食谱:为 TTS 训练准备多语言语音数据集







本食谱介绍了我们如何准备数据集来训练 Parler TTS mini v1.1 多语言模型,您可以在此处尝试。
配料
我们使用了 2 个涵盖法语、波兰语、德语、荷兰语、意大利语、葡萄牙语和西班牙语的多语言开源数据集
什么是 Parler TTS?
Parler-TTS 是一种轻量级文本转语音 (TTS) 模型,能够以给定说话者(性别、音调、说话风格等)的风格生成高质量、自然的声音。它重现了 Stability AI 和爱丁堡大学的 Dan Lyth 和 Simon King 在论文“使用合成注释进行高保真文本转语音的自然语言指导”中提出的工作。
Parler TTS 项目是由 Hugging Face 发起的一个开源项目。您可以在 huggingface.co/parler-tts 了解更多信息。
模型性能
为了进行评估,我们生成了一个测试集,其中包含每种语言的 40 个样本。描述提示遵循模型训练期间使用的相同结构。虽然这些受控样本有助于建立模型能力基线,但它们可能无法完全代表真实世界性能,尤其是当提示与训练格式显著偏离时。
以下是各种语言的词错误率 (WER) 结果
| 语言 | 词错误率 (%) |
|---|---|
| 西班牙语 | 0.70 |
| 德语 | 1.13 |
| 英语 | 1.19 |
| 法语 | 2.31 |
| 意大利语 | 3.16 |
| 波兰语 | 4.02 |
| 荷兰语 | 4.38 |
| 葡萄牙语 | 5.08 |
先决条件
最初的 Parler-TTS 分词器是专门为英语量身定制的。由于其词汇量有限且没有字节回退机制(一种将分词器词汇中未找到的单词部分映射到标记的系统),因此它不适用于多语言训练。
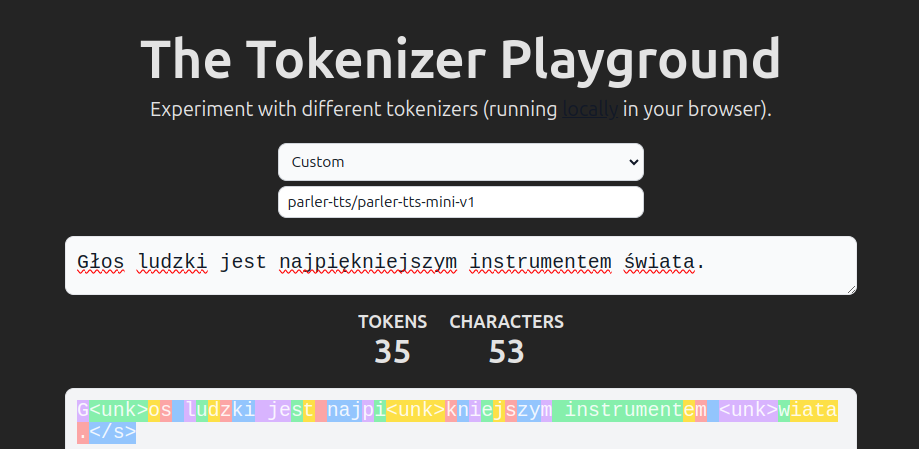
Parler-TTS v1.1 采用了一种改进的分词器,其中包含字节回退。您可以通过在 Tokenizer Playground 中选择 parler-tts/parler-tts-mini-v1.1 作为您的自定义分词器来探索此分词器在不同语言中的功能。
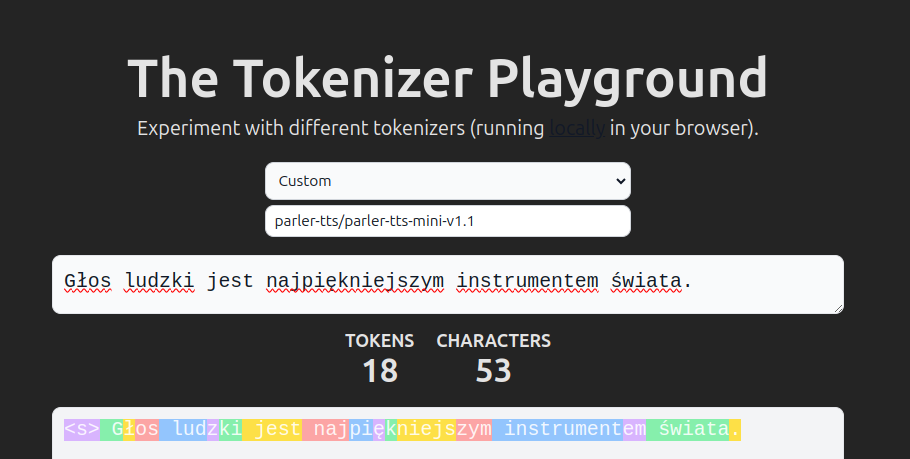
注意:Parler-TTS v1.1 现在使用两个不同的分词器,一个用于描述,另一个用于提示。
方法
1. 更新 Phonemizer 并添加标点恢复
我们已从 g2p 库过渡到使用 espeak-ng 后端的 phonemizer,以显著扩展我们的语言支持能力。
切换到 ESpeak-NG 作为我们的音素化后端带来了对 100 多种语言和变体的支持,包括
- 日耳曼语族:英语、德语、荷兰语、瑞典语、丹麦语、挪威语
- 罗曼语族:法语、西班牙语、意大利语、葡萄牙语、罗马尼亚语
- 斯拉夫语族:俄语、波兰语、捷克语、斯洛伐克语、克罗地亚语、塞尔维亚语
- 亚洲语言:普通话、日语(平假名)、韩语、越南语
- 印度语族:印地语、孟加拉语、泰米尔语、泰卢固语
- 闪族语族:阿拉伯语、希伯来语
- 非洲语言:斯瓦希里语、祖鲁语、南非荷兰语
如果您想使用 dataspeech 当前不支持的语言数据集,您需要
- 更新 phonemizer
- 更新大小写模型(内部使用 spaCy)
- 更新标点恢复模型(目前使用 deepmultilingualpunctuation)
- 您可以在 hub 上找到微调版本或微调您自己的版本
- 标点恢复和大小写脚本可在此处找到
2. 初始清洗
清洗过程侧重于删除可能对模型训练产生负面影响的低质量样本。这包括音频文本不匹配、音频质量差或转录不正确的样本。
计算每个样本的 Levenshtein 相似度分数
- Levenshtein 距离通过计算单字符操作(插入、删除、替换)的最小数量来衡量两个字符串的不同程度
- 我们将其归一化为 0-1 的相似度分数,其中 1 表示完美匹配
- 这有助于验证转录的质量
删除 Levenshtein 相似度分数 < 0.9 的样本
- 这消除了不正确/不完整的转录
- 0.9 的分数表示字符串有 90% 的相似度,允许微小变化,同时过滤掉主要差异
- 我们仅对 CML-TTS 数据集执行了此清洗
- 您可以在 huggingface.co/datasets/PHBJT/cml-tts-filtered 找到已清洗版本
以下是 原始数据集 中存在的一些无效样本示例
| 原始数据集转录 | 重新计算的转录 | 音频样本 | 分数 |
|---|---|---|---|
| omstreken. Het derde | van het derde boek | 0.32 | |
| Não peço mais ao | fim do capítulo vinte sete gravado por felipe valle | 0.18 |
3. 注释过程
现在我们已经对多语言音频数据集进行了注释和清理,我们可以根据注释生成自然语言描述,如 dataspeech 库 中所示
准备转录数据
- 使用数据集中的现有转录
- 恢复转录中的标点和大小写(两者都非常重要)
生成样本描述(在 dataspeech 的实用脚本 中处理)
- 计算句子指标(语速等)
- 将指标输入到 LLM
- 为每个样本生成描述性文本
这些数据集与 LibriTTS-R 英语数据集 一起用于训练 Parler TTS mini V1.1 多语言模型。
如果您想用其他语言微调 Parler TTS mini V1.1,Parler-TTS 库 中提供了训练食谱。




