如何使用 Apify 构建增量式网络爬虫
社区文章 发布于 2024 年 8 月 23 日


我使用 Apify 一段时间了,它是一个非常强大的平台,可以提取各种网络数据,无论是 Twitter 动态、文档,还是其他任何内容。
在现实世界中,只抓取一次网站并不能解决所有问题。网站内容**不断更新**,例如分类广告或文章,那么如何跟上这些变化呢?通常,您有两种主要根据频率区分的周期性方法:
常规周期性抓取,例如每周一次:这种方法涉及以固定但频率较低的时间间隔抓取整个网站。优点:您可以捕获所有更改和更新。缺点:数据在两次抓取之间可能会过时,尽管比频繁抓取消耗的资源少。
高频率周期性抓取,例如每天一次:在这种方法中,您更频繁地抓取整个网站,以便在更新发生时立即捕获。优点:您可以以最小的延迟保持数据最新。缺点:由于重复抓取整个网站,这种方法可能非常昂贵且效率低下。
那么有没有更有效的方法来管理这个问题呢?
幸运的是,有。通过 Apify,您现在可以专注于只抓取更新的页面,从而大幅减少抓取的数据量,同时保持信息最新。在本指南中,我将逐步向您展示如何实施这种更有效的方法,并探讨这种方法可以为您节省时间和资源的用例。
工作原理
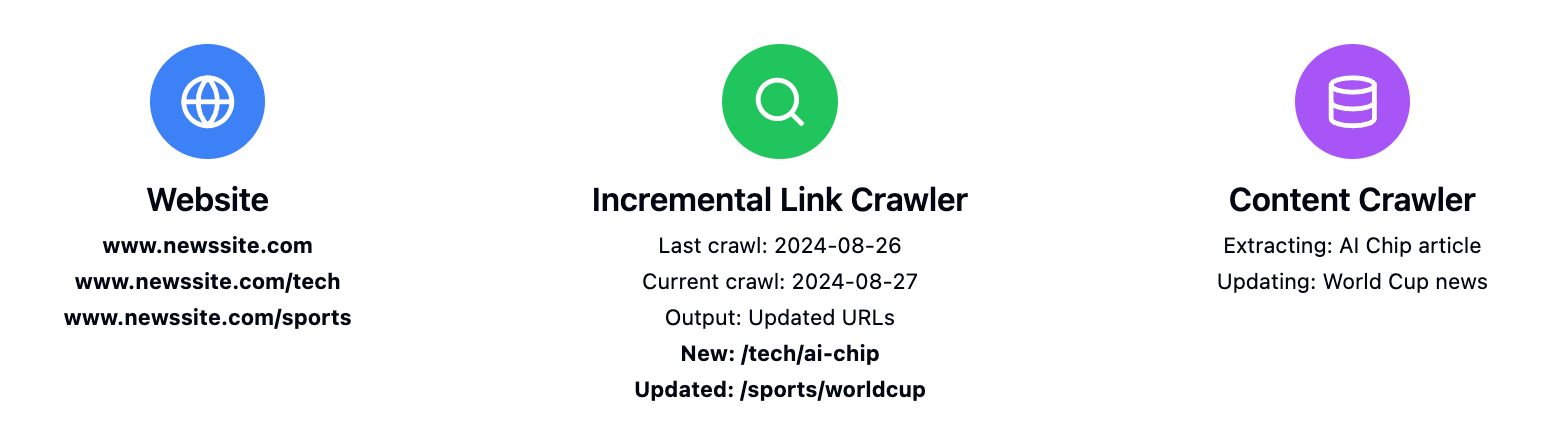
增量式网络爬虫接收两个主要输入:
url:您想要监控的网站daysAgo:您想要回溯搜索更新的天数(默认为 1 天)
示例
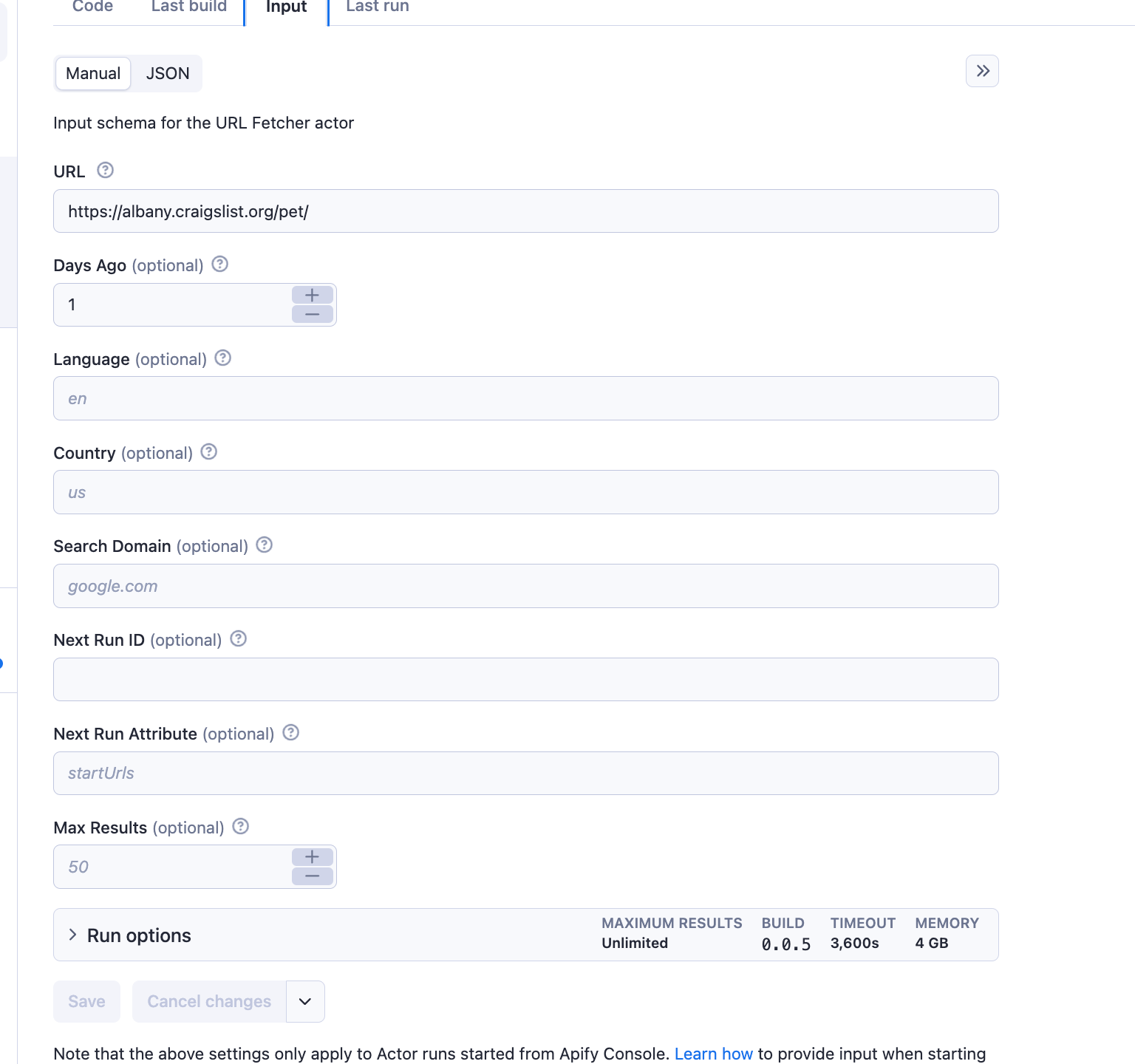
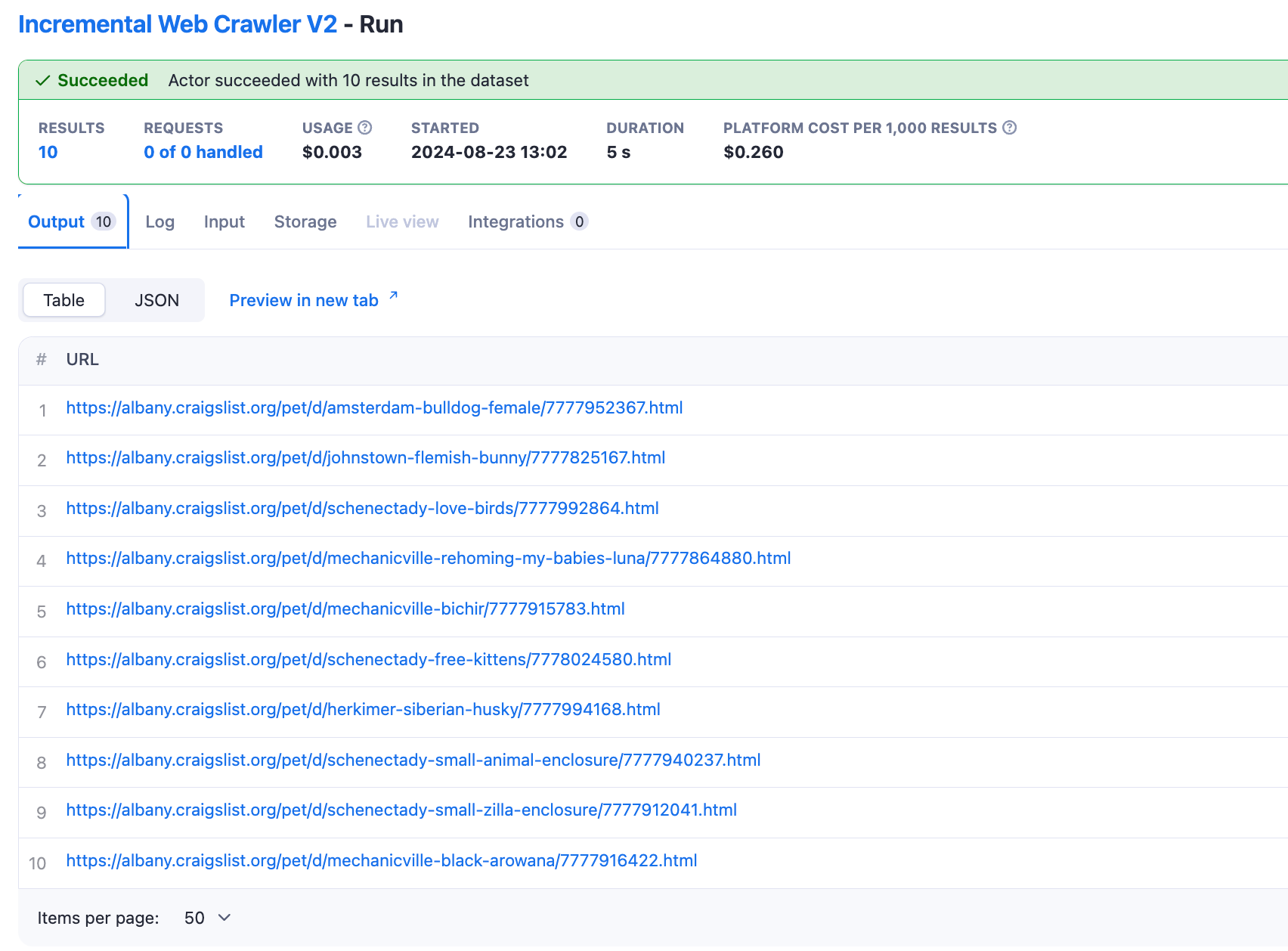
然后,爬虫将识别在指定时间范围内添加或更新的页面,并返回一个指向新添加或更新页面的 URL 列表。
**与其他 Actors 集成**,例如 **apify/website-content-crawler**
用户为下一个 Actor 创建一个任务,并将任务 ID 传递给增量爬虫,增量爬虫在找到更新链接后调用该任务。
nextRunId:后续任务的 ID(可选)nextRunAttribute:在下一次运行中要更新的属性(默认为“startUrls”,可选)
示例配置
基本设置示例
{"url": "https://www.example-news-site.com","daysAgo": 2,"maxResults": 100}
包含后续任务的高级设置
{...."nextRunId": "your-task-id","nextRunAttribute": "startUrls"}
优化结果的技巧
- 使用滑动窗口以确保捕获所有相关更新。例如,对于每日抓取,将
daysAgo设置为 2 或 3 天;对于每周抓取,设置为 8 或 9 天。
有关使用增量链接爬虫的更多信息,请参阅文档。