如何让 GPT 像咨询顾问一样说话



你是否曾经向 GPT 提问一个简单的问题,却得到了大量信息,其中许多信息无关紧要,甚至让人感到不知所措?
下面是一个例子
你:“我如何减肥?”
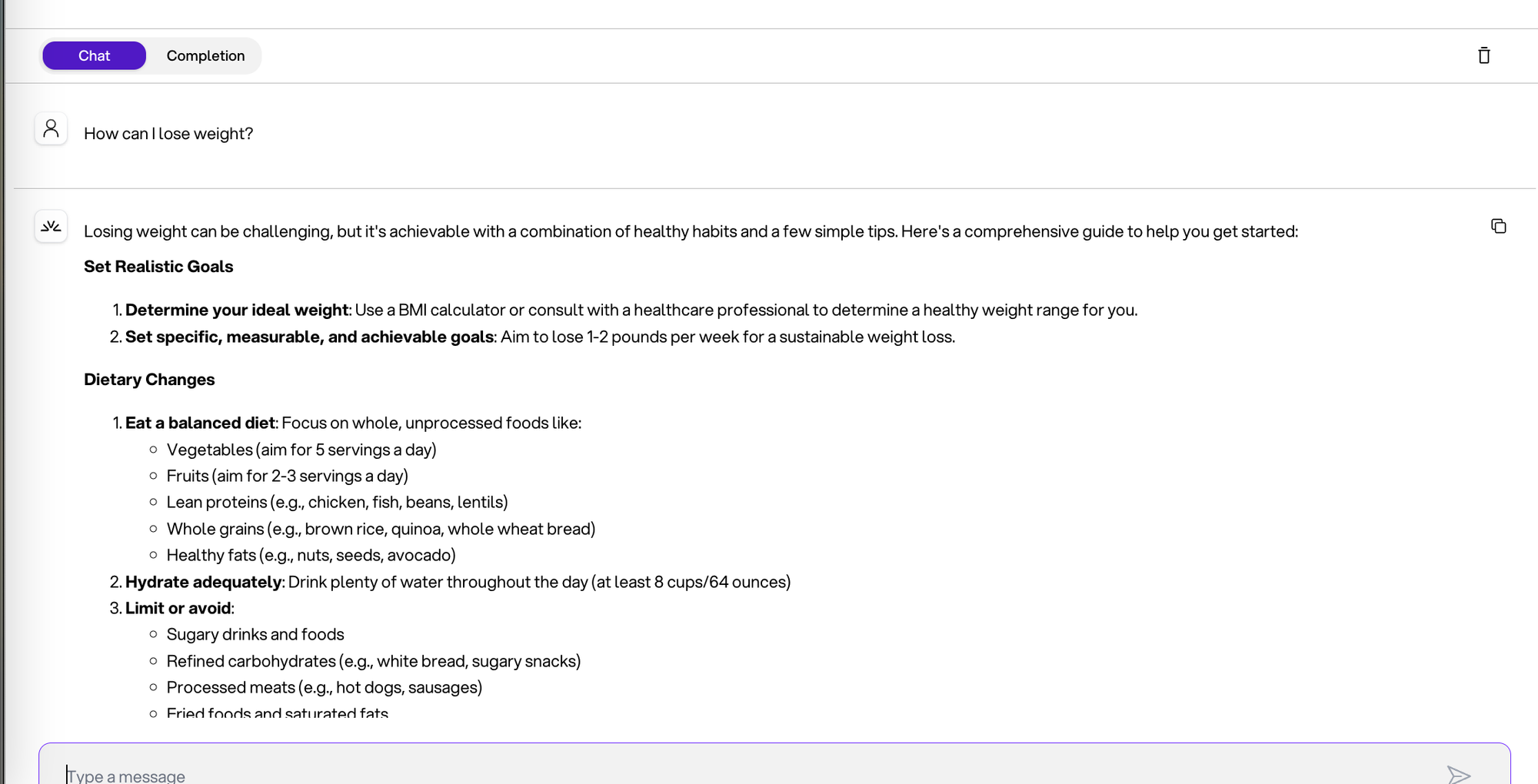
我不知道你收到这么多信息时是什么感觉,但我个人感觉**不堪重负**😄**
相反,我期望一个知识渊博的人类顾问在给出建议之前,会尝试缩小搜索范围。
也许是这样:
“减肥可能很困难。**你是在寻找饮食方面的建议,还是想了解一些锻炼方案?**请告诉我,这样我才能为你提供最适合你情况的建议。”
这是我们可以通过微调技术改进的地方。
在本指南中,我将向你展示如何微调 LLaMA-3 来实现这一点。在 LLaMA-3 仓促下结论之前,它会首先尝试了解你的偏好,然后最终给出量身定制的建议。
为了演示这个概念,我使用了我用 ChatGPT 创建的一个小型数据集。在实际场景中,你会使用更大的数据集来反映你的领域和对话模式。
环境设置
我们将使用 LLaMA-Factory(一个用于微调语言模型的开源框架)和 Vast.ai(一个类似于 Colab 但更便宜的 GPU 实例租赁平台)。或者,你可以使用任何支持 GPU 的虚拟机。
步骤 1:准备环境
- 访问Vast.ai并创建一个新实例
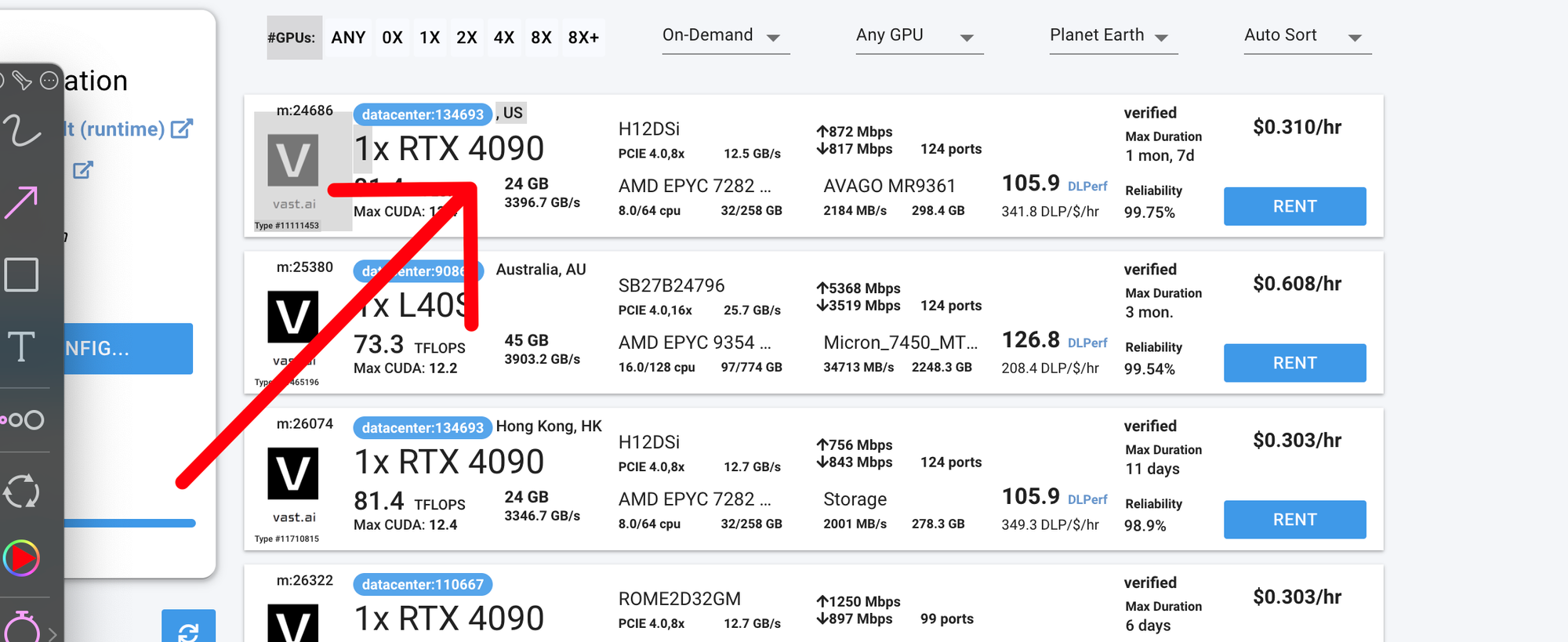

然后在浏览器中打开 Jupyter Notebook——或者,你也可以在 Visual Studio Code 中使用 ssh 运行它。为简单起见,我们将直接在浏览器中完成整个教程。
然后启动新终端
步骤 2:安装必要软件包
通过安装所需软件包来设置你的环境
pip install --upgrade huggingface_hub
huggingface-cli login
⚠️
如果您尚未获得LLaMA3b的访问权限,请注意,您必须在Hugging Face上请求llama3的访问权限(它是免费的)。
[
meta-llama/Meta-Llama-3.1-8B-Instruct - Hugging Face
我们正在通过开源和开放科学来推进人工智能并使其民主化。

](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct)
步骤 2:安装 LLAMA Factory
克隆 LLaMA-Factory 仓库
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
步骤 3:测试模型当前行为
开始一个聊天会话来测试基础 LLaMA-3 模型的行为
llamafactory-cli chat --model_name_or_path meta-llama/Meta-Llama-3-8B --template llama3
💡
请注意,下载模型并启动推理可能需要几分钟。
现在我们可以试验基础模型,看看它在微调之前的行为。
步骤 4:微调模型
下载一个将对话结构化得更像人类顾问的数据集
wget https://huggingface.co/datasets/airabbitX/gpt-consultant/resolve/main/gpt_consultant.json
以下是数据集中的一个摘录
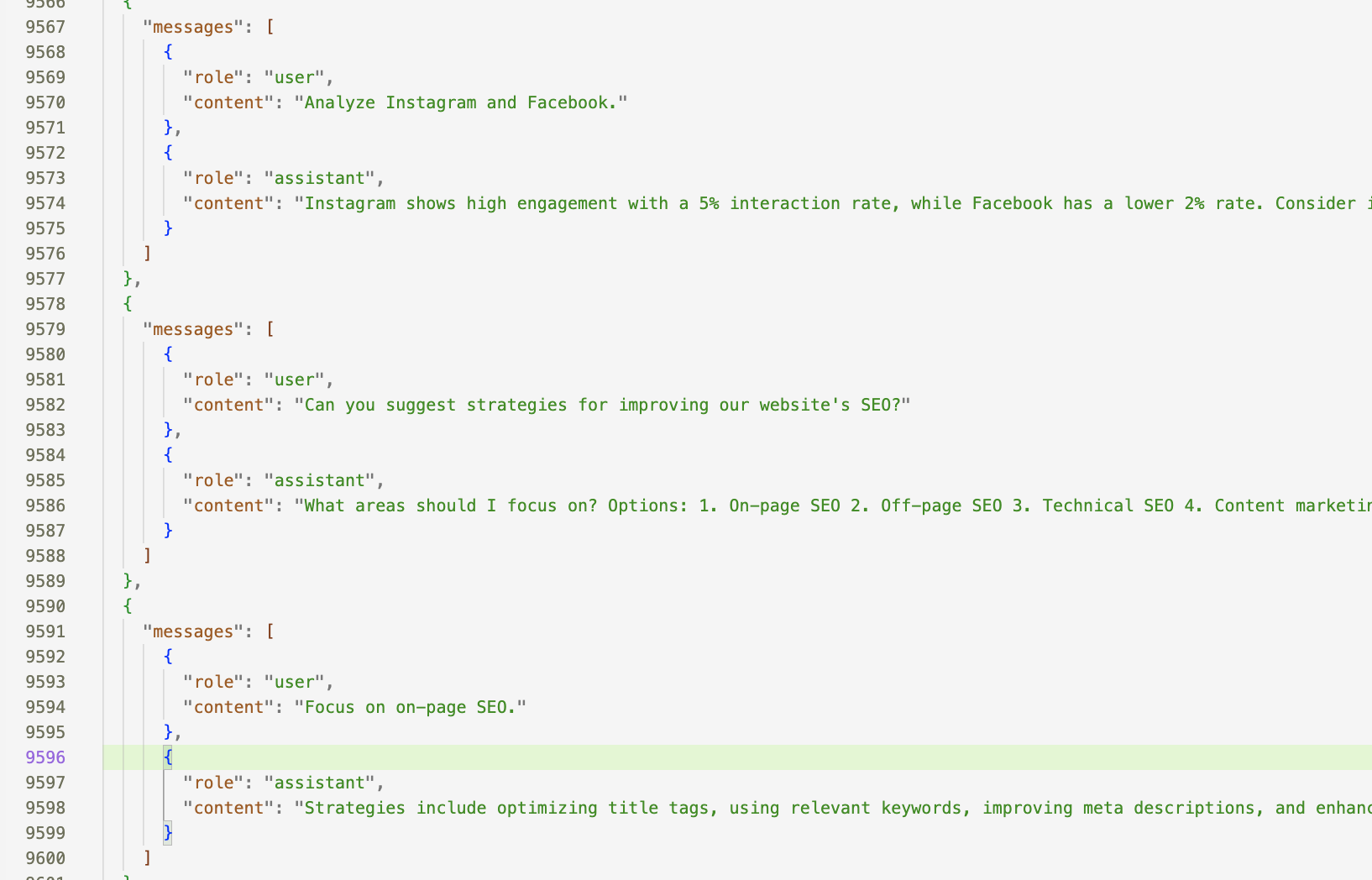
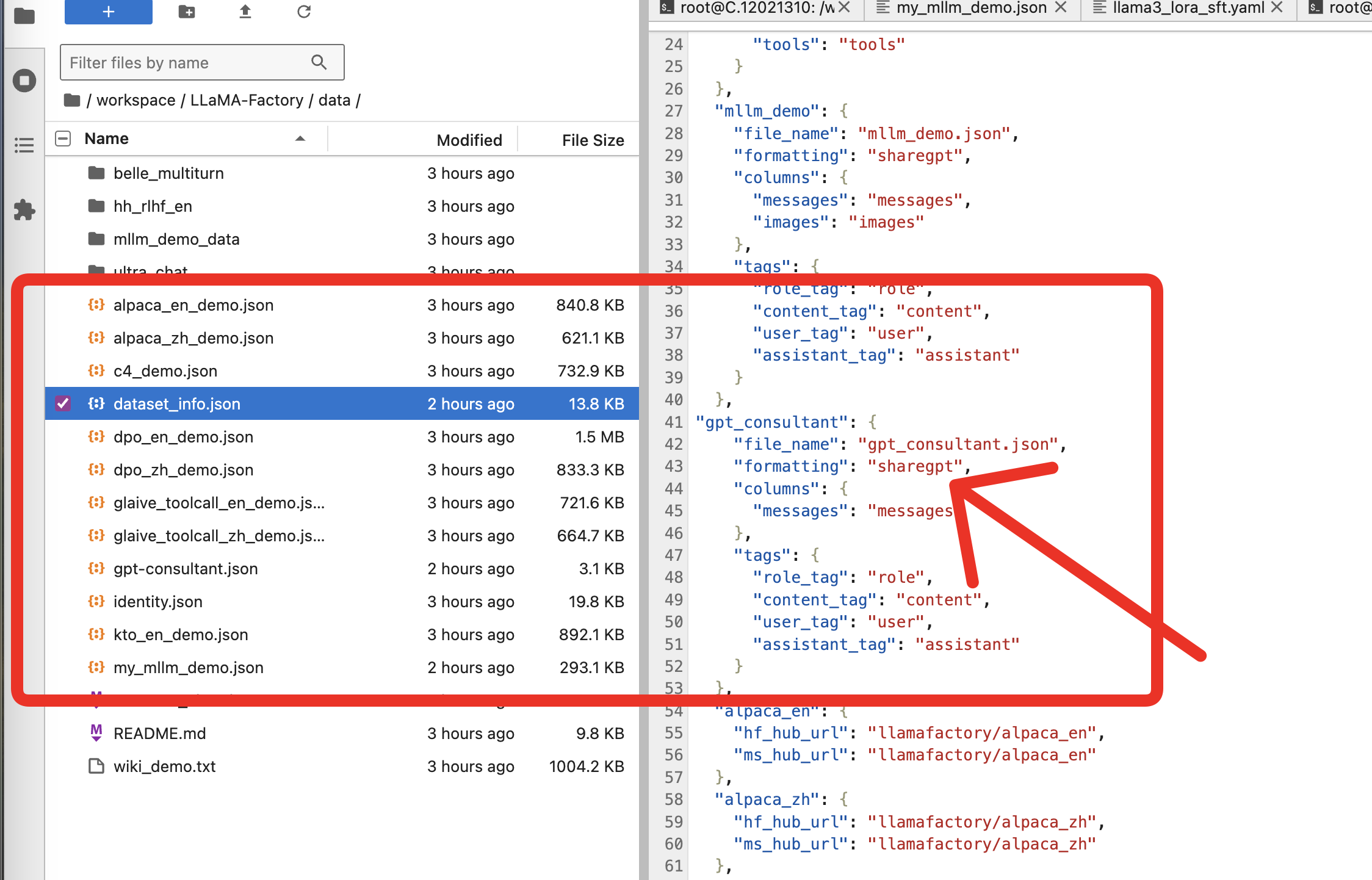
将json文件上传到该路径
/workspace/LLaMA-Factory/data

在llamafactory中为datasetinfo.json添加一个新条目
"gpt_consultant": {
"file_name": "gpt_consultant.json",
"formatting": "sharegpt",
"columns": {
"messages": "messages"
},
"tags": {
"role_tag": "role",
"content_tag": "content",
"user_tag": "user",
"assistant_tag": "assistant"
}
}
现在我们可以开始用数据集训练模型了。
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
如果一切顺利,你应该会看到这样的进度。

步骤 5:测试微调后的模型
训练完成后,再次测试模型以查看改进后的行为
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
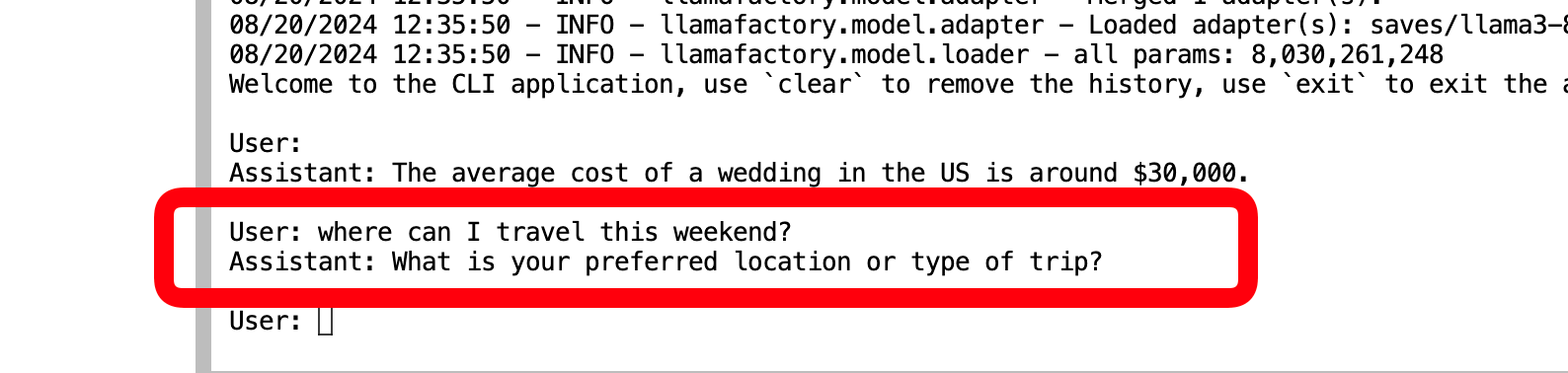
现在我们向模型提出我们曾向原始 LLAMA3b 提出的问题。
如你所见,它会先尝试了解你的背景和情况,然后再得出结论。这不仅仅适用于健康问题。

结论
通过微调 LLaMA-3,我们可以让模型更具对话性,更像顾问,而不是维基百科机器。
您可以通过调整超参数和向数据集添加更多对话来显著改善模型的对话能力,并且您可以尝试使用不同的模型,如 Mistral、Phi 等。
当然,这只是冰山一角。
在第二部分中,我们将对 OpenAI GPt-4o-mini 进行相同的练习。敬请期待!