我们如何为 🤗 API 客户将 Transformer 推理速度提升 100 倍
🤗 Transformers 已成为全球数据科学家探索最先进的自然语言处理(NLP)模型和构建新 NLP 功能的默认库。它拥有超过 5,000 个预训练和微调模型,支持超过 250 种语言,无论您使用哪种框架,它都是一个丰富且易于访问的乐园。
尽管在 🤗 Transformers 中试验模型很容易,但要在生产环境中以最高性能部署这些大型模型,并将它们管理在一个可随使用量扩展的架构中,对任何机器学习工程师来说都是一个**艰巨的工程挑战**。
这 100 倍的性能提升和内置的可扩展性,是我们托管的 加速推理 API 的订阅者选择在其之上构建 NLP 功能的原因。为了实现**最后 10 倍的性能**提升,优化需要深入底层,并针对特定模型和目标硬件进行。
这篇文章分享了我们为客户榨干每一滴计算资源的一些方法。🍋
实现第一个 10 倍加速
优化之旅的第一步是最容易实现的,即使用 Hugging Face 库 提供的最佳技术组合,这与目标硬件无关。
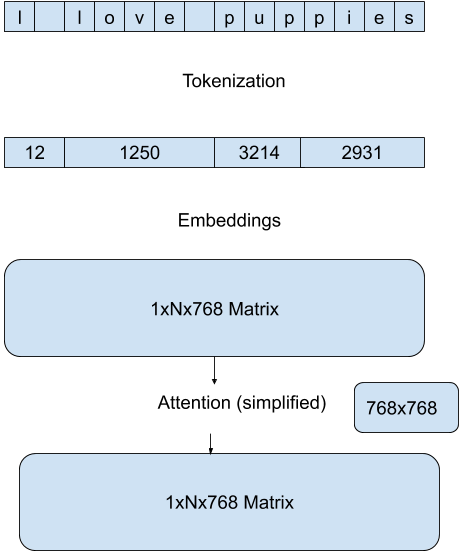
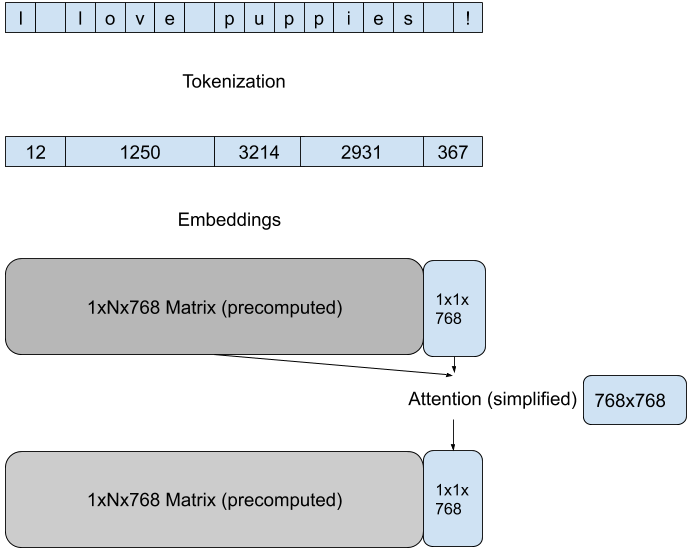
我们使用 Hugging Face 模型 pipelines 中内置的最高效方法,来减少每次前向传播的计算量。这些方法特定于模型架构和目标任务,例如,对于 GPT 架构上的文本生成任务,我们通过在每次传递中专注于最后一个 token 的新注意力来降低注意力矩阵计算的维度。
| - | 朴素版本 | 优化版本 |
|---|---|---|
| - |  |
 |
在推理过程中,分词(Tokenization)通常是效率的瓶颈。我们使用 🤗 Tokenizers 库中最高效的方法,利用模型分词器的 Rust 实现,并结合智能缓存,使整体延迟最多可提速 10 倍。
通过利用 Hugging Face 库的最新功能,我们针对给定的模型/硬件组合,相比于开箱即用的部署方式,实现了可靠的 10 倍加速。由于 Transformers 和 Tokenizers 通常每个月都会发布新版本,我们的 API 客户无需不断适应新的优化机会,他们的模型会持续运行得更快。
编译制胜:难以实现的 10 倍
现在,事情变得非常棘手了。为了获得最佳性能,我们需要修改模型并针对特定的推理硬件进行编译。硬件本身的选择将取决于模型(内存大小)和需求概况(请求批处理)。即使是为同一个模型提供预测服务,一些 API 客户可能会从加速 CPU 推理中获益更多,而另一些则可能从加速 GPU 推理中获益更多,每种情况都需要应用不同的优化技术和库。
一旦为特定用例选定了计算平台,我们就可以开始工作了。以下是一些可以在静态图上应用的 CPU 特定技术:
- 优化计算图(移除未使用的流程)
- 融合层(使用特定的 CPU 指令)
- 量化操作
使用开源库(例如 🤗 Transformers 与 ONNX Runtime)中的开箱即用功能不会产生最佳结果,或者可能导致精度的显著损失,尤其是在量化过程中。没有一劳永逸的解决方案,对于每种模型架构,最佳路径都各不相同。但通过深入研究 Transformers 代码和 ONNX Runtime 文档,我们可以协调各方因素,再实现一个 10 倍的加速。
不公平优势
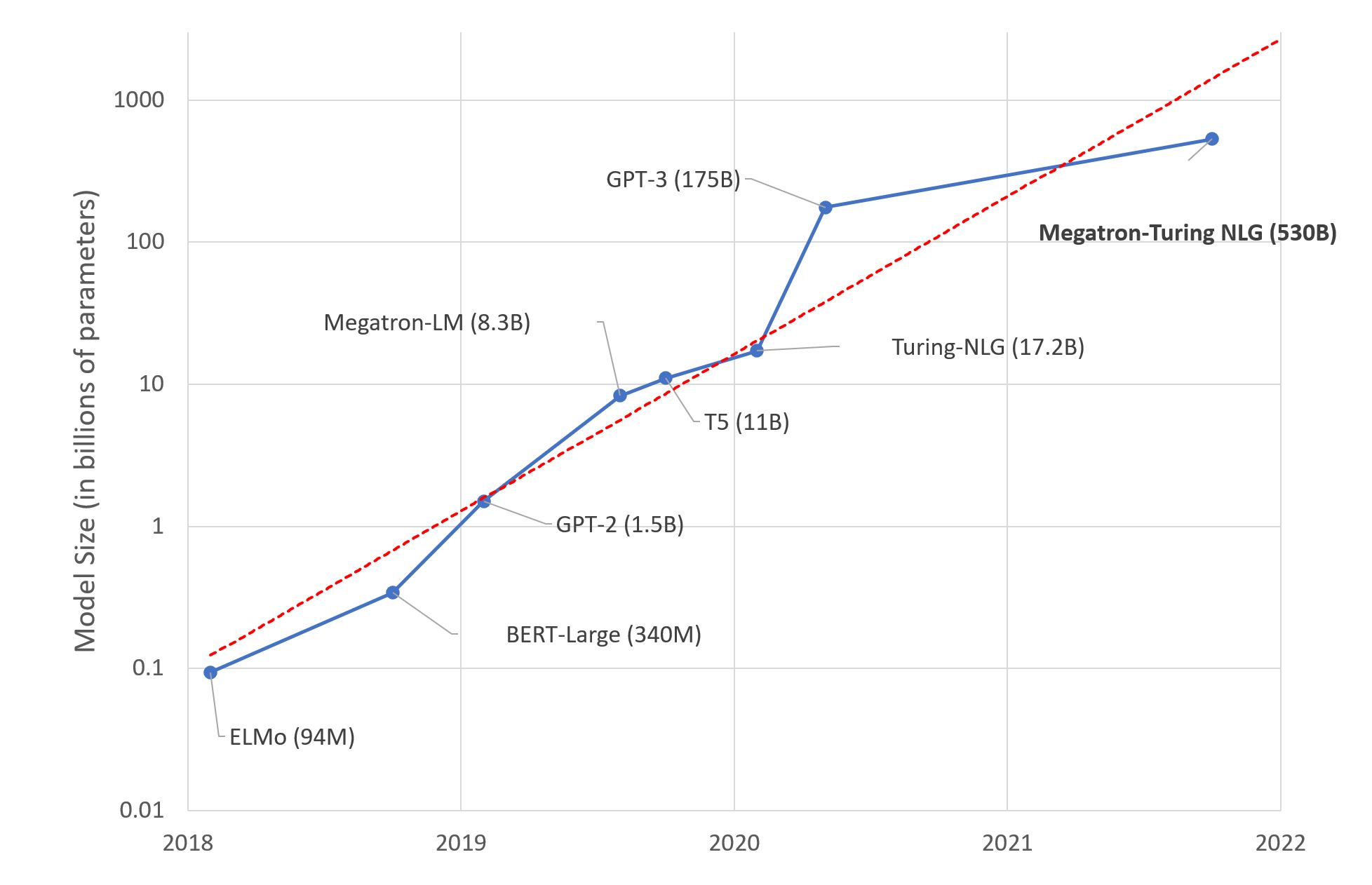
Transformer 架构是机器学习性能的一个决定性转折点,它始于 NLP 领域。在过去 3 年中,自然语言理解和生成的改进速度急剧加快。另一个相应加速的指标是模型的平均大小,从 BERT 的 1.1 亿参数增长到如今 GPT-3 的 1750 亿参数。
这一趋势给机器学习工程师在将最新模型部署到生产环境时带来了严峻的挑战。虽然 100 倍的加速是一个很高的门槛,但这正是在实时消费者应用中以可接受的延迟提供预测服务所必需的。
作为 Hugging Face 的机器学习工程师,为了达到这个门槛,我们当然拥有一个不公平的优势,那就是与 🤗 Transformers 和 🤗 Tokenizers 的维护者们在同一个(虚拟)办公室工作 😬。我们也非常幸运,通过与英特尔、英伟达、高通、亚马逊和微软等硬件和云供应商的开源合作,我们建立了丰富的伙伴关系,这使我们能够利用最新的硬件优化技术来调整我们的模型和基础设施。
如果您想在我们的基础设施上感受速度,请开始免费试用,我们会与您联系。如果您想在我们优化您自己基础设施的经验中受益,请参与我们的 。