与任何完整网站(不仅仅是单个页面)聊天。完整教程

网络上充满了信息,有时很难找到适合您特定需求的信息。如果网站提供商没有或搜索功能薄弱(例如仅关键词搜索),则更是如此。
什么是“与网站聊天”?
通过“与网站聊天”方法,我们不仅仅是向 ChatGPT 询问一个主题。我们首先将网站信息提供给 GPT,然后开始询问有关该网站的问题。与简单地上传单个文件不同,这种方法允许您询问有关整个网站的问题,而不仅仅是单个页面。
为什么不直接使用站点搜索?.
与站点搜索的区别在于,我们可以用自然语言与文档进行实际聊天和互动,而不仅仅是基于关键词。您甚至可以提出一个问题并获得针对该特定查询的答案。
为什么不直接使用 ChatGPT,即不进行爬取?.
与不进行嵌入,直接向 LLM 提问,而不进行爬取并向其提供文档相比,存在幻觉的风险——LLM 会编造不存在或事实错误的内容,从而误导用户。这可能会让您迷失方向,无法按照应采取的步骤完成任务。
解决方案:爬取 + 嵌入 + 聊天.
幸运的是,有一种解决方案可以查询网络上这种非结构化但非常有价值的信息:使用 LLM 来解释这些信息并回答我们的问题。网络上关于如何使用文件或文件夹来做到这一点的信息很多,但对于复杂的网络结构(包括机器人防护和链接跟踪),这可能不是一项简单的任务。
如果您想超越分析或爬取单个网页的文本,通常需要考虑以下几点:
- 模拟 JavaScript
- 使用代理绕过机器人防护
- 跟踪链接到一定深度
- 自动滚动
- 提取文本并跳过所有不重要的内容,如导航等。
- 还有更多
但让我们退一步。我们通常需要实现一个完整的解决方案需要什么?在爬取整个网站之后,我们需要与之对话。
在一个完美的世界里,您会有一个这样的工作流程:
爬取 > 提取/清理 > 嵌入以进行向量搜索 > 使用 LLM 对此数据进行 QA.
一些商业现成解决方案提供 AI 搜索功能来爬取整个站点,这很棒。但有一个问题:您无法控制该爬虫。
还有更多:数据爬取后会发生什么,即它是如何进行分块和**嵌入**以进行检索等?这部分通常也受到限制。
有数十种开箱即用的解决方案,但它们大多或全部都缺乏这种控制。我承认,有时对于一个链接简单的小型网站,使用现成解决方案可能就足够了(如果它是免费的或价格可承受的话)。但在许多情况下,如果您想获得可靠的结果,您需要对爬虫和提取过程有更多的控制。
如果您想构建一个可靠的解决方案,我建议将其分解成几部分,并使用专门从事每个部分的工具,而不是依赖一个供应商来完成所有工作,这样做的缺点是高度主观,控制有限,而且最重要的是,完全锁定供应商。这是我的个人观点,特别是对于对您真正重要的应用程序。
好的,让我们回到我们的示例:**创建一个 RAG 以与网站聊天**(这里:Obsidian 文档)
我们的管道,我看到两个主要部分
第一部分:收集数据
爬取 > 提取/清理。
第二部分:分析并实际使用这些数据。
嵌入 > 检索 / 使用 LLM 进行 QA
在本教程中,我们将使用 Apify 进行工作流程的第一部分(数据提取),并使用 Open WebUI 进行第二部分(嵌入和使用数据进行 QA)。
对于第一部分,有一些平台专门使用多个代理进行爬取,并使用最先进的技术来爬取包含数千甚至数十万页面的大型网站。我多年来一直在广泛使用的一个是 Apify。
如果您从未听说过 Apify,请自行谷歌:)
我已经创建了一些 Open WebUI 的教程,您可能希望在继续之前阅读它们。
使用场景将是**爬取我钟爱的笔记工具 Obsidian** 的文档,将其嵌入 OpenWebUI,然后询问有关特定使用场景的问题,例如如何创建和使用 Canvas,如何使用 Markdown 等,或文档中提供的任何其他问题。
如果您没有 Apify 帐户,可以免费注册,甚至可以免费获得每月 5 美元的报价。对于小型爬取任务,这通常就足够了。
那么,让我们开始吧。
https://console.apify.com/actors/aYG0l9s7dbB7j3gbS/input
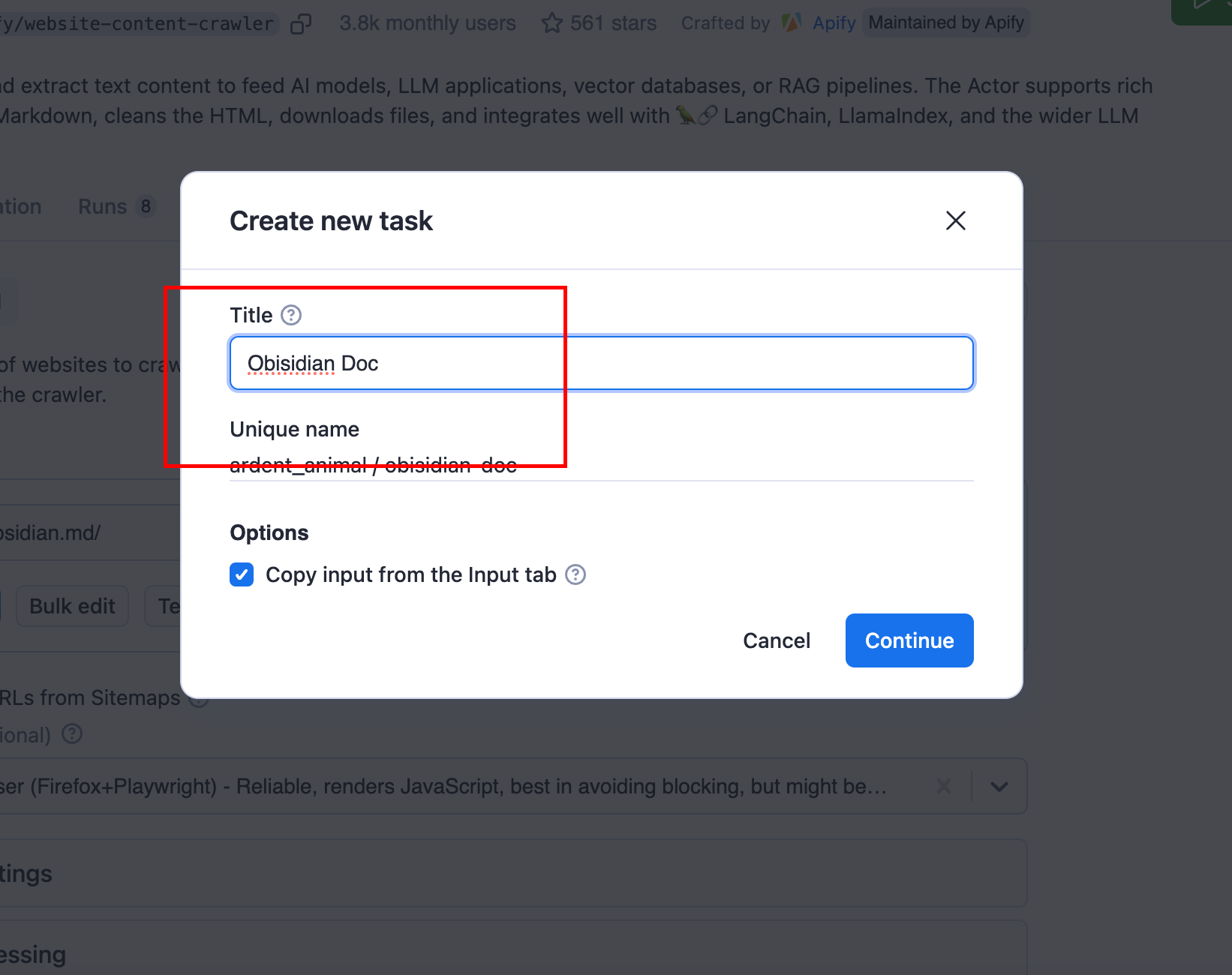
步骤 1:打开网站内容爬虫 actor(这是包含获取整个网站所有内容的所有细枝末节的逻辑片段,具有大量配置)。然后按下“创建任务”。这就是爬取任务。给它一个类似“Obsidian 文档”的名称。
然后为起始 URL 设置一些基本配置。
使用此链接:https://help.obsidian.md
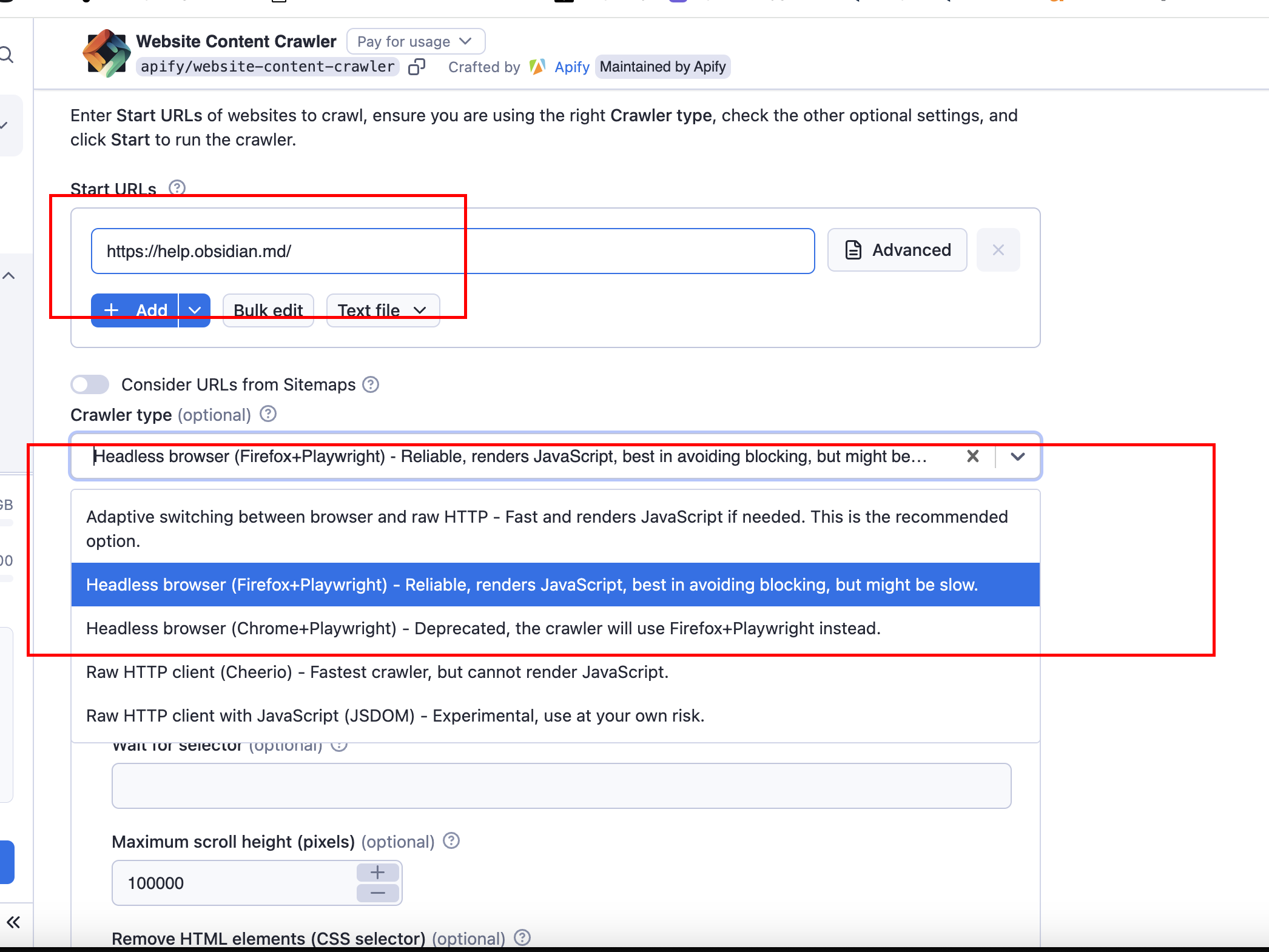
然后添加一个模式,例如这样爬取所有与文档相关的页面
https://help.obsidian.md/**(请注意,双星号表示无论深度如何,只要主部分 help.obsidian.md 在 URL 中,所有页面都将被爬取)