GPU贫民救星:革新低比特开源大型语言模型和高成本效益的边缘计算






来自 GreenBitAI

动机与背景
自2010年以来,人工智能技术取得了显著的进步,深度学习的兴起和AlphaGo在围棋领域的出色胜利是重要的里程碑。OpenAI在2022年末推出的ChatGPT展示了大型语言模型(LLMs)前所未有的能力。此后,生成式AI模型迅速发展,成为第四次工业革命的重要驱动力,特别是在工业升级中推动智能和自动化技术进步。这些技术正在改变我们处理信息、做出决策和互动的方式,有望在经济和社会层面带来深远变化。AI带来了巨大的机遇;然而,这项技术的实际应用面临挑战,尤其是高昂的成本。例如,大型模型在商业化过程中的开销对企业来说可能是一个沉重负担。持续的技术突破令人鼓舞,但如果成本无法控制,维持研发和获得广泛信任将变得困难。然而,大型开源模型的兴起正在逐渐改变这一局面。它们不仅通过提高可及性来民主化技术,还通过降低进入壁垒来促进快速发展。例如,消费级GPU现在可以支持高达7B/8B模型参数的全参数微调,其成本可能远低于专有模型。在这种去中心化AI范式中,开源模型可以显著降低边际成本,同时竞争确保了质量并加速了商业化。观察还表明,经过量化压缩的大型模型通常比同等大小的小型预训练模型表现更好,这表明量化模型保留了出色的能力,为选择开源模型而非重复预训练提供了有力理由。
在快速发展的人工智能领域,基于云的大模型正在推动技术边界,以实现更广泛的应用和更强大的计算能力。然而,市场需要快速部署和快速增长的智能应用,这导致了带有大模型的边缘计算的普及——尤其是7B和13B等中型模型——它们以其成本效益和可调节性而闻名。企业更喜欢对这些模型进行微调,以确保稳定的应用性能和持续的数据质量控制。此外,反馈机制允许从应用中收集的数据训练更高效的模型,使得持续的数据优化和详细的用户反馈成为核心竞争优势。尽管云模型在处理复杂任务方面具有高精度,但它们面临几个关键挑战:
- 推理服务的基建成本:高性能硬件,特别是GPU,稀缺且昂贵。与集中式商业运营相关的增量边际成本是扩大AI业务规模的重大障碍。
- 推理延迟:在生产环境中,模型必须快速响应并提供结果,因为任何延迟都可能直接影响用户体验和应用性能。这需要能够高效运行的基础设施。
- 隐私和数据保护:在涉及敏感信息的场景中,使用第三方云服务处理敏感数据可能会引发隐私和安全问题,从而限制了云模型的使用。
鉴于这些挑战,边缘计算提供了一个有吸引力的替代方案。在边缘设备上直接运行中型模型可以减少数据传输延迟,提高响应速度,并有助于在本地管理敏感数据,从而提高数据安全性和隐私性。通过专有数据的实时反馈和迭代更新,AI应用变得更高效和个性化。
尽管开源模型和工具生态系统中有许多创新,但仍存在一些局限性。这些模型和工具通常缺乏针对本地部署的优化,由于计算能力和内存限制,其使用受到限制。例如,即使是相对较小的7B模型,也可能需要高达60GB的GPU内存(需要昂贵的H100/A100 GPU)才能进行全参数微调。此外,市场上预训练的小型模型选择有限,LLM团队往往更专注于扩展模型规模,而不是优化小型模型。而且,虽然现有的量化技术在模型部署期间有效减少内存使用,但它们不允许在微调过程中进行量化权重优化,这限制了开发人员在资源受限的情况下使用更大模型的能力。开发人员通常希望通过量化技术在微调过程中也节省内存,这一需求尚未得到有效满足。
我们的方法是解决这些痛点,并为开源社区做出重大的技术贡献。通过使用神经架构搜索(NAS)和相应的训练后量化(PTQ)方案,我们提供了200多个低比特量化的小型模型,这些模型源自110B到0.5B的各种大型模型。这些模型优先考虑准确性和质量,刷新了低比特量化的最新精度。我们的NAS算法还考虑了量化模型参数的硬件友好布局,使这些模型能够轻松适应主流计算硬件,如NVIDIA GPU和Apple芯片,大大减轻了开发人员的工作。此外,我们推出了开源框架Bitorch Engine和专门为低比特模型训练设计的DiodeMix优化器。开发人员可以直接在量化空间中对低比特量化模型进行全参数监督微调和持续训练,使训练和推理表示对齐。这种更短的工程链大大提高了效率,加速了模型和产品的迭代。通过整合低比特权重训练技术和低秩梯度技术,我们可以在单个GTX 3090 GPU上实现LLaMA-3 8B模型的全参数微调(见图1)。我们的解决方案简单有效,节省资源并解决了量化模型中的精度损失问题。我们将在后续章节中讨论更多技术细节。
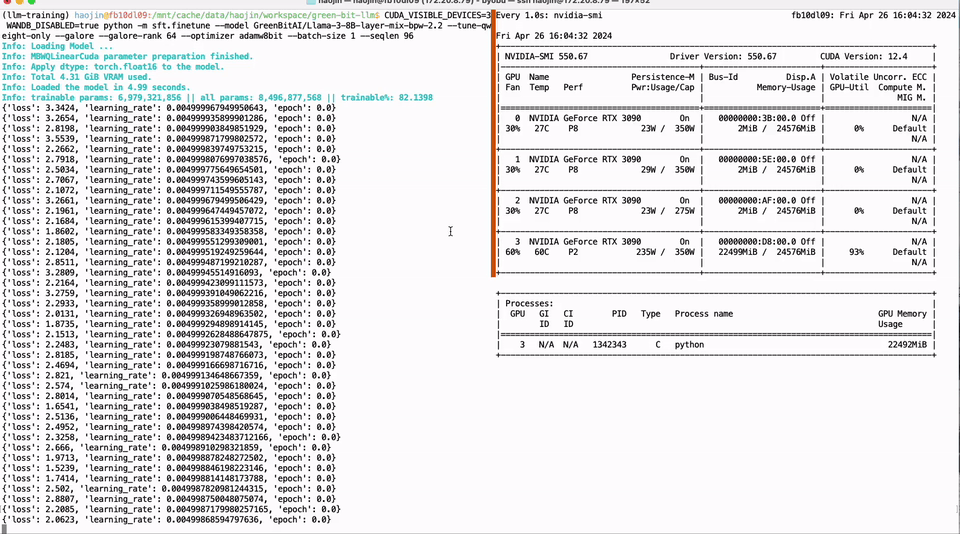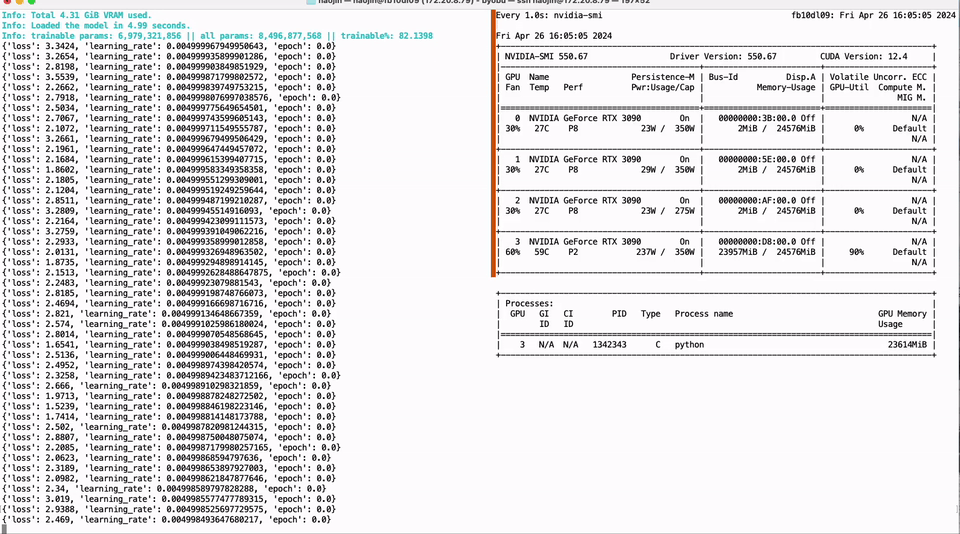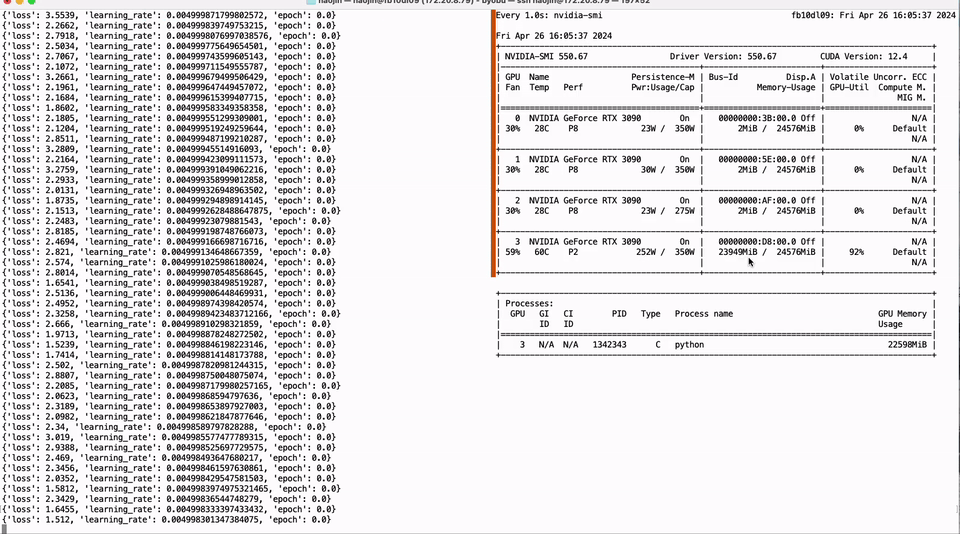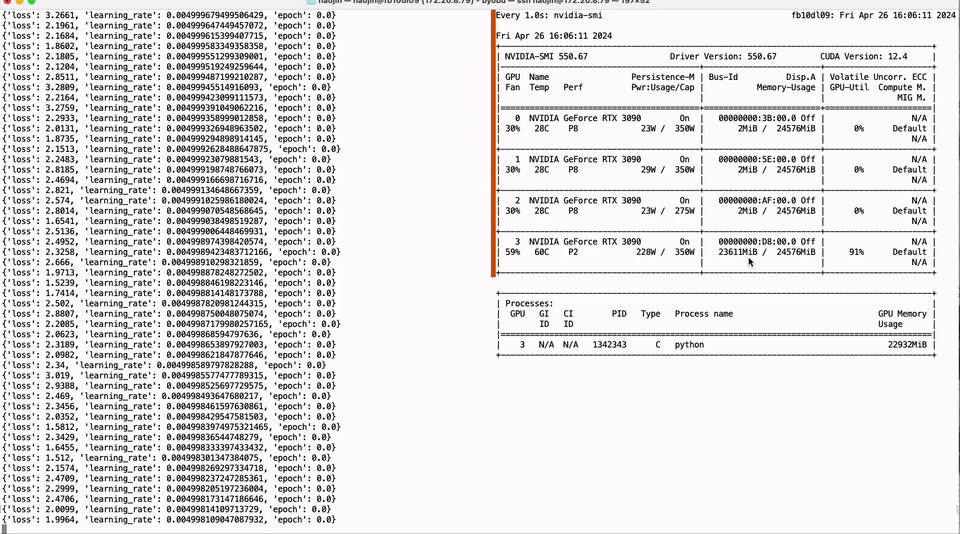 图1. 单个GTX 3090实现LLaMA-3 8B全参数微调。
图1. 单个GTX 3090实现LLaMA-3 8B全参数微调。
模型量化
大模型时代的一个显著特点是计算资源需求的显著增加。如GPTQ和AWQ等权重训练后量化(PTQ)压缩方案已证明了大型语言模型在4比特表示上的可靠性。它们在性能损失最小的情况下,将权重空间压缩了四倍,从而显著减少了模型推理所需的硬件资源。同时,QLoRA巧妙地将4比特LLM表示与LoRA技术结合,将低比特表示扩展到微调阶段。微调后,它将LoRA模块与原始FP16模型合并,实现了资源需求较低的参数高效微调(PEFT)。这些前沿的工程探索为社区提供了便利的研究工具,显著降低了模型研究和工业应用的资源壁垒,并激发了学术界和工业界对更低比特表示的想象。
与INT4相比,像INT2这样的更低比特“四舍五入到最近”(RTN)量化要求原始模型具有更平滑的连续参数空间,以保持较低的量化损失。例如,超大规模模型通常表现出容量冗余和对量化的更高容忍度。最近的工作,如LLM.int8(),分析了当前基于Transformer的大型语言模型,观察到模型推理过程中存在系统性的激活出现现象,其中少数通道在最终推理结果中起决定性作用。最近的研究,如layer-Importance,进一步观察到Transformer模块的不同深度在对模型容量的贡献方面也呈现出非均匀分布。这些特性为低比特压缩提供了洞察。因此,我们探索了一种结合搜索和校准的两阶段LLM低比特量化方法。
首先,我们使用NAS相关方法搜索和排序参数空间的量化敏感性,利用经典的混合精度表示来实现模型参数内的最佳比特分配。为了降低复杂性,我们选择不使用复杂的向量量化和INT3表示,而是使用经典的组级MinMax量化器。我们只选择INT4(组大小128)和INT2(组大小64)作为我们的基本量化表示。相对简单的量化器设计降低了计算加速核的复杂性和跨平台部署的挑战。为此,我们探索了层混合(Layer-mix)和通道混合(Channel-mix)排列下的混合精度搜索空间。通道混合量化更适合Transformer架构的系统性激活出现现象,通常实现较低的量化损失,而层混合量化保持了优异的模型容量和硬件友好性。通过高效的混合精度NAS算法,我们可以在RTX 3090等低端GPU上,在几个小时内完成Qwen1.5 110B这样的大型模型的量化布局统计,并根据这些特性在几秒钟内为任何低比特模型执行最佳架构搜索。我们观察到,我们可以基于搜索和重要性排序快速构建鲁棒的低比特模型。
在从搜索中获得量化布局后,我们引入了一种基于离线知识蒸馏的可扩展PTQ校准算法,以解决超低比特量化(如2到3比特)带来的累积分布漂移问题。使用包含512个样本的多源校准数据集,我们可以在单个A100 GPU上,在几个小时内完成0.5B到110B大型语言模型的PTQ校准。尽管额外的校准步骤会延长压缩时间,但根据经典低比特和量化感知训练(QAT)研究的经验,这是构建低量化损失模型的必要条件。随着开源社区中100B+大型模型(如Command R plus、Qwen1.5 110B、LLama3 400B)的不断涌现,构建高效可扩展的量化压缩方案将成为LLM系统工程研究的重要组成部分,也是我们持续关注的焦点。我们凭经验证明,结合搜索和校准的低比特量化方法在推动开源社区模型架构适应性方面具有显著优势。
性能分析
通过我们的两阶段量化压缩方法,我们开发了200多个低比特量化模型,这些模型源自各种开源LLM,包括最新的Llama3、Llama2、Phi-3、Qwen1.5和Mistral等系列。我们使用EleutherAI lm-evaluation-harness库来探索这些低比特量化模型在实际性能和行业应用中的表现。我们的4比特量化校准方案实现了相对于FP16表示的无损压缩。使用混合INT4和INT2表示实现的次4比特量化校准方案,在多个零样本评估结果中显示,经典的INT2量化表示,只需极少的数据校准,就足以保持语言模型在阅读理解(BoolQ、RACE、ARC-E/C)、常识推理(Winogr、Hellaswag、PIQA)和自然语言推理(WIC、ANLI-R1、ANLI-R2、ANLI-R3)中的核心能力。
| 零样本任务 | Phi-3 mini 128k (bpw:2.5/3.0/4.0/16) | Llama 3 8B (bpw:2.5/3.0/4.0) | Qwen1.5 14B (bpw:2.2/2.5/3.0) |
|---|---|---|---|
| PIQA | 0.75/0.77/0.78/0.78 | 0.74/0.76/0.79 | 0.74/0.77/0.78 |
| BoolQ | 0.79/0.80/0.82/0.85 | 0.75/0.78/0.79 | 0.83/0.79/0.83 |
| Winogr. | 0.65/0.66/0.70/0.73 | 0.68/0.70/0.72 | 0.67/0.68/0.69 |
| ARC-E | 0.71/0.76/0.77/0.78 | 0.76/0.77/0.79 | 0.72/0.72/0.73 |
| ARC-C | 0.40/0.45/0.49/0.51 | 0.41/0.44/0.51 | 0.40/0.41/0.42 |
| WiC | 0.49/0.57/0.60/0.59 | 0.51/0.52/0.54 | 0.64/0.62/0.68 |
表1. 低比特量化模型零样本评估结果
此外,我们通过少样本消融实验探索了超低比特模型的应用潜力。一个有趣的发现是,超低比特模型(例如bpw:2.2/2.5),主要以INT2表示,在5样本辅助下可以恢复到原始FP16模型的零样本推理水平。这种利用少量示例样本的能力表明,低比特压缩技术正接近一个阶段,即它可以创建具有有限能力的“智能”语言模型。这在与RAG等检索增强技术结合时特别有效,使其适用于创建更具成本效益的模型服务。
| 5样本任务 | Phi-3 mini 128k (bpw:2.5/3.0/4.0/16) | Llama 3 8B (bpw:2.5/3.0/4.0) | Qwen1.5 14B (bpw:2.2/2.5/3.0) |
|---|---|---|---|
| PIQA | 0.76/0.78/0.76/0.76 | 0.75/0.77/0.79 | 0.76/0.79/0.79 |
| BoolQ | 0.79/0.80/0.86/0.86 | 0.79/0.80/0.81 | 0.86/0.84/0.86 |
| Winogr. | 0.67/0.68/0.72/0.72 | 0.70/0.71/0.74 | 0.69/0.71/0.71 |
| ARC-E | 0.77/0.79/0.81/0.82 | 0.77/0.79/0.82 | 0.78/0.81/0.81 |
| ARC-C | 0.44/0.50/0.54/0.53 | 0.44/0.47/0.51 | 0.47/0.50/0.49 |
| WiC | 0.53/0.56/0.65/0.62 | 0.60/0.55/0.59 | 0.64/0.61/0.62 |
表2. 低比特量化模型5样本评估结果
鉴于我们目前的少样本PTQ校准仅引入了有限的计算资源(包含512个样本的校准数据集),以我们的开源模型为基础进行更全面的全参数微调将进一步提高低比特模型在实际任务中的性能。我们已经提供了定制的开源工具来高效满足这一需求。
开源工具
我们发布了三款工具来支持这些模型的使用,并计划在未来不断优化和扩展它们。
Bitorch Engine (BIE)
Bitorch Engine (BIE)是一个尖端的神经网络计算库,旨在为现代AI研究和开发找到灵活性和效率之间的完美平衡。基于PyTorch,BIE为低比特量化神经网络操作定制了优化的网络组件。这些组件保持了深度学习模型的高精度和准确性,并显著减少了计算资源的消耗。它为低比特量化LLM的全参数微调奠定了基础。此外,BIE还提供了基于CUTLASS和CUDA的内核,支持1-8比特量化感知训练。我们还开发了一个专门为低比特组件设计的优化器DiodeMix,它有效解决了量化训练和推理表示之间的对齐问题。在开发过程中,我们发现PyTorch原生不支持低比特张量的梯度计算,这促使我们对PyTorch进行了轻微修改,以提供一个支持低比特梯度计算的版本,方便社区使用此功能。目前,BIE可以通过Conda和Docker安装,完全基于Pip的预编译安装版本也将很快向社区提供,以提供更多便利。
green-bit-llm
green-bit-llm是为GreenBitAI的低比特LLM开发的工具包。该工具包支持在云端和消费级GPU上的高性能推理,并与Bitorch Engine结合,支持直接使用量化LLM进行全参数微调和PEFT。它已兼容多个低比特模型系列,详细信息见表3。
| 大型语言模型 | 类型 | 比特 | 大小 | Hugging Face链接 |
|---|---|---|---|---|
| Llama-3 | 基础/指令 | 4.0/3.0/2.5/2.2 | 8B/70B | GreenBitAI Llama-3 |
| Llama-2 | 基础/指令 | 3.0/2.5/2.2 | 7B/13B/70B | GreenBitAI Llama-2 |
| Qwen-1.5 | 基础/指令 | 4.0/3.0/2.5/2.2 | 0.5B/1.8B/4B/7B/14B/32B/110B | GreenBitAI Qwen 1.5 |
| Phi-3 | 指令版 | 4.0/3.0/2.5/2.2 | 迷你 | GreenBitAI Phi-3 |
| Mistral | 基础/指令 | 3.0/2.5/2.2 | 7B | GreenBitAI Mistral |
| 01-Yi | 基础/指令 | 4.0/3.0/2.5/2.2 | 6B/9B/34B | GreenBitAI 01-Yi |
表3. 支持的低比特LLM
我们以最新的Llama-3 8B基础模型为例。我们选择对其进行2.2/2.5/3.0比特精度的量化监督微调(Q-SFT),重点关注整个参数集。我们使用了Hugging Face上托管的“tatsu-lab/alpaca”数据集,其中包含52,000个训练对话样本。模型在一个epoch内进行训练,指令微调最少,严格在量化权重空间内对齐,不涉及传统的后处理步骤,如LoRA参数优化和集成。训练后,模型可以直接部署进行推理,无需更新任何其他FP16参数,从而验证了量化学习的有效性。Q-SFT前后以及经典LoRA微调对模型能力的影响如表4所示。
| 零样本任务 | 基础(bpw 2.2/2.5/3.0) | LoRA(bpw 2.2/2.5/3.0) | Q-SFT + Galore (bpw 2.2/2.5/3.0) | Q-SFT(bpw 2.2/2.5/3.0) |
|---|---|---|---|---|
| PIQA | 0.72/0.74/0.76 | 0.75/0.77/0.78 | 0.75/0.76/0.78 | 0.75/0.76/0.79 |
| BoolQ | 0.74/0.75/0.78 | 0.77/0.76/0.80 | 0.77/0.76/0.79 | 0.78/0.78/0.80 |
| Winogr. | 0.67/0.68/0.70 | 0.68/0.69/0.71 | 0.68/0.69/0.71 | 0.67/0.69/0.72 |
| ARC-E | 0.73/0.76/0.77 | 0.77/0.77/0.79 | 0.76/0.77/0.79 | 0.75/0.76/0.79 |
| ARC-C | 0.39/0.41/0.44 | 0.46/0.44/0.49 | 0.45/0.43/0.47 | 0.45/0.43/0.49 |
| WiC | 0.50/0.51/0.52 | 0.50/0.50/0.52 | 0.50/0.52/0.57 | 0.50/0.51/0.60 |
| 平均 | 0.62/0.64/0.66 | 0.65/0.65/0.68 | 0.65/0.65/0.68 | 0.65/0.65/0.69 |
表4. Q-SFT对零样本能力的影响
除了我们的低比特模型,green-bit-llm还完全兼容AutoGPTQ系列的4比特量化和压缩模型。这意味着Hugging Face上所有2,848个现有的4比特GPTQ模型都可以使用green-bit-llm在量化参数空间中进行低资源进一步训练或微调。作为LLM部署生态系统中最流行的压缩格式之一,现有的AutoGPTQ爱好者可以使用green-bit-llm无缝切换模型训练和推理,而无需引入新的工程步骤。
我们创新的DiodeMix优化器专门为低比特模型设计,是Q-SFT在低资源设置下稳定运行的关键。该优化器有助于缓解FP16梯度和量化空间之间的不匹配问题。量化参数更新过程巧妙地转化为基于参数组之间累积梯度相对大小的排序问题。开发更符合量化参数空间的优化器将是我们持续研究的重要方向。
gbx-lm
gbx-lm将GreenBitAI的低比特模型适配到Apple的MLX框架,实现在Apple芯片上高效运行大型模型。它目前支持模型加载、生成和LoRA微调等基本操作。此外,该工具提供了一个演示,说明用户可以按照我们详细的指南,在Apple设备上快速建立本地聊天演示页面。
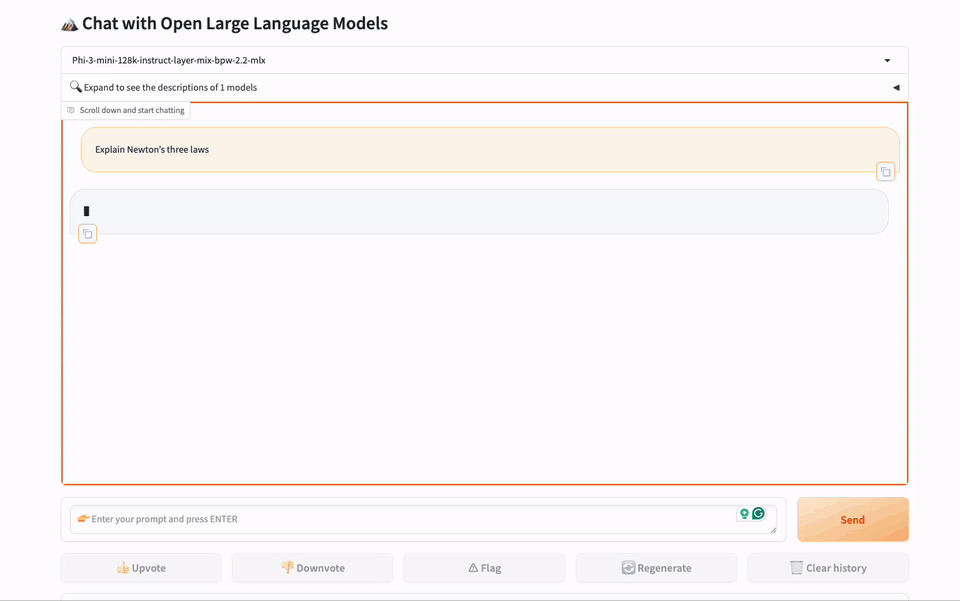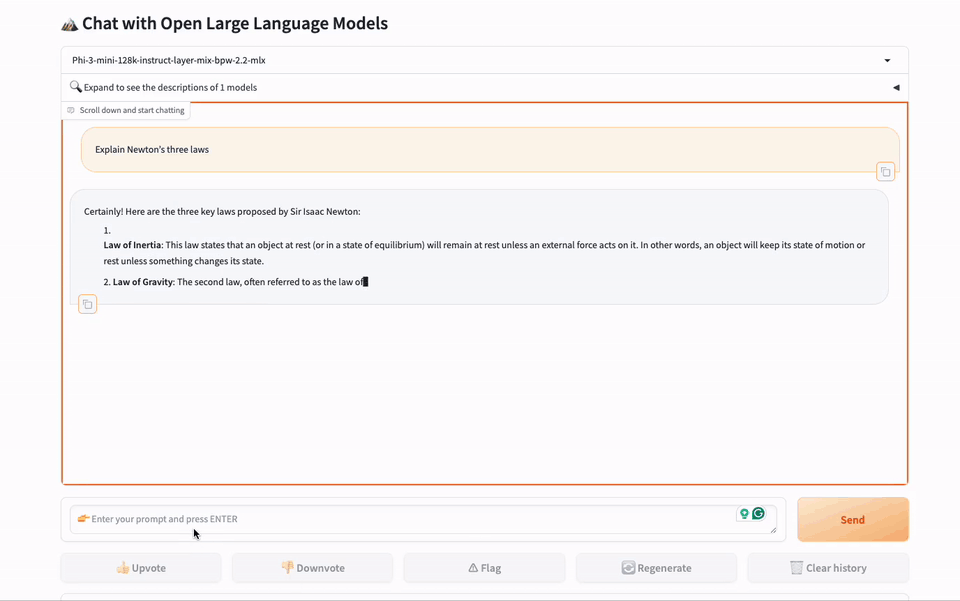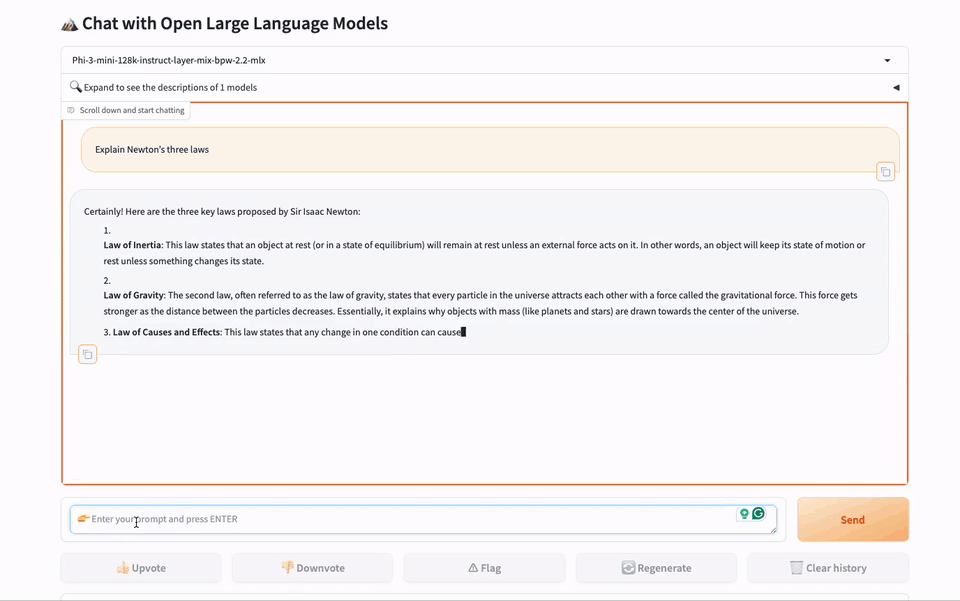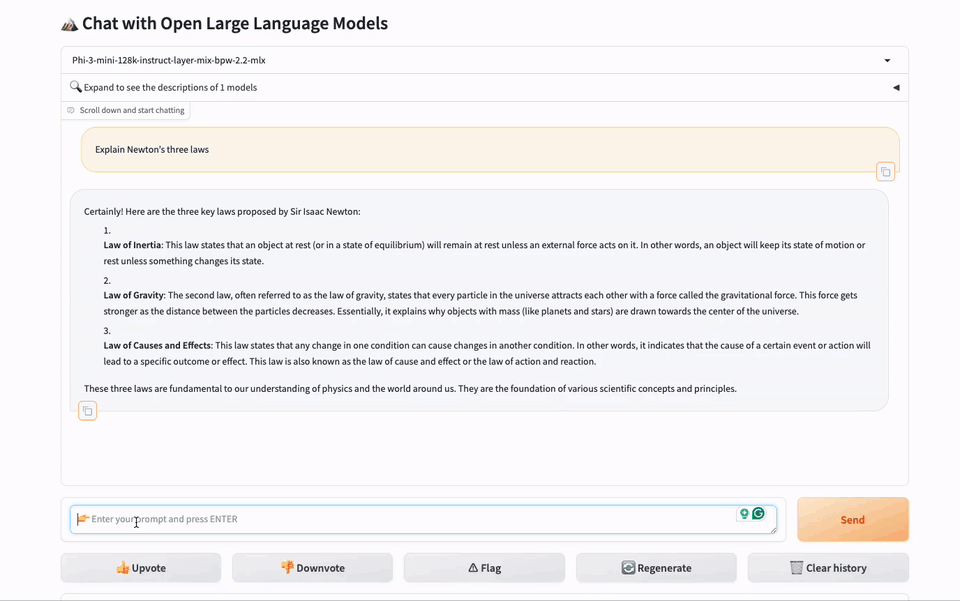 图2. 使用gbx-lm引擎在MacBook上进行网页聊天演示。
图2. 使用gbx-lm引擎在MacBook上进行网页聊天演示。
总结
我们期待与更多开发者共同推动开源社区的发展。如果您对此充满热情并希望与志同道合的伙伴一起进步,请不要犹豫!我们真诚欢迎您加入我们。您可以通过社区平台或直接发送电子邮件至team@greenbit.ai与我们联系。
链接:
- 模型库: GreenBitAI
- BIE: bitorch-engine
- green-bit-llm: green-bit-llm
- gbx-lm: gbx-lm



