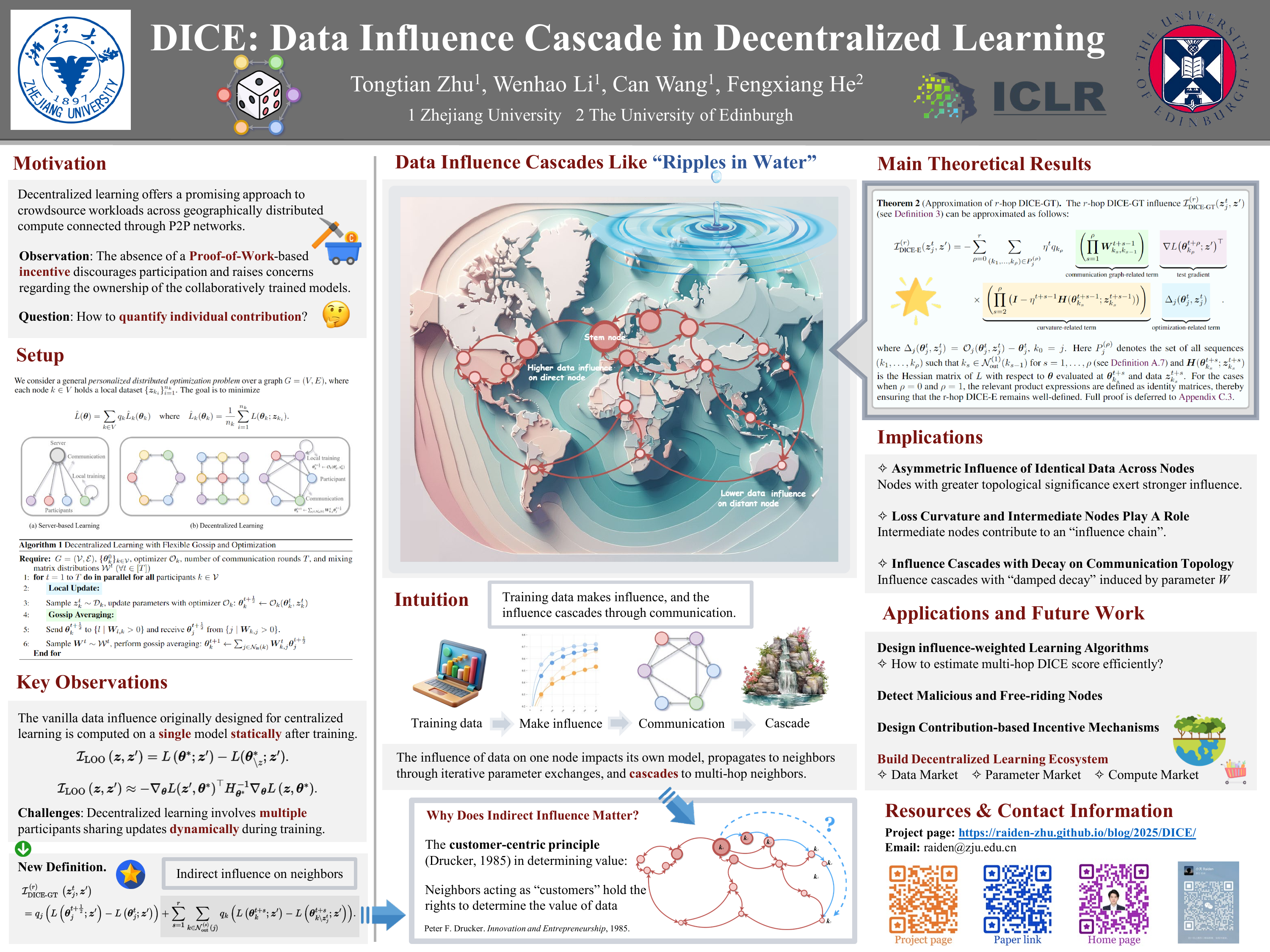
🎲 [ICLR 2025] DICE:去中心化学习中的数据影响力级联
总结: 我们提出了 DICE,这是首个用于衡量完全去中心化学习 (decentralized learning) 中数据影响 (data influence) 的框架。
标签: 数据影响 (Data_Influence), 去中心化学习 (Decentralized_Learning)
作者: Tongtian Zhu 1 Wenhao Li 1 Can Wang 1 Fengxiang He 2
1 浙江大学 2 爱丁堡大学
📄 论文 • 💻 代码 • 📚 预印本 • 🔗 推特 • 🖼️ 海报 • 📊 PPT • 🎥 视频 (中文)
正在更新中,敬请期待更多内容! 😉
🗓️ 2025-07-17 — 更新了主要结果
主要结果
定理 (r-hop DICE-GT 的近似)
r-hop DICE-GT 影响 I D I C E − G T ( r ) ( z j t , z ′ ) I DICE − GT ( r ) ( z j t , z ′ )
I D I C E − E ( r ) ( z j t , z ′ ) = − ∑ ρ = 0 r ∑ ( k 1 , … , k ρ ) ∈ P j ( ρ ) η t q k ρ ( ∏ s = 1 ρ W k s , k s − 1 t + s − 1 ) ⏟ 通信图相关项 × ∇ L ( θ k ρ t + ρ ; z ′ ) ⊤ ⏟ 测试梯度 × ( ∏ s = 2 ρ ( I − η t + s − 1 H ( θ k s t + s − 1 ; z k s t + s − 1 ) ) ) ⏟ 曲率相关项 × Δ j ( θ j t , z j t ) ⏟ 优化相关项 I DICE − E ( r ) ( z j t , z ′ ) = − ρ = 0 ∑ r ( k 1 , … , k ρ ) ∈ P j ( ρ ) ∑ η t q k ρ 通信图相关项 ( s = 1 ∏ ρ W k s , k s − 1 t + s − 1 ) × 测试梯度 ∇ L ( θ k ρ t + ρ ; z ′ ) ⊤ × 曲率相关项 ( s = 2 ∏ ρ ( I − η t + s − 1 H ( θ k s t + s − 1 ; z k s t + s − 1 ) ) ) × 优化相关项 Δ j ( θ j t , z j t )
其中 Δ j ( θ j t , z j t ) = O j ( θ j t , z j t ) − θ j t Δ j ( θ j t , z j t ) = O j ( θ j t , z j t ) − θ j t k 0 = j k 0 = j P j ( ρ ) P j ( ρ ) k s ∈ N o u t ( 1 ) ( k s − 1 ) k s ∈ N out ( 1 ) ( k s − 1 ) s = 1 , … , ρ s = 1 , … , ρ ( k 1 , … , k ρ ) ( k 1 , … , k ρ ) H ( θ k s t + s ; z k s t + s ) H ( θ k s t + s ; z k s t + s ) L L θ θ θ k s t + s θ k s t + s z k s t + s z k s t + s )
DICE 的核心洞见
我们的理论揭示了在去中心化学习中,塑造数据影响力的各种因素之间复杂的相互作用:
1. 非对称影响与通讯拓的扑重要性: 相同数据的影响力在网络中并非均匀分布。 相反,具有更高拓扑重要性的节点 (node) 会产生更强的影响力。2. 中间节点与损失景观的角色: 中间节点会主动构成一条“影响链 (influence chain)” 3. 带有阻尼衰减的影响级联: 数据影响力会以一种由混合参数 W 引起的“阻尼衰减 (damped decay)” 形式进行级联传播。这种衰减可能随跳数 (hop) 呈指数级下降,确保了影响力的“局部性 (localized)”
引用
如果我们的工作对您有所启发,欢迎引用我们的论文。
@inproceedings{zhu2025dice,
title="{DICE: Data Influence Cascade in Decentralized Learning}",
author="Tongtian Zhu and Wenhao Li and Can Wang and Fengxiang He",
booktitle="The Thirteenth International Conference on Learning Representations",
year="2025",
url="[https://openreview.net/forum?id=2TIYkqieKw](https://openreview.net/forum?id=2TIYkqieKw)"
}

{kind=link}