使用 BHI 过滤单图像超分辨率数据集







简介
我为他人创建了我的 vitepress 网站,并使用和视觉比较了 600 多种不同的超分辨率模型。自那时以来,我自行训练并发布了 100 多个单图像超分辨率(SISR)模型,这些模型基于 15 种不同的架构,如 MoSR、RealPLKSR、DRCT、SPAN、DAT 或 ATD 及其各自的架构选项。
这些模型可在我的 GitHub 模型仓库、Huggingface 个人资料或 openmodeldb 上找到,并且可以在这个 ZeroGPU Huggingface Space 上在线试用。
出于 SISR 训练的目的,我偶尔会策划数据集,最早是在 2023 年 8 月,我为我的 FaceUp 模型系列制作了一个名为 FaceUp 的 FFHQ 策划版本,其中我使用了 HyperIQA 图像质量度量进行过滤。
在这篇文章中,我将评估我过去用于 SISR 模型训练的两种数据集过滤技术的影响,即 HyperIQA 和 IC9600 用于复杂度过滤。
方法
我的目标是为数据集找到一个简单的数据集策划工作流程,该工作流程通常可以提高质量(模型训练验证指标分数)或效率(通过减少图像数量同时保持相似的验证指标分数来节省存储空间)。
BHI(块效应、HyperIQA、IC9600)过滤方法是我提出的,我将通过运行测试并查看其结果来评估其有效性或无效性。
我的方法如下:
- 在标准数据集上训练一个 SISR 模型,同时生成验证指标分数,这将作为基线模型。
- 使用 HyperIQA 和 IC9600 对该数据集进行评分。
- 使用这两种方法以不同的阈值过滤数据集。
- 在每个过滤后的数据集上训练 SISR 模型,同时生成验证指标分数。
- 根据与基线模型相比的指标分数,评估数量减少的有效性。
- 从测试中为 HyperIQA 和 IC9600 各自推导出一个好的阈值,然后将这些过滤技术结合起来,根据这些阈值创建一个经过策划的数据集版本。
- 使用相同的选项在该策划数据集上训练一个 SISR 模型,同时生成验证指标分数。
- 根据数量减少及其最终评分指标与基线模型进行比较来评估有效性。
DF2K 主测试
系统设置
所有测试都在我的家用电脑上完成,以下是我的配置:
Ubuntu 20.04.6 LTS 64 位
RTX 3060 (12 GB 显存)
16 GiB 内存
AMD® Ryzen 5 3600 6 核处理器 × 12
数据集
我选择的数据集是 DF2K 数据集,它是 DIV2K 和 Flicker2K 数据集的组合,常被用作新 SISR 架构论文的标准训练数据集。
此外,在查看PLKSR 论文时,他们从头开始训练了所有 plksr_tiny 模型(因此没有使用预训练策略),其中在 DF2K 上训练的模型比仅在 DIV2K 上训练的模型获得了更好的指标分数。

为了提高训练期间的 I/O 速度,采用了平铺策略,正如 real-esrgan 仓库的训练部分 所建议的。将 DF2K 平铺到 512x512 像素后,训练数据集现在包含 21387 个平铺图像。
这个平铺版本的 DF2K 数据集将用于训练基础模型并进行过滤,可以在这里找到。由于所有过滤都将在我上传到 Huggingface 的这个平铺数据集上完成,因此本帖中用于训练的所有过滤子集及其各自的指标分数都是可重现的。
编辑:BHI 过滤版本的 DF2K 可以在这里找到。
训练
Plksr_tiny 是一种训练速度较快、在论文中得分高于 SAFMN、DITN 或 SPAN 的架构选项,将用于以 4 倍尺度运行这些测试。
用于配对训练的低分辨率 (LR) 对应物将仅通过双三次下采样创建。
为了重现性,我提供了下载基线模型高分辨率(HR)和低分辨率(LR)数据集的链接。
DF2K 分块 HR 的链接
DF2K 分块 LR 的链接
至于训练框架,对于所有这些测试,都使用了 neosr,其 提交哈希为 dc4e3742132bae2c2aa8e8d16de3a9fcec6b1a74,并使用了 确定性训练。
通常使用 fp16 格式,批次大小为 16,补丁大小为 32 进行模型训练,并使用 lr 1e-4,betas [0.9,0.99] 的 adamw 作为优化器,使用 60k 和 120k 里程碑的 multisteplr 作为调度器,仅使用 L1Loss,并启用 EMA。
训练配置通常将可用于重现。虽然默认配置中有很多选项,但为了视觉清晰度,这些选项已通过删除 neosr 中提供的标准配置中所有注释掉的选项而缩短。
验证
DIV2K 数据集是 DF2K 的一个子集,提供了包含 100 张图像的官方验证集,以及其高分辨率和相应的低分辨率对应物。我们将在训练期间使用此验证集进行验证。
训练期间的验证将每 10,000 次迭代发生一次,这将提供足够的数据,同时不会因运行推理而过多地减慢训练速度,验证将使用 PSNR、SSIM 和 DISTS 指标。
官方 DIV2K 验证集可以在这里下载
指标
每次测试我都会提供 Tensorboard 图表,以可视化模型训练的 PSNR、SSIM 和 DISTS 验证指标。
PSNR 和 SSIM 经常在论文中用作验证指标。由于 DISTS 已添加到 neosr,我也获得了此指标的 Tensorboard 图表。
目前有 25 个全参考(和 45 个非参考)指标选项可用于 pyiqa,我在尝试从模型训练的检查点中找到发布候选时,全部运行了一次。在本测试结束时,我将在策划模型上(除了 PSNR、SSIM 和 DISTS)额外使用 topiq_fr 和 AHIQ 指标,这些指标在我的经验中表现良好。
浮点格式
测试使用 fp32、fp16 或 bf16 进行训练的不同选项,基线模型(在完整的平铺 DF2K 数据集上)已在所有这些格式上训练了 200,000 次迭代。
从 Tensorboard 的以下图表中可以看出,尽管验证指标分数差异很小,但 fp16 提供了最大的训练时间改进,因此除非另有说明,否则今后将用于测试。
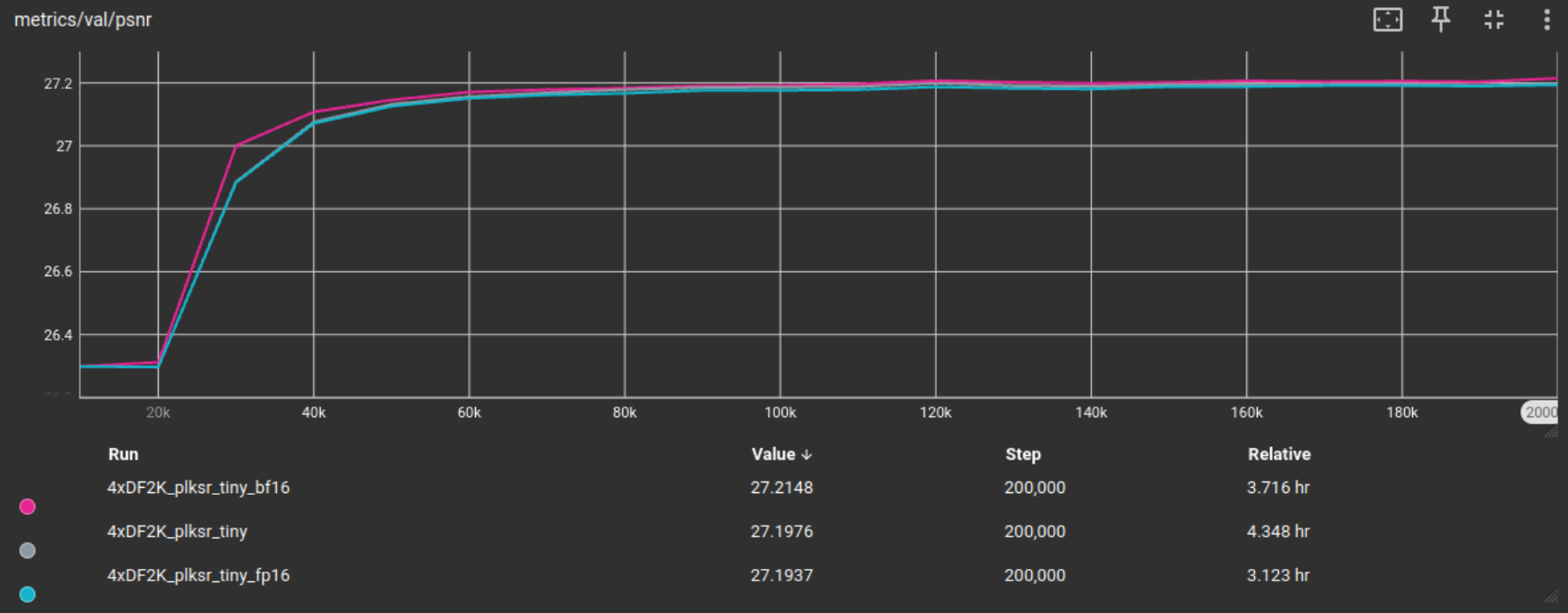


基线模型及其训练配置可以在这里找到
BHI 方法使用块效应、HyperIQA 和 IC9600 过滤进行 SISR 训练数据集策划,我将在以下部分中按此顺序介绍这些过滤技术。
块效应
我将块效应过滤添加到此策划工作流程中,阈值为 30,因为他们在 《重新思考图像超分辨率的训练数据视角》 论文中已经测试并表明,在训练集中添加 75% 或更低的 jpg 压缩对 sisr 训练过程可能非常有害,如其图 5 所示,而且通常情况下,较低的块效应会导致指标值提高(Manga109 测试集除外),如其表 4 所示。由于将块效应阈值从 30 降低到 10 并未导致验证指标分数增加,因此我们的 BHI 过滤方法使用块效应阈值 < 30。这些视觉效果为了方便起见插入在此处,并取自他们的论文。


为了可视化,最低和最高块效应得分的瓦片


HyperIQA 过滤
图像质量评估的目的是通常通过为其分配分数来评估图像的视觉感知质量。我在这里的假设是,IQA 可以用于通过过滤评分瓦片来提高整个训练数据集的质量,从而去除评分不佳的瓦片(例如模糊和嘈杂的瓦片)。
我们将测试这个假设。
对于图像质量评估,我在 DF2K 瓦片数据集上使用 HyperIQA 评分。
我使用 HyperIQA 对分块的 DF2K 数据集进行了评分,分数可以在这里找到。
为了可视化,我在此插入最低和最高 HyperIQA 评分的瓦片。


根据该评分,我创建了以下过滤后的训练子集,以及剩余瓦片数量和占完整分块数据集的百分比:
HyperIQA 分数 >= 0.1 -> 未过滤,完整集 = 基础模型 (100%)
HyperIQA 分数 >= 0.2 -> 21,347 块 (99.8%)
HyperIQA 分数 >= 0.3 -> 20,689 块 (96.7%)
HyperIQA 分数 >= 0.4 -> 18,477 块 (86.4%)
HyperIQA 分数 >= 0.5 -> 14,572 块 (68.1%)
HyperIQA 分数 >= 0.6 -> 8,471 块 (39.6%)
HyperIQA 分数 >= 0.7 -> 1,780 块 (8.3%)
HyperIQA 分数 >= 0.8 -> 44 块 (0.2%)
然后我对每个子集训练了 fp16 模型,每个模型迭代 100k 次,除了 0.8 子集,因为它剩下的瓦片太少,无法进行有意义的训练。结果显示在以下图形中,并以 fp16 基线模型作为参考点。



在所有这些指标中,在 HyperIQA 分数 >= 0.2 过滤后的训练子集上进行训练,给了我们更好的指标。我们将把这个作为 BHI 过滤数据集的阈值。
令我惊讶的是,我曾假设数据集的整体 IQA 分数越高(即以更高的 IQA 分数过滤),指标就会越好。从 PSNR 和 SSIM 来看,情况似乎并非如此。相反,只移除最差的瓦片(分数低于 0.2)似乎对训练验证指标产生了积极影响。
我还要在这里指出,PSNR 和 SSIM 得分高于基线模型的模型仍包含超过 90% 的分块数据集瓦片,而使用更高阈值时瓦片数量显著下降,因此瓦片的数量可能在这些验证指标中发挥作用。
IC9600 过滤
另一个假设是,增加数据集的总体复杂度(增加每个训练瓦片上的信息量)也将有利于 SISR 训练,或者更确切地说,有利于 SISR 训练数据集的策划。
对于图像复杂度自动评估,我使用 IC9600 对 DF2K 瓦片数据集进行评分,其分数可在此处找到。
为了可视化,最低和最高的 IC9600 评分瓦片


根据评分,我创建了以下过滤后的子集:
IC9600 分数 >= 0.1 -> 20,807 瓦片 (97.3%)
IC9600 分数 >= 0.2 -> 19,552 瓦片 (91.4%)
IC9600 分数 >= 0.3 -> 17,083 瓦片 (79.9%)
IC9600 分数 >= 0.4 -> 12,784 瓦片 (59.8%)
IC9600 分数 >= 0.5 -> 6,765 瓦片 (31.6%)
IC9600 分数 >= 0.6 -> 1,918 瓦片 (9.0%)
IC9600 分数 >= 0.7 -> 318 瓦片 (1.5%)
IC9600 分数 >= 0.8 -> 44 瓦片 (0.2%)
然后我对每个子集训练了 fp16 模型,每个模型迭代 100k 次,除了 0.8 子集,因为它剩下的瓦片太少,无法进行有意义的训练。结果显示在以下图形中,并以 fp16 基线模型作为参考点。

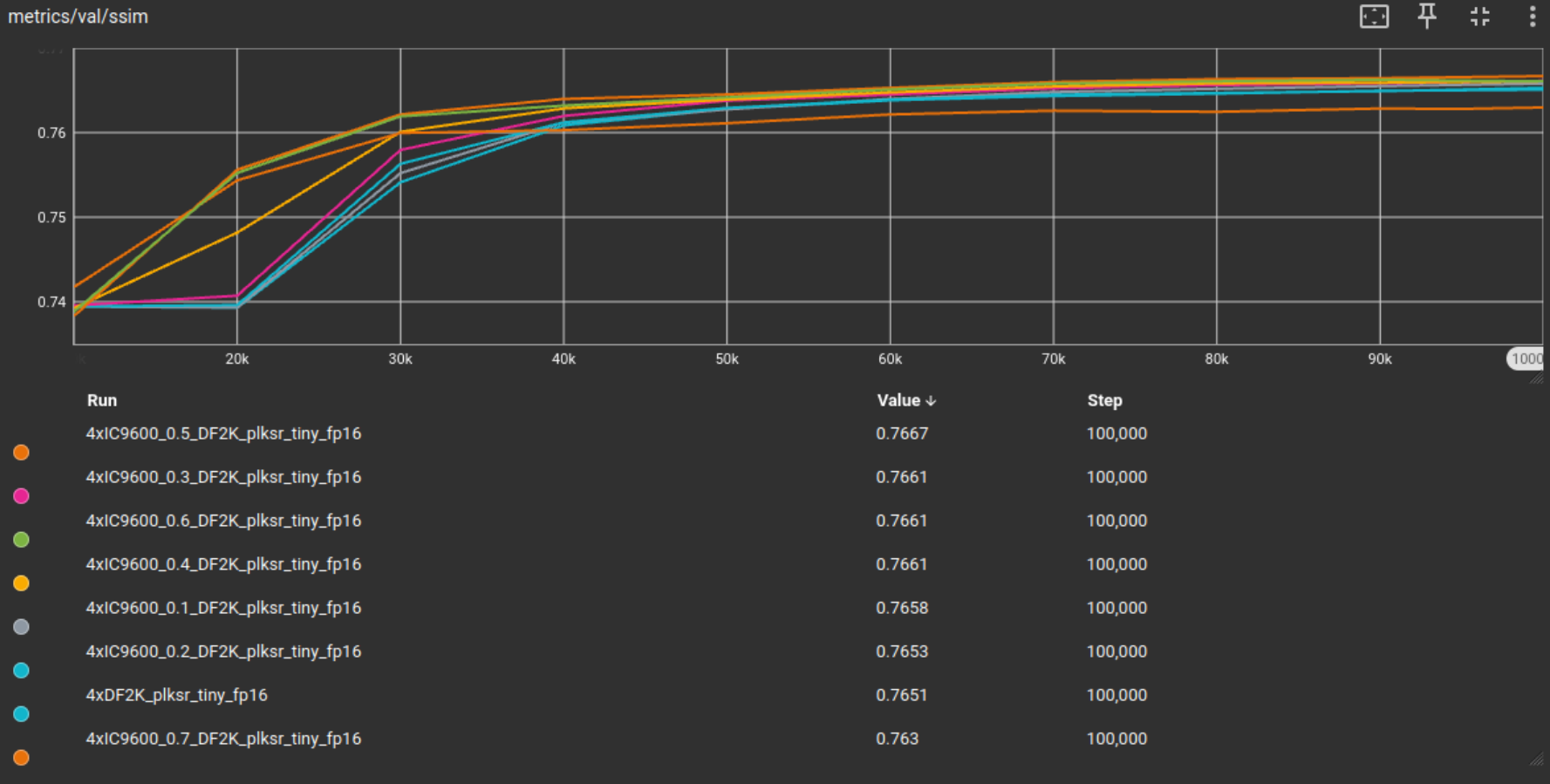

从这些结果来看,IC9600 过滤似乎对训练有积极影响。模型不仅收敛更快,或者在训练的早期迭代中达到更高的指标分数,而且通常能够达到更高的验证指标。在 PSNR 和 SSIM 中,阈值 0.5 达到了最高的指标值。总体而言,这暗示更高的 IC9600 阈值通常是有益的。高于 0.5 的阈值得分较差可能是因为训练集中瓦片数量的大幅减少。
BHI 过滤
现在,我将之前的过滤方法结合到 BHI 过滤方法中,使用从先前测试中确定的阈值:
块效应 < 30,HyperIQA >= 0.2,IC9600 >= 0.5
我在现在经过 BHI 过滤的 DF2K 分块数据集上训练了一个 fp16 模型。瓦片的数量如下:
基线 DF2K 模型:21,387 块 策划的 DF2K 模型:6,620 块 (31%)
以下是训练验证结果,合并在此处意味着组合过滤技术,即 BHI 过滤的 DF2K 分块训练集。



从结果来看,BHI 过滤 DF2K 分块数据集不仅使训练数据集大小减少了 69%,同时在 DIV2K 验证集上实现了更好的 PSNR、SSIM 和 DISTS 验证指标分数。
尽管我认为 10 万次迭代对于 plksr_tiny 这种轻量级网络选项的测试通常就足够了,但在 PLKSR 论文中,他们从头开始训练 plksr_tiny 模型,迭代次数高达 45 万次。由于这是最终的 DF2K 分块测试,我也会将训练迭代次数增加到 50 万次,以便能够捕捉到长时间训练迭代可能发生的情况。

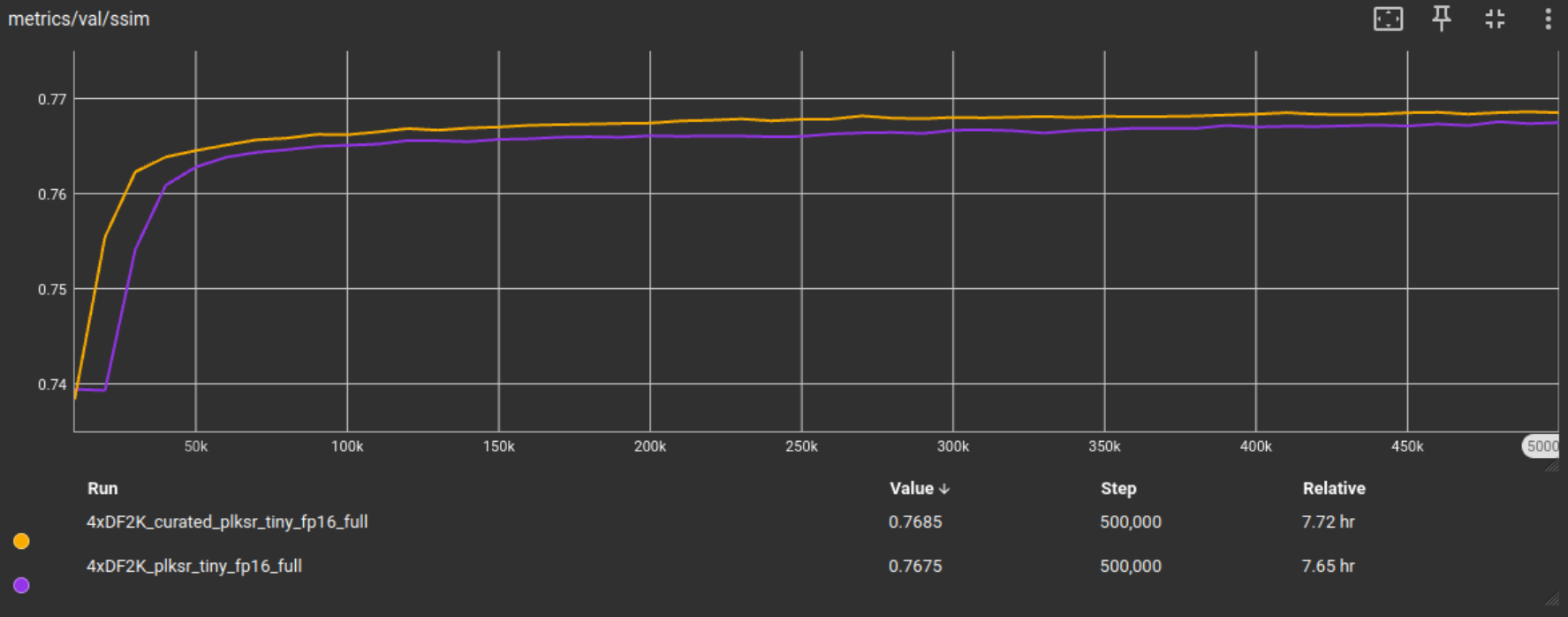

我们可以看到,指标分数有所提高,并且由于块效应过滤等过滤技术,随着迭代次数的增加,指标会持续略微改善。
为了确保这些结果不是 DIV2K 测试集特有的,我将在多个官方测试集上测试这些最终模型,并使用多个指标。具体来说,是 Urban100、BSD100、DIV2K 和 LSDIR 测试集,使用 PSNR、SSIM、DISTS、AHIQ 和 TOPIQ_FR FR(全参考)IQA 指标。
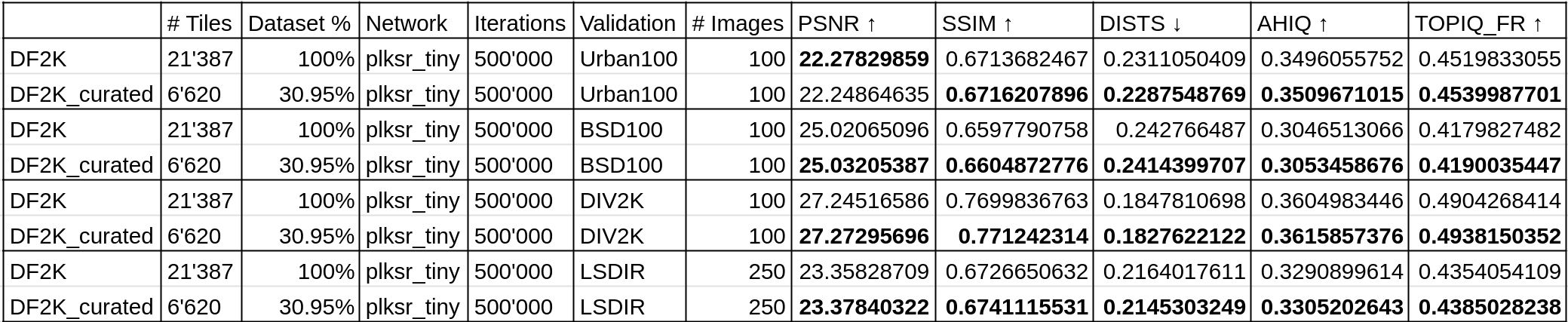
即使使用更多的测试集和指标,先前的评估仍然成立,在 BHI 过滤的 DF2K 分块测试集上训练的模型通常能够获得更好的指标分数。BHI 过滤方法在 DF2K 分块数据集上与 plksr_tiny 架构选项结合使用是有效的,它在减少训练数据集大小的同时,在多个测试集上使用多个指标取得了更好的结果。
顺便说一句,作为一项额外的 10 万次迭代快速测试,我想看看如果改变一个参数,即补丁大小,并将其从 32 翻倍到 64,会发生什么。一般来说,增加训练补丁大小会导致更好的视觉模型输出。


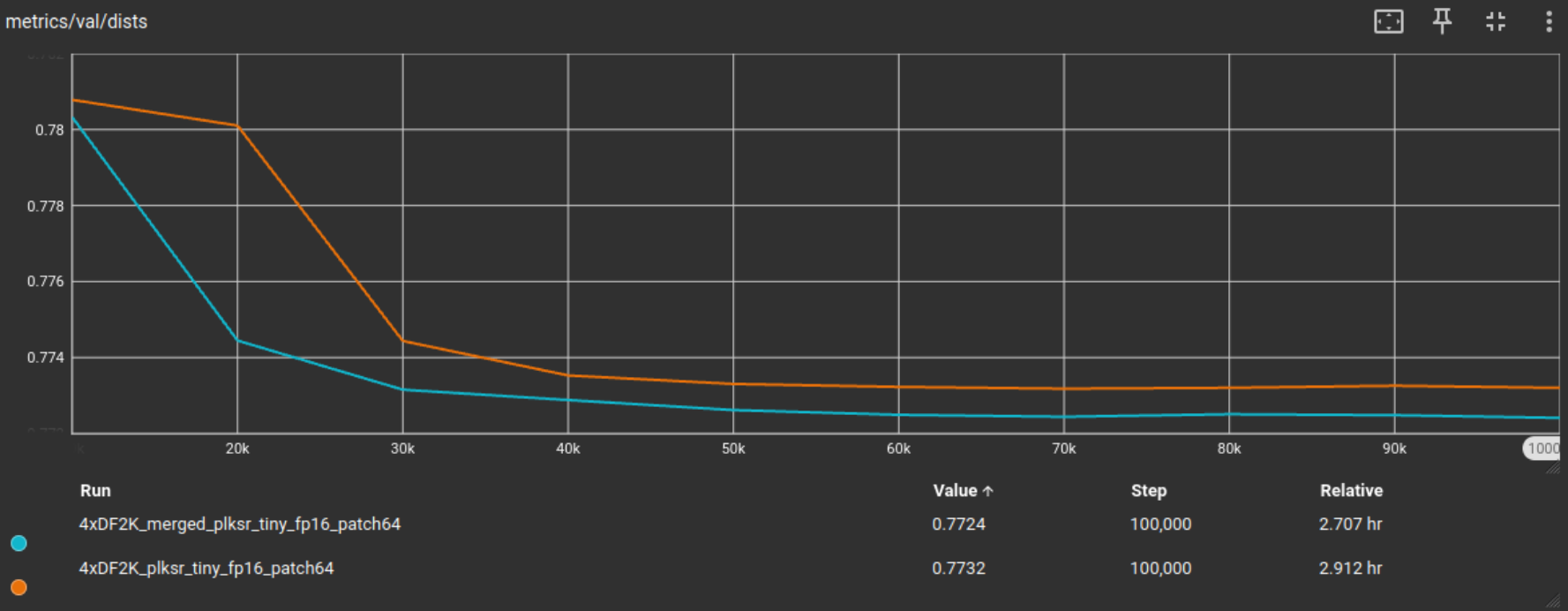
我们获得了与之前的 32x32 补丁 10 万次迭代测试类似的结果,指标略有提高。
ImageNet 附加测试
为了测试这是否与数据集或架构选项无关,我使用 ImageNet 数据集重复了此过滤方法,ImageNet 数据集通常用于论文中的预训练策略(如 PLKSR 中的标准模型)。
将数据集平铺为 512x512 像素后,我们剩下 197,436 个瓦片。
相应的低分辨率(LR)再次通过双三次下采样创建,比例为 0.25,用于 4 倍模型训练。
训练验证在 Urban100 测试集上进行。
至于架构选项,这次我们使用 SPAN,它比 plksr_tiny 略快,并且在 CVPR 2024 NTIRE 的高效超分辨率挑战赛(ESR)中获得第一名。
所有与此测试相关的文件都在 imagenet 子文件夹中。
HyperIQA 过滤
如前所述,我们使用 HyperIQA 对 ImageNet 分块数据集进行评分,并根据不同的阈值创建子集。
HyperIQA 分数 >= 0.1 -> 未过滤,完整集 = 基础模型 (100%)
HyperIQA 分数 >= 0.2 -> 195,500 瓦片 (99.0%)
HyperIQA 分数 >= 0.3 -> 162,991 瓦片 (82.6%)
HyperIQA 分数 >= 0.4 -> 105,809 瓦片 (53.6%)
HyperIQA 分数 >= 0.5 -> 54,819 瓦片 (27.8%)
HyperIQA 分数 >= 0.6 -> 18,397 瓦片 (9.3%)
HyperIQA 分数 >= 0.7 -> 1,592 瓦片 (0.8%)
HyperIQA 分数 >= 0.8 -> 16 瓦片 (<0.1%)
然后我对每个子集训练了 fp16 模型,每个模型迭代 100k 次,除了 0.8 子集,因为它剩下的瓦片太少,无法进行有意义的训练。结果显示在以下图形中,并以 fp16 基线模型作为参考点。
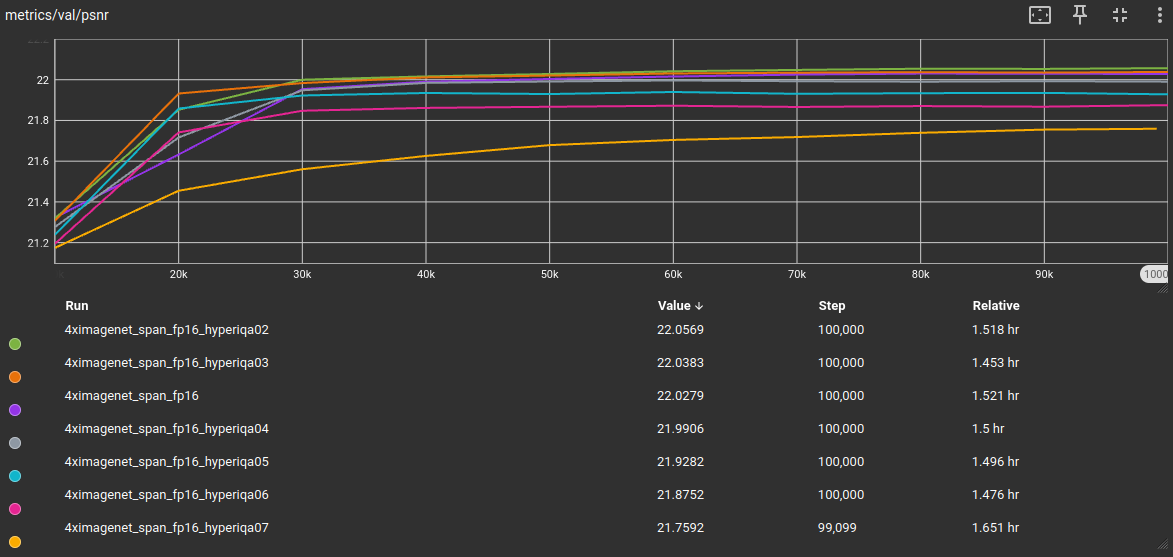


我们得到了与分块 DF2K 数据集相似的结果。这是一件好事,因为它意味着之前的结果既不依赖于数据集,也不依赖于架构选项。
IC9600 过滤
如前所述,我们使用 IC9600 对 ImageNet 分块数据集进行评分,并根据不同的阈值创建子集。
IC9600 分数 >= 0.1 -> 189,120 瓦片 (95.8%)
IC9600 分数 >= 0.2 -> 166,824 瓦片 (84.5%)
IC9600 分数 >= 0.3 -> 129,410 瓦片 (65.5%)
IC9600 分数 >= 0.4 -> 74,987 瓦片 (38.0%)
IC9600 分数 >= 0.5 -> 24,989 瓦片 (12.7%)
IC9600 分数 >= 0.6 -> 3,607 瓦片 (1.8%)
IC9600 分数 >= 0.7 -> 446 瓦片 (0.2%)
IC9600 分数 >= 0.8 -> 49 瓦片 (<0.1%)
然后我对每个子集训练了 fp16 模型,每个模型迭代 100k 次,除了 0.8 子集,因为它剩下的瓦片太少,无法进行有意义的训练。结果显示在以下图形中,并以 fp16 基线模型作为参考点。



这次,之前 0.5 的阈值反而得到了更差的结果,这可能 again 源于训练图像瓦片数量的更大减少。我们将 IC9600 过滤的阈值调整为 0.4,这在 SSIM 和 DISTS 上取得了最好的指标,在 PSNR 上取得了第二好的指标。
BHI 过滤
我们将 BHI 过滤方法应用于分块的 ImageNet 数据集,参数如下:
块效应 < 30
HyperIQA >= 0.2
IC9600 >= 0.4
我在现在经过 BHI 过滤的 ImageNet 分块数据集上训练了一个 fp16 模型。瓦片数量如下:
基线 ImageNet 模型:197,436 瓦片
策划的 ImageNet 模型:4,505 瓦片 (2.3%)
以下是 Urban100 测试集上的训练验证结果:
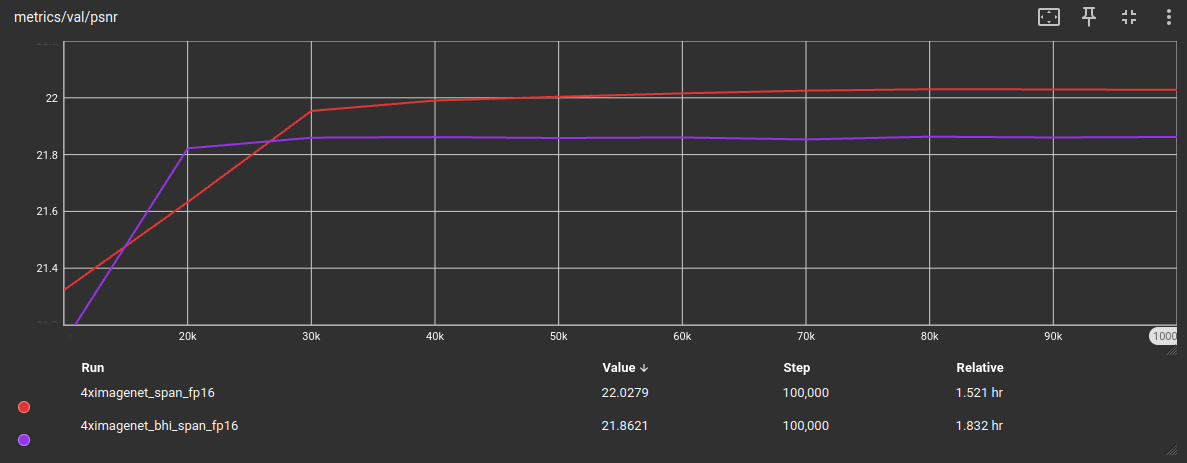


虽然在 DISTS 指标上这两个模型接近,但在 PSNR 和 SSIM 上它们之间存在更宽的指标差距。我假设这可能是由于训练集中瓦片数量的大幅减少(-97.71824%)造成的。
导致瓦片数量大幅减少的最大影响是块效应过滤,因为 ImageNet 受 JPG 伪影困扰。我们可以通过可视化它们的块效应分布来查看这两个使用的数据集之间的差异。


深蓝色部分是当前块效应过滤阈值所保留的部分。在 DF2K 中,21,387 个瓦片中有 20,873 个瓦片满足此标准(97.6%),而在 ImageNet 中,197,436 个瓦片中只有 6,787 个瓦片满足块效应得分低于 30 的标准(3.4%)。
通过大幅减少训练瓦片,训练信息会丢失。在这种情况下,我们希望通过将此 BHI 过滤后的 ImageNet 数据集与另一个 BHI 过滤后的数据集(例如,将此数据集与之前的 DF2K-BHI 集结合)来增加瓦片数量。或者更好的是,使用另一个受 JPG 伪影困扰较少的数据集。
为了评估是否确实是训练瓦片数量减少的原因,我将块效应阈值提高到 90,或者从视觉上来说,我们现在使用深蓝色、橙色和黄色部分进行训练。这使我们获得了更大一部分完整数据集,具体来说是 60,314 个瓦片(30.5%)。
正如所料,当增加块效应阈值以使更多的训练瓦片在 BHI 过滤过程中幸存下来时,验证指标再次接近基线模型,同时减少了整体训练数据集的大小。


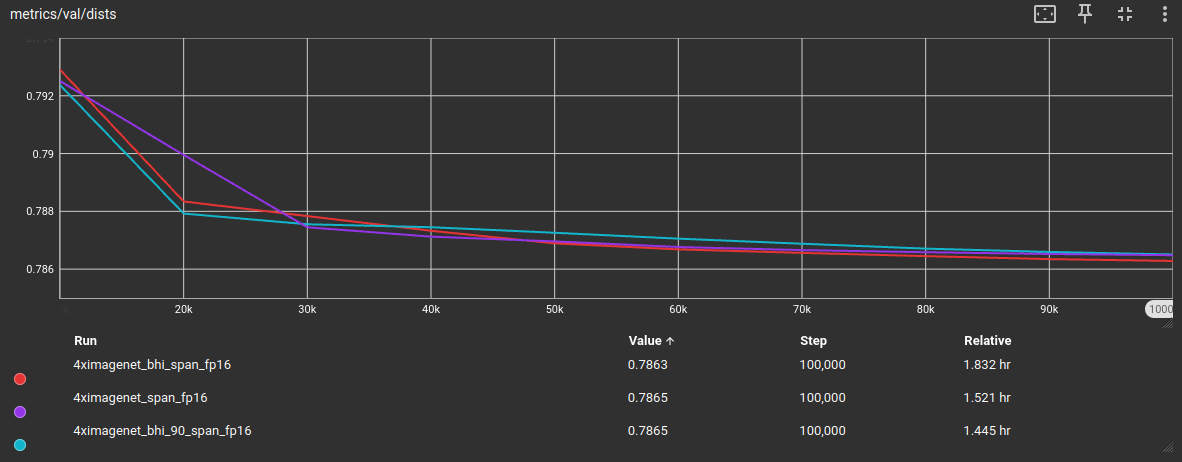
出于好奇,由于我将 IC9600 阈值从 >= 0.5 调整到 >= 0.4,我想测试一下之前的 DF2K 平铺数据集是否会从这个变化中受益。因此,我训练了另一个 plksr_tiny 模型,进行了这些调整,并使用相同的 DIV2K 验证数据集进行训练期间的验证指标评估。



这些测试结果表明,BHI 过滤方法可以有效地策划 SISR 训练数据集,通过大幅减少训练数据集大小同时保持验证指标分数相似,并且不受数据集或架构选项的特定限制。
LSDIR 快速测试
BHI 过滤
出于好奇,我在 LSDIR 数据集上进行了另一项测试,但这次只进行了过滤后的最终结果的快速测试。
我测试了当前值的 BHI 过滤,以及 IC9600 之前(旧的)阈值 0.5 的 BHI 过滤,这里我用“0.5”标记。
LSDIR 基线:179,006 块
LSDIR BHI:116,141 块 (64.9%)
LSDIR BHI 0.5:62,192 块 (34.7%)



从这些指标中我们可以看出,切换到 IC9600 阈值 0.4 仍然成立,或者比之前的 0.5 阈值给出更好的结果。BHI 过滤仍然是减少训练图像数量的有效方法,同时获得与未过滤数据集相似的指标。
未来工作
这里我只是写下我将来可能测试和/或在 Huggingface 社区发帖的可能未来工作。这些主要是我认为在 SISR 训练领域仍然可以测试的一些想法。
- 创建一个由多个合并数据集组成的 BHI 过滤数据集(我目前正在进行此项工作)
- 我只测试了 HyperIQA,但还有其他的 IQA NR 或审美模型。在我的快速测试中,qalign8bit 和 topiq_nr 过滤到相同数据集大小并没有显著更好的表现。不过,仍然可以测试 pyiqa 中所有可用的 NR 指标,看看它们中是否有最适合(或比 hyperiqa 更适合)SISR 数据集策划的。
- 这同样适用于 IC9600,还有其他复杂度指标,在该帖子中提到的论文中,他们例如测试了基于分割的过滤(通过计算图像中的分割数量)。IC9600 可以与这些进行比较。
- 稀有性过滤是否可以用于 SISR 训练数据集策划以增加多样性,就像论文 “稀有性分数:评估合成图像稀有性的新指标” 中那样?github 仓库
- 我们能否使用聚类(如 k-均值)或类似方法来获取训练数据集中对象分布的信息?这可以用于增加多样性(例如,如果我们识别出数据集中只有 0.1% 包含肖像照片/人脸)。
- 我只快速测试了多尺度,它并没有真正改善结果。但可以更彻底地测试多尺度对 SISR 模型训练是否有益。
- 从我的测试来看,我得到的印象是训练数据集中存在的噪声并没有像我预期的那样产生负面影响(我总是尽量保持我的训练集无噪声)。可以测试训练数据集中存在噪声是否对 SISR 训练有负面影响(当然,噪声的程度如何)。(尽管相反,我预计模糊会有负面影响。但这也可以测试)
- 我曾经致力于一个真实退化数据集,这导致了我的 RealWebPhoto 数据集,我可以在 Huggingface 上发一篇关于它的帖子。
- 根据训练经验,Real-ESRGAN 流水线中使用的默认 otf 值(在他们的仓库中使用,然后被 HAT 和其他架构沿用)似乎并未优化或不理想,或者换句话说,过于极端。我曾测试过不同的值,这导致了 neosr 现在使用的标准 otf 值。我也可以就此在 Huggingface 上发一篇帖子(并重新测试)。
- 就像我的自然数据集一样,我制作了一个过滤更少、训练瓦片数量更少的版本,用于轻量级架构选项。这可以测试,轻量级架构选项(如 SPAN)、中量级架构选项(如 MAN)和重量级 Transformer/架构选项(如 DAT)是否有理想的训练瓦片数量?如果答案是肯定的,那是什么?或者架构选项总是从更多的训练信息/更高数量的训练瓦片中受益(保持复杂度不变)?
- 通常有关于单个损失的论文。但是损失组合呢?哪些损失组合会产生什么效果/结果?
- Neosr mssim 损失与像素 l1 损失,其他 neosr 特定的损失(一致性损失)?
- 哪些 FR 指标最适合 SISR 训练验证指标?总是只有 PSNR 和 SSIM 吗?(速度和结果)
- 比 Real-ESRGAN 更好的 otf 退化流水线,也可以添加例如用于游戏纹理放大器的 DX1 压缩,用于视频放大器的不同视频压缩等等?(将 umzi 的 wtp_dataset_destroyer 等集成到训练软件中)
- 我通常不太喜欢基于扩散的超分辨率器,因为它们过多地改变了输入图像(输出是一个不同的图像,基本上不是输入图像的放大版本)。但我确实认为它们有优点。如果输入图像因退化而损坏过多,以至于单独的 Transformer 无法恢复,那么这种效果可能是期望的,因此需要额外细节进行幻觉,这是扩散器的优势,但以可控的方式,就像我在我的超流程中展示的那样。我也可以就此在 Huggingface 上发表一篇帖子。
你已经读到我的文章末尾了 :D 感谢你的阅读 :)





