衡量重要指标:图像生成评估的客观指标







使用最先进的模型生成高质量视觉效果现在越来越容易。开源模型可以在笔记本电脑上运行,云服务可以在几秒钟内将文本转换为图像。这些模型已经在改变广告、游戏、时尚和科学等行业。
但是创建图像是容易的部分。判断它们的质量要困难得多。人工反馈速度慢、成本高、有偏见,而且经常不一致。此外,质量有许多方面:创意、真实感和风格并不总是一致的。改进一个可能会损害另一个。
这就是为什么我们需要清晰、客观的指标来衡量质量、连贯性和原创性。我们将了解如何使用 Pruna 衡量图像质量并比较模型,而不仅仅是“看起来很酷吗?”
指标概述
评估指标没有唯一的正确分类方法,因为一个指标可以根据其用法和评估的数据属于多个类别。在我们的存储库中,所有质量指标都可以通过两种模式计算:单一和成对。
- 单一模式通过将生成的图像与输入参考或真实图像进行比较来评估模型,为每个模型生成一个分数。
- 成对模式通过直接评估每个模型生成的图像来比较两个模型,为这两个模型生成一个单一的比较分数。
这种灵活性既可以实现绝对评估(单独评估每个模型),也可以实现相对评估(模型之间的直接比较)。
除了评估模式之外,从评估标准角度思考指标也很有意义,以提供结构和清晰度。我们的指标分为两大类
- 效率指标:衡量模型在推理过程中的速度、内存使用、碳排放、能源等消耗。在 Pruna,我们致力于让您的模型更小、更快、更便宜、更环保,因此使用这些效率指标评估您的模型是水到渠成的。然而,由于效率指标并非图像生成任务所特有,我们不会在本博客文章中详细讨论它们。如果您想了解更多关于这些指标的信息,请参阅我们的文档。
- 质量指标:衡量生成图像的内在质量及其与预期提示或参考的对齐程度。这包括
- 分布对齐:生成图像与真实世界分布的相似程度。
- 提示对齐:生成图像与其预期提示之间的语义相似性。
- 感知对齐:生成图像和参考图像之间的像素级或感知相似性。
下表总结了 Pruna 中最常见的质量指标、它们的类别、分数范围和主要局限性,以帮助指导指标选择。
| 指标 | 测量方法 | 类别 | 范围(↑越高越好/↓越低越好) | 局限性 |
|---|---|---|---|---|
| FID | 与真实图像的分布相似性 | 分布对齐 | 0 到 ∞ (↓) | 假设高斯性,需要大量数据集,依赖于代理模型 |
| CMMD | CLIP 空间分布相似性 | 分布对齐 | 0 到 ∞ (↓) | 核选择影响结果,依赖于代理模型 |
| CLIPScore | 图像-文本对齐 | 提示对齐 | 0 到 100 (↑) | 对图像质量不敏感,依赖于代理模型 |
| PSNR | 像素级相似性 | 感知对齐 | 0 到 ∞ (↑) | 感知对齐度不高 |
| SSIM | 结构相似性 | 感知对齐 | -1 到 1 (↑) | 对于小的输入变化可能不稳定 |
| LPIPS | 感知相似性 | 感知对齐 | 0 到 1 (↓) | 依赖于代理模型 |
分布对齐度量
分布对齐度量衡量生成图像与真实世界数据分布的相似程度,比较低级和高级特征。在成对模式下,它们比较不同模型输出以生成一个单一的分数,该分数反映相对图像质量。

生成的图像与真实的图像非常相似,并且分布对齐良好,表明质量良好。

生成的图像明显失真,并且分布差异显著,指标将其捕捉为不匹配。
Fréchet Inception Distance (FID):FID(此处介绍)是评估 AI 生成图像真实感的最常用指标之一。它通过比较参考图像(例如真实图像)的特征分布与要评估模型生成的图像的特征分布来工作。
工作原理简述
- 我们使用一个**预训练的代理模型**,将真实图像和生成的图像都输入其中。这个预训练的代理模型通常是 **Inception v3**,这也解释了该指标的名称。
- 该模型将每张图片转换为一个**特征嵌入**(图片的数值摘要)。我们假设每组的嵌入形成一个**高斯分布**。
- FID 然后测量两个分布之间的*距离*——它们越接近,效果越好。
较低的 FID 分数表明生成的图像与真实图像更相似,这意味着更好的图像质量。
想知道数学原理?
FID 计算为两个多元高斯分布之间的 Fréchet 距离
FID = ||μr − μg||² + Tr(Σr + Σg − 2(Σr Σg)1/2)其中:
- (μr, Σr) 是真实图像特征的均值和协方差。
- (μg, Σg) 是生成图像特征的均值和协方差。
- Tr 表示矩阵的迹。
- (Σr Σg)1/2 表示两个协方差矩阵的几何平均值。
Clip Maximum-Mean-Discrepancy (CMMD): CMMD(此处介绍)是衡量生成图像与真实图像相似程度的另一种方法。与 FID 类似,它比较特征分布,但不是使用 Inception 特征,而是使用预训练 CLIP 模型中的嵌入。
其工作原理如下:
- 我们使用一个**预训练的代理模型**,将真实图像和生成的图像都输入其中。这个预训练的代理模型通常是**CLIP**。
- 该模型将每张图片转换为一个**特征嵌入**(图片的数值摘要)。我们**不**假设每组的嵌入形成一个**高斯分布**。
- 使用核函数(通常是 RBF)来比较这些分布的差异,而不假设它们是高斯分布。
较低的 CMMD 分数表示生成图像的特征分布与真实图像的特征分布更相似,意味着更好的图像质量。
想知道数学原理?
CMMD 基于最大平均差异(MMD)计算,公式为:
CMMD = 𝔼[ k(φ(xr), φ(x′r)) ] + 𝔼[ k(φ(xg), φ(x′g)) ] − 2𝔼[ k(φ(xr), φ(xg)) ]其中:
- φ(xr) 和 φ(x′r) 是从 CLIP 中提取的两个独立真实图像嵌入。
- φ(xg) 和 φ(x′g) 是从 CLIP 中提取的两个独立生成图像嵌入。
- k(x, y) 是一个正定核函数,用于衡量嵌入之间的相似性。
- 期望值 𝔼[·] 在多个样本对上计算。
提示对齐度量

提示对齐度量评估生成图像与输入提示的匹配程度,尤其是在文本到图像任务中。在成对模式下,它们转而测量不同模型输出之间的语义相似性,将重点从提示对齐转移到模型一致性。
CLIPScore:CLIPScore(此处介绍)用于衡量生成的图像与其生成的文本提示的匹配程度。它使用预训练的 CLIP 模型,该模型将文本和图像映射到相同的嵌入空间。
思路如下
- 通过**代理 CLIP 模型**传入图像及其提示以获取它们的嵌入。
- 测量这两个嵌入的接近程度。它们越接近,图像与提示的对齐度就越好。
CLIPScore 的范围从 0 到 100。分数越高,表示图像与提示的语义对齐度越好。请注意,此指标不关注视觉质量,仅关注含义的匹配度。
想知道数学原理?
给定图像 *x* 及其对应的文本提示 *t*,CLIP Score 的计算公式为
CLIPScore = max⎛100 × (φI(x) · φT(t)) / (||φI(x)|| · ||φT(t)||), 0⎞其中:
- φI(x) 是生成图像的 CLIP 图像嵌入。
- φT(t) 是相关提示的 CLIP 文本嵌入。
CLIP Score 的范围从 0 到 100,分数越高表示图像与提示之间的对齐度越好。然而,它可能对图像质量不敏感,因为它侧重于语义相似性而不是视觉保真度。
感知对齐度量
感知对齐度量评估生成图像的感知质量和内部一致性。它们比较图像之间的像素级或特征级差异。这些指标通常本质上是成对的,因为在某些情况下,例如逐像素比较,将生成的图像与其他生成的图像进行比较更合适。
峰值信噪比 (PSNR):PSNR 衡量生成图像与其参考(真实)图像之间的像素级相似性。它广泛用于评估图像压缩和恢复模型。
较高的 PSNR 值表示更好的图像质量,但 PSNR 并不总是与人类感知良好关联。
想知道数学原理?
PSNR 的计算公式为
PSNR = 10 × log10 ⎛ (L²) / MSE ⎞其中:
- L 为最大可能像素值(例如,8 位图像为 255)。
- MSE(均方误差)是像素值之间平方差的平均值。
结构相似性指数 (SSIM):SSIM 通过比较像素强度的局部模式而不是仅仅是原始像素差异来改进 PSNR。它通过考虑小图像块中的亮度、对比度和结构来模拟人类视觉感知。
SSIM 的范围为 -1 到 1,其中 1 表示完美相似性。
想知道数学原理?
SSIM 通常计算为
SSIM(x, y) =
(2μxμy + C1)(2σxy + C2) / (μx2 + μy2 + C1)(σx2 + σy2 + C2)其中:
- μx, μy 是图像 *x* 和 *y* 的平均强度。
- σx2, σy2 是方差。
- σxy 是图像之间的协方差。
- C1, C2 是用于稳定的小常数。
学习感知图像块相似度 (LPIPS):LPIPS 是一种基于深度学习的指标,它使用预训练神经网络(例如 VGG、AlexNet)中的特征来衡量图像之间的感知相似度。与 PSNR 和 SSIM 不同,LPIPS 捕捉的是高层次的感知差异,而不是像素级差异。
想知道数学原理?
LPIPS 的计算公式为
LPIPS(x, y) = ∑l wl || Fl(x) − Fl(y) ||22其中:
- Fl(x) 和 Fl(y) 是图像 *x* 和 *y* 从层 *l* 获得的深层特征表示。
- wl 是学习到的权重,用于调整每个特征层的重要性。
较低的 LPIPS 分数意味着生成的图像与参考图像在感知上更相似。
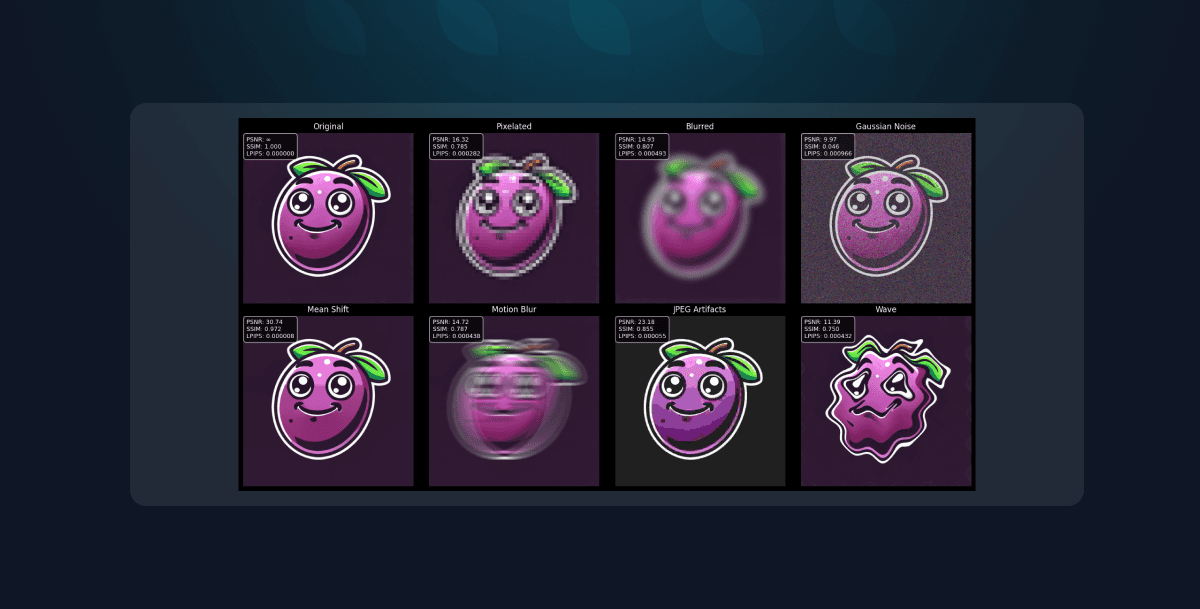
为了说明不同失真如何影响指标分数,我们来看下面的示例。下图展示了应用于原始图像的各种失真,以及 SSIM、PSNR 和 LPIPS 等指标对这些变化的反应。

图片中的结果说明了不同类型的失真如何影响这些基于任务的指标所给出的分数。值得注意的是
- 模糊图像的 SSIM 分数往往高于 PSNR。这表明虽然细节丢失了,但图像的整体结构和模式保持完整,这与 SSIM 对结构一致性的关注相符。
- 另一方面,像素化图像保持了相对较高的 PSNR 值,但 SSIM 排名下降。这表明虽然像素强度差异仍然很小,但图像的结构连贯性显著下降——这突出了 SSIM 对空间关系的敏感性,而不仅仅是像素级精度。
这些观察结果表明选择正确的指标至关重要。每个指标都捕捉图像质量的不同方面,使其在不同场景下根据失真类型和所评估的感知质量而有用。
使用评估代理自信地评估 AI 模型!
Pruna 中的评估框架包含几个关键组成部分
第 1 步:定义要衡量的指标
使用 `Task` 对象指定您想要计算哪些质量指标。您可以根据所需控制程度,通过三种不同的方式提供指标。
from pruna.evaluation.task import Task from pruna.data.pruna_datamodule import PrunaDataModule from pruna.evaluation.metrics.metric_torch import TorchMetricWrapper # Method 1: plain text from predefined options evaluate_image_generation_task = Task("image_generation_quality", datamodule=PrunaDataModule.from_string('LAION256')) # Method 2: list of metric names metrics = ['clip_score', 'psnr'] evaluate_image_generation_task = Task(request = metrics, datamodule=PrunaDataModule.from_string('LAION256')) # Method 3: list of metric instances clip_score_metric = TorchMetricWrapper("clip_score", model_name_or_path = "openai/clip-vit-base-patch32") psnr_metric = TorchMetricWrapper('psnr', base=2.0) metrics = [clip_score_metric, psnr_metric] evaluate_image_generation_task = Task(request= metrics, datamodule=PrunaDataModule.from_string('LAION256'))步骤 2:运行评估代理
将您的模型传递给 `EvaluationAgent`,让它处理一切:运行推理、计算指标并返回最终分数。
from pruna.evaluation.evaluation_agent import EvaluationAgent eval_agent = EvaluationAgent(evaluate_image_generation_task) results = eval_agent.evaluate(your_model)
随着人工智能生成图像越来越普及,有效评估其质量变得前所未有的重要。无论您是针对真实感、准确性还是感知相似性进行优化,选择正确的评估指标都是关键。Pruna 现已开源,您可以自由探索、定制,甚至向社区贡献新的评估指标。
我们的文档和教程(此处)提供了如何添加您自己的指标的分步指南,让您比以往任何时候都更容易根据您的需求定制评估。立即尝试,贡献您的力量,帮助塑造人工智能图像评估的未来!

