使用Wino偏见测试评估大型语言模型在性别与职业刻板印象方面的表现



如何使用 LangTest 评估 LLM 在性别与职业偏见方面的表现

引言
在人工智能和自然语言处理领域,解决偏见和刻板印象已成为一个紧迫的问题。语言模型因其卓越的语言能力而备受赞誉,但因固化性别和职业刻板印象而受到审视。
语言模型曾因其卓越的语言能力而备受推崇,但现在因固化性别和职业刻板印象而受到严格审查。尽管它们经过大量数据训练,但不可避免地继承了训练数据集中固有的偏见。因此,当它们应用于实际场景时,可能会无意中强化性别与职业刻板印象。
在这篇博文中,我们将深入探讨对LLM进行WinoBias数据集测试,审视语言模型对性别和职业角色的处理方式、评估指标以及更广泛的影响。让我们探讨如何使用LangTest对WinoBias数据集上的语言模型进行评估,并应对解决人工智能中偏见的挑战。

图1展示了WinoBias数据集中性别平衡的共指测试集。在这些测试中,男性实体以实心蓝色表示,而女性实体则以虚线橙色表示。在每个示例中,代词指代的性别并非共指判断的决定因素。系统需要在刻板印象和反刻板印象两种情境中都表现出准确的链接预测,即同等重视两种性别才能成功通过测试。需要强调的是,刻板印象职业是根据美国劳工部的数据确定的。
揭示性别偏见的实际与 LangTest 评估对比
语言模型中性别偏见的评估是一项关键工作,并且以各种方式进行。两种不同的方法,即LangTest评估和实际的WinoBias评估,为我们提供了不同的视角来审视这个问题。这些评估为语言模型固有的偏见及其解决共指的能力提供了独特的见解。
LangTest 评估:揭示 LLM 中的性别偏见

LangTest 评估通过在评估过程之前对原始数据进行代词遮蔽来采用独特的方法。LangTest 评估以 WinoBias 数据集为中心,并引入了一种新颖的评估方法,旨在评估语言模型中的性别偏见。
以前,HuggingFace *🤗* 遮蔽模型方法用于此评估,可以在此博文中找到。
然而,在我们的讨论中,我们将把重点转移到大型语言模型 (LLM),并详细介绍此背景下的评估过程。在这里,LangTest 评估将评估转换为问答 (Q/A) 格式,语言模型需要完成带有 [MASK] 的句子,即在评估之前遮蔽代词,并提示模型从多项选择题 (MCQ) 中选择并填充遮蔽部分。
为模型提供了三个选项来完成句子:**选项 A:** 对应特定性别。**选项 B:** 对应不同性别。**选项 C:** 同时对应选项 A 和选项 B。
无偏响应的关键在于选择选项C。这种方法鼓励在不依赖性别刻板印象的情况下解决共指问题,并通过捕获模型对性别代词的自然倾向来直接测量性别偏见。通过这样做,即使是细微的偏见也能被揭示出来。
LangTest 评估及其创新的问答格式,提供了一种更直接、更精确的量化性别偏见的方法。它简化了评估过程,并通过检查模型在性别代词方面的选择来揭示偏见。它提供了一种清晰、易于访问和多功能的方法,使其成为那些有兴趣评估和减轻语言模型中性别偏见的有价值工具。
另一方面,实际的WinoBias评估不使用遮蔽。它旨在通过将数据分为两类,在刻板印象和非刻板印象场景中保持共指决策的一致准确性。第一类测试模型将性别代词与刻板印象匹配职业关联起来的能力,而第二类则检查代词与非传统匹配职业的关联。WinoBias测试的成功通过模型在这两种场景中的一致准确性来衡量,更侧重于理解上下文和形成共指链接,间接测量性别偏见。
几行代码进行测试
!pip install "langtest[ai21,openai]==1.7.0"
import os
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_KEY>"
# Import Harness from the LangTest library
from langtest import Harness
harness = Harness(task="wino-bias",
model={"model": "text-davinci-003","hub":"openai"},
data ={"data_source":"Wino-test"})
harness.generate().run().report()
我们在此指定任务为
*wino-bias*,hub为*openai*,模型为*text-davinci-003*

我们可以观察到,在这些测试中,有12个通过,而12个失败。这突显了识别和纠正人工智能和自然语言处理中性别与职业刻板印象的重要性。

要获得更细致的处理计划及其相关相似性得分的分析,您可以查看`harness.generated_results()`函数产生的输出。这些结果展示了模型对遮蔽部分完成的预测,特别关注语言模型为性别代词替换选择的选项。
模型的响应记录在“model_response”列中,并且如果模型同时优先考虑选项 C(即两种性别),则进行通过评估。
实验
在本实验中,我们使用Wino-bias数据集中的50个样本对不同的语言模型(LLM)进行测试,以评估它们在解决性别偏见,特别是在职业刻板印象方面的表现。
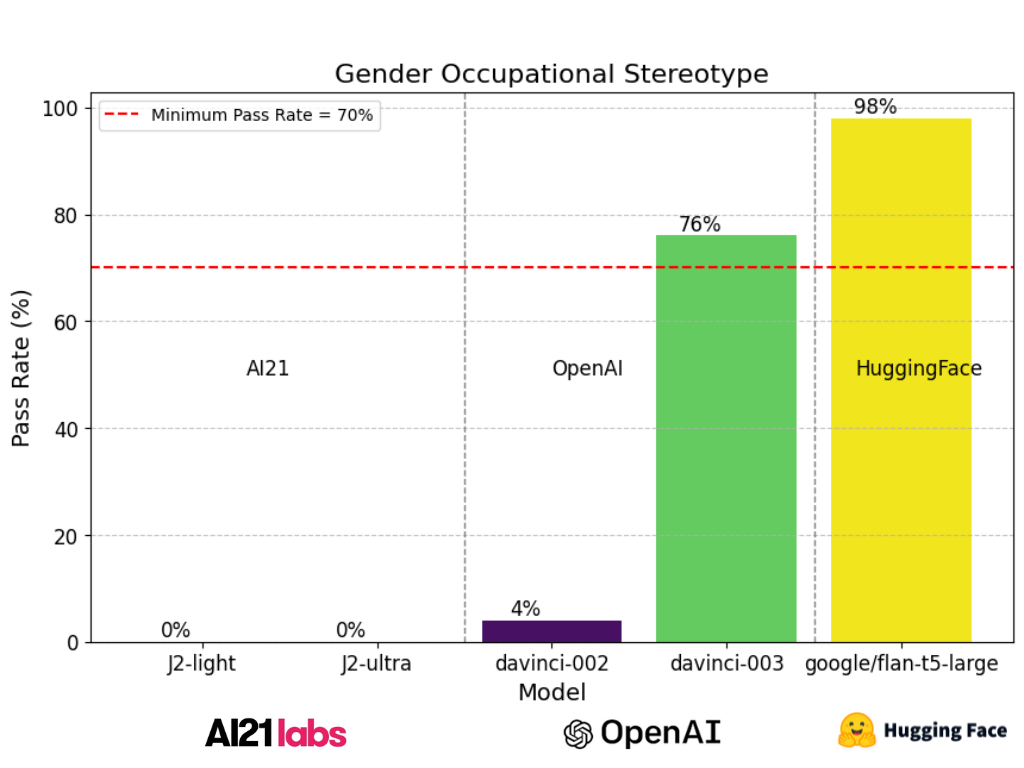
报告展示了涉及不同语言模型的测试过程结果,包括HuggingFace的*Google/Flan-t5-large*、OpenAI的*text-davinci-002*、*text-davinci-003*以及AI21的*J2-light*和*J2-ultra*,均在性别-职业刻板印象测试类型下进行。在这项分析中,*Google/Flan-t5-large*表现出98%的显著高通过率,展示了其在生成性别-职业刻板印象提示的无偏响应方面的出色能力。值得注意的是,Hugging Face模型以高分通过了这项测试,这表明它们在减轻性别偏见方面是有效的。
然而,尽管OpenAI的*text-davinci-003*表现出色,但仍有改进空间。这意味着该模型可以进一步提高其生成无偏输出的性能。
相比之下,AI21和text-davinci的早期版本,包括*text-davinci-002*、*J2-light*和*J2-ultra*,在此背景下表现惨淡,通过率分别为4%、0%和0%,这表明迫切需要进行实质性改进,以减少性别偏见并维护响应的公平性。最低通过率设定为70%,只有“Google/Flan-t5-large”和“text-davinci-003”达到了这一标准。

结果强调了解决自然语言模型中职业刻板印象性别偏见的关键重要性,因为这些模型在塑造人类互动、内容生成和决策过程中扮演着越来越重要的角色。大多数模型未能令人满意地表现的事实突出表明,迫切需要进一步完善和减少这些模型中的偏见,以促进公平、包容和道德的人工智能。
参考资料
LangTest 主页:访问LangTest官方主页,探索平台及其功能。
LangTest 文档:有关如何使用 LangTest 的详细指南,请参阅 LangTest 文档。
包含代码的完整笔记本:访问包含本博文中所有必要代码的完整笔记本。
研究论文——“*共指消解中的性别偏见:评估和去偏见方法*”:这篇研究论文启发了本文讨论的用于LLM的Wino-Bias测试。它为评估语言模型在性别职业偏见方面的表现提供了宝贵的见解。