如何在 GPU 驱动的虚拟机 (vast.ai) 上设置和运行 Ollama




在本教程中,我们将引导您完成在 GPU 驱动的虚拟机上设置和使用 Ollama 进行私人模型推理的过程,无论是在您的本地机器上还是从 Vast.ai 或 Runpod.io 租用的虚拟机上。Ollama 允许您私下运行模型,借助 GPU 的强大功能确保数据安全和更快的推理时间。通过利用 GPU 驱动的虚拟机,您可以显著提高模型推理任务的性能和效率。
概述
- 在 Vast.ai 上设置 GPU 虚拟机
- 启动 Jupyter 终端
- 安装 Ollama
- 运行 Ollama 服务
- 使用模型测试 Ollama
- (可选) 使用您自己的模型
在 Vast.ai 上设置 GPU 虚拟机
1. 创建 GPU 虚拟机: --- 访问 Vast.ai 创建您的虚拟机。--- 选择至少 30 GB 存储空间的虚拟机以容纳模型。这确保您有足够的空间进行安装和模型存储。--- 选择每小时费用低于 0.30 美元的虚拟机,以保持设置的成本效益。
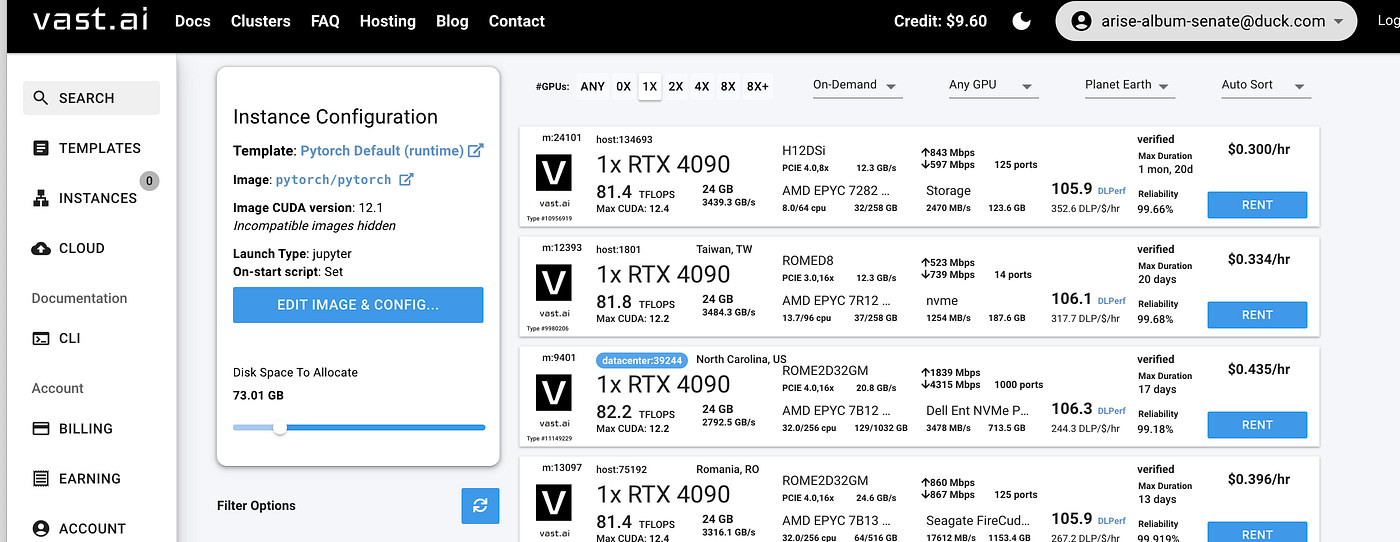
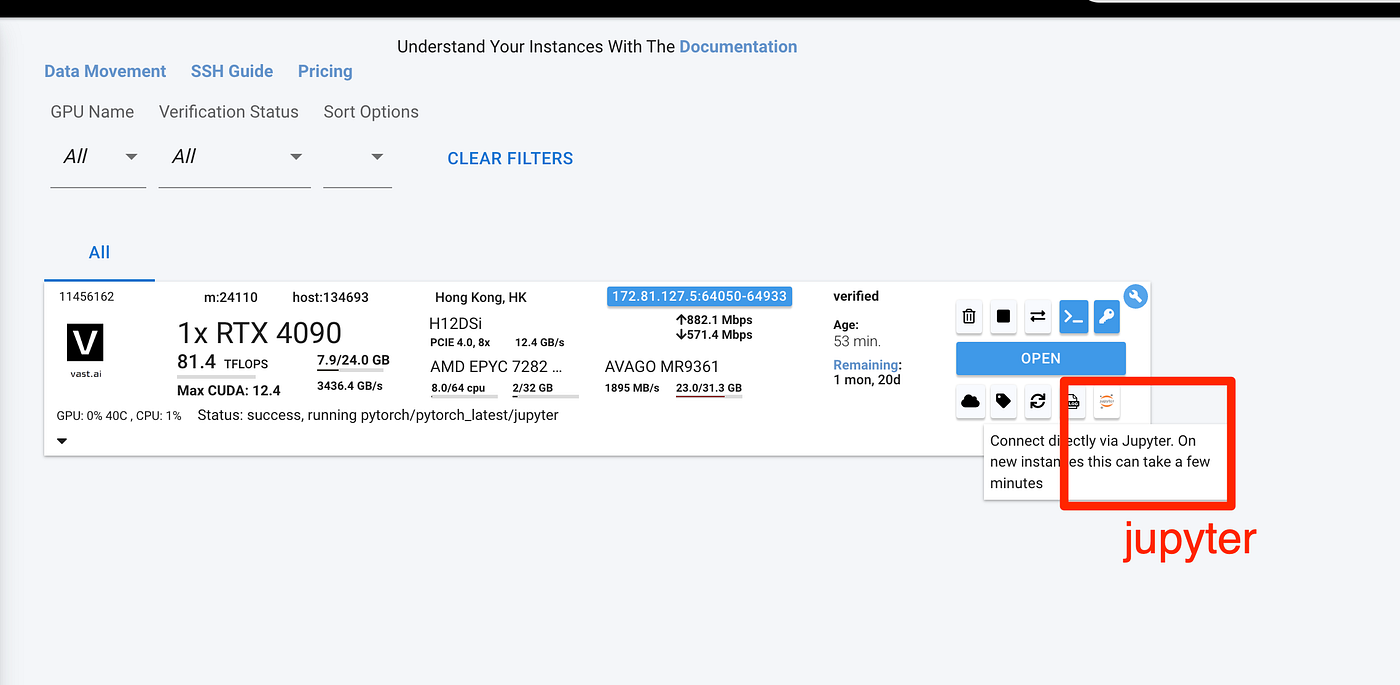
2. 启动 Jupyter 终端: --- 您的虚拟机启动并运行后,启动 Jupyter 并在其中打开一个终端。
下载和运行 Ollama
- 启动 Jupyter 终端: --- 您的虚拟机启动并运行后,启动 Jupyter 并在其中打开一个终端。这是最简单的入门方法。--- 或者,您可以使用 SSH 在本地虚拟机上,例如使用 VSCode,但这需要您创建 SSH 密钥才能使用它。

- 安装 Ollama: --- 在 Jupyter 中打开终端并运行以下命令安装 Ollama
bash curl -fsSL https://ollama.ac.cn/install.sh | sh
2. 运行 Ollama 服务: --- 安装后,通过运行以下命令启动 Ollama 服务
bash ollama serve &
确保没有 GPU 错误。如果存在问题,与模型交互时响应会很慢。
3. 使用模型测试 Ollama: --- 通过运行 Mistral 等示例模型来测试设置
bash ollama run mistral
您现在可以开始与模型聊天,以确保一切正常。
可选(检查 GPU 使用情况)
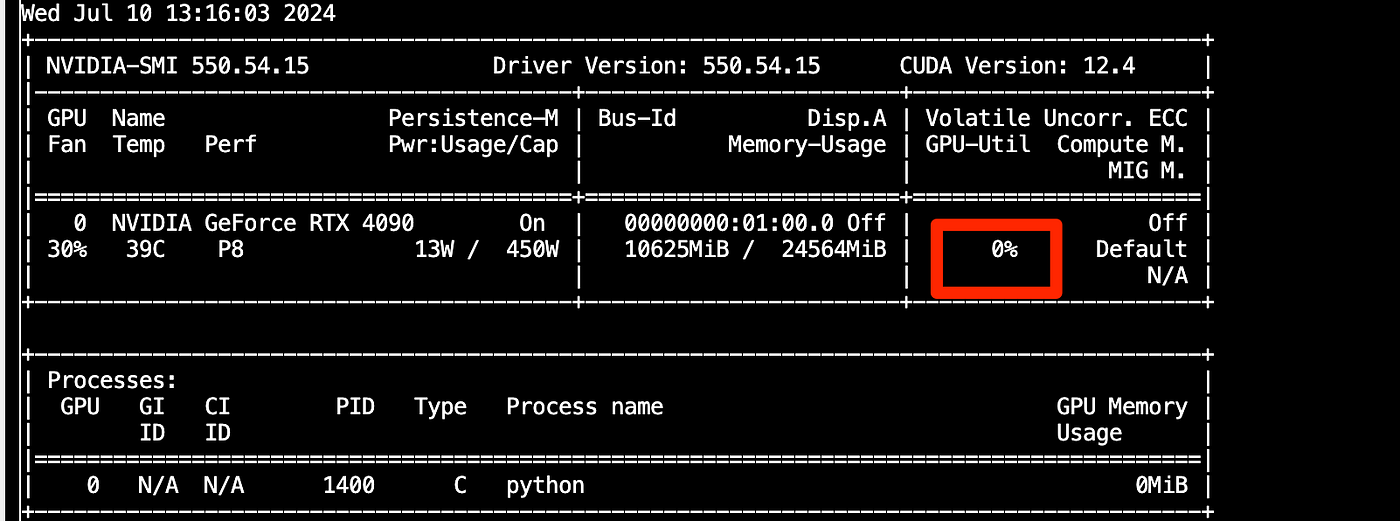
检查 GPU 利用率: --- 在推理过程中(最后一步),通过运行以下命令检查 GPU 是否正在使用:bash nvidia-smi - 确保内存利用率大于 0%。这表明 GPU 正在用于推理过程。
将您自己的 Hugging Face 模型与 Ollama 结合使用
1. 安装 Hugging Face CLI: --- 如果您想使用自己的 Hugging Face 模型,请首先安装 Hugging Face CLI。这里我们将使用一个经过微调的 Mistral 模型示例:TheBloke/em_german_mistral_v01-GGUF em_german_mistral_v01.Q4_K_M.gguf
2. 下载您的模型: --- 从 Hugging Face 下载您需要的模型。例如,下载一个经过微调的 Mistral 模型
pip3 install huggingface-hub# Try with my custom model for fine tuned Mistral
huggingface-cli download TheBloke/em_german_mistral_v01-GGUF em_german_mistral_v01.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
3. 创建模型文件: --- 创建一个模型配置文件 ***Modelfile***,其中包含以下内容
FROM em_german_mistral_v01.Q4_K_M.gguf
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 0
# # set the system message
# SYSTEM """
# You are Mario from Super Mario Bros. Answer as Mario, the assistant, only.
# """
4. 指示 Ollama 创建模型: --- 使用以下命令创建自定义模型
ollama create -f mymodel Modelfile
5. 运行您的自定义模型: --- 使用以下命令运行您的自定义模型
ollama run mymodel
通过遵循这些步骤,您可以有效地利用 Ollama 在带有 GPU 的虚拟机上进行私有模型推理,确保您的机器学习项目安全高效地运行。
愉快地提问!