什么是Qwen-Agent框架?在通义千问系列中







🔳 我们讨论了通义千问模型的时间线,重点关注它们的智能体能力以及它们如何与其他模型竞争,并探讨了什么是通义千问智能体框架以及如何使用它
当所有人都在谈论DeepSeek-R1在模型推理方面的里程碑时,来自阿里巴巴的通义千问模型却被忽视了,尽管它们正在酝酿一些有趣且开源的东西。从一开始,它们就致力于让它们的最佳模型具备代理能力,例如工具使用,这是它们早期模型也利用过的。今天,我们将讨论**通义千问模型在实现强大推理能力方面的整个历程,这些能力与OpenAI和DeepSeek的SOTA模型相媲美,甚至超越它们**。但这还不是全部。随着人工智能和机器学习社区现在更多地关注生态系统和复杂框架,我们将深入探讨**Qwen-Agent框架**——一个功能完善的代理生态系统,它让通义千问模型能够自主规划、调用函数并直接执行复杂的、多步任务。通义千问家族绝对值得您的关注,所以让我们开始吧!
📨 点击关注!如果你想直接在收件箱中接收我们的文章,请在此订阅
在本期节目中,我们将讨论
- 引言
- 这一切是如何开始的:通义千问 1.0 和通义千问 2
- 通义千问2.5和QwQ-32B与DeepSeek-R1竞争
- Qwen-Agent框架
- 应用示例
- 结论:通义千问的进步为何脱颖而出
- 来源和进一步阅读
这一切是如何开始的:通义千问 1.0 和通义千问 2
首先,简单介绍一下阿里巴巴,以便了解其规模。阿里巴巴集团于1999年由马云在中国杭州创立,现已发展成为电子商务和技术的全球领导者。截至2024年12月31日的季度,公司收入增长8%,达到2802亿元人民币(383.8亿美元),创下一年多以来的最快增长。截至2025年3月,公司市值约为3286.3亿美元,位列全球最有价值公司之列。其人工智能战略以其在多样化业务中的大量投资和整合而著称。公司已承诺在未来三年内向人工智能和云计算基础设施投资超过3800亿元人民币(约530亿美元),超过其过去十年在这些领域的总支出。
而这正是通义千问模型开始发挥重要作用的地方。
从通义千问模型开发的伊始,我们就可以看到其实现强大的代理能力(包括工具使用和深度推理)如何塑造了通义千问模型的战略和进步。以下是阿里巴巴云主要模型的时间线简述,它引导我们了解通义千问今天为代理开发所提供的能力。
**2023年年中,阿里巴巴云通义千问团队**首次开源了名为**通义千问1.0**的LLM家族。它包含了1.8B、7B、14B和72B参数的基础LLM,在多达3万亿个多语言数据(主要侧重于中文和英文)上进行预训练。通义千问1.0模型具有长达32K个token的上下文窗口,一些早期版本为8K。
除了基础模型,阿里巴巴还发布了通过监督微调和RLHF对齐的**Qwen-Chat**变体。即使在早期阶段,它也展示了广泛的技能——它可以进行对话、生成内容、翻译、编码、解决数学问题,甚至在适当提示下可以使用工具或充当代理。**因此,从他们的第一个模型开始,通义千问团队就设计了他们的模型,使其具有代理行为并能够有效使用工具。**
**2024年2月**,通义千问团队发布了升级版**通义千问1.5**。此次,他们为所有模型尺寸统一支持了32K上下文长度,并将模型系列扩展到包括0.5B、4B、32B,甚至110B参数的模型。不仅其通用技能,如多语言理解、长上下文推理和对齐得到了改进,而且代理能力也跃升到与GPT4水平相当的工具使用基准。当时,**在许多情况下,它正确选择和使用工具的准确率超过95%。**
**2024年6月**带来了**通义千问2**,它继承了之前模型的Transformer架构,并对所有模型尺寸(与通义千问1.5相比)应用了分组查询注意力(GQA),以提高模型推理速度并减少内存使用。这为专业任务奠定了坚实基础,后来在2024年8月,**通义千问2-数学**、**通义千问2-音频**(用于理解和总结音频输入的音频-文本模型)和**通义千问2-视觉**相继问世。
**通义千问2-视觉是一个重要的里程碑。**就像DeepSeek处理其模型特性一样,通义千问团队也找到了自己的技术来改进他们的模型。借助通义千问2-视觉,阿里巴巴云引入了他们的特殊创新,例如**朴素动态分辨率**,它允许处理任意分辨率的图像,并将其动态转换为可变数量的视觉token。为了更好地对齐所有模态(文本、图像和视频)的位置信息,它使用了**多模态旋转位置嵌入(MRoPE)**。通义千问2-视觉可以处理20多分钟的视频,并可以集成到手机和机器人等设备上。
通义千问2.5和QwQ-32B与DeepSeek-R1竞争
此外,**2024年9月**,为应对日益激烈的竞争,特别是来自DeepSeek等新竞争对手的挑战,阿里巴巴推出了**通义千问2.5**。此次发布包含了一系列模型,参数从0.5亿到720亿不等,在**高达18万亿个token的庞大数据集**上进行预训练,涵盖了语言、音频、视觉、编码和数学等应用。它们支持29种以上语言,输入可支持128K个token的超长上下文,输出可生成长达8K个token。但这个上下文长度并非**通义千问2.5**的极限——**通义千问2.5-1M模型(于2025年1月推出)可以处理极长的上下文——多达100万个token**,同时处理这些token的速度提高3-7倍。
2.5版本模型中最令人印象深刻的是**通义千问2.5-视觉**,于**2025年1月**发布。它**充当数字环境中的视觉代理**——它不仅仅描述图像,还可以与图像进行交互。通义千问2.5-视觉旨在根据视觉输入“推理和动态指导工具”。它利用**原生动态分辨率**(用于图像)、**动态帧率训练和绝对时间编码**(用于视频),这使得它能够处理不同大小的图像和长达数小时的视频。为了有效地处理长视频,它在通义千问2-视觉的基础上,通过将MRoPE的时间分量与绝对时间对齐,进一步提升了性能。
更令人着迷的是,**通义千问2.5-视觉可以控制电脑和手机等设备**,这表明该多模态模型**功能与OpenAI的Operator类似**。这使得它能够预订航班、检索天气信息、编辑图像和安装软件扩展——总之,它可以做代理系统通常能做的事情。

通义千问2.5的发布时间(1月26日)恰逢中国农历新年假期,这被视为对前一周(1月20日)震惊人工智能社区的DeepSeek-R1模型迅速崛起的应对。
与此同时,通义千问团队还开发了一个更复杂的模型——**通义千问2.5-Max,一个大规模专家混合(MoE)模型**,在超过20万亿个token上进行训练,并通过监督微调(SFT)和人类反馈强化学习(RLHF)进一步完善。这次发布表明,**通义千问模型可以与DeepSeek-V3、Llama3.1-405B、GPT-4o和Claude3.5-Sonnet等顶级大型模型竞争,甚至超越它们**。
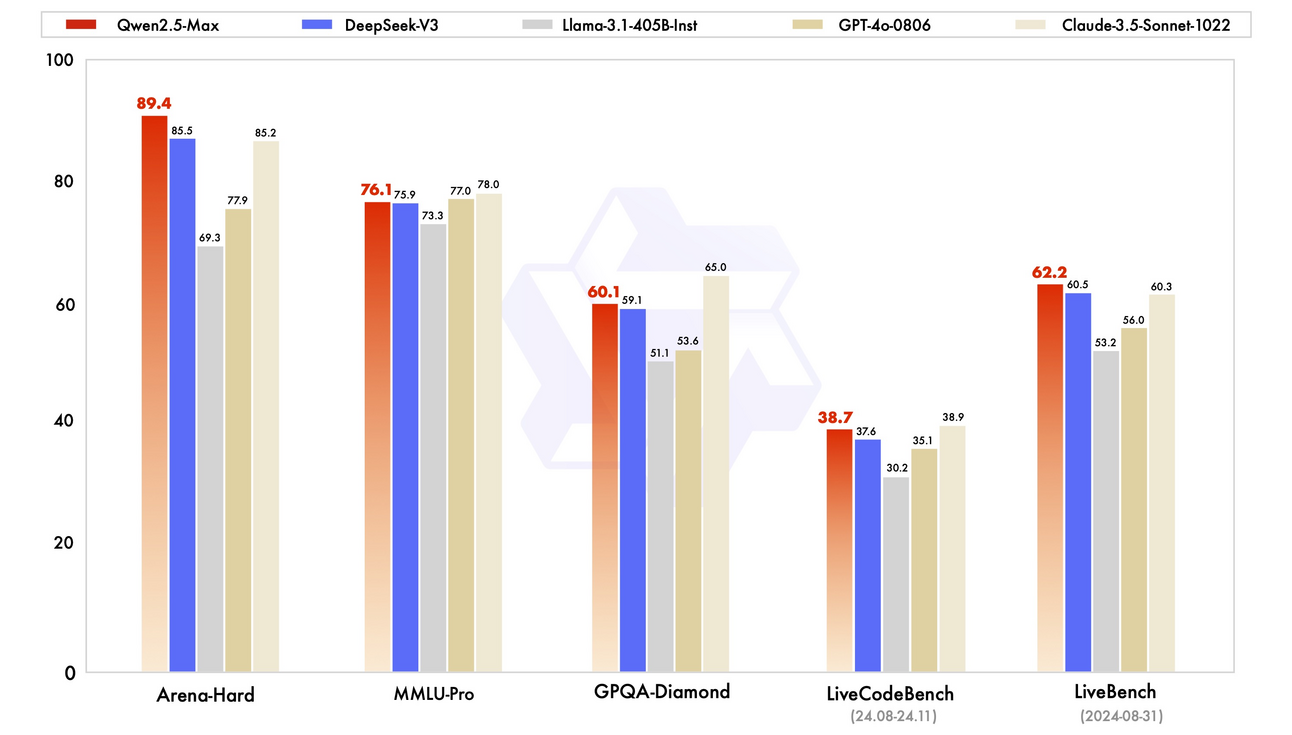 图片来源:通义千问2.5-Max博客文章
图片来源:通义千问2.5-Max博客文章
如我们所见,通义千问2.5系列作为阿里巴巴2025年的旗舰AI模型,结合了深厚知识、工具使用技能和多领域专业知识,并具有扩展的上下文长度。通过专注于代理功能,**它们为使用通义千问骨干构建更自主的AI代理系统奠定了基础**。
在通义千问团队2025年的模型中,还有一个值得注意的成员——**QwQ-32B推理模型**。它于2024年11月首次作为增强逻辑推理的实验性预览模型亮相,但直到最近,在**2025年3月初**才获得力量。QwQ-32B也是“沉迷于”RL的结果。在这里,RL的有效扩展使得较小的模型也能像较大的模型一样强大:**只有320亿参数的QwQ提供的性能可与大得多的DeepSeek-R1(671B参数,37B活跃)相媲美。它还超越了较小的o1-mini。**这些令人印象深刻的推理能力为能够使用工具和动态适应任务的AI代理开辟了新的可能性。
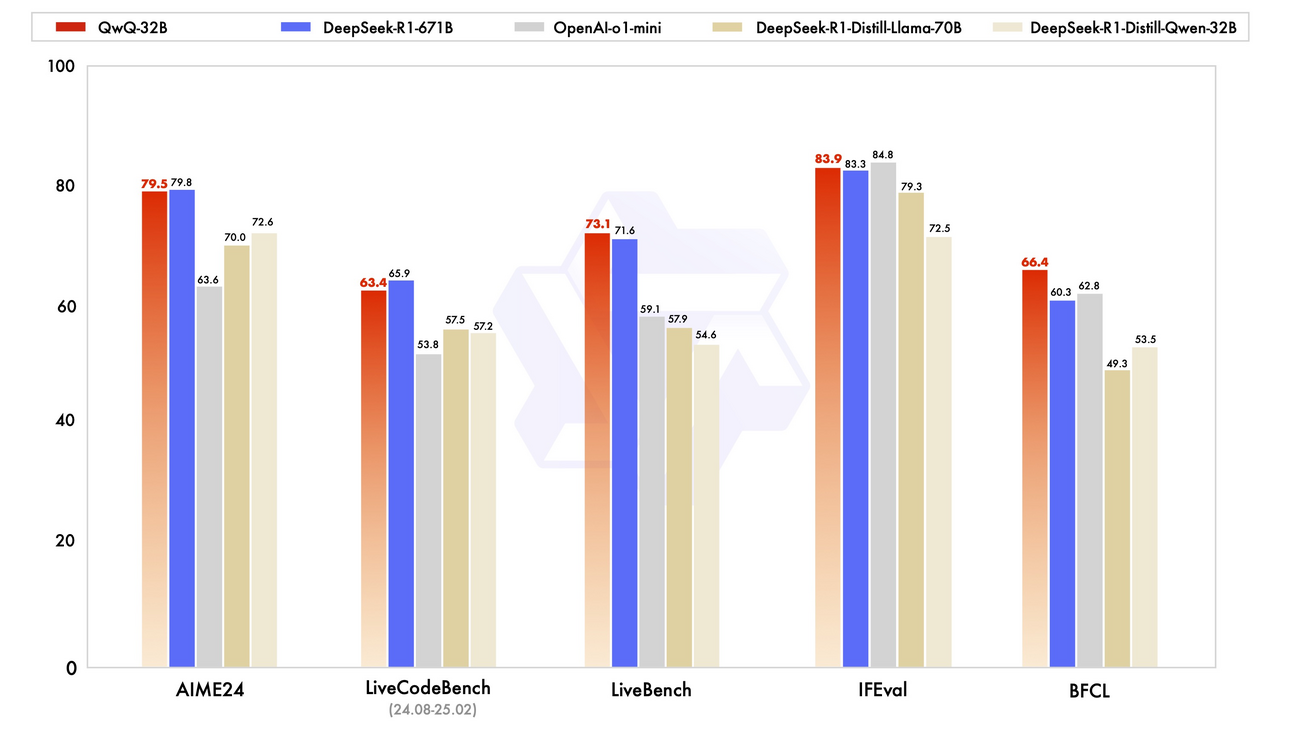 图片来源:QwQ-32B博客文章
图片来源:QwQ-32B博客文章
好的,以上是通义千问团队自2023年以来工作的简要总结。我们在这里探讨的是如何利用通义千问模型构建AI代理和应用程序——这正是**Qwen-Agent框架**。随着社区现在对完整生态系统越来越感兴趣,现在是关注这一发展的绝佳时机。
什么是Qwen-Agent框架?
**Qwen-Agent框架旨在支持通义千问模型在实际应用中作为智能体运行的应用程序开发**。它建立在通义千问在指令遵循、工具集成、多步规划和长期记忆处理方面的优势之上。Qwen-Agent提供了一种模块化设计,其中内置函数调用支持的LLM和外部工具可以组合成更高层次的智能体。
Qwen-Agent框架的关键方面包括:
工具集成和函数调用
该框架使得定义通义千问模型可以调用的工具(函数、API)变得简单明了。它处理类似于OpenAI函数调用规范的“函数调用”JSON-like语法,以便模型可以输出调用并接收工具的结果。Qwen-Agent附带了用于网页浏览、代码执行、数据库查询等的现成工具插件。这使得通义千问模型可以在需要时使用计算器或获取网页内容等工具。
规划和记忆
该代理框架为模型配备了工作记忆和规划器,以处理多步任务。用户无需提示每个步骤,Qwen-Agent可以让模型内部规划一系列动作。例如,在一个复杂的查询中,模型可能会规划搜索网页,然后总结结果,然后起草答案。Qwen-Agent可以维护过去步骤的记忆,因此模型会记住工具返回了什么,并将这些信息反馈到下一步的提示中。
然而,主要问题是:**你能用Qwen-Agent构建什么?**
Qwen-Agent应用示例
以下是几个使用Qwen-Agent构建的应用程序,它们展示了Qwen-Agent如何使用工具和执行规划。
代码解释器集成
Qwen-Agent内置了代码解释器,允许模型执行Python代码进行数据分析、计算和可视化任务。实际上,这赋予了Qwen集成沙盒般的能力来运行代码,类似于OpenAI的代码解释器。用户可以上传文件或提供数据,Qwen将编写并运行Python代码来分析数据或生成图表。例如,此代码解释器可以从数据生成图表。此功能功能强大,但并非沙盒化,这意味着代码在宿主环境中运行。
浏览器助手 (BrowserQwen Chrome扩展程序)
浏览器助手使用通义千问模型在用户的浏览器中浏览网页和文档,并使用实时信息回答查询。它以名为BrowserQwen的Chrome扩展程序形式提供(可在GitHub上获取)。它可以讨论或回答有关当前网页/PDF的问题,并保存您访问过的页面历史记录。这使得通义千问能够总结多个页面的内容,并利用收集到的信息协助写作任务。
BrowserQwen还支持插件集成——例如,它使用前面提到的代码解释器工具来解决数学问题并直接从浏览器创建数据可视化。
 图片来源:Qwen-Agent GitHub文档
图片来源:Qwen-Agent GitHub文档
但是,如果您需要从包含1M个token的超长文档中获取问题的答案怎么办?Qwen-Agent也可以通过智能检索方法提供帮助。
通过检索实现百万token上下文
Qwen-Agent的一个创新用途是通过检索来扩展上下文长度。研究人员从一个标准的8k上下文聊天模型开始,并通过**三个步骤**使其能够处理1M token的文档,例如阅读整本书:
- 构建一个能够处理长上下文的强大代理。
- 使用该代理生成高质量的训练数据。
- 使用合成数据微调模型,以创建强大的长上下文AI。
通过结合以下**三个级别**,系统可以从海量文本中查找和处理最相关的信息:
- 级别1:检索增强生成(RAG)
 图片来源:“使用Qwen-Agent将LLM从8k上下文扩展到1M上下文”博客
图片来源:“使用Qwen-Agent将LLM从8k上下文扩展到1M上下文”博客
- 将长文档分成较小的块(例如512个token)。
- 使用基于关键字的搜索来查找最相关的部分。
- 为提高效率,使用传统的BM25检索而不是复杂的嵌入模型。
- 级别2:逐块阅读
- 它不再仅仅依赖关键词重叠,而是单独扫描每个块。
- 如果某个块相关,它将提取关键句子并优化其搜索。这可以防止重要细节被忽略。
- 级别3:分步推理
- 系统采用多步流程来回答复杂问题。
- 它将一个查询分解成更小的子问题,并逐步回答它们。例如,要回答“贝多芬第五交响曲在哪个世纪发明了哪种交通工具?”,系统首先会发现该交响曲创作于19世纪,然后搜索在该时代发明的交通工具。
Qwen-Agent的这种检索辅助方法和随后的微调使得LLM能够有效地从8K上下文扩展到1M个token。总的来说,这个过程展示了我们如何将LLM与代理编排器结合,通过工具辅助策略克服基础模型限制。
 图片来源:“使用Qwen-Agent将LLM从8k上下文扩展到1M上下文”博客
图片来源:“使用Qwen-Agent将LLM从8k上下文扩展到1M上下文”博客
同样值得注意的是,Qwen-Agent现在为官方的Qwen Chat网络应用程序提供后端支持——当用户在线与Qwen聊天时,该代理框架管理对话,支持在聊天中使用工具等功能。
结论:通义千问的进展为何脱颖而出?
如我们所见,通义千问团队可以向社区提供许多独特的开放功能。通义千问模型在DeepSeek-R1和OpenAI的模型中脱颖而出,原因在于其强大的**多语言性能、开源可用性、企业适应性**以及**强调工具使用、规划和函数调用等智能体能力的整体方法**。可用于智能体框架(如Qwen-Agent)的广泛开源模型使所有通义千问开发都像一个全面的智能体生态系统。虽然我们离真正的自主AI智能体还有很长的路要走,但通义千问团队的进步是向前迈出的一步。即使现在,借助开放的Qwen-Agent框架,开发人员也可以创建能够执行复杂任务的智能体,例如阅读PDF、与工具交互以及执行自定义功能。
值得注意的是,许多研究人员依赖通义千问模型进行测试,因为它在可访问性和高性能之间取得了平衡,使其成为推进人工智能研究的首选。
通义千问的下一步是什么?通义千问3还是QwQ模型的新版本?会更注重缓慢、循序渐进的推理,因为这是一种趋势,还是它们会找到自己的AGI之路?我们将拭目以待。
作者:Alyona Vert 编辑:Ksenia Se
资料来源和进一步阅读
通义千问模型
- 通义千问 1.0 - GitHub
- 通义千问 1.5 - 博客文章
- 通义千问 2 - 博客文章
- 通义千问2-VL - 博客文章
- 通义千问2-Math - 博客文章
- 通义千问2-Audio - GitHub
- 通义千问2.5 - GitHub
- 通义千问2.5-VL - GitHub
- 通义千问2.5-Math - GitHub
- 通义千问2.5-1M - 博客文章
- 通义千问2.5-Max - 博客文章
- QwQ-32B - 博客文章
- 其他通义千问模型的博客
- 通义千问家族在Hugging Face
进一步阅读资源
- 通义千问技术报告作者:白金泽等。
- 通义千问2技术报告作者:杨安等。
- 通义千问2-VL:以任意分辨率增强视觉语言模型对世界的感知 作者:白帅等。
- 通义千问2-Audio技术报告作者:林俊阳、储云飞等。
- 通义千问2.5技术报告作者:惠斌元等。
- 通义千问2.5-VL技术报告作者:陈可钦等。
- 通义千问2.5-1M技术报告作者:刘大一恒等。
- Qwen-Agent框架
- 使用Qwen-Agent将LLM从8k上下文扩展到1M上下文
- BrowserQwen在GitHub上
- 阿里巴巴股票分析
- 美联社关于阿里巴巴的报道
图灵邮报资源
今天就到这里。感谢您的阅读!
如果本文能帮助您的同事增强对人工智能的理解并保持领先,请与他们分享。





