AI 模型优化技术简介










Pruna AI 是一个面向机器学习团队的 AI 优化引擎,旨在简化可扩展推理。该工具包的设计理念是简洁,只需几行代码即可优化您的模型。它是开源的,旨在以下几个方面实现更好的模型:
- 更快:通过先进的优化技术加速推理时间
- 更小:在保持质量的同时减小模型大小
- 更便宜:降低计算成本和资源需求
- 更环保:减少能源消耗和环境影响
在本博客中,我们将介绍实现这四个目标的关键技术。在我们深入探讨每种技术之前,让我们先了解一下我们库中实现的各项技术的概述。
优化技术
首先,我们创建了 Pruna 中实现的各种技术的高级概述。这是一个有限的优化技术列表,可以进一步丰富,但它构成了您理解的坚实基础。
| 技术 | 描述 | 速度 | 内存 | 质量 |
|---|---|---|---|---|
批处理 |
将多个输入分组在一起同时处理,提高计算效率并减少处理时间。 | ✅ | ❌ | ➖ |
缓存 |
存储计算的中间结果以加速后续操作。 | ✅ | ➖ | ➖ |
编译器 |
使用特定硬件的指令优化模型。 | ✅ | ➖ | ➖ |
知识蒸馏 |
训练一个更小、更简单的模型来模仿一个更大、更复杂的模型。 | ✅ | ✅ | ❌ |
量化 |
降低权重和激活的精度,从而降低内存需求。 | ✅ | ✅ | ❌ |
剪枝 |
移除不重要或冗余的连接和神经元,从而形成一个更稀疏、更高效的网络。 | ✅ | ✅ | ❌ |
恢复 |
压缩后恢复模型的性能。 | ➖ | ➖ | ✅ |
推测解码 |
推测解码通过让一个小型、快速的模型同时预测多个token来加速 AI 文本生成,然后由一个更大的模型验证这些token,从而创建高效的并行工作流。 | ✅ | ❌ | ➖ |
✅(改善),➖(大致相同),❌(恶化)
技术要求和限制
在我们继续之前,请注意这些技术及其底层实现算法都有特定的要求和限制。有些技术只能应用于特定硬件,如 GPU,或特定模型,如 LLM 或图像生成模型。另一些可能需要分词器、处理器或数据集才能运行。最后,并非所有技术都可以互换使用,因此存在兼容性限制。
优化技术
现在我们将深入探讨不同的优化技术。尽管我们会更深入地了解各种技术及其底层算法,但我们不会深入到细枝末节。我们将保持高层概括,并重点介绍 Pruna 库中针对每种技术实现的基本底层算法之一。
批量处理 AI 模型推理
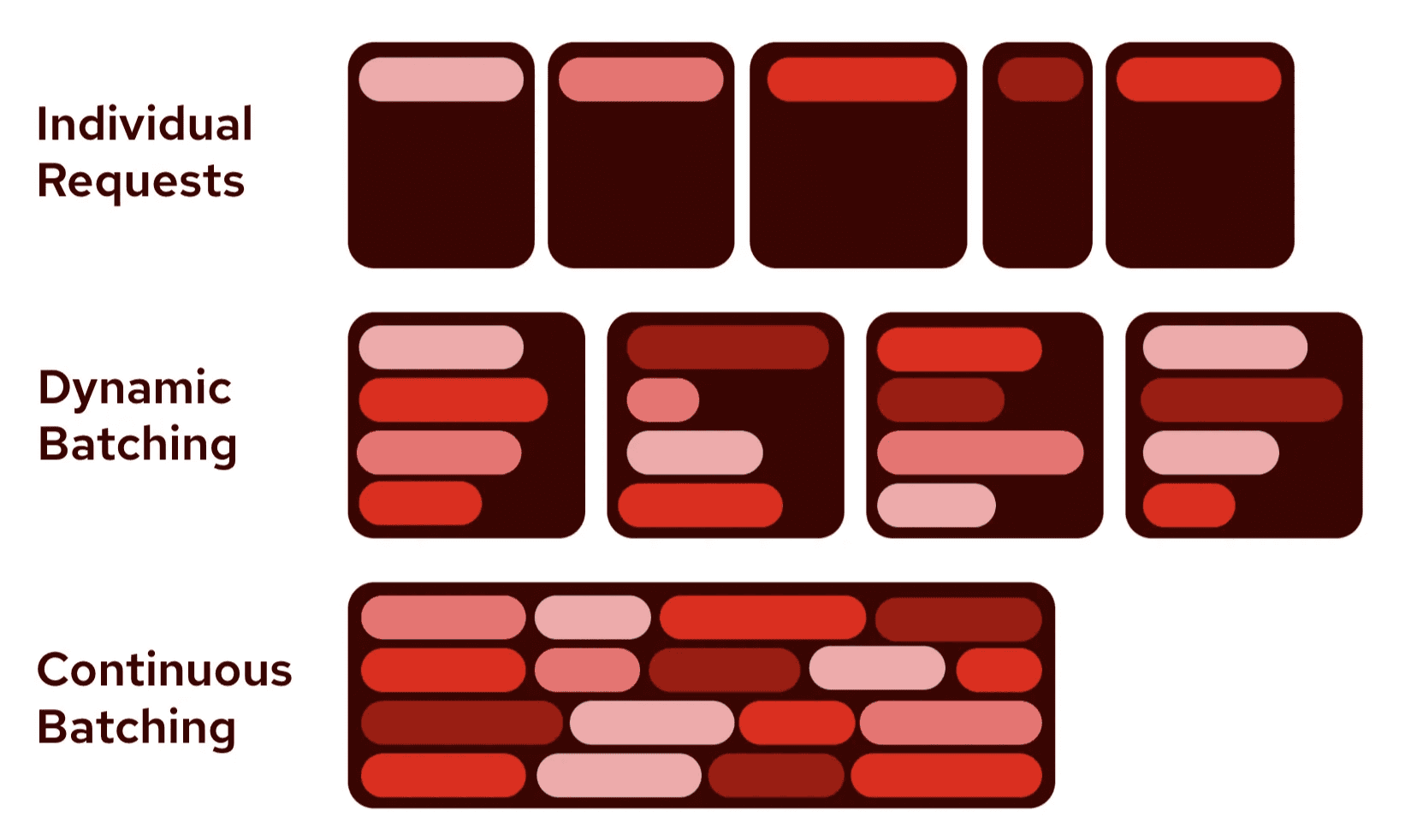
批量处理将多个输入分组在一起,同时进行处理,从而提高计算效率并减少整体处理时间。GPU 不是一次处理一个提示,而是并行处理多个提示,从而最大限度地利用硬件。这显著提高了吞吐量,因为现代 GPU 专为并行计算而设计。批量处理减少了每个示例的计算开销,并允许在多个输入之间更好地分配固定成本,从而通常提高吞吐量。
对于批量处理,我们实现了 WhisperS2T,它在 Whisper 模型的基础上工作。它智能地批量处理较小的语音片段,并且设计得比其他实现快得多,与 WhisperX 相比,速度提升了 2.3 倍,与使用 FlashAttention 2 的 HuggingFace Pipeline (Insanely Fast Whisper) 相比,速度提升了 3 倍。
缓存中间结果
缓存存储计算的中间结果以加速后续操作,通过重用先前计算的结果来减少推理时间。对于基于 Transformer 的 LLM,这通常涉及存储来自先前 token 的键值对以避免冗余计算。当逐个 token 生成文本时,每个新 token 可以重用先前 token 的缓存计算,而不是重新计算整个序列。这显著提高了推理效率,特别是对于长上下文应用。然而,缓存不仅仅用于保存 KV 计算,还可以用于 LLM 和图像生成模型的多个地方。
对于缓存,我们实现了 DeepCache,它在 diffuser 模型的基础上工作。DeepCache 通过利用扩散管道的 U-Net 块来重用缓存的高级特征,从而加速推理。它的优点是无需训练且几乎无损,同时将模型加速 2 到 5 倍。
使用并行生成进行推测解码
推测解码通过并行化生成过程的一部分来提高语言模型推理的效率。不是一次生成一个token,一个更小、更快的草稿模型在一个前向传播中生成多个候选token。然后,更大、更准确的模型并行验证或纠正这些token,从而在不显著牺牲输出质量的情况下实现更快的token生成。这种方法减少了所需的顺序步骤数量,降低了整体延迟并加速了推理。需要注意的是,推测解码的有效性取决于草稿模型和目标模型之间的一致性,以及所选的批量大小和验证策略等参数。
我们尚未实现任何推测解码算法,但请务必继续关注以发现我们未来的算法!
针对特定硬件的编译
编译通过将高级模型操作转换为低级硬件指令来优化模型以适应特定硬件。像 NVIDIA TensorRT、Apache TVM 或 Google XLA 这样的编译器会分析计算图,尽可能地融合操作,并为目标硬件生成优化代码。这个过程消除了冗余操作,减少了内存传输,并利用了硬件特定的加速功能,从而缩短了推理时间并降低了延迟。重要的是要注意,模型/硬件的每种组合都将有不同的最佳编译设置。
对于编译,我们实现了 Stable-fast,它在扩散模型的基础上工作。Stable-fast 是一个用于图像生成模型的优化框架。它通过将关键操作融合到优化内核中,并将扩散管道转换为高效的 TorchScript 图来加速推理。
针对小型模型的知识蒸馏
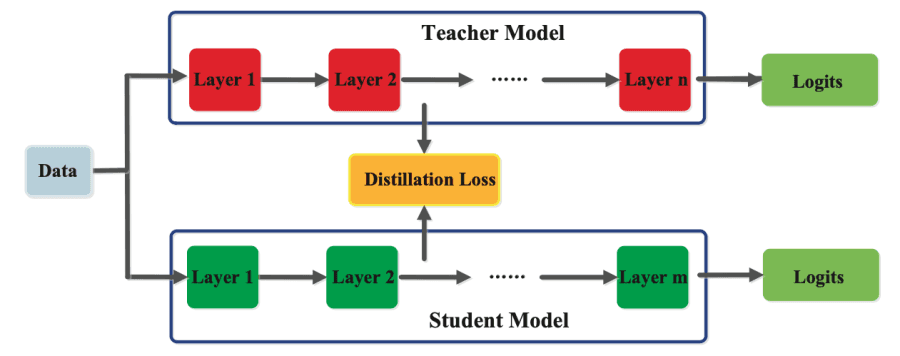
知识蒸馏训练一个更小、更简单的模型来模仿一个更大、更复杂的模型。较大的“教师”模型产生输出,较小的“学生”模型学习复制这些输出,从而在减少计算需求的同时有效地传递知识。这种技术保留了较大模型的大部分性能和能力,同时显著减少了参数数量、内存使用和推理时间。知识蒸馏可以针对感兴趣的特定能力,而不是通用性能。
对于知识蒸馏,我们实现了 Hyper-SD,它在扩散模型的基础上工作。Hyper-SD 是一个知识蒸馏框架,它将扩散过程分为时间步长组,以保留和重构 ODE 轨迹。通过整合人类反馈和分数蒸馏,它可以在推理步骤大幅减少的情况下实现近乎无损的性能。
针对低精度的量化
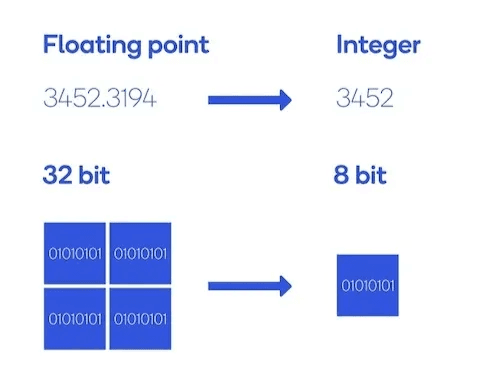
量化通过将高精度浮点数(FP32/FP16)转换为低精度格式(INT8/INT4)来降低权重和激活的精度,从而降低内存需求。这减少了模型大小、内存带宽需求和计算复杂度。现代量化技术,如训练后量化(PTQ)和量化感知训练(QAT),可在实现显著效率提升的同时最大限度地减少精度损失。硬件加速器通常对低精度算术有专门支持,进一步提高了性能。
对于量化,我们实现了半二次量化 (HQQ),它适用于任何模型。HQQ 利用快速、鲁棒的优化技术进行即时量化,无需校准数据,使其适用于任何模型。该算法专门适用于扩散器模型。
修剪冗余神经元
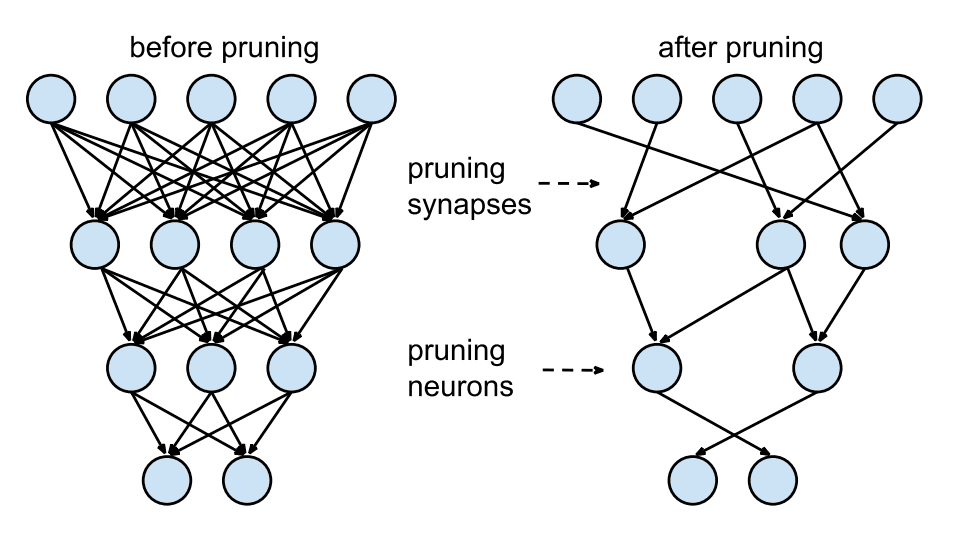
剪枝移除不重要或冗余的连接和神经元,从而形成一个更稀疏、更高效的网络。存在各种剪枝策略,包括基于幅度的剪枝(移除最小的权重)和彩票假说方法(寻找稀疏子网络)。关键的设计选择通常是剪枝哪个结构(例如权重、神经元、块)以及如何对结构进行评分(例如使用权重幅度、一阶、二阶信息)。如果仔细操作,剪枝可以显著减小模型大小(通常为 80-90%),同时对性能的影响最小。稀疏模型需要专门的硬件或软件支持才能实现计算增益。
对于剪枝,我们实现了结构化剪枝,它适用于任何模型。结构化剪枝从网络中移除整个单元,如神经元、通道或滤波器,从而形成一个更紧凑、计算效率更高的模型,同时保留标准硬件可以轻松优化的规则结构。
通过训练恢复性能
恢复是特殊的,因为它允许提高压缩模型的性能。在压缩后,它通过微调或再训练等技术恢复模型的性能。在积极剪枝后,模型通常会经历一些性能下降,这可以通过额外的训练步骤来缓解。这个恢复阶段允许剩余参数进行适应和补偿压缩。高效恢复的方法包括学习率回溯、权重回溯和分步剪枝(在剪枝迭代之间进行恢复)。恢复过程有助于在模型大小和性能之间实现最佳权衡。
对于恢复,我们实现了文本到文本的 PERP,它在文本生成模型的基础上工作。此恢复器是一种通用的 PERP 恢复器,用于通过范数、头部和偏差微调以及可选的 HuggingFace LoRA 来处理文本到文本模型。同样,我们也支持文本到图像的 PERP 用于其他图像生成模型。
接下来是什么?
这是对这些类别中的每一个的简要介绍,还有更多细微之处、技术和实现需要强调。最酷的是,这些技术中的每一个都已在开源 Pruna 库中实现,并已准备好供您使用!不要忘记在社交媒体上关注我们,加入我们的运动,让您的 AI 模型更便宜、更快、更小、更环保!




