使用 RunPod 和 AnythingLLM(无服务器)部署私有 Hugging Face 模型以进行推理




本指南将引导您在 RunPod 的 **无服务器** 基础设施上部署私有 Hugging Face 模型,并将其连接到 AnythingLLM。此设置允许您运行自己的 AI 模型进行聊天交互,而无需依赖公共 API。
为什么选择无服务器?
此设置的主要优点是运行私有 AI 模型具有成本效益。传统的 AI 产品通常需要持续运行的专用 GPU 资源,这可能非常昂贵,尤其是对于不频繁使用的情况。此方法利用了**按使用付费定价**,您只在使用模型时才需要付费。例如,您可能需要为 48 GB GPU 支付约 0.00034 美元/秒,但至关重要的是,**当模型空闲时,您无需支付任何费用**。这使其成为具有零星或不可预测使用模式的项目的理想选择。尽管有 Fireworks.ai 等多家提供商提供此类服务,但本指南以 RunPod 为例。通过将无服务器产品与您的私有 Hugging Face 模型和 AnythingLLM 相结合,您可以获得一个功能强大、定制化的 AI 模型,并且具有仅按实际使用付费的成本效益,与始终开启的 GPU 实例相比,这可能会节省大量成本。
什么是 AnythingLLM?
AnythingLLM 是一个开源的全栈“与您的文档聊天”应用程序,允许用户在私有和企业环境中与他们的文档聊天⁵。它不断发展并提供以下关键功能
- 能够上传文档并将其嵌入工作区⁵
- 智能重用工作区中的数据,无需复制原始数据源⁵
- 文档嵌入的成本估算⁵
- 工作区设置以自定义 LLM 的响应、聊天历史记录和提示⁵
- 运行聊天历史记录以保持上下文⁵
- 能够向现有工作区添加或从中删除文档⁵
AnythingLLM 由 Mintplex Labs 开发,可在 GitHub 上找到:https://github.com/Mintplex-Labs/anything-llm
第 1 部分:为 Hugging Face 模型设置 RunPod
1. 在 RunPod 上选择无服务器 vLLM
前往 https://www.runpod.io/console/serverless
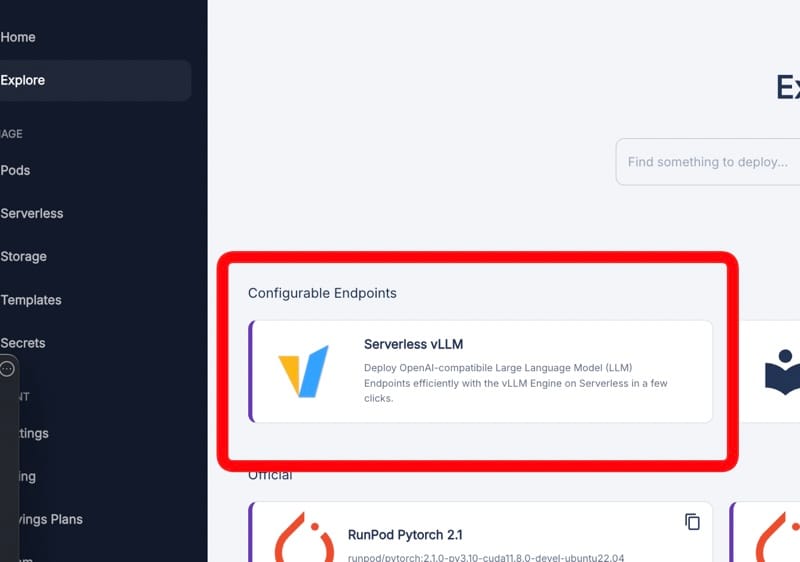
选择“Serverless vLLM”。我们之所以使用它,是因为它针对运行大型语言模型进行了优化,并提供了 OpenAI 兼容的 API,而 AnythingLLM 集成需要此 API。
2. 配置您的 Hugging Face 模型
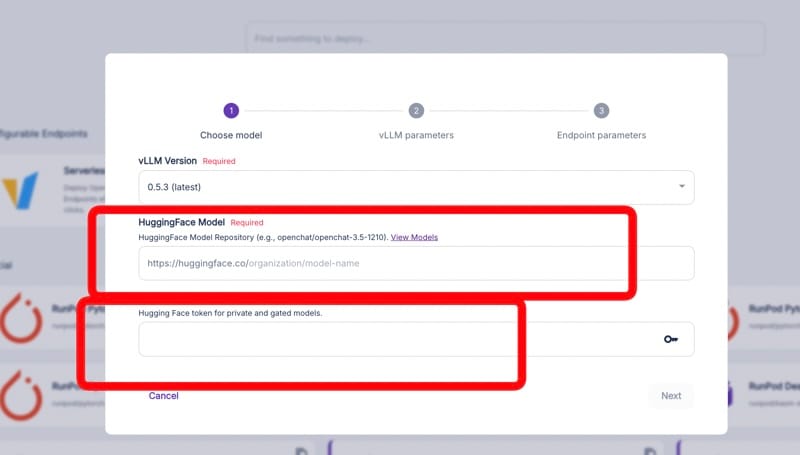
输入您的 Hugging Face 模型详细信息
- 模型名称:您在 Hugging Face 上的模型的完整路径。
- 令牌:您用于访问私有模型的 Hugging Face API 令牌。
此步骤告诉 RunPod 要部署哪个模型以及如何访问它。
3. 创建 RunPod API 密钥
前往 https://www.runpod.io/console/user/settings
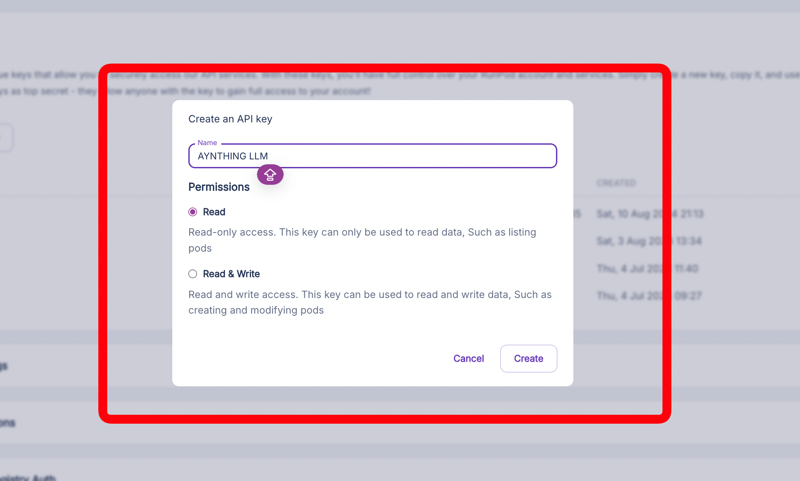
创建一个新的 API 密钥。此密钥将用于验证对已部署模型的请求。
4. 记下您的 API 密钥
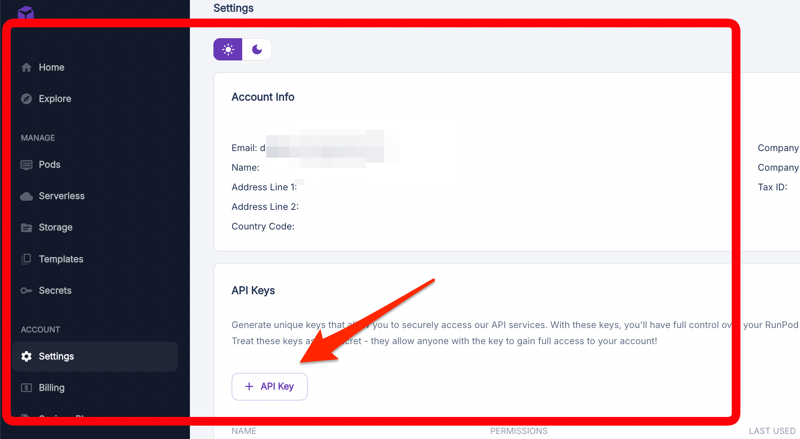
记下您的 API 密钥。您将需要这些密钥才能与部署的模型进行交互。
5. 查看您的无服务器端点
返回 https://www.runpod.io/console/serverless
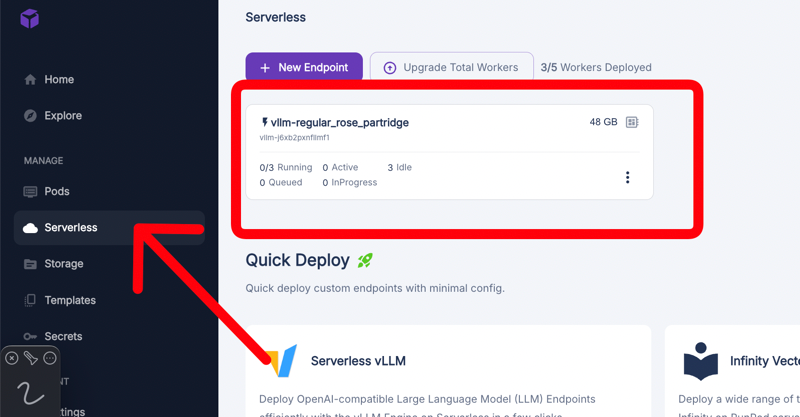
查找您新创建的端点。这表明您的模型现已部署并可供使用。
6. 访问端点详细信息
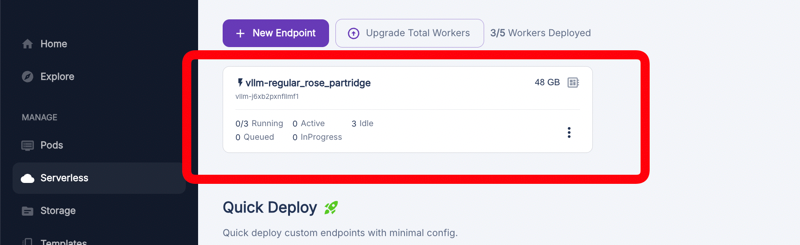
点击您的端点以查看其详细信息。这为您提供了有关已部署模型状态和使用情况的信息。
7. 获取 OpenAI 基本 URL
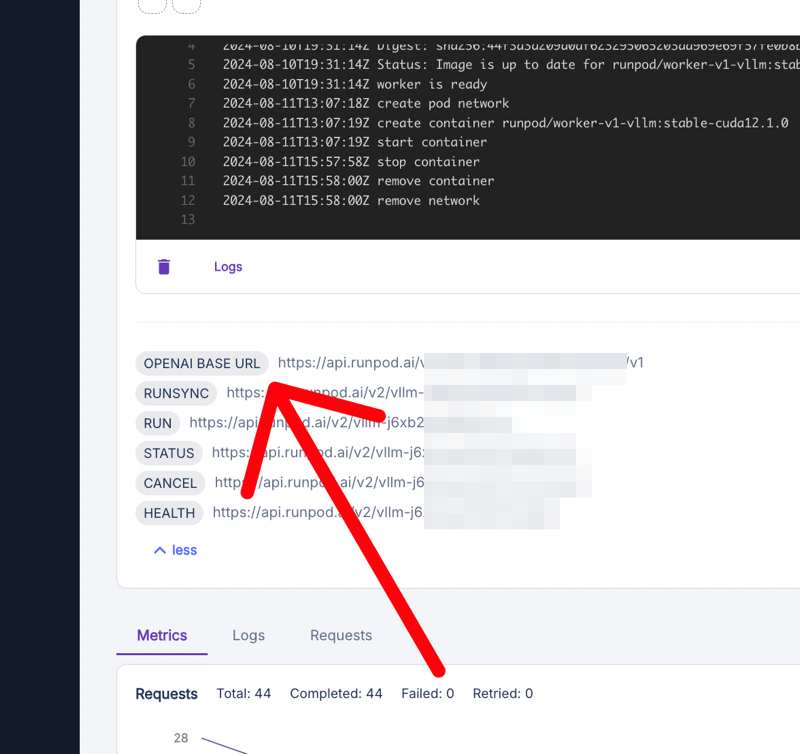
查找并复制“OPENAI BASE URL”。此 URL 至关重要——它是 AnythingLLM 将请求发送到您的模型进行交互的地方。
第 2 部分:配置 AnythingLLM
8. 打开 AnythingLLM 设置
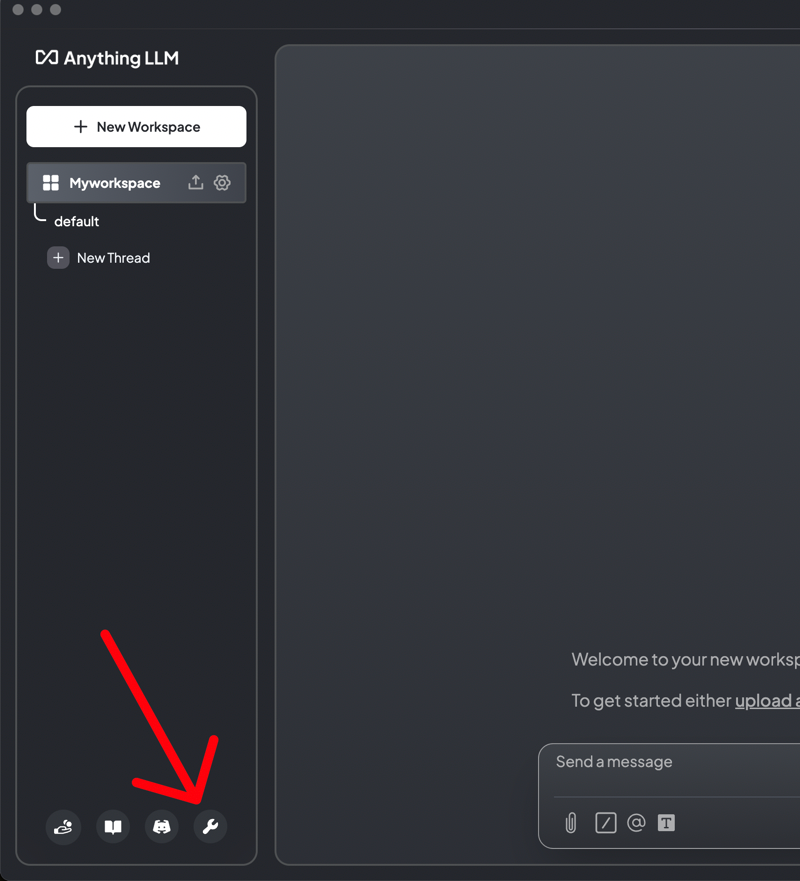
在 AnythingLLM 中,转到设置。我们需要将其配置为使用您在 RunPod 上部署的模型,而不是默认选项。
9. 导航到 AI 提供商
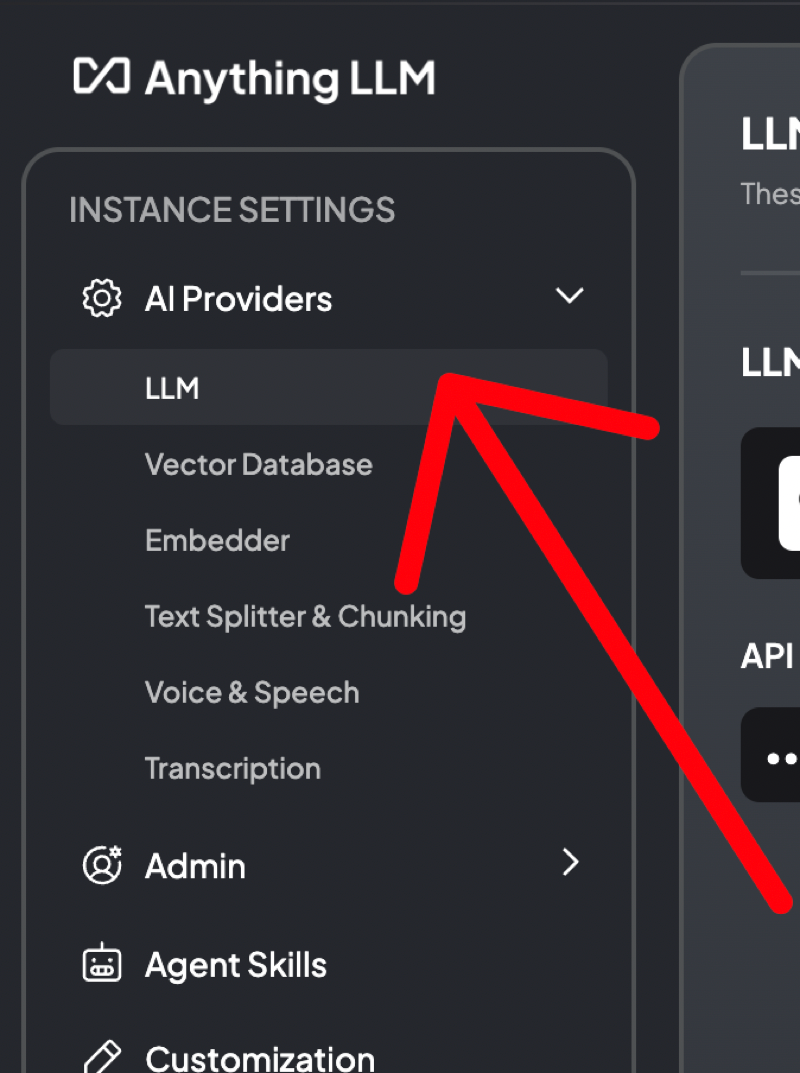
在设置中,转到 AI 提供商并选择“LLM”。在这里您可以告诉 AnythingLLM 有关您的自定义模型的信息。
10. 设置 LLM 提供商
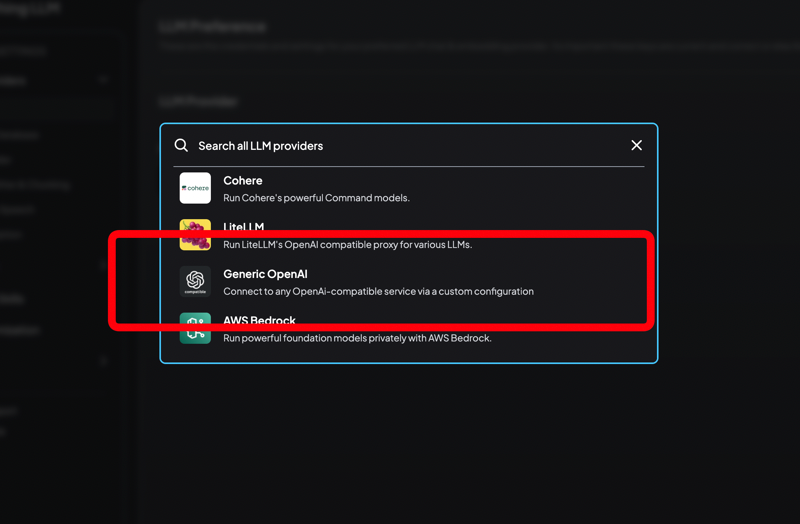
选择“通用 OpenAI”作为提供商。此选项允许 AnythingLLM 使用 OpenAI 兼容的 API 与您在 RunPod 上部署的模型进行通信。
11. 输入您的模型详细信息
在 OpenAI 设置中(图像中未显示)
- OpenAI 基本 URL:粘贴步骤 7 中的 URL。
- API 密钥:输入步骤 3 中的 RunPod API 密钥。
- 模型名称:您的 Hugging Face 模型名称。
这些设置将 AnythingLLM 连接到 RunPod 上的特定模型。
12. 保存并测试
保存您的设置并测试连接。AnythingLLM 现在应该能够使用您托管在 RunPod 上的私有模型进行聊天。
请注意,启动可能需要几秒钟。您可以增加空闲超时以避免每次在短时间内与模型聊天时都重新启动。
结论
您现在已经使用您自己的 Hugging Face 模型设置了一个私有 AI 聊天系统,该模型托管在 RunPod 上,并与 AnythingLLM 集成。此配置使您可以控制模型并保持数据私密,同时仍提供类似 ChatGPT 的体验。