LAD: LoRA-适应降噪器






作者
Ruurd Kuiper1, Maarten van Smeden1, Lars de Groot1, Ayoub Bagheri2
1乌得勒支大学医学中心 2乌得勒支大学
完整论文即将发布,并将提交同行评审。如有疑问,请通过r.j.a.kuiper@umcutrecht.nl联系我们。
演示
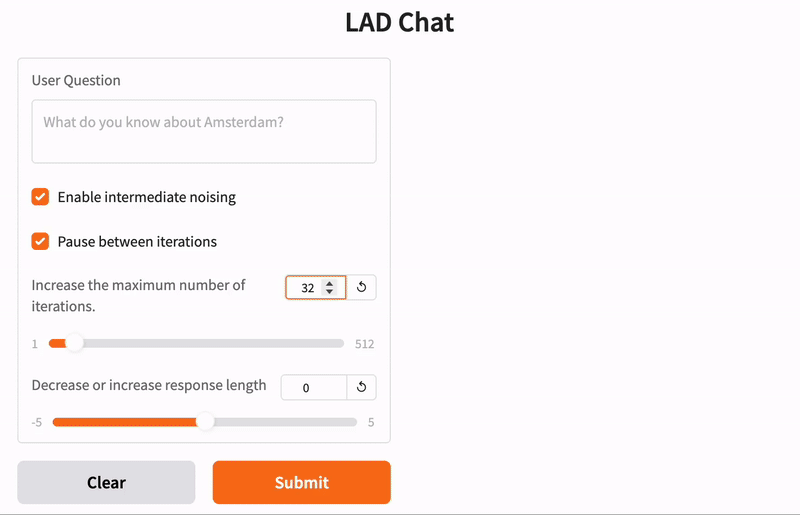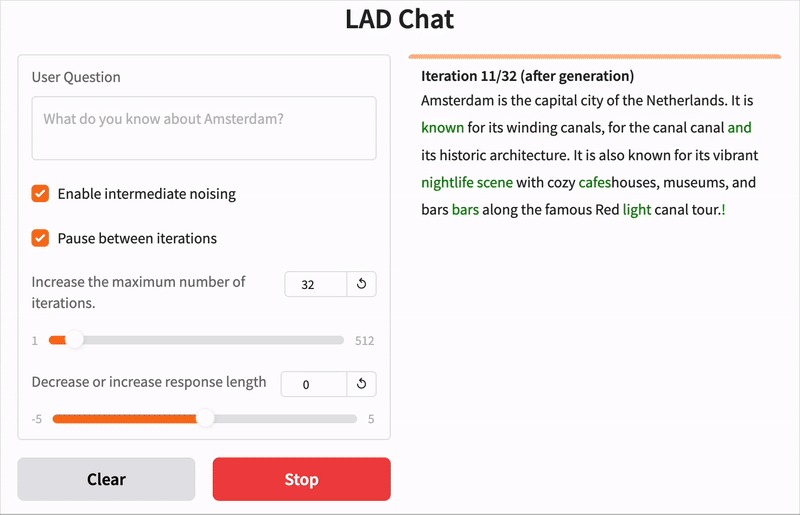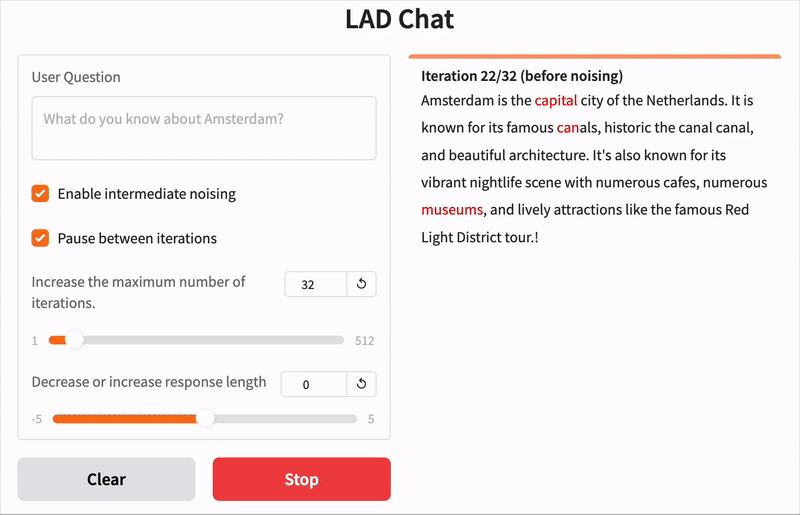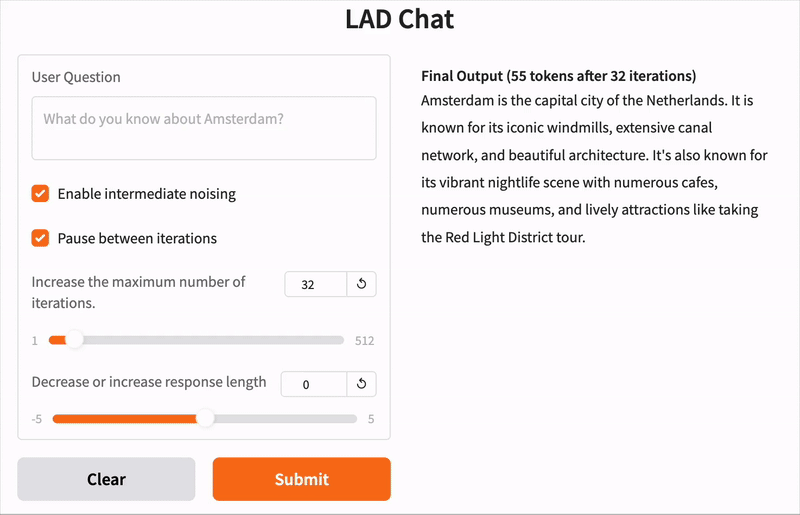
点击链接亲自尝试!该演示正在运行**LAD 8B Instruct**模型,该模型已针对遵循用户指令进行了微调。尝试关闭中间噪声,体验**无重掩码的扩散**。您可以在迭代之间添加短暂的暂停,以可视化被掩码(红色)和生成的(绿色)token。下面的GIF显示了一个示例。
核心创新(TL;DR)
- 高效适应: 仅用单张GPU训练数小时即可适应扩散。
- 快速推理: 对于简单查询,通常所需的步数少于输出token数。
- 可扩展的测试时计算: 可通过增加迭代次数来提高回答质量。
- 结构降噪: 结合掩码和结构噪声,实现全序列细化。
- 无噪声细化: 无需重掩码,即可迭代改进完整序列。
动机与方法
自回归模型虽然功能强大,但受限于严格的从左到右生成过程,这限制了效率和双向推理。基于扩散的模型提供了一种有前景、灵活的替代方案,但在适应离散文本数据方面面临挑战。LAD(LoRA-适应降噪器)的创建旨在弥合这一差距,提供了一个既灵活又高效的非自回归生成框架。
我们引入了一种新颖的方法,该方法将预训练的LLaMA[^1]模型用于迭代、双向序列细化。通过重新利用这些自回归模型,LAD受益于它们广泛的领域知识,同时摆脱了它们的顺序解码限制。这在不需要昂贵的完整模型再训练的情况下实现,使其成为开发先进生成能力的实用解决方案。
降噪过程的可视化
下面是带重掩码和不带重掩码的降噪过程的两个示例,回答的问题是:“你对阿姆斯特丹了解多少?”
 |
 |
| 左侧: 每步后带重掩码的降噪。 token以递减的频率重新掩码,以允许迭代修正。 |
右侧: 无重掩码的降噪。 token只细化一次,降低了灵活性但加快了推理速度。 |
图例: token阴影反映模型置信度,从红色(低确定性)到绿色(高确定性)。“MASK”指掩码token。虽然从右图看不出来,但带重掩码的降噪也仅用“MASK”token初始化。
与自回归模型需要每个token一步不同,LAD通常在少于其token输出长度的迭代中收敛。上面两个示例都在少于序列长度的步数内达到了连贯的输出。无重掩码版本在16步内收敛,而重掩码版本细化多达32步。重掩码能够实现更好的最终质量和可扩展的计算,例如,不使用重掩码的版本在最后一句话中出现了一个小错误。
LAD如何工作:核心创新
LAD的核心是其结构化和掩码训练目标的结合,这使得灵活的推理成为可能。我们修改了冻结的LLaMA Transformer骨干的 استاندard 因果注意力机制,使其完全双向,允许模型一次性考虑整个序列的上下文。在这个冻结的基础上,我们训练了轻量级的低秩适应(LoRA)适配器。这种参数高效的方法保留了原始模型的知识,同时大大减少了适应所需的计算资源。据我们所知,这是首次证明自回归模型可以通过仅使用LoRA微调转换为扩散生成。
训练和效率
LAD 8B Instruct模型在训练时非常注重效率,这是通过微调而不是从零开始训练来实现的。我们只进行了100,000次训练迭代,上下文长度为256,批量大小为8,总共只有2亿个训练token。相比之下,Meta的LLaMA 3 8B是在15万亿个token上训练的,而类似从零开始训练的扩散模型,如LlaDa[^2],使用了2.3万亿个token。这意味着LAD仅使用了它们各自token数量的0.001%和0.008%。
训练在大约10小时内在一张NVIDIA A100 (40GB) GPU上完成。通过采用冻结的LLaMA骨干网络和LoRA适配器,LAD显著降低了训练强大的非自回归文本模型的门槛,避免了从零开始训练或全参数微调的高昂计算成本。
初步结果
| 基准测试 | 分数(% 正确) |
|---|---|
| ARC-简单 | 88.5 |
| ARC-挑战 | 81.0 |
| MMLU | 60.5 |
| HellaSwag | 70.0 |
注意:分数是在每个数据集的随机200个示例子集上计算的。完整的基准测试结果将随后发布。
引用
完整论文即将发布,并将提交同行评审。在此期间,如果您在工作中使用了LAD,请引用此初步版本
@misc{kuiper2025lad,
author = {Ruurd Kuiper and Maarten van Smeden and Lars de Groot and Ayoub Bagheri},
title = {LAD: LoRA-Adapted Denoiser},
year = {2025},
howpublished = {\url{https://ruurdkuiper.github.io/tini-lad/}},
note = {Work in progress}
}
我们欢迎您的反馈和合作,以便我们继续开发和评估LAD。
参考文献
[^1]: Grattafiori, A., et al. (2024). The Llama 3 Herd of Models. arXiv:2407.21783
[^2]: Nie, S., et al. (2025). Large Language Diffusion Models. arXiv:2502.09992