LLM 聊天机器人 3.0:将 LLM 与动态 UI 元素融合







大型语言模型(LLM)极大地改变了聊天机器人和对话式人工智能,使交互更加自然和直观。然而,在某些方面仍有改进空间,可以提高其有效性。
我们来看看与传统聊天机器人的典型互动
User: I'm looking for warm travel destinations in Europe.
AI: Great! I can help with that. Which country are you interested in?
1. Spain
2. Italy
3. Greece
User: 2
AI: Excellent choice. What type of accommodation do you prefer?
1. Hotel
2. Hostel
3. Airbnb
- 用户通常需要根据 LLM 的响应进行深入或选择。
- 选择选项需要输入文本或使用编号系统。
- 此过程可能很繁琐,尤其是在进行多次选择或在移动设备上时。
使用 LLM 生成动态 UI
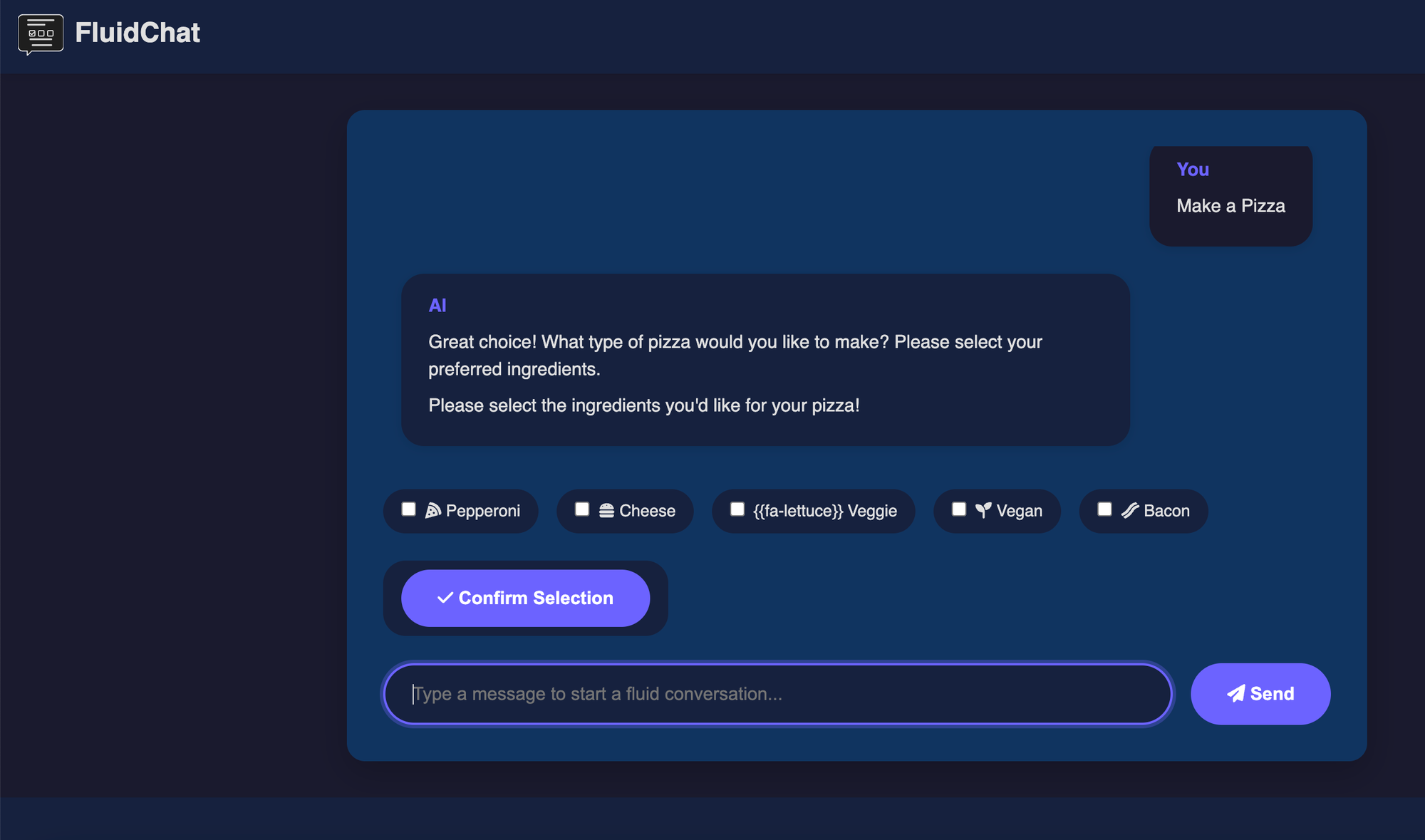
从更用户友好的角度来看同一个问题,受到网络上典型 UI 元素(按钮、图标等)的启发,我们可以将这些相同的元素集成到聊天本身。结果可能是这样的。
我们问了同样的问题,但没有仅仅得到国家列表或项目符号,而是得到了这样的选择
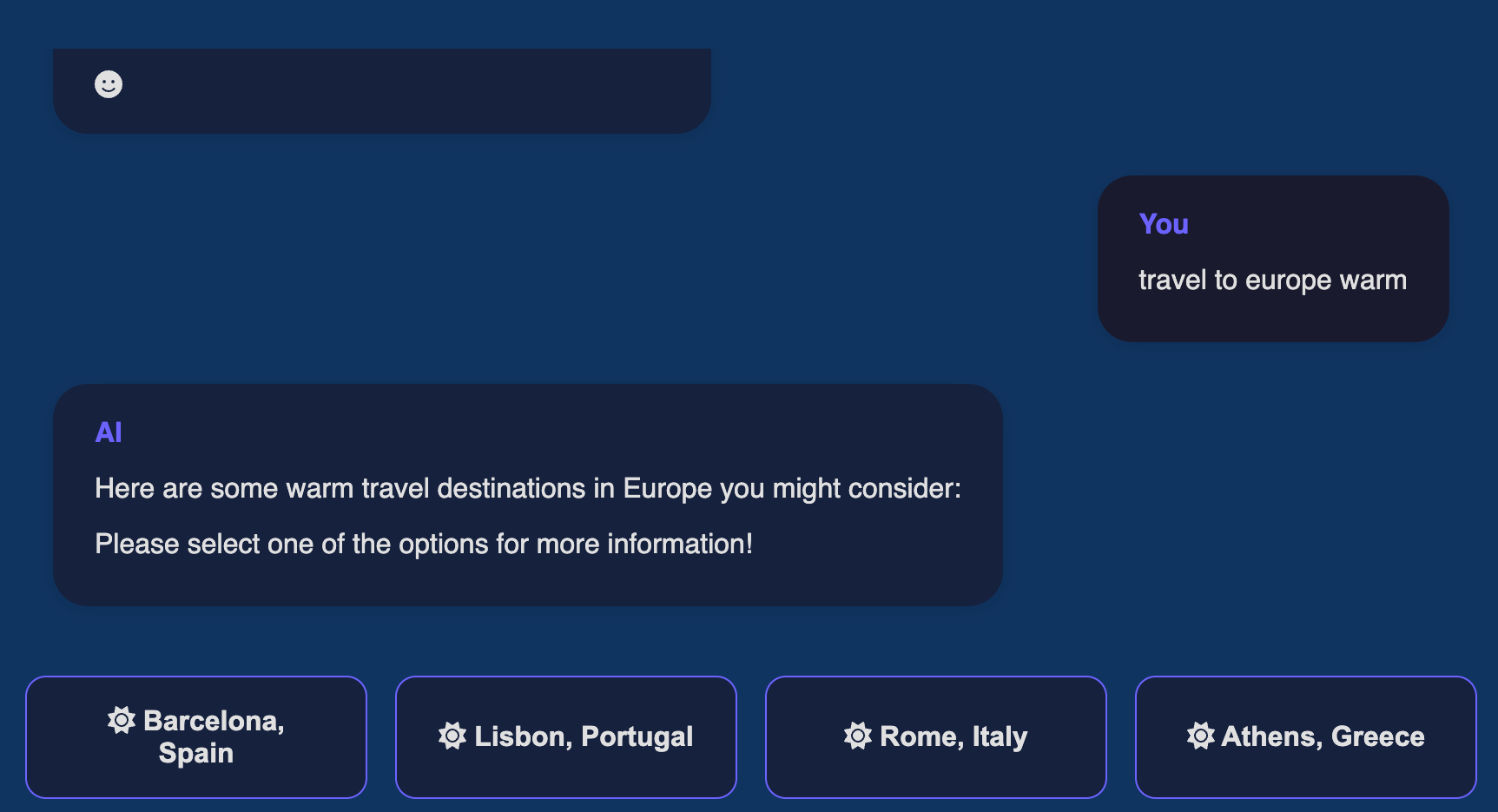
选择一个或多个项目后,会自动向 LLM 发送包含所选内容的回复,因此它“知道”我们选择了什么,在下面的案例中是“葡萄牙里斯本”。
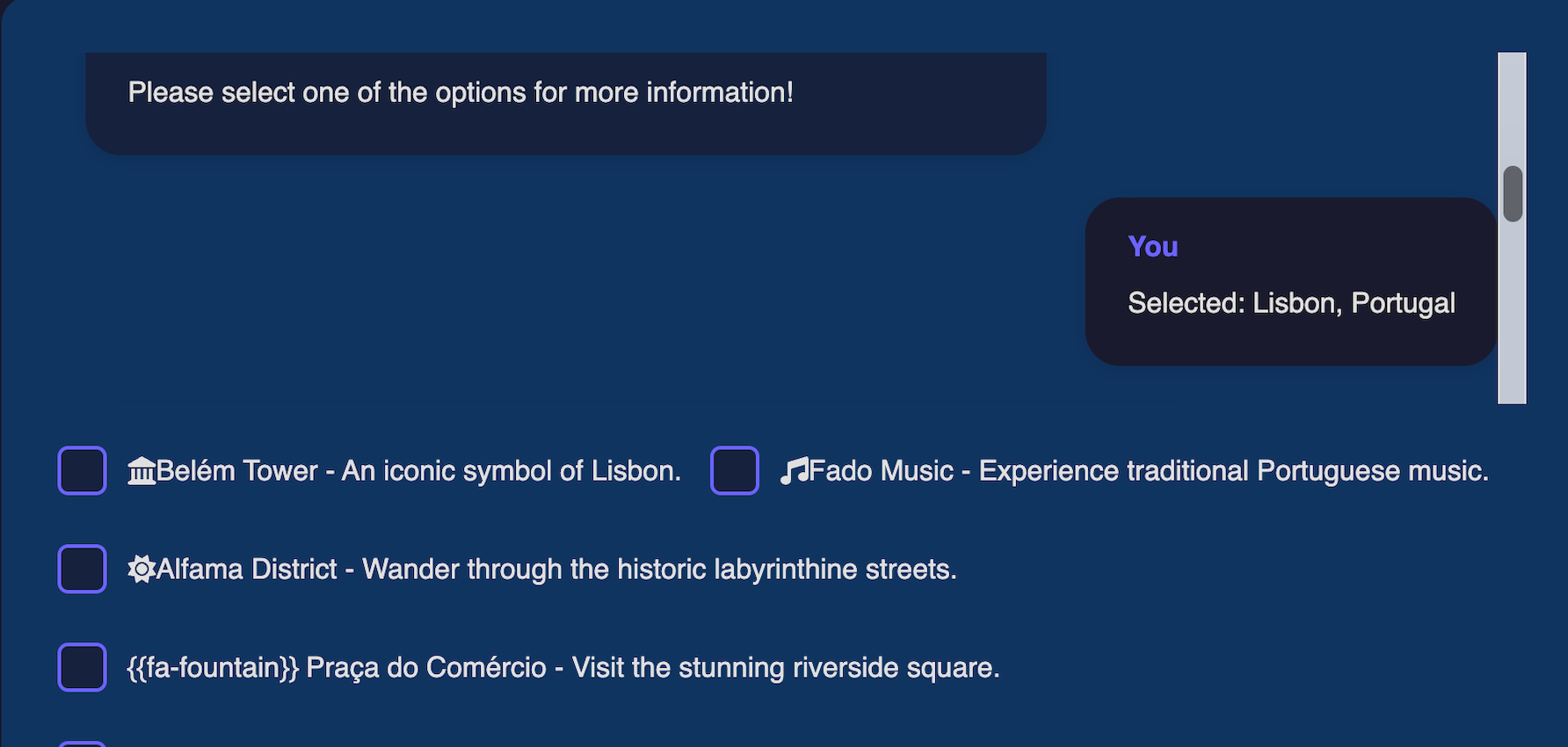
您可以在这里尝试:https://fluidchat.vercel.app
请注意,该应用程序仍在开发中,并使用 gpt-4o-mini,该模型有时无法输出某些图标的正确代码。
与基于文本的聊天对话的主要区别
- 动态 UI 生成:LLM 可以生成按钮、复选框和下拉菜单等 UI 元素。
- 交互式选择:用户可以直接通过 UI 进行选择,而无需键入响应。
- 对话上下文:UI 交互无缝集成到对话历史记录中。
- 移动友好:界面设计旨在方便在桌面和移动设备上使用。
****这种方法与 Artifact(Claude)和 Canvas(OpenAI)有何不同****
Anthropic 术语中的 Artifacts 和 OpenAI 术语中的 Canvas 都引入了以超友好方式呈现信息(如 HTML、SVG、React 等)的方法。但是,它们尚未提供捕获信息(例如用户输入)的方法。
技术深度解析
为了实现这种动态 UI 生成,我们为少数元素实现了一种非常简单的自定义标记语言。这种语言允许 LLM 不仅生成文本,还生成用于渲染 UI 元素的指令。
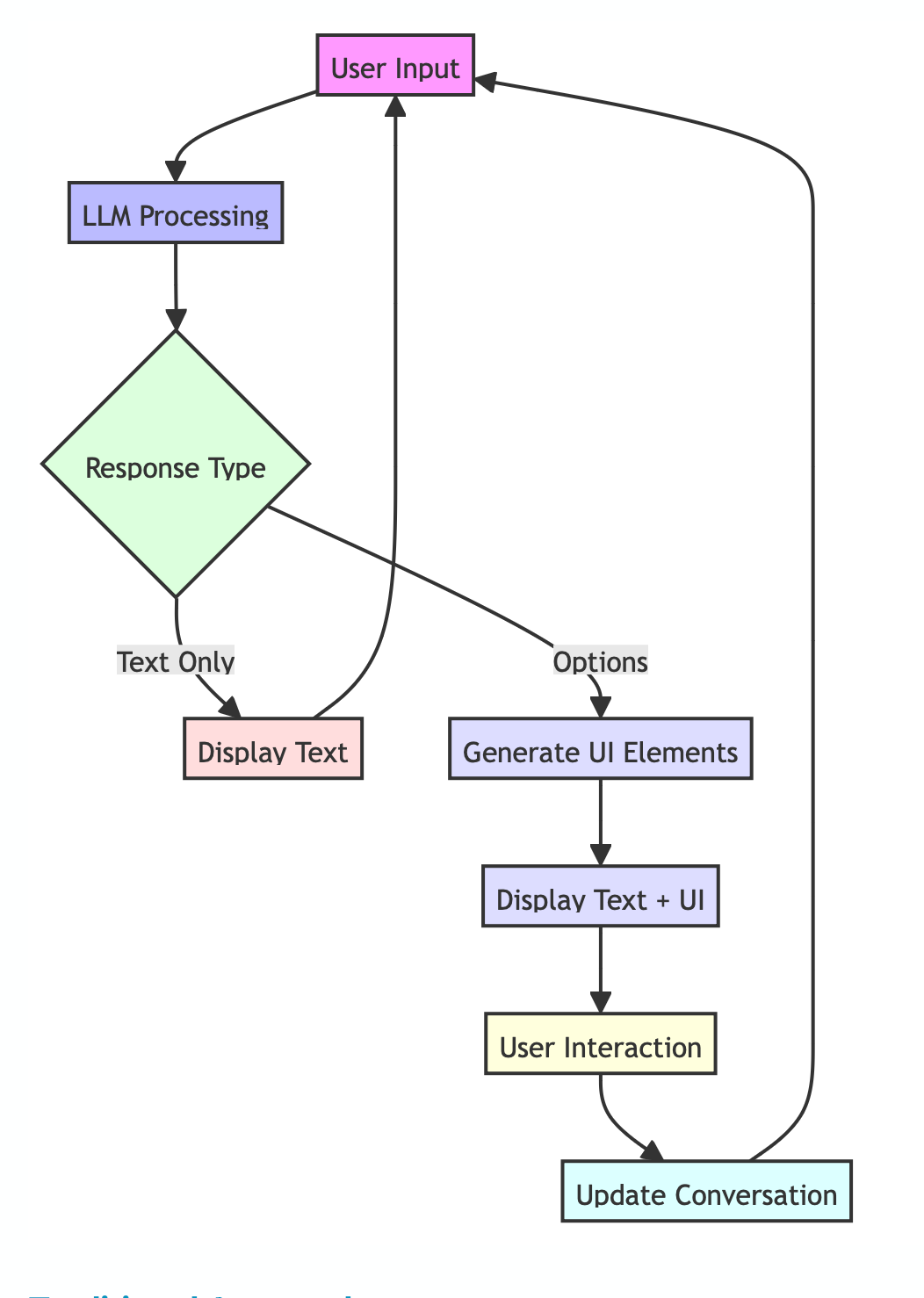
该标记语言的设计与典型的编程语言不同。这种区别至关重要,因为它可以防止 LLM 在生成实际代码片段作为对话一部分时造成混淆。
这是一个展示我们自定义标记语言某些元素的表格
为了使这项工作有效,我们需要在两方面实施它:LLM 端(通过提示)和解释并显示这些 UI 元素的客户端。
LLM 端
这是一个简单的提示,告诉 LLM 何时以及如何使用这些元素。
You are an AI assistant capable of presenting options for user selection and using Font Awesome icons. When appropriate, use the following formats:
1. [SINGLE_SELECT] for single-choice options
2. [MULTI_SELECT] for multiple-choice options
3. [CHOICE] for general choice options
Present the options in a numbered list format. Use Font Awesome icons by wrapping the icon name in double curly braces, like {{icon-name}}. Examples:
[SINGLE_SELECT]
1. {{fa-home}} Home
2. {{fa-user}} Profile
3. {{fa-cog}} Settings
[MULTI_SELECT]
1. {{fa-pizza-slice}} Pizza
2. {{fa-hamburger}} Burger
3. {{fa-ice-cream}} Ice Cream
[CHOICE]
1. {{fa-car}} Drive
2. {{fa-bicycle}} Cycle
3. {{fa-walking}} Walk
客户端
在客户端(聊天界面)我们也必须集成这些元素。
// Render different types of content
const renderContent = () => {
if (typeof message.content === 'string') {
return <p>{message.content}</p>;
}
if (Array.isArray(message.content)) {
return message.content.map((item, index) => (
<div key={index}>
{item.text && <p>{item.text}</p>}
{item.options && renderOptions(item.options, item.type)}
</div>
));
}
return null;
};
// Render interactive UI elements
const renderOptions = (options, type) => {
switch (type) {
case 'single-select':
// Render single-select buttons
case 'multi-select':
// Render multi-select buttons with confirm
default:
return null;
}
};
视觉增强:锦上添花
上述实现不仅限于输入元素,还可以添加对富可视化(如显示 font-awesome、markdown 等)的支持。其中一些视觉元素已经得到所有主要聊天机器人界面的支持。
例如,我们可以扩展我们的标记语言以包含图标规范
[CHOICE:Small{icon:pizza-sm},Medium{icon:pizza-md},Large{icon:pizza-lg}]
这可以渲染为同时包含文本和代表性图标的按钮,进一步改善用户体验。
下一步是什么
这里介绍的流畅方法只是 LLM 和用户之间交互新 UI 模式的开始,它使交互更顺畅,尤其是在用户需要大量输入(而不是简单的信息对话)时。
看看语音交互将如何发展也将很有趣,尤其是在流式语音 API 方面。然而,在我看来,文本交互永远不会失去其应用,尤其是在内容丰富的应用程序中,因为它们太嘈杂而无法听。我们已经从有时感觉像折磨的热线菜单中体验到了后者 :)