Accelerate 1.0.0








Accelerate 在今天是什么?
3.5 年前,Accelerate 是一个简单的框架,旨在通过一个低级抽象来简化*原始* PyTorch 训练循环,从而使多 GPU 和 TPU 系统上的训练更容易。
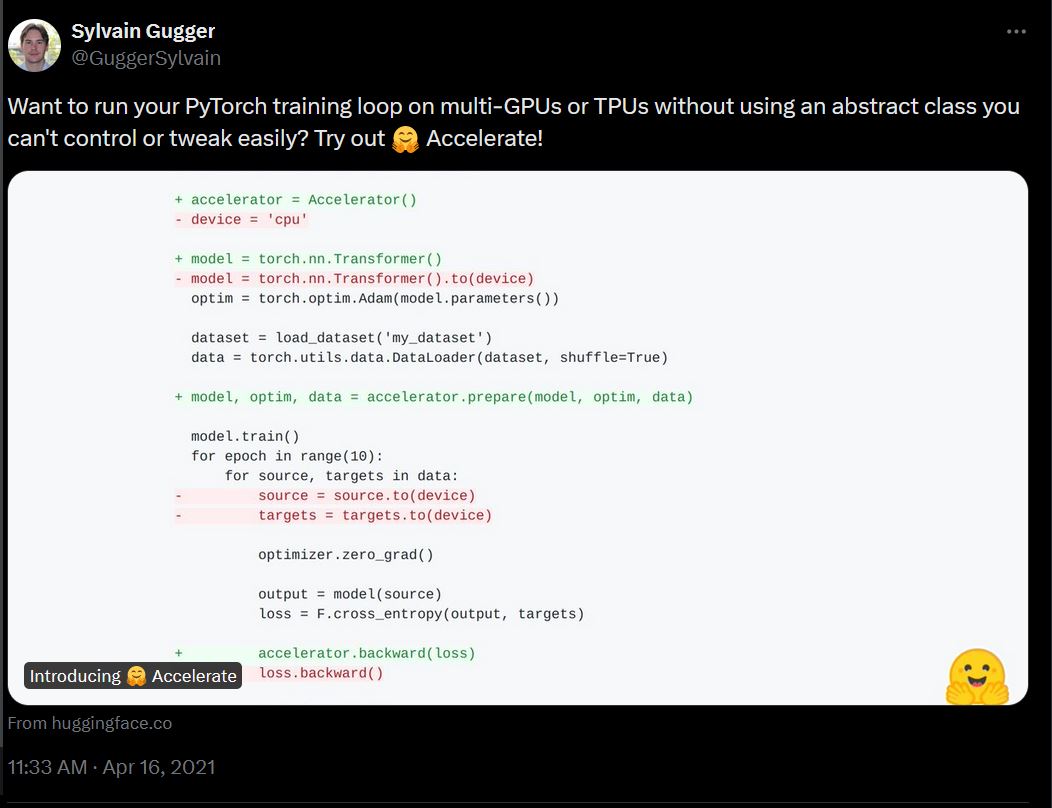
从那时起,Accelerate 已扩展成为一个多功能的库,旨在解决大规模训练和大型模型面临的许多常见问题,在这个 4050 亿参数(Llama)成为新的语言模型规模的时代。这包括:
- 一个灵活的低级训练 API,允许在六种不同的硬件加速器(CPU、GPU、TPU、XPU、NPU、MLU)上进行训练,同时保留原始训练循环的 99%。
- 一个易于使用的命令行界面,旨在配置和运行跨不同硬件配置的脚本。
- 大模型推理或
device_map="auto"的诞生地,允许用户不仅在多设备上对 LLM 进行推理,现在还通过参数高效微调(PEFT)等技术帮助在小型计算设备上训练 LLM。
这三个方面使 Accelerate 成为了 Hugging Face 几乎所有软件包的基础,包括 transformers、diffusers、peft、trl 等!
由于该软件包已稳定近一年,我们很高兴地宣布,从今天起,我们已发布 Accelerate 1.0.0 的第一个发布候选版本!
本博客将详细介绍:
- 我们为什么决定发布 1.0 版本?
- Accelerate 的未来是什么,以及我们认为 PyTorch 的整体发展方向是什么?
- 发生了哪些破坏性更改和弃用,以及如何轻松迁移?
为什么是 1.0 版本?
发布 1.0.0 版本的计划已经酝酿了一年多。API 大致达到了我们期望的程度,以 Accelerator 为中心,大大简化了配置并使其更具可扩展性。然而,我们知道在我们将 Accelerate 的“基础”称为“功能完整”之前,还有一些缺失的部分:
- 整合 MS-AMP 和
TransformersEngine的 FP8 支持(更多信息请参阅此处和此处) - 在使用 DeepSpeed 时支持多个模型的编排(实验性)
- 大模型推理 API 的
torch.compile支持(需要torch>=2.5) - 将
torch.distributed.pipelining集成作为另一种分布式推理机制 - 将
torchdata.StatefulDataLoader集成作为另一种数据加载器机制
随着 1.0 版本所做的更改,Accelerate 已准备好应对新的技术集成,同时保持用户界面 API 的稳定。
Accelerate 的未来
现在 1.0 版本即将完成,我们可以专注于社区中即将出现的新技术,并找到将其集成到 Accelerate 中的途径,因为我们预见 PyTorch 生态系统即将发生一些根本性的变化。
- 作为多模型 DeepSpeed 支持的一部分,我们发现虽然 DeepSpeed 目前的运作方式*可以*,但随着我们努力支持简单的封装以准备模型用于任何多模型训练场景,最终可能需要对整体 API 进行一些重大更改。
- 随着 torchao 和 torchtitan 的兴起,它们暗示了 PyTorch 的未来整体方向。目标是更原生支持 FP8 训练、新的分布式分片 API 以及对新版本 FSDP(FSDPv2)的支持,我们预计 Accelerate 的大部分内部和通用使用 API 将需要更改(希望不会太剧烈),以满足这些需求,因为这些框架将慢慢变得更加稳定。
- 在
torchao/FP8 的基础上,许多新框架正在引入不同的想法和实现,以使 FP8 训练能够正常稳定运行(例如transformer_engine、torchao、MS-AMP、nanotron)。我们 Accelerate 的目标是将这些实现集中在一个地方,并通过简单的配置让用户根据自己的意愿探索和测试每一个,旨在找到最终最稳定和灵活的那些。这是一个快速发展的研究领域(并非双关语),特别是随着 NVIDIA 的 FP4 训练支持即将到来,我们希望确保我们不仅能够支持每种方法,而且能够为每种方法提供 可靠的基准,以展示它们开箱即用的特性(只需最少的调整)与原生 BF16 训练的比较。
我们对 PyTorch 生态系统中分布式训练的未来感到非常兴奋,我们希望确保 Accelerate 在每一步都提供支持,降低这些新技术的入门门槛。通过这样做,我们希望社区能够继续共同实验和学习,以找到在更复杂的计算系统上训练和扩展更大模型的最佳方法。
如何试用
要尝试 Accelerate 的第一个发布候选版本,请使用以下方法之一:
- pip
pip install --pre accelerate
- Docker
docker pull huggingface/accelerate:gpu-release-1.0.0rc1
有效的发布标签有:
gpu-release-1.0.0rc1cpu-release-1.0.0rc1gpu-fp8-transformerengine-release-1.0.0rc1gpu-deepspeed-release-1.0.0rc1
迁移帮助
以下是本次发布中所有弃用的完整详细信息:
- 传入
dispatch_batches、split_batches、even_batches和use_seedable_sampler到Accelerator()现在应通过创建accelerate.utils.DataLoaderConfiguration()并将其传入Accelerator()来处理(Accelerator(dataloader_config=DataLoaderConfiguration(...)))。 Accelerator().use_fp16和AcceleratorState().use_fp16已被移除;这应该通过检查accelerator.mixed_precision == "fp16"来替代。Accelerator().autocast()不再接受cache_enabled参数。取而代之的是,应该使用AutocastKwargs()实例来处理此标志(以及其他标志),并将其传递给Accelerator(Accelerator(kwargs_handlers=[AutocastKwargs(cache_enabled=True)]))。accelerate.utils.is_tpu_available应替换为accelerate.utils.is_torch_xla_available。accelerate.utils.modeling.shard_checkpoint应替换为huggingface_hub库中的split_torch_state_dict_into_shards。accelerate.tqdm.tqdm()不再接受True/False作为第一个参数,而是应该将main_process_only作为命名参数传入。ACCELERATE_DISABLE_RICH不再是有效的环境变量,取而代之的是,应该通过设置ACCELERATE_ENABLE_RICH=1手动启用rich回溯。- FSDP 设置
fsdp_backward_prefetch_policy已替换为fsdp_backward_prefetch。
总结
非常感谢您使用 Accelerate;在过去几年中,看着一个最初的小想法发展成为超过 1 亿次下载量和近 30 万次每日下载量,这真是令人惊叹。
通过这次发布候选版本,我们希望为社区提供一个机会,在正式发布之前进行试用并迁移到 1.0 版本。







