🪢 Langfuse 和 🤗 Hugging Face:五种结合使用它们的方法







Hugging Face 和 Langfuse 是开发和运行 LLM 应用程序的流行平台。本指南将展示五种结合使用这两个平台以简化开源 LLM 开发的方法。
什么是 Langfuse? Langfuse 是一个用于 LLM 工程的开源平台。它为 AI 应用程序提供追踪和监控功能,帮助开发人员调试、分析和优化其产品。Langfuse 通过原生集成、OpenTelemetry 和 SDK 与各种工具和框架集成。
本指南将向您展示如何:
- 追踪 Hugging Face 模型
- 评估 Hugging Face smolagents
- 在 Playground 和评估器中使用 Hugging Face 模型
- 使用 Hugging Face 数据集进行数据集实验
- 在 Hugging Face Spaces 上部署 Langfuse
1) 使用 Langfuse 追踪 Hugging Face 模型
Hugging Face 允许您查询各种开源和专门微调的模型。最常见的集成模式之一是使用 Python 查询 Hugging Face 模型,并通过 Langfuse 自动追踪模型调用。使用 Langfuse OpenAI 集成,您可以轻松指向任何 Hugging Face 模型端点。例如,调用 `Meta-Llama-3-8B-Instruct` 模型。
import os
from langfuse.openai import OpenAI
from langfuse.decorators import observe
# Set up your environment variables
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com"
os.environ["HUGGINGFACE_ACCESS_TOKEN"] = "hf_..."
# Initialize the OpenAI client pointing to the Hugging Face Inference API
client = OpenAI(
base_url="https://api-inference.huggingface.co/models/meta-llama/Meta-Llama-3-8B-Instruct/v1/",
api_key=os.getenv('HUGGINGFACE_ACCESS_TOKEN'),
)
# Optionally, use the @observe() decorator to trace other application logic as well
@observe()
def get_poem():
completion = client.chat.completions.create(
model="model-name", # this can be an arbitrary identifier
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a poem about language models"},
]
)
return completion.choices[0].message.content
print(get_poem())
有关更多示例,请查看 Langfuse Hugging Face 集成文档。
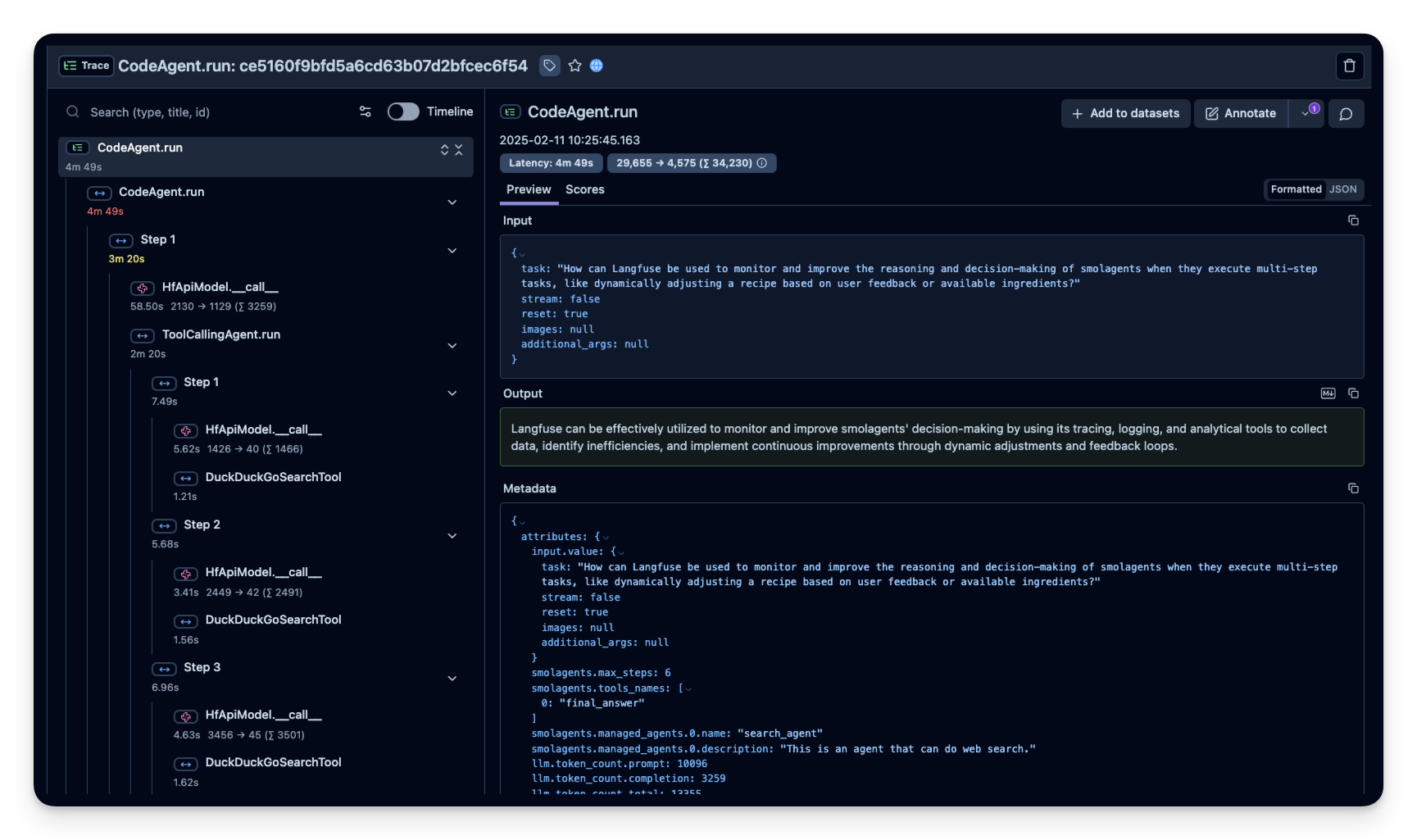
2) 使用 Langfuse 追踪 Hugging Face Smolagents
对于使用 Hugging Face 极简代理框架 — smolagents — 的开发人员,与 Langfuse 集成可以帮助您追踪多步过程并监控代理的推理。下面是一个简化示例,展示如何检测 smolagents:
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.trace.export import SimpleSpanProcessor
from openinference.instrumentation.smolagents import SmolagentsInstrumentor
# Initialize the tracer provider and set up the OTLP exporter to send traces to Langfuse
trace_provider = TracerProvider()
trace_provider.add_span_processor(SimpleSpanProcessor(OTLPSpanExporter()))
SmolagentsInstrumentor().instrument(tracer_provider=trace_provider)
# Now, create a smolagent and run it
from smolagents import CodeAgent, ToolCallingAgent, DuckDuckGoSearchTool, HfApiModel
# Initialize the model (you can provide additional parameters as needed)
model = HfApiModel(model_id="deepseek-ai/DeepSeek-R1-Distill-Qwen-32B")
# Create an agent that can perform a web search
search_agent = ToolCallingAgent(
tools=[DuckDuckGoSearchTool()],
model=model,
name="search_agent",
description="Agent to perform web searches."
)
# Create a manager agent that coordinates the operations
manager_agent = CodeAgent(
tools=[],
model=model,
managed_agents=[search_agent],
)
result = manager_agent.run("How can Langfuse be used to monitor and improve the reasoning of smolagents when executing multi-step tasks?")
print(result)
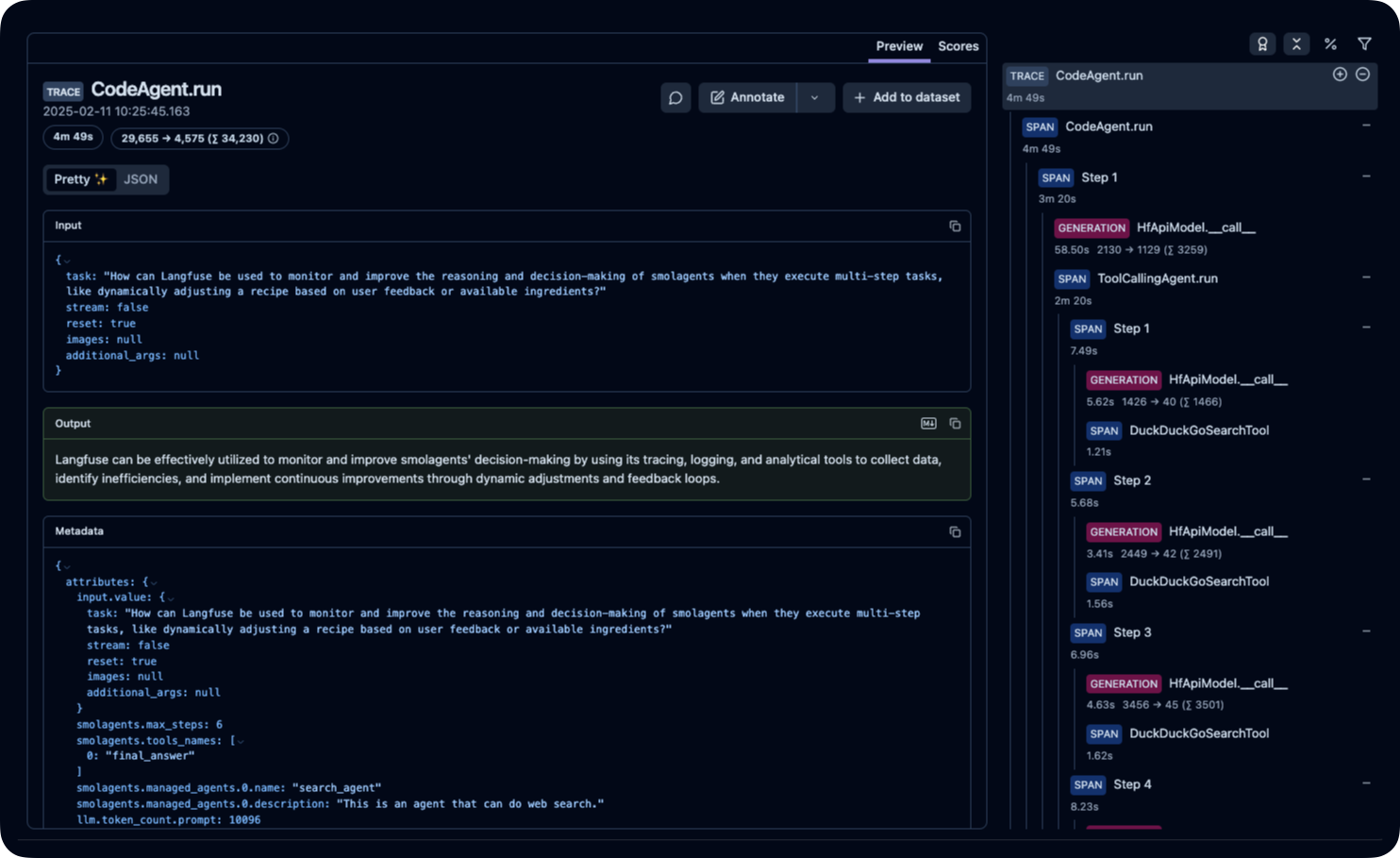
此集成允许您查看 smolagent 执行的每个步骤的详细追踪。在 smolagents 文档中了解有关此集成的更多信息。
3) Hugging Face 模型在 Playground 和评估器中的应用
您还可以在 Langfuse Playground 中使用 Hugging Face 模型,并用于 LLM-as-a-Judge 评估器。这使您能够测试提示并使用开源模型进行基于模型的评估。
要在 Langfuse 中添加 Hugging Face 模型,请导航到项目设置。创建新的模型连接,并选择 openai 作为提供商。将 API 基本 URL 替换为模型的端点(例如 `https://api-inference.huggingface.co/models/meta-llama/Meta-Llama-3-8B-Instruct/v1/`)。将您的 Hugging Face 访问令牌添加到 API 密钥字段。对于模型名称,您可以使用任何任意标识符。
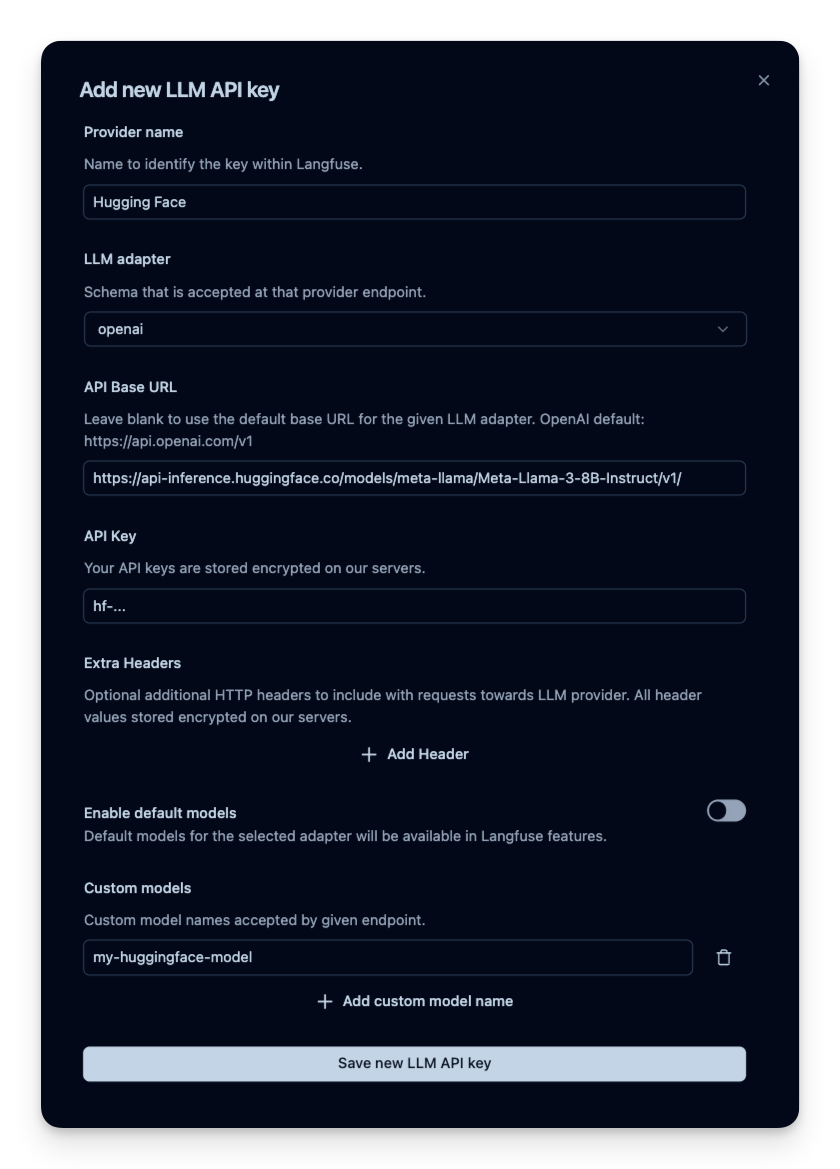
了解更多关于如何设置 Langfuse 的 LLM-as-a-Judge 评估器和 Langfuse Playground 的信息。
4) Hugging Face 数据集用于数据集实验
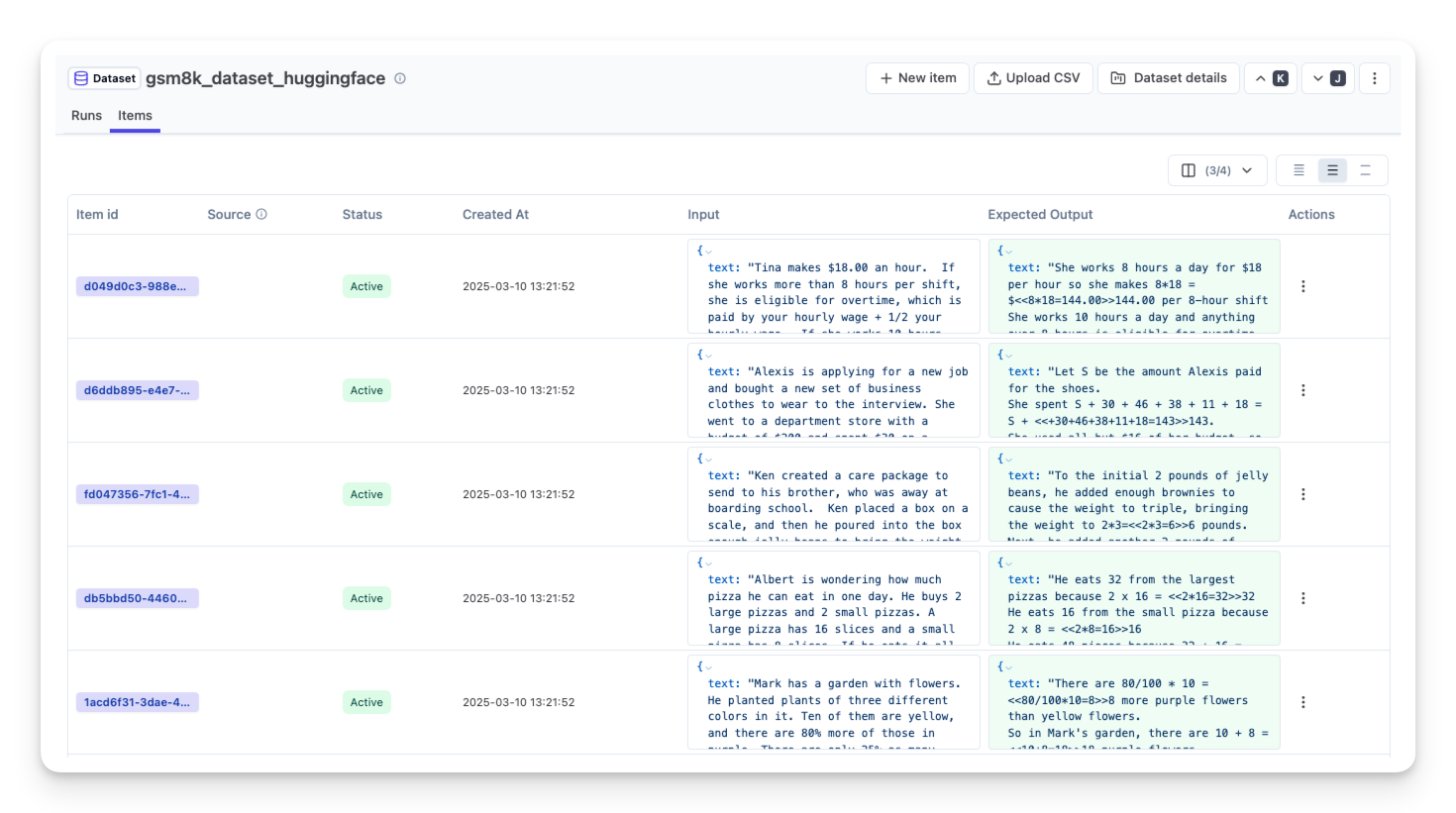
Hugging Face 提供了各种可用于评估 LLM 和 AI 代理的数据集。这些数据集可用于运行 Langfuse 数据集实验。
此示例展示了如何将 Hugging Face 数据集引入您的可观测性管道,从而使用 Langfuse 追踪性能和评估分数。
首先,我们从 Hugging Face 获取一个数据集。在本例中是包含数学文字问题的 GSM8K 数据集。
import os
import pandas as pd
from datasets import load_dataset
from langfuse import Langfuse
# Load a benchmark dataset (e.g., GSM8K)
dataset = load_dataset("openai/gsm8k", split="train[:10]") # limit to first 10 for demo
df = pd.DataFrame(dataset)
print("First few rows of the dataset:")
print(df.head())
# Initialize your Langfuse client (ensure you have your API key configured)
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..."
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..."
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com"
langfuse = Langfuse(api_key=os.getenv("LANGFUSE_SECRET_KEY"))
# Create a new dataset in Langfuse
dataset_name = "GSM8K_Benchmark"
langfuse.create_dataset(
name=dataset_name,
description="Benchmark dataset for evaluating LLM performance",
metadata={"type": "benchmark"}
)
# Upload each dataset item to Langfuse
for i, row in df.iterrows():
langfuse.create_dataset_item(
dataset_name=dataset_name,
input={"question": row["question"]},
expected_output={"answer": row["answer"]},
metadata={"index": i}
)
然后,您可以循环遍历数据集项目,以测试您的应用程序的每个数据集输入。
dataset = langfuse.get_dataset("<langfuse_dataset_name>")
# Run our agent against each dataset item
for item in dataset.items:
langfuse_trace, output = run_your_application(item.input["text"])
# Link the trace to the dataset item for analysis
item.link(
langfuse_trace,
run_name="notebook-run-01",
run_metadata={ "model": model.model_id }
)
# Optionally, store a quick evaluation score for demonstration
langfuse_trace.score(
name="<example_eval>",
value=1,
comment="This is a comment"
)
您可以重复此过程,使用不同的
- 模型(OpenAI GPT、本地 LLM 等)
- 工具(搜索 vs. 非搜索)
- 提示(不同的系统消息)
然后在 Langfuse 中并排比较它们
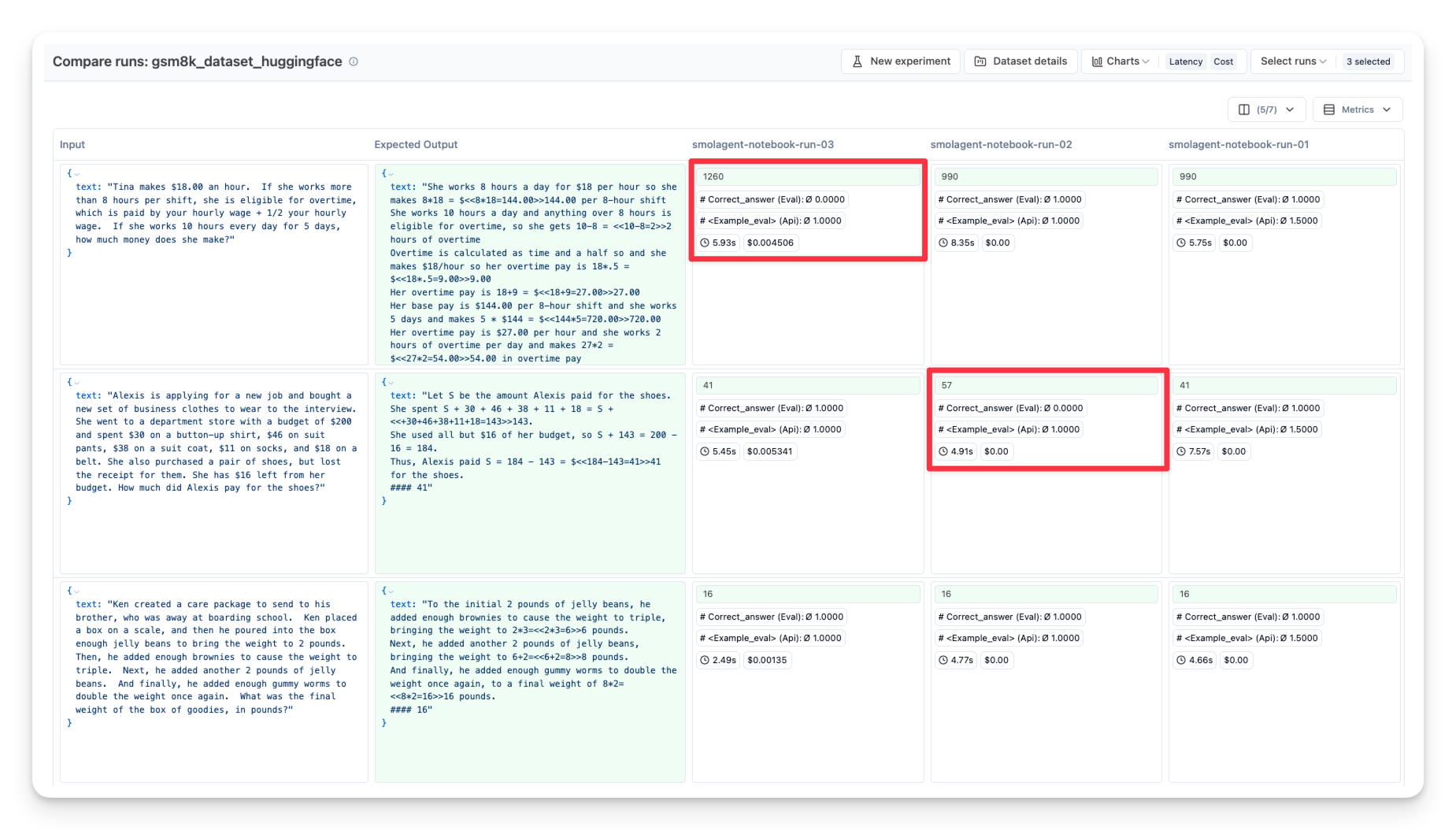
有关如何使用 Langfuse 数据集实验的更多详细信息,请查看文档。
5) 在 Hugging Face Spaces 上部署 Langfuse
Langfuse 也可以直接部署在 Hugging Face Spaces 上,将 Spaces 的即时可访问性与 Langfuse 可观测性的强大功能结合起来。
要进行部署,只需创建一个新的 Hugging Face Space,选择 Docker 作为您的 SDK,然后选择 Langfuse 作为模板。您需要设置持久存储并配置环境变量以确保安全操作。
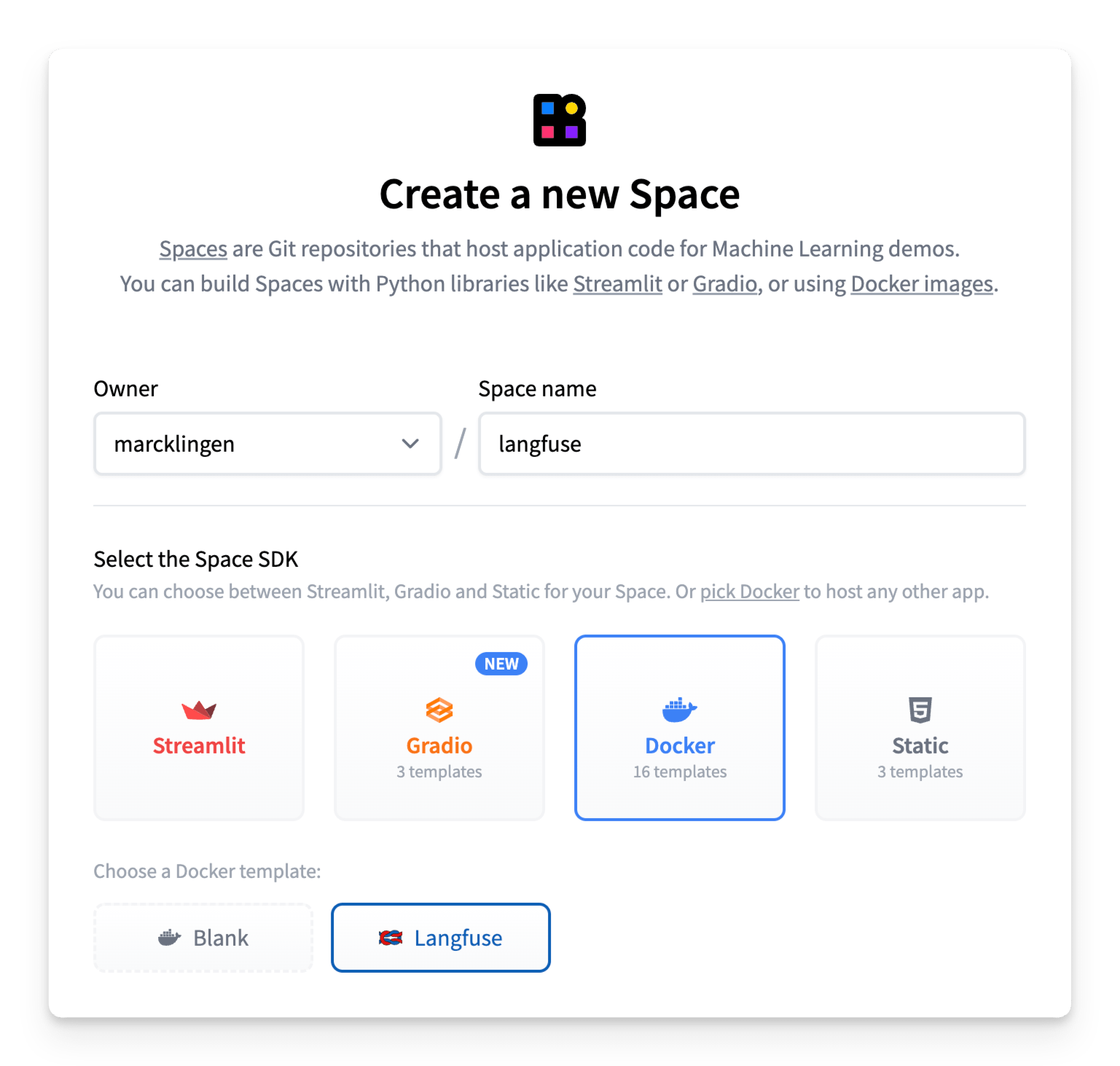
有关在 Spaces 上部署 Langfuse 的分步指南,请查看 Spaces 文档。






