用NLP和图神经网络,更好地理解复杂网页结构。 优点:理解能力强,可自动调整抓取策略。 缺点:可能需要更多计算资源和前期配置。 |
| 灵活性 | 需要手动编写代码以应对不同类型网页,灵活性较低。 优点:针对特定任务优化后执行效率高。 缺点:难以适应新类型网站或结构变化。 |
适应性强,可根据网页内容自动调整抓取策略。 优点:灵活应对不同网站和内容结构。 缺点:初期设置和训练时间可能较长。 |
| 效率 | 处理大规模数据效率高,但需要大量前期配置。 优点:高效处理已知结构数据。 缺点:前期配置工作量大,难以应对结构变化。 |
智能分析和自动化流程提高了数据抓取效率和准确性。 优点:自动化程度高,减少人工干预。 缺点:运行时需要更多资源。 |
| 易用性 | 需要编写和维护大量代码,学习曲线陡峭。 优点:技术文档和社区支持丰富。 缺点:对初学者不友好,需要前期配置和持续维护。 |
提供用户友好界面和自动化功能,降低使用门槛。 优点:易于上手,减少编码需求。 缺点:需要理解复杂的AI模型和配置。 |
| 成本 | 开源工具通常免费,但需要大量开发和维护资源。 优点:使用成本低。 缺点:隐藏成本高(如开发时间、维护)。 |
可能需要付费使用或订阅服务,特别是商业解决方案。 优点:降低开发和维护成本。 缺点:初期投入较高。 |
| 适用性 | 适用于结构和规则已知,特别是静态网页的网站。 优点:高效抓取结构稳定的网站。 缺点:对动态或频繁变化的网站适应性差。 |
适用于复杂结构和动态内容的网站,自动适应和调整抓取策略。 优点:适用于各种类型的网站。 缺点:对于简单结构网站可能过于复杂。 |
| 法律与道德 | 需要手动遵守数据隐私法律和网站抓取规则。 优点:法律界限清晰。 缺点:需要大量人工检查和调整。 |
内置合规性检查和隐私保护功能,自动遵循法律和道德标准。 优点:降低法律风险和道德问题。 缺点:依赖工具的合规性。 |
法律与道德考量
a. 数据隐私问题
在进行数据抓取时,数据隐私是一个关键的考虑因素。随着全球对数据隐私的日益关注,各国纷纷出台了相关法律法规,如欧盟的《通用数据保护条例》(GDPR)和美国的《加州消费者隐私法案》(CCPA)。这些法规旨在保护用户隐私,防止未经授权的个人数据收集和使用。
- 遵守隐私法规:在抓取数据时,务必遵守目标国家或地区的隐私法规。例如,避免收集包含个人身份信息(PII)的数据,或在必要时获得用户的明确同意。
- 数据匿名化和去标识化:对收集到的数据进行匿名化和去标识化处理,以保护用户隐私。确保在数据处理和存储过程中,无法通过个人信息追溯到具体个人。
b. 遵守robots.txt协议
robots.txt是一个用于告知搜索引擎和其他爬虫哪些页面可以抓取、哪些页面不能抓取的文本文件。网站管理员通过在网站根目录放置robots.txt文件来定义爬虫的访问规则。
- 阅读并遵循robots.txt文件:在抓取数据之前,爬虫应首先读取目标网站的robots.txt文件,并遵守其中定义的抓取规则。这不仅有助于避免给目标网站带来负担,也是对网站管理员意愿的尊重。
- 负载管理:合理设置爬取频率,避免对目标网站服务器造成过大负载。利用爬虫框架中的延迟设置功能,控制抓取速度,最大程度减少对网站的影响。
c. 如何规避其他AI公司的爬虫
网站https://darkvisitors.com/列出了各大AI公司爬虫的User Agent,并告知你如何在robots.txt文件中屏蔽这些爬虫。
实际应用
五年前,我在新浪和搜狐的时候,我们有一个部门负责一个庞大的分布式爬虫系统,其中包含了爬虫可能遇到的几乎所有问题。因此,我在这方面也有着丰富的经验,在此分享,希望能给大家一些启发。
爬虫的核心在于**模拟人类所有动作,然后自动化**。
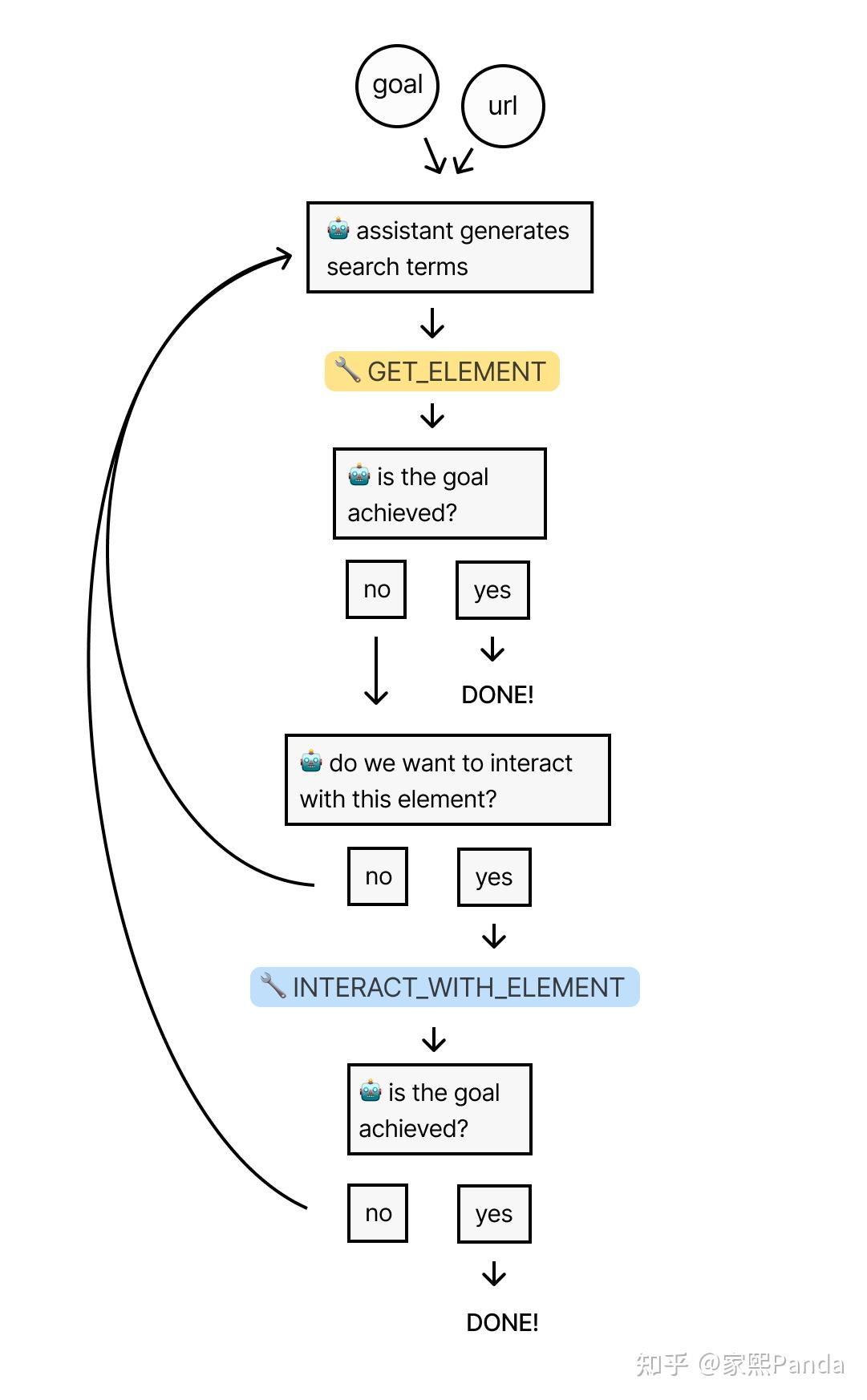
1. 如何构建一个通用AI爬虫
(本节代码可在此查看:https://github.com/PandaVT/DataTager/blob/main/blog_code/ai_crawler.py)
在代码工程中,有一个原则:抽象。
为什么要谈抽象?
构建一个通用AI爬虫听起来像是一项宏大且技术含量高的任务,让人感到无从下手。那么,我们可以先放下这个概念上的难度,来思考以下解决问题的逻辑
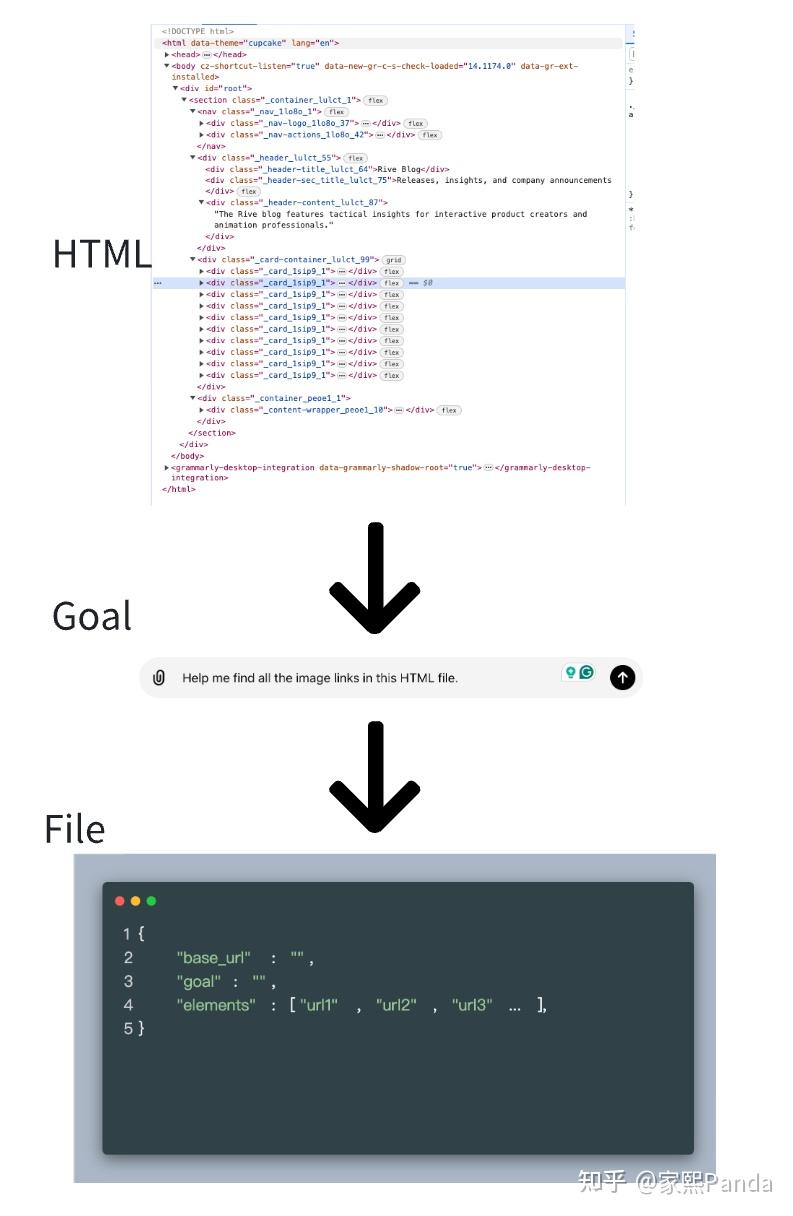
a. 这个问题应该有哪些输入和输出?
经过一番思考,很明显
input: target website URL, content to scrape
output: file containing the scraped content
这个初步的定义帮助我们思考
b. 我们能从输入直接得到输出吗?
这听起来很有挑战性,因为没有直接的方法能将这种输入直接转换为输出,中间还需要一些其他复杂的步骤。那么接下来的问题是
c. 中间有哪些步骤,每个步骤的输入和输出是什么?
从这里,我们可以勾勒出一个清晰的逻辑链条
step1: fetch_html.py
input: target website URL
output: HTML content of the target website
step2: parse_content.py
input: HTML content of the target website + content to scrape
output: Specific data parsed (such as text, images, etc.)
step3: process_data.py
input: Specific data parsed (such as text, images, etc.)
output: Further processing of the data, such as text cleaning, format standardization, etc.
step4: save_data.py
input: Processed data
output: Saved file
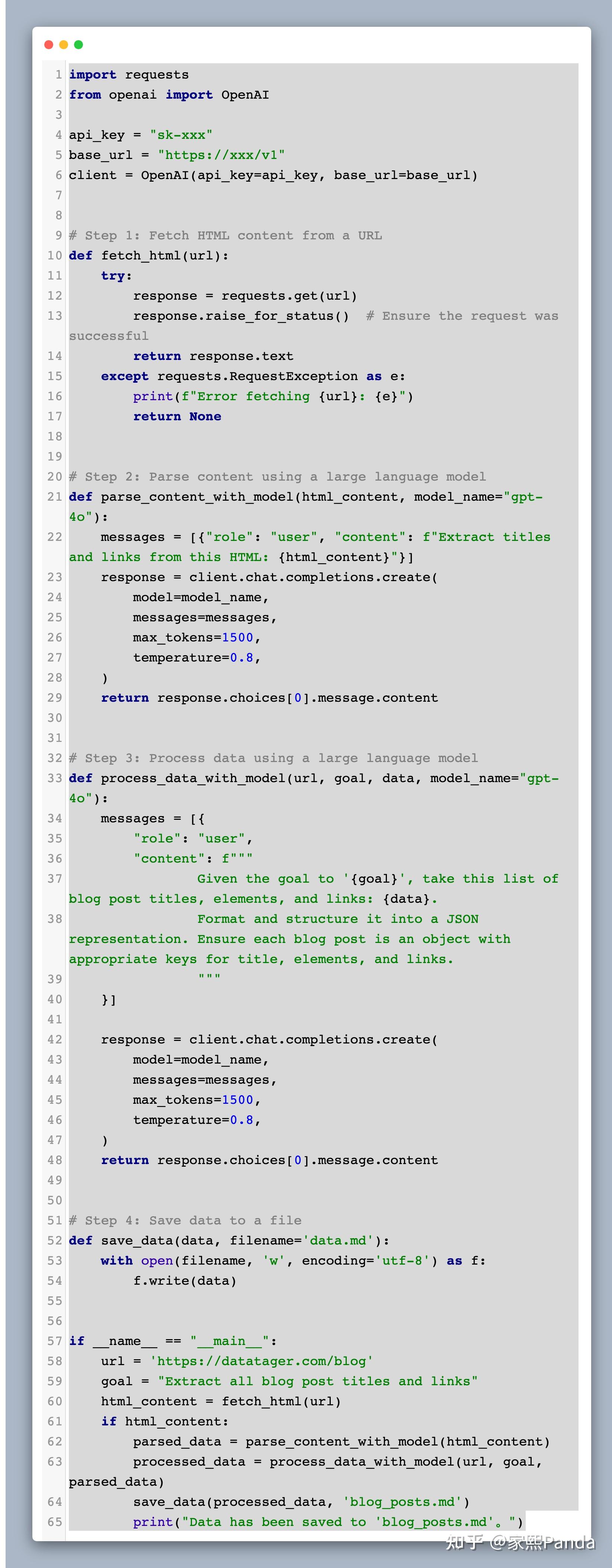
以https://datatager.com/blog为例,1-4步是如何执行的呢?
第1步:fetch_html.py
首先,我们需要一个函数,它能够从给定的URL获取HTML内容。
import requests
def fetch_html(url):
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"Error fetching {url}: {e}")
return None
第2步:parse_content.py
接下来,解析HTML内容,找出所有博客文章的标题和链接。
from bs4 import BeautifulSoup
def parse_content(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
articles = soup.find_all('h2', class_='entry-title') # Assume titles are within <h2 class="entry-title"> tags
data = []
for article in articles:
title = article.find('a').get_text() # Extract the text of the title
link = article.find('a')['href'] # Extract the link
data.append({'title': title, 'link': link})
return data
第3步:process_data.py
这一步可以用于进一步处理数据,例如简化或格式化。在这个例子中,我们可能不需要复杂的处理。
def clean_text(text):
# Simple text cleaning logic
cleaned_text = text.replace('\n', ' ').strip()
return cleaned_text
def process_data(data):
return [clean_text(text) for text in data]
第4步:save_data.py
最后,我们需要一个函数来将数据保存到文件中。
import json
def save_data(data, filename='data.json'):
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=4, ensure_ascii=False)
主函数
最后,我们可以将这些步骤组合起来,运行完整的爬虫。
if name == "__main__":
url = 'https://datatager.com/blog'
html_content = fetch_html(url)
if html_content:
parsed_data = parse_content(html_content)
processed_data = process_data(parsed_data)
save_data(processed_data, 'blog_posts.json')
print("Data has been saved to 'blog_posts.json'。")
AI能增强什么?
所以当我们抓取https://datatager.com/blog时,本质上我们是在存储网站的HTML,然后解析它以提取我们想要的内容。
以前,在第2步中,我们使用XPath、CSS选择器和正则表达式从HTML中提取所需元素。
在第3步中,数据处理涉及简单的替换函数、正则表达式或基本的模型,如BERT或word2vec。
这两个步骤本质上都涉及与语言理解相关的任务,现在我们可以利用LLMs(大型语言模型)自然的、强大的语言理解能力来完成这些任务。
当然,这里缺少许多细节,一个实际的、可操作的项目将需要更多。然而,上述三步抽象方法可以有效解决复杂的逻辑工程问题。这也形成了通用AI爬虫的原型。
这里是本节的基本代码,它已经可以运行并取得不错的结果。感兴趣的读者可以基于此代码原型进行扩展:https://github.com/PandaVT/DataTager/blob/main/blog_code/ai_crawler.py
2. 传统爬虫与Scrapy的使用(以学校数据库为例)
PS:由于第一部分已经详细介绍了爬虫流程,以下章节将只做简要介绍。
详细代码请访问:https://github.com/JessyTsu1/Primary_students
代码结构
code文件夹:包含初步且简单的分析代码。data文件夹:包含最终数据和处理脚本。Multi_stu文件夹:使用Scrapy进行爬取。
简要编写爬虫以理解需求和方法
- 详情页URL:https://school.wjszx.com.cn/senior/list.html
- 每页URL:https://school.wjszx.com.cn/senior/introduce-2.html
- 目录页的代码,每个标签都没有标题,这可能会导致后续错误,因此不建议使用目录抓取。
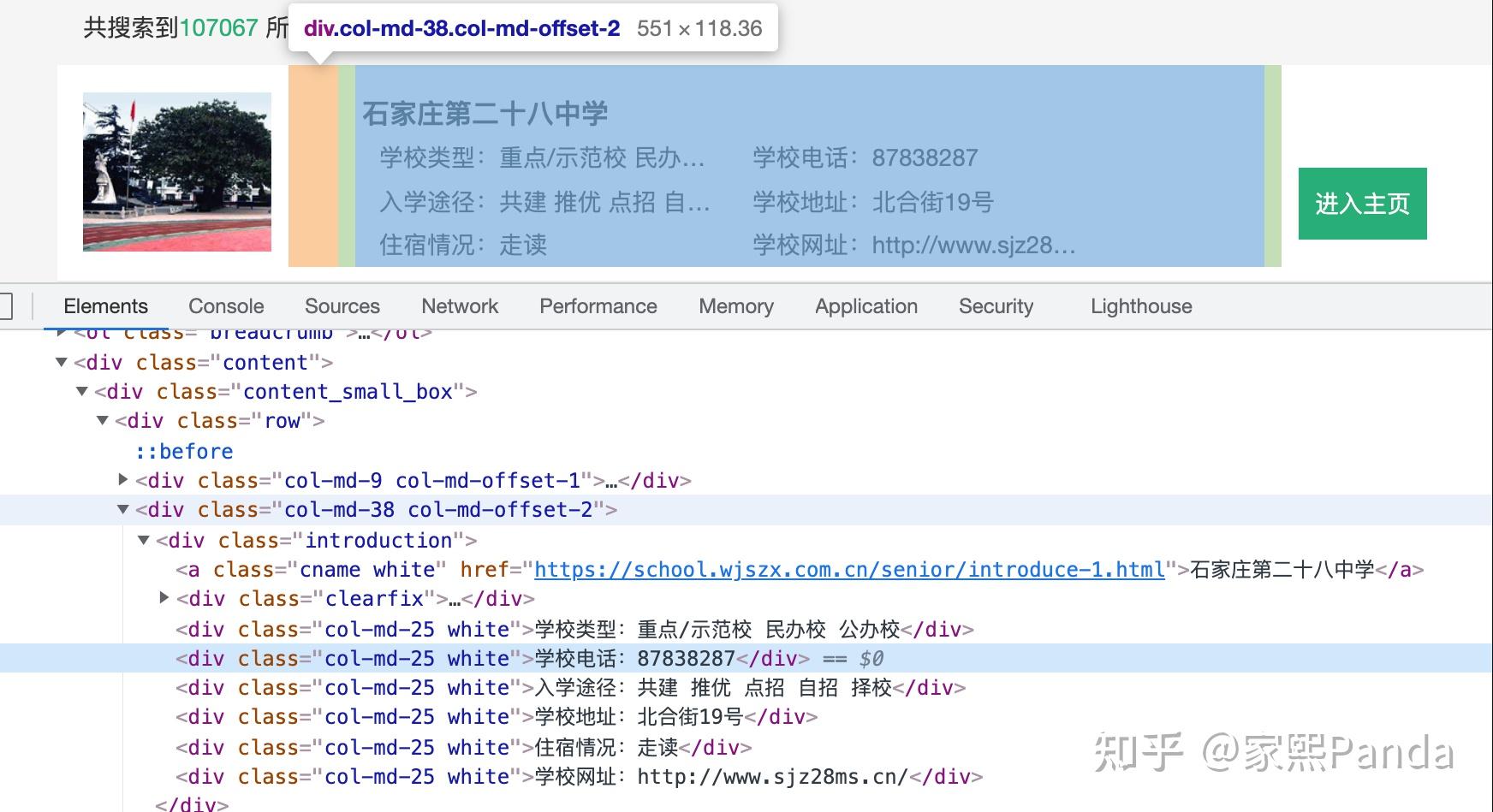
- 详情页的结构:设计相当简陋……每个字段的标题直接赋值为变量,所以直接抓取标题名称即可,无需进一步处理字段。
基于以上代码分析,我们可能会遇到以下问题
- 编码问题可能导致无法检索URL。
- 直接抓取的数据应为字典类型;移除[]将其转换为字段。
- 没有信息的字段可能会导致bug。
首先,尝试简单抓取并计时,看看暴力抓取是否可行
for i in range(10000)
url = “https://school.wjszx.com.cn/senior/introduce-{}.html”.format(i)
spider(url)
class spider(url):
## spider
return name, phone, address, url(or return info)
class saving(info):
# Open an existing Excel file
# Open a sheet
# In a for loop, store a field in a row for a fixed column
# Close Excel
分析与改进
- 由于每次抓取页面后打开、存储和关闭Excel都涉及I/O密集型操作,使用多线程可以加速这一过程。
- 由于Python的GIL(全局解释器锁),多线程可能比较麻烦。而且,在这种I/O不大会阻塞的情况下,使用协程可能会更快。
- 访问时记得伪装请求头。对于大量数据,编写多个请求头并随机选择。同样,IP也使用IP池。
- 考虑到目标网站的简单性,假设反爬机制不多。隐藏请求头并在夜间抓取应该能最大程度减少问题。
想更快?使用Scrapy爬虫框架
这里是一个简单的使用介绍
使用pip安装后,在同一目录下
scrapy startproject stu
这将创建一个Scrapy项目目录,其中包含一个名为spiders的文件夹,你可以在其中编写爬虫。
yield大致等同于return。
settings.py中的几项设置
FEED_EXPORT_ENCODING = 'utf-8' ## Change to utf-8
ROBOTSTXT_OBEY = True
CONCURRENT_REQUESTS = 100
CONCURRENT_REQUESTS_PER_DOMAIN = 100
CONCURRENT_REQUESTS_PER_IP = 100
#DOWNLOAD_DELAY = 3 ## Set download delays for more advanced websites, to counteract scraping defenses
COOKIES_ENABLED = False
开始爬取
scrapy crawl stu
开始爬取并将结果保存为stu.json
scrapy crawl stu -o stu.json
3. Google学术爬虫和视频爬虫演示版:
https://github.com/JessyTsu1/google_scholar_spider
https://github.com/JessyTsu1/DouYinSpider
4. 电商平台数据采集
电商平台数据采集是典型的应用场景。通过抓取产品信息和用户评论,可以进行市场分析和消费者行为研究。
- 工具选择:使用Scrapy或GPT-Crawler抓取产品信息。
- 抓取数据:包括产品名称、价格、描述、用户评论等。
- 数据用途:分析市场趋势,了解竞争对手定价策略,研究消费者购买行为和偏好,为企业提供决策支持。
- 可能案例:某电商公司使用Scrapy抓取多个竞争对手网站的产品信息,结合内部销售数据进行市场分析,调整自身定价策略,提升市场竞争力。
5. 新闻网站数据抓取
新闻网站数据抓取主要是为了获取最新的新闻内容,训练新闻分类模型或生成模型。
- 工具选择:使用Selenium或Jina Reader获取最新新闻。
- 抓取数据:新闻标题、正文、发布时间、作者等。
- 数据用途:训练新闻分类模型,自动生成新闻摘要,进行情感分析。
- 可能案例:某媒体公司使用Jina Reader实时抓取多个新闻网站的新闻,自动生成每日新闻摘要,并发布到自家网站,提高用户粘性和流量。
6. 社交网络数据分析
社交网络数据分析涉及抓取和分析用户关系和互动,以提供对社交行为的洞察。
- 工具选择:使用Scrapegraph-AI抓取社交网络数据。
- 抓取数据:用户关系、互动频率、帖子内容、点赞和评论数据等。
- 数据用途:识别社交网络中的关键意见领袖(KOL),研究用户互动模式,制定社交营销策略。
- 可能案例:某市场研究公司使用Scrapegraph-AI抓取社交平台的用户互动数据,分析关键意见领袖的影响力和粉丝互动情况,为客户制定精准的社交营销策略,提升品牌曝光度和用户参与度。
这些实际案例展示了不同爬虫工具在各种应用场景下的操作方式和效果,有助于更好地理解如何选择和使用爬虫工具进行有效的数据采集。
二、公开数据集
在科学研究中,由于各种原因,研究人员常常无法通过网络抓取直接获取数据,且该领域通常有固定的基准数据集可供研究人员针对特定目标进行优化。在这种情况下,开放数据集成为研究人员使用和基准测试的关键资源。
公开数据集是大型语言模型训练的重要数据来源之一,它们来源于各种研究机构、政府机构和开源社区。在选择和评估公开数据集时,需要考虑数据集的质量、规模和多样性,以确保模型训练的有效性。
来源与类型
公开数据集可以从以下几种来源获取
研究机构:许多大学和研究机构发布了大量的优质研究数据集,通常用于学术研究和实验。例如,斯坦福大学和麻省理工学院等机构经常发布机器学习和人工智能领域的数据集。
政府机构:政府部门提供了广泛的公共数据集,涵盖经济、社会、环境等多个领域,可用于各种分析和研究。例如,美国政府的Data.gov门户网站提供了丰富的公共数据资源。
开源社区:开源社区和项目贡献了大量数据集,这些数据集通常由开发者和研究人员共同维护和更新。例如,GitHub、ModelScope和HuggingFace。
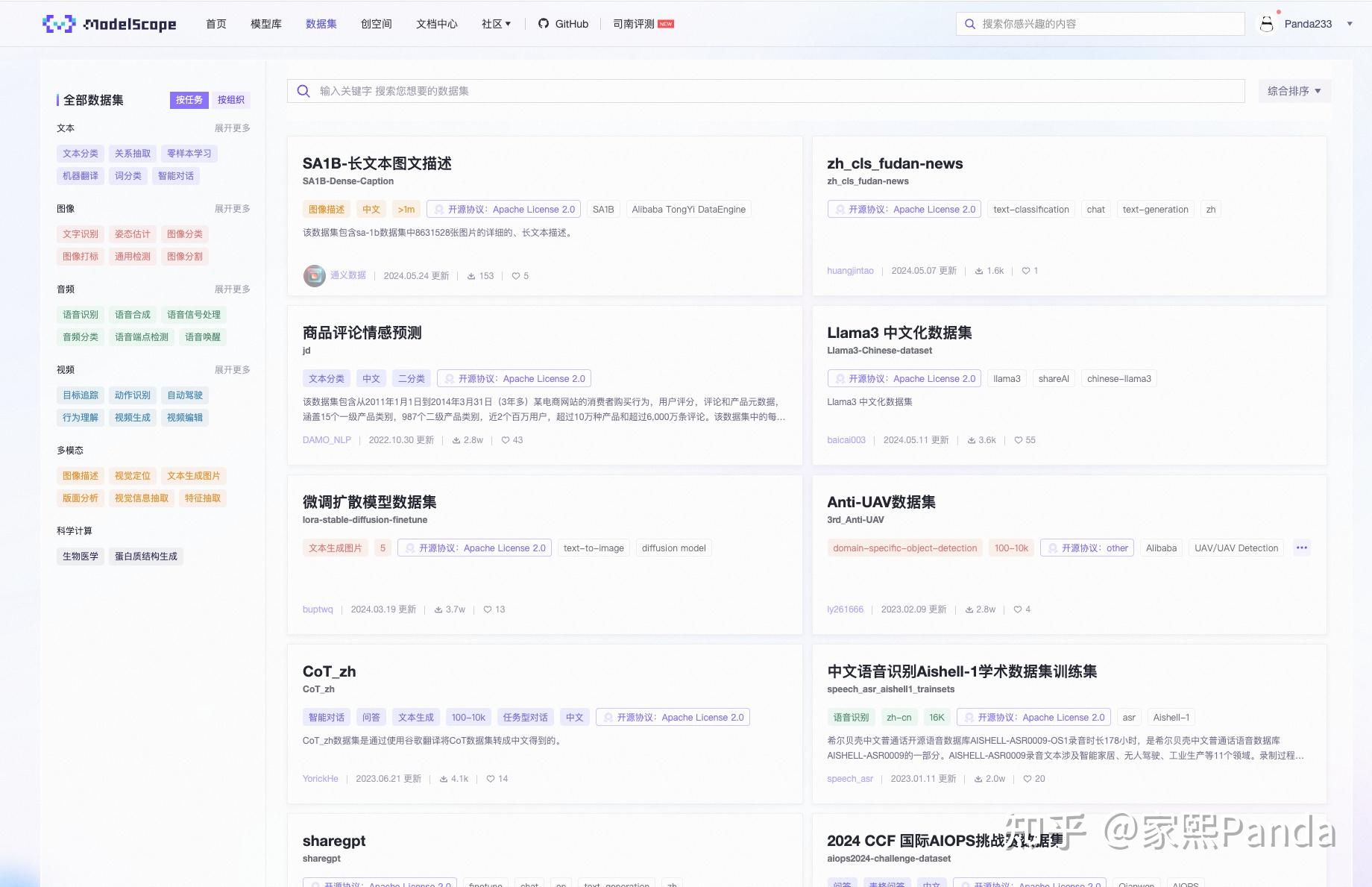
评估与选择标准
在选择公开数据集时,以下标准是关键的考量因素
- 数据集质量:数据的准确性和完整性是数据集质量的主要指标。高质量的数据集应该经过严格的数据清洗和验证,以确保其可靠性。
- 数据集规模:数据集的规模影响模型训练的效果。更大的数据集通常提供更多的训练样本,从而提高模型的泛化能力。
- 数据集多样性:多样性对于确保模型能够处理不同场景和任务至关重要。一个多样化的数据集应包含各种类型的数据样本,涵盖广泛的可能输入。
常用平台与资源
以下是一些常用的公共数据集平台和资源
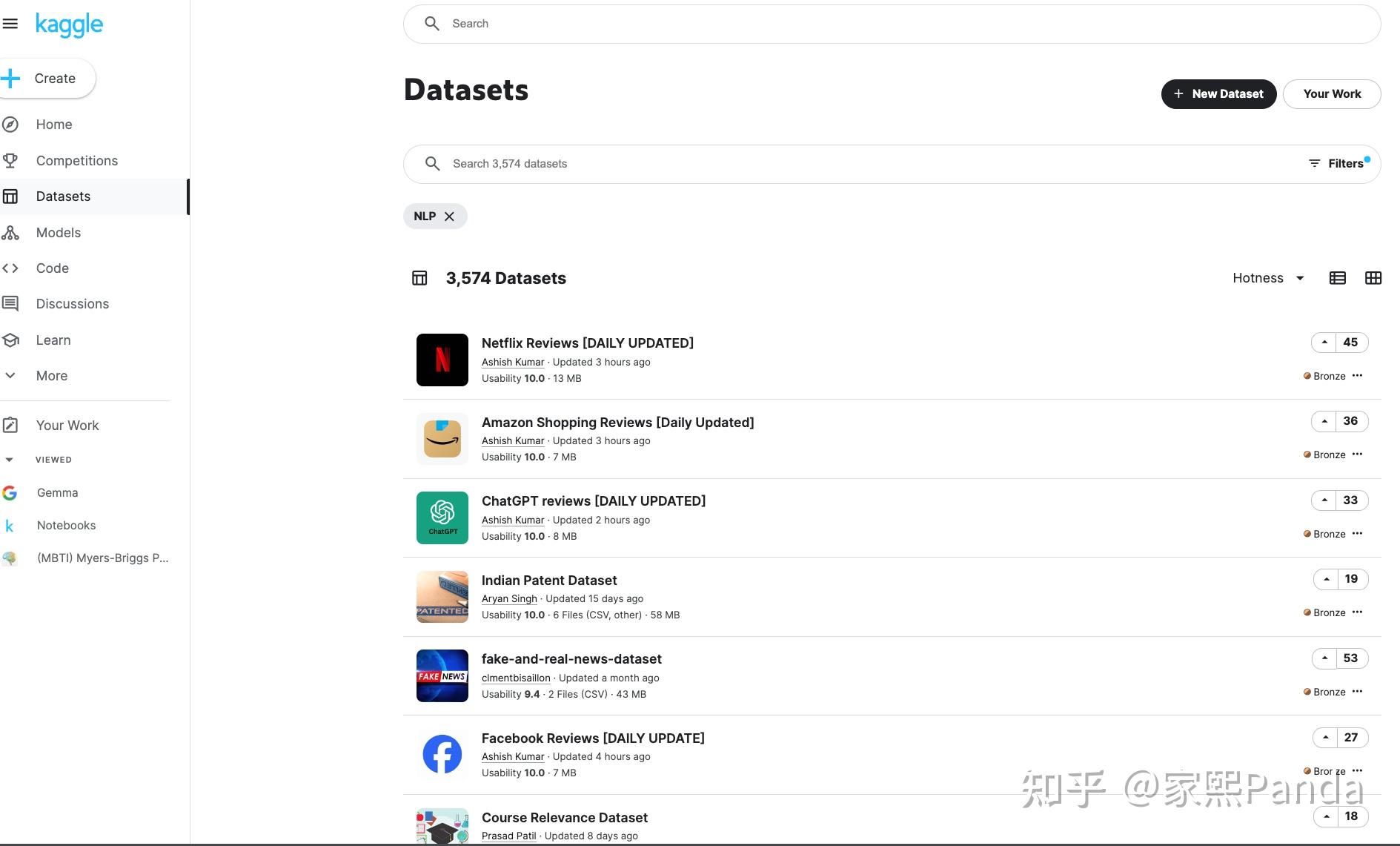
- Kaggle:Kaggle是一个数据科学竞赛平台,提供了众多高质量的公共数据集。用户可以在Kaggle上找到机器学习和数据科学项目中常用的数据集,并参与社区讨论和竞赛。
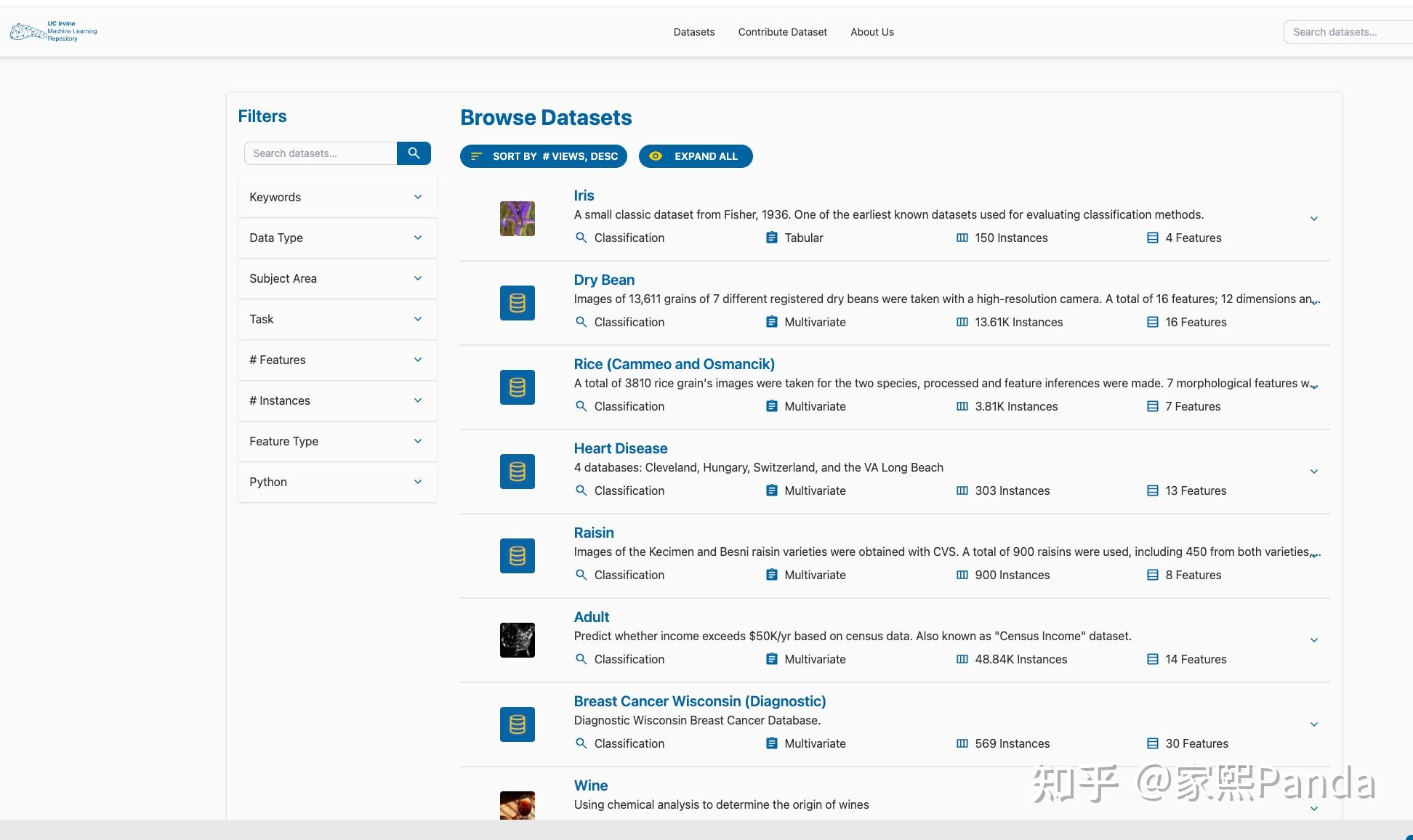
- UCI机器学习仓库:UCI机器学习仓库是一个历史悠久的资源,包含了各种类型的机器学习数据集,适用于训练和测试各种算法和模型。
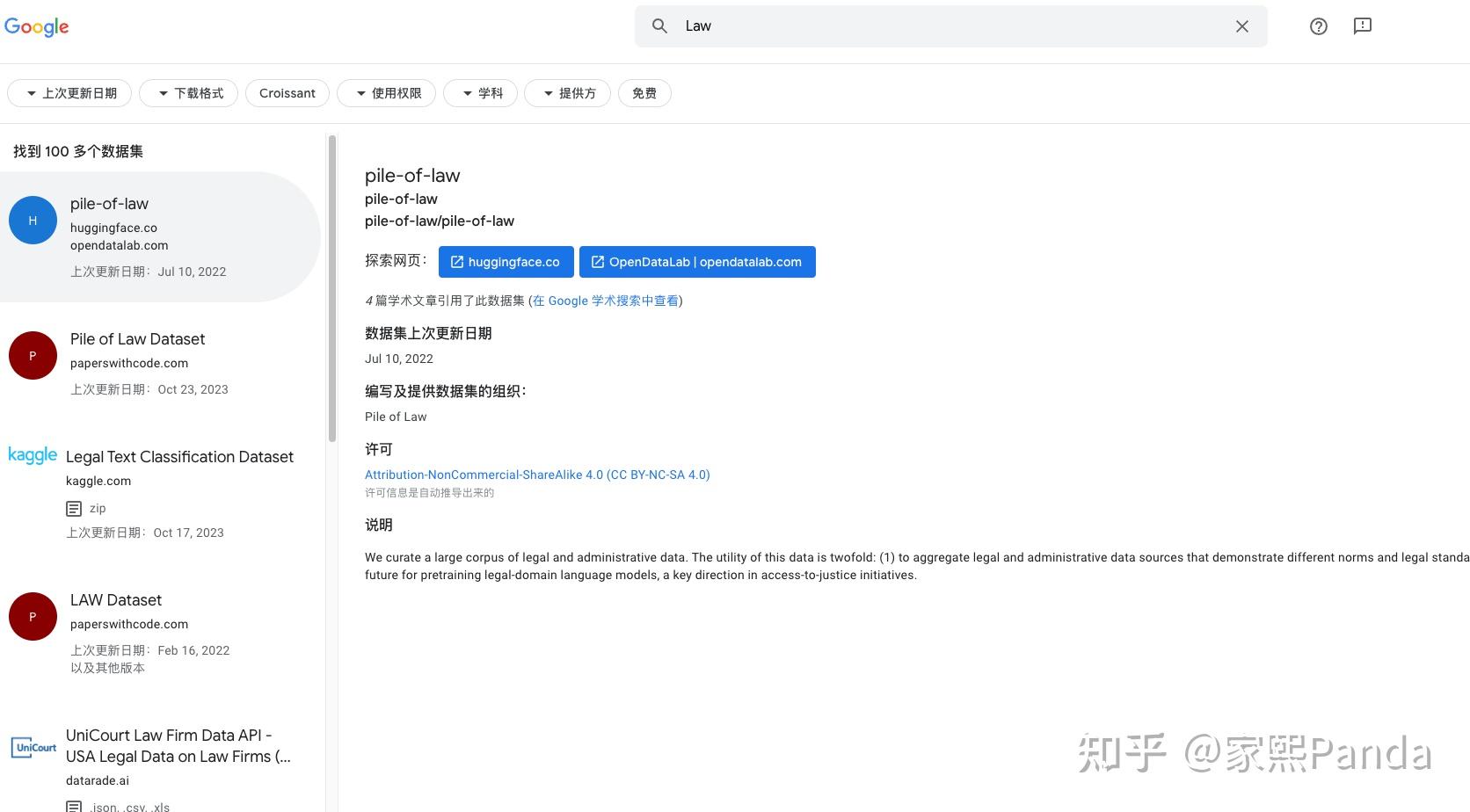
- Google Dataset Search:Google Dataset Search 是一个专门用于搜索公共数据集的工具,让用户能够轻松查找和访问涵盖广泛领域和应用场景的各类公共数据集。
实际应用案例
公共数据集在具体项目中的应用能够显著提升数据收集和模型训练的效率与效果。以下是一些实际应用案例
自然语言处理任务:在自然语言处理(NLP)任务中,可以使用 Kaggle 上的文本数据集来训练语言模型。例如,利用 Quora Question Pairs 数据集训练问答系统,通过识别和分类相似问题来提高回答的准确性。
计算机视觉任务:在计算机视觉领域,可以使用 UCI Machine Learning Repository 的图像数据集来训练图像分类或目标检测模型。例如,使用 CIFAR-10 数据集训练图像分类模型,用于识别和分类日常生活中的物体。
- 社会经济分析:政府机构提供的公共数据集可以用于社会经济分析和研究。例如,利用 Data.gov 上的普查数据进行社会经济状况的分析和预测,以协助政府和企业进行决策和政策制定。
这些实际案例展示了公共数据集在各种项目中的广泛应用和重要性。合理选择和利用公共数据集,能够有效地提升模型训练效果和应用价值。
大语言模型预训练数据集
在预训练阶段,LLM从海量的无标签文本数据中学习广泛的知识,并将这些知识存储在模型的参数中。这使得LLM具备了一定的语言理解和生成能力。
网页文本,学术资料、书籍、各领域文本等,如法律文书、财务年报、医学教材等,是预训练语料来源。
通常将预训练数据集分为两类:通用数据集和领域特定数据集。
- 通用预训练数据集通常包括来自互联网的文本内容,如新闻、社交媒体、百科全书等。它们旨在提供通用语言知识和数据资源,以支持各种NLP任务。
- 领域特定预训练数据集旨在为LLMs提供专业知识,如法律文档、各学科教科书等。
值得关注的是,将数学和代码数据纳入预训练,可显著增强模型的推理能力。
书籍数据
书籍是未经标注的预训练数据的丰富来源。若考虑将书籍作为预训练数据,则不可避免地需要研究书籍分类,以便我们能够轻松选择相关书籍数据,从而强化模型在特定领域的能力。
参考阮一峰老师的文章:https://www.ruanyifeng.com/blog/2007/01/classification.html
书籍可分为
1. 中国图书馆分类法(第四版)(CLC)
A 马克思主义、列宁主义、毛泽东思想、邓小平理论 B 哲学、宗教 C 社会科学总论 D 政治、法律 F 经济 G 文化、科学、教育、体育 H 语言、文字 I 文学 J 艺术 K 历史、地理 N 自然科学总论 O 数理科学和化学 Q 生物科学 R 医药、卫生 S 农业科学 T 工业技术 U 交通运输 V 航空、航天 X 环境科学、安全科学 Z 综合性图书
2. 国会图书馆分类法(LCC)
A - GENERAL WORKS B - PHILOSOPHY. PSYCHOLOGY. RELIGION C - AUXILIARY SCIENCES OF HISTORY D - HISTORY (GENERAL) AND HISTORY OF EUROPE E - HISTORY: AMERICA F - HISTORY: AMERICA G - GEOGRAPHY. ANTHROPOLOGY. RECREATION H - SOCIAL SCIENCES J - POLITICAL SCIENCE K - LAW L - EDUCATION M - MUSIC AND BOOKS ON MUSIC N - FINE ARTS P - LANGUAGE AND LITERATURE Q - SCIENCE R - MEDICINE S - AGRICULTURE T - TECHNOLOGY U - MILITARY SCIENCE V - NAVAL SCIENCE Z - BIBLIOGRAPHY. LIBRARY SCIENCE. INFORMATION RESOURCES (GENERAL)
3. 杜威十进制分类法(DDC)
000 Generalities 100 Philosophy & psychology 200 Religion 300 Social sciences 400 Language 500 Natural sciences & mathematics 600 Technology (Applied sciences) 700 The arts 800 Literature & rhetoric 900 Geography & history
学术和互联网资源
- arXiv10:收集物理学、数学、计算机科学、生物学、量化金融等领域的预印本。这不仅提供了高质量的学术知识,还能使模型掌握论文的LATEX格式。
- S2ORC (Lo et al., 2020) 涵盖了所有学科的英文学术论文。它包含大量的元数据、摘要、参考文献列表和结构化的全文。
- WikiText:该数据集基于维基百科,专为语言建模任务设计。WikiText 数据集包含高质量的文章文本,用于测试语言建模算法。
- Common Crawl:一个庞大的网络数据集,每月抓取超过二十亿个网页。它被用于训练一些最大的语言模型,例如 OpenAI 的 GPT 系列,并支持各种其他 NLP 任务。
- BookCorpus:包含从未出版书籍中收集的文本,广泛用于自然语言处理研究。它有助于模型理解更长的文本依赖关系。
- Pushshift.io Reddit Dataset:由 Pushshift 提供,此数据集用于各种 NLP 研究,包括语言模型预训练。它包含大量来自 Reddit 的帖子和评论。
- PubMed Central:在近五百万份生物医学出版物的开放获取中发挥作用。
- The Pile:由 EleutherAI 开发,是一个用于训练语言模型的大型数据集,它包含各种数据源,如 GitHub、PubMed、ArXiv 等。该数据集旨在为语言模型训练提供多样化和广泛的文本。
- MNBVC:来自渔社社区的大规模中文语料库,对标ChatGPT训练的40T数据,目前已达33065GB(截至2024.5.30)。
大语言模型指令微调数据集
指令微调数据集用于对预训练的大语言模型(LLMs)进行进一步的微调,使模型能够更好地理解和遵循人类指令。这一过程有助于弥合LLMs的下一个词预测目标与遵循人类指令的目标之间的差距,从而提升LLMs的能力和可控性。
SFT数据集根据指令类型可划分为两类:问答咨询数据集和Agent子任务数据集。
问答咨询数据集:
这类数据集没有明确的指令,但要求模型进行咨询式的回应,定义为问答咨询数据集,如
{
"instruction": "",
"input": "I got hit by a car when I went out today, what should I do?",
"output": """I'm very sorry to hear that, and I hope you weren't seriously injured. Here are some steps you might need to consider:
Seek medical help: Even if you feel that the injuries are not severe, sometimes internal injuries may not be immediately apparent. It's best to go to a hospital or clinic for a comprehensive examination.
Call the police: If you haven't already, you should contact the local police immediately so they can come to the scene and make a record. This is very important for any possible claims or legal procedures later.
Document evidence: If possible, take photos to document the accident scene, vehicles, injuries, etc. If there are witnesses, try to get their contact information.
Contact your insurance company: Notify your insurance company about the accident as soon as possible and follow their guidance for the next steps.
Legal consultation: Consider consulting a lawyer to understand your rights and possible compensation.
I hope you recover quickly, and if you need further help or information, let me know anytime!"""
}
这类数据集不要求模型完成具体的任务,而仅仅是学习输出的逻辑和风格。值得一提的是,将模型在大量领域特定咨询数据集上进行训练,如医疗咨询,会让模型的回答具备医学模型的特点。
Agent子任务数据集
通过具体的指令,涉及到预设任务类型的数据集,让模型学习各个任务的表达,定义为 Agent子任务数据集,例如
{
"instruction": "You are an experienced multilingual translator, please translate the following text into ancient Chinese poetry, ensuring faithfulness, expressiveness, and elegance",
"input": "Of course I still love you",
"output":"纵使万里云舒,吾心犹存"
},
//Tips: from Elon Musk, SpaceX
{
"instruction": "Please ask further questions regarding the following legal issue to obtain more relevant information:",
"input": "My father married my stepmother and they had a son. When my father fell ill, he left all his property to his son. My stepmother says that since we both cared for the elderly together, how can she protect her rights?",
"output": "1. Do you have any written or verbal agreements with your father and stepmother regarding the distribution of property and the care of the elderly?\n2. Do you have evidence that you contributed to the care of the elderly, such as paying for medical expenses or providing daily support?\n3. Do you have any other evidence that suggests an unfair distribution of property by your father, such as a will or property transfer records?\n4. Have you communicated or negotiated with your stepmother to resolve this issue?\n5. Have you consulted a lawyer or other legal professional to understand your rights and possible ways to protect them?"
},
{
"instruction": "Identify the legal key terms from the following information:",
"input": "Liability determination for losses caused by unauthorized transactions on a stolen bank card",
"output": "Bank card disputes; counterfeit card transactions; liability allocation; civil litigation; contract;"
},
InstructGPT-sft (Ouyang et al., 2022) 将一部分数据集分为了十个类别,包括生成、开放式问答、头脑风暴、聊天、重写、摘要、分类、其他、封闭式问答和提取。
BELLE train 3.5M CN (BELLE Group, 2023) 在此基础上,增加了角色扮演、数学、翻译、编码和无害等类别,同时删除了聊天和其他类别。
Firefly (Yang, 2023) 进一步细化了指令类别,覆盖了23个类别。例如,故事生成和歌词生成等子类别归属于原有的“生成”类别。考虑到当前的分类现状并仅关注单轮对话指令,指令大致分为15个类别:推理、数学、头脑风暴、封闭式问答、开放式问答、编码、提取、生成、重写、摘要、翻译、角色扮演、社会规范和其他。
观察上述任务类别,我们可以得出一个有趣的结论:训练领域大模型的关键,在于尽可能细化Agent子任务数据集,再选择一个能力不错的通用模型,配合领域微调(SFT)数据集,就可以打造一个看似能够解决该领域所有问题的领域大模型。
DataTager是一款旨在解决SFT数据集创建的产品。
三、合作伙伴数据
在数据收集过程中,与合作伙伴协作是一种获取高质量、定制化数据的有效途径。此类合作可以为特定项目提供高度相关的样本,确保数据的质量和可靠性。
合作优势
与合作伙伴协作进行数据收集具有以下几个关键优势
- 定制化数据:合作伙伴可以提供根据特定需求定制的数据集。这些数据往往更符合项目的实际需求,从而提高模型的训练和应用效果。
- 数据质量保障:合作伙伴通常具备专业的数据收集和处理能力,能够提供经过严格验证和清洗的高质量数据。这有助于减少数据中的噪声和错误,提升模型的准确性和可靠性。
选择合作伙伴的标准
在选择合作伙伴时,应考虑以下标准,以确保合作顺利并达到预期效果
- 声誉:选择声誉良好的合作伙伴,他们更有可能保证数据质量和合作的可靠性。
- 数据相关性:合作伙伴提供的数据应与项目需求高度相关。
- 技术能力:合作伙伴在数据收集、处理和管理方面的技术能力至关重要。
案例分析
以下是一些合作伙伴数据收集的成功案例,以及其中遇到的挑战和解决方案
- 成功合作的具体案例
- 在医疗保健领域,研究机构与大型医院合作,获取患者数据以训练疾病预测模型。通过合作,这些机构获得了真实的医疗数据,显著提高了模型预测的准确性。
- 在电子商务领域,平台与供应商合作,共享产品销售数据和用户行为数据。通过这种合作,电商平台更好地了解市场需求和用户偏好,优化了产品推荐和营销策略。
- 面临的挑战与解决方案
- 数据隐私与安全:在合作过程中,数据隐私和安全是首要考虑的问题。为解决这一问题,采用数据匿名化和加密技术,确保敏感信息不被泄露。此外,双方签订严格的保密协议,明确数据使用和保护的责任和义务。
- 数据格式与兼容性:不同合作伙伴之间的数据格式可能存在差异,导致数据整合困难。为解决这一问题,采用标准化数据格式和接口,确保数据收集和处理过程中的兼容性和一致性。
- 沟通与协调:在合作过程中,保持良好的沟通和协调至关重要,以确保项目目标和数据需求的一致性。定期召开会议和交流,及时解决出现的问题和挑战,是成功合作的保障。
“信任度”
“信任度”一词之所以加引号,是因为这是我自创业以来的个人感受而创造的名称。在法律、医疗、教育、金融等领域,即便我们旨在打造面向普罗大众的消费级产品,用户在咨询后仍会关注咨询回应是否获得了知名组织和机构的背书。来自协和医院、红圈所、罗翔、魔方等受尊敬机构的背书能显著提升用户信任。我将此称为“信任度”。
- 提升信任度的必要性:为了提高用户信任度,与这些知名机构合作,获取其数据和认可至关重要。即使是消费级产品,由于行业性质,我们也需要争取“信任度”。因此,我们不可避免地需要与大企业(Big B)和政府机构(Big G)打交道。
通过与合作伙伴紧密协作,可以获取高质量、定制化的数据,显著提升模型的训练效果和实际应用价值。此外,与知名机构的合作还能增强用户对产品的信任度(“信任度”),为消费级产品在市场上的成功奠定坚实基础。在选择合作伙伴和解决合作过程中的挑战时,需综合考虑声誉、数据相关性和技术能力等因素,以确保合作顺利进行。
四、众包平台
众包平台是一种通过大众力量收集和处理数据的有效方法。在这种模式下,任务被分配给大量的在线工作者,他们完成任务并提供反馈。众包数据收集在大型语言模型训练中具有显著价值。
概念与工作原理
- 众包数据收集的基本模式:众包平台将大规模的数据收集任务分解为小任务,然后分配给众多的在线工作者。工作者完成任务后提交数据,平台进行汇总和验证。这种模式不仅能够快速收集大量数据,还能够覆盖多样化的数据来源。
优缺点
- 优点
- 数据多样性:众包平台可以从全球各地的工作者那里收集数据,确保了数据的多样性和广泛覆盖。
- 快速收集:通过众包,可以快速收集大量数据,特别适用于需要快速获取大量数据的项目。
- 缺点
- 数据质量控制:由于众包平台上的工作者背景和能力各异,数据质量可能存在不一致性。需要建立有效的质量控制机制,以确保数据的准确性和一致性。
- 管理与协调:管理和协调大量工作者的任务需要额外的工作量。需要建立清晰的任务标准和验证流程。
| 众包平台 | |
|---|---|
| 优点 | 数据多样性:可以从全球各地的工作者那里收集数据,确保多样性和广泛覆盖。 快速收集:可以快速完成大量数据收集任务。 |
| 缺点 | 数据质量控制:由于工作者背景和能力各异,数据质量可能存在不一致性。 管理与协调:管理和协调大量工作者的任务需要额外的工作量。 |
热门平台
以下是一些常用的众包平台,它们在数据收集和处理方面具有丰富的经验和广泛的应用
- Amazon Mechanical Turk:MTurk是一个广泛使用的众包平台,提供各种类型的数据收集和处理任务。用户可以在 MTurk 上发布任务,从全球各地的工人那里获取数据。

Figure Eight (formerly CrowdFlower):Figure Eight是一个专业的众包平台,提供数据标注、清洗和验证等服务,广泛应用于机器学习和人工智能项目。
Appen:Appen是一个知名的众包平台,专注于提供高质量的数据收集和标注服务,在语言数据和图像数据处理方面尤为擅长。
实际应用案例
众包平台在大型语言模型的训练中得到了广泛应用,以下是一些实际应用案例
- 文本标注:在大型语言模型的训练过程中,需要大量的标注文本数据。通过 Amazon Mechanical Turk,研究人员可以发布文本分类、情感分析等任务,快速获取大量标注文本数据。这些数据用于训练和评估大型语言模型。
- 对话数据收集:大型语言模型需要丰富的对话数据来训练对话生成能力。通过 Figure Eight,企业可以发布对话数据收集任务,获取多样化的对话数据,用于训练对话模型。
- 语言数据收集:为了提升大型语言模型的多语言处理能力,需要收集各种语言的文本数据。Appen 的多语言数据收集服务可以帮助收集不同地区和语言的文本样本,支持多语言模型的训练和优化。
众包平台为大型语言模型的训练提供了强大的数据收集和标注支持。通过有效利用这些平台,可以高效获取多样化、高质量的数据,为大型语言模型的训练奠定坚实基础。此外,众包平台的快速响应和大规模数据处理能力,满足了大型语言模型训练对数据的高要求。
五、数据存储格式
在数据收集和处理阶段,选择合适的数据存储格式对于确保数据的可用性和处理效率至关重要。常见的数据存储格式包括 JSON、JSONL、CSV 和 XML。其他格式如 Parquet、Avro 和 HDF5 也被广泛使用,每种格式都有其独特的优缺点。
常用格式
- JSON:JavaScript Object Notation,一种轻量级的数据交换格式,易于读写。
- JSONL:JSON Lines,每行一个 JSON 对象,适合逐行处理大型数据集。
- CSV:逗号分隔值,一种用于存储表格数据的纯文本格式。
- XML:可扩展标记语言,一种广泛使用的数据交换和存储可扩展标记语言。
- Parquet:一种列式存储格式,适用于大数据处理,特别是在 Apache Hadoop 生态系统中。
- Avro:一种行式存储格式,支持数据序列化和模式演进,适用于数据流和大数据处理。
- HDF5:分层数据格式,一种用于存储和管理大规模数据的格式,广泛应用于科学计算和机器学习。
优缺点对比
| 格式 | 可读性 | 解析效率 | 存储空间 | 其他特点 |
|---|---|---|---|---|
| JSON | 易于读写,结构清晰 | 解析速度适中 | 比 CSV 大,比 XML 小 | 易于使用,广泛支持 |
| JSONL | 易于逐行处理 | 解析速度快 | 中等 | 适合大规模数据处理 |
| CSV | 简单易读,但缺乏结构信息 | 解析速度快 | 最小 | 易于处理,广泛应用 |
| XML | 可读性好,但冗长 | 解析速度慢 | 最大,包含大量标签信息 | 自描述性强,支持复杂结构 |
| Parquet | 可读性差 | 解析速度快,适合列式读取 | 压缩效率高,占用空间小 | 列式存储,适合大数据分析 |
| Avro | 可读性一般 | 解析速度快 | 压缩效率高,占用空间小 | 支持数据模式演进,适合流处理 |
| HDF5 | 可读性差 | 解析速度快 | 高效存储大规模数据 | 支持复杂数据结构和多维数组 |
实际使用建议
在选择数据存储格式时,需要根据具体的应用场景和需求进行权衡。以下是一些实际使用建议
- JSON:适用于结构化数据,尤其需要嵌套和复杂数据结构的场景。常用于 API 数据交换和配置文件。
- 示例:用于存储用户设置和应用程序配置,数据结构清晰,易于解析和修改。
- JSONL:适用于大规模数据处理,尤其需要逐行读取和处理的数据集。常用于日志文件和数据流处理。
- 示例:用于存储大规模日志数据,每行一个 JSON 对象,方便快速解析和处理。
- CSV:适用于简单的表格数据,尤其需要高效存储和快速访问的场景。常用于数据分析和报告生成。
- 示例:用于存储和处理销售记录、用户数据等大型数据集,解析速度快,占用空间小。
- XML:适用于需要高可读性和自描述性的数据,常用于文档格式和数据交换标准。
- 示例:用于文档存储和配置文件,数据结构清晰,但解析速度较慢,文件大小较大。
- Parquet:适用于大数据处理,尤其需要列式存储和高效压缩的场景。常用于数据仓库和大数据分析。
- 示例:在 Hadoop 和 Spark 环境中用于高效数据存储和分析。
- Avro:适用于需要数据序列化和模式演进的场景,常用于数据流和大数据处理。
- 示例:在 Kafka 和 Hadoop 中用于数据交换和存储,支持高效数据流处理。
- HDF5:适用于科学计算和机器学习中涉及大规模数据存储和管理,支持复杂数据结构和多维数组。
- 示例:用于存储和处理科学数据,如天文观测数据和机器学习训练数据。
通过合理选择数据存储格式,可以显著提升数据处理效率,并确保数据的可读性和可维护性。根据具体的应用场景和需求选择最合适的数据格式,有助于提高整体数据管理和利用的效益。
六、数据收集注意事项
在数据收集过程中,关注数据隐私和合规性,同时确保数据质量和一致性至关重要。以下是一些关键注意事项。
数据隐私与合规性
在数据收集和处理过程中,必须遵守相关数据隐私法规,确保数据的合法性和用户隐私的保护。
- GDPR (General Data Protection Regulation):欧盟的法规,要求用户明确同意,并确保欧盟居民数据的安全和隐私。
- CCPA (California Consumer Privacy Act):保护加州居民的个人数据隐私,赋予消费者更多控制和信息权利。
- 其他相关法规:各国和地区可能有不同的隐私保护法律,必须相应遵守。
数据清洗与预处理
数据清洗和预处理是确保数据质量的关键步骤,它们能够去除数据中的噪声和错误,提升数据的准确性和一致性。
- 数据清洗:包括删除重复数据、纠正错误数据和填充缺失值。可以使用各种数据清洗工具和技术,如 Pandas、OpenRefine 等。
- 示例:使用 Pandas 库清洗 CSV 文件中的数据,删除重复行,纠正格式错误,并填充缺失值,以确保数据完整性和准确性。
- 数据预处理:包括标准化、归一化、特征提取等。经过预处理的数据更适合模型训练和分析。
- 示例:在训练机器学习模型之前,对数据进行标准化处理,将所有特征缩放到相同范围,以避免特征值差异过大影响模型性能。
去重与标准化
去重和标准化是数据收集中的重要环节,有助于避免数据冗余和不一致。
- 去重:通过检查和删除重复数据,减少数据冗余,提高数据处理效率和模型训练效果。
- 示例:在用户数据收集中,通过检查用户 ID 等唯一标识符,删除重复的用户记录,确保每个用户的数据唯一。
- 标准化:将数据转换为统一的格式,确保数据的一致性和可比性。标准化包括格式转换、单位转换等。
- 示例:在多源数据整合时,将所有日期格式统一为 ISO 8601 标准,确保不同数据源之间的一致性。
通过遵守数据隐私法规、进行有效的数据清洗和预处理,以及进行去重和标准化,可以显著提升数据质量和一致性,为后续的数据分析和模型训练奠定坚实基础。
七、数据存储与管理
云存储与本地存储
- 云存储:由第三方服务提供商(如 AWS、Google Cloud、Microsoft Azure)提供。云存储具有高可扩展性和灵活性,适用于大规模数据存储和处理。
- 优势:可扩展性强、高可用性、无需硬件维护。
- 劣势:成本随存储量和使用频率增加、安全性依赖第三方服务提供商。
- 示例:使用 Amazon S3 存储大规模训练数据,利用其强大的数据管理和分发能力,支持大型语言模型的训练。
- 本地存储:通过企业或个人维护的设备(如 NAS、SAN)进行数据存储。
- 优势:对数据和硬件拥有完全控制权,无需担心外部服务中断。
- 劣势:可扩展性受限、需要自行维护和管理。
- 示例:某研究机构使用本地存储设备存储敏感研究数据,确保数据安全和隐私。
分布式数据库
- 分布式数据库:用于存储和管理大规模数据的数据库系统,数据分布在多个节点上,以提供高性能和高可用性。
- 优势:高可扩展性、高可靠性、支持大规模并发访问。
- 劣势:部署和管理复杂、数据一致性和延迟需要优化。
- 示例:使用 Apache Cassandra 存储和管理分布式数据,支持大规模实时数据处理和分析。
最佳实践
数据标注与元数据管理
- 数据标注:对数据进行分类和标记,以便更方便地检索和管理。
- 示例:管理用于训练大型语言模型的数据的标签,标记数据来源、类别和使用场景,以便于检索和使用。
- 元数据管理:管理数据的相关信息,包括数据来源、创建时间、格式等,确保数据的完整性和可追溯性。
- 示例:建立元数据管理系统,记录每个数据集的详细信息,确保数据在整个生命周期中的管理。
数据版本控制
- 数据版本控制:对数据进行版本管理,记录数据的更改历史,确保数据的可追溯性和一致性。
- 示例:使用 DVC(Data Version Control)工具管理训练数据的版本,记录每次数据更新和更改,确保模型训练过程中使用的数据一致性。
参考文献:
https://x.com/vikingmute/status/1737296571354743268
https://timconnors.co/posts/ai-scraper
https://zhuanlan.zhihu.com/p/692683234
https://zhuanlan.zhihu.com/p/669816705
https://zhuanlan.zhihu.com/p/693096151
使用 Redis 启动代理池: https://github.com/Python3WebSpider/ProxyPool
https://blog.csdn.net/gyt15663668337/article/details/86345690
Scrapy 简单介绍: https://vip.fxxkpython.com/?p=5038