LLM 中的 RAG 与微调:综合指南与示例






大型语言模型 (LLM) 彻底改变了自然语言处理,但通过专门的技术可以进一步增强其有效性。本文探讨了两种此类方法:**检索增强生成 (RAG) 和微调**。通过理解这些方法,数据科学家和 AI 从业者可以就是否针对其特定用例采用哪种技术做出明智的决定。
引言
人工智能世界正在迅速发展,LLM 处于这场变革的最前沿。随着这些模型变得越来越复杂,**对根据特定任务或领域定制模型的技术的需求也随之增长**。RAG 和微调已成为实现这一目标的两种主要方法。这些技术到底是什么,它们又有什么区别?本文旨在揭示 RAG 和微调的神秘面纱,全面概述其机制、优势和理想用例。
什么是检索增强生成 (RAG)?
**检索增强生成(RAG),由 Meta 于 2020 年推出,是一种将 LLM 连接到精选的动态数据库的架构框架**。这种连接允许模型访问最新且可靠的信息并将其纳入其响应中。但这个过程到底是如何运作的呢?
当用户提交查询时,RAG 系统首先在其数据库中搜索相关信息。然后,检索到的数据与原始查询结合,并输入到 LLM 中。最后,**模型利用其预训练知识和检索到的信息提供的上下文生成响应**。这种方法使 LLM 能够生成更准确、更符合上下文的输出。
RAG 的主要优势之一是它能够增强安全性和数据隐私。与其他可能暴露敏感信息的方法不同,**RAG 将专有数据保留在安全的数据库环境中,从而实现严格的访问控制**。这一特性使得 RAG 对处理机密信息的企业特别有吸引力。
微调的力量
**微调涉及在较小、专门的数据集上训练 LLM,以调整其参数以适应特定任务或领域**。这个过程允许模型在处理特定类型的查询或生成领域特定内容方面变得更加熟练。但是,是什么让微调如此有效呢?
通过使模型与利基领域的细微差别和术语保持一致,**微调显著提高了模型在特定任务上的性能**。例如,Snorkel AI 的一项研究表明,一个经过微调的模型达到了与 GPT-3 模型相同的质量,同时体积小 1,400 倍,并且需要的真实标签不到 1%。
然而,微调并非没有挑战。**它需要大量的计算资源和高质量的带标签数据集**。此外,经过微调的模型可能会随着它们的专业化而失去一些通用能力。在决定是否采用微调时,必须仔细考虑这些因素。
选择正确的方法
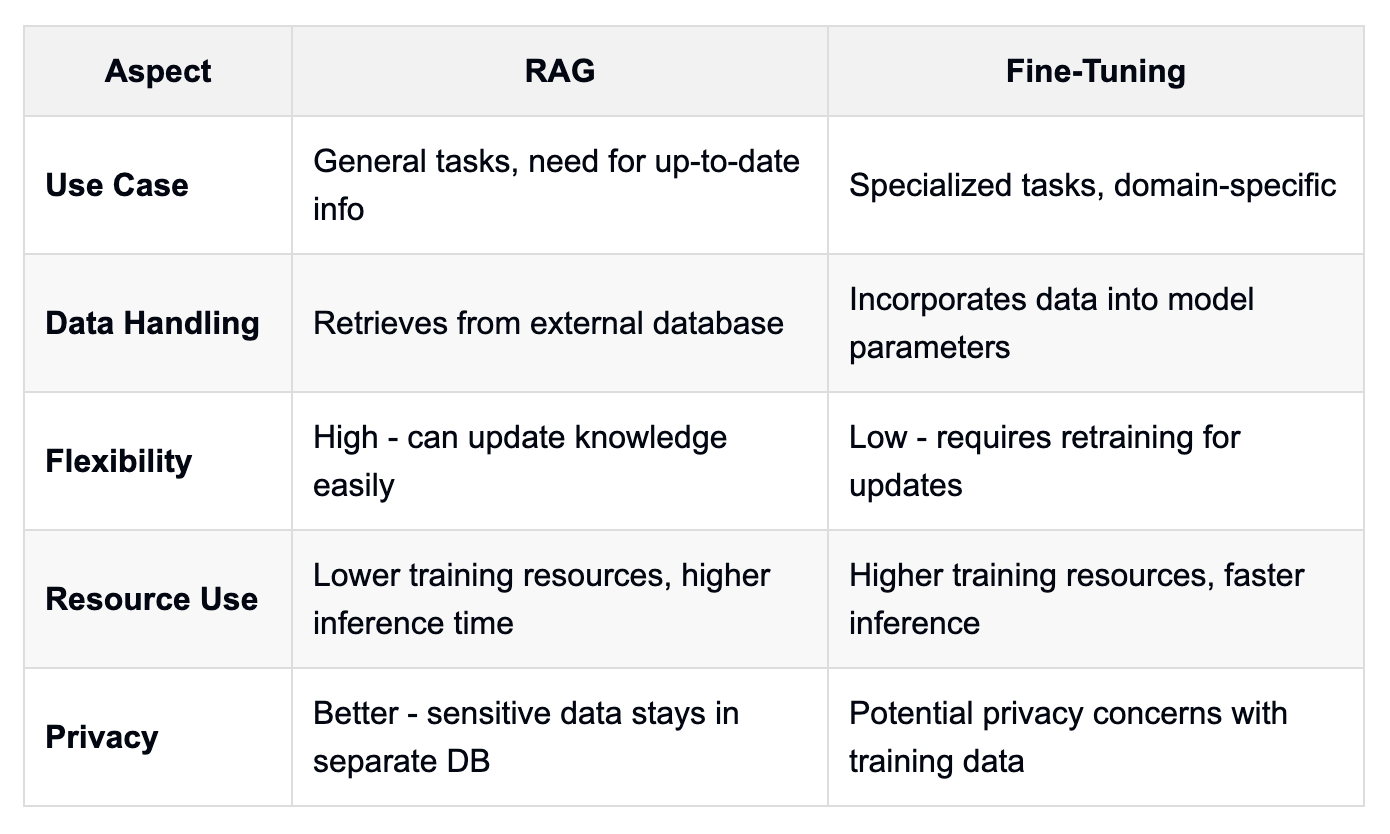
从业者如何决定是为特定用例使用 RAG 还是微调?该决定通常取决于各种因素,包括**安全要求、可用资源以及手头任务的特异性**。
**由于其可扩展性、安全性和整合最新信息的能力,RAG 通常是大多数企业用例的首选**。它在处理敏感数据或需要访问频繁更新的信息时特别有用。根据 Apache Airflow 和 Superset 的创建者 Maxime Beauchemin 在 2024 年的一次采访,RAG 在实现商业智能工具中的 AI 驱动功能方面已被证明是有效的。
另一方面,**微调在高度专业化的任务中或旨在获得更小、更高效的模型时表现出色**。它在处理需要深入理解特定术语或上下文的利基领域时特别有效。然而,重要的是要注意,微调需要更多资源,并可能导致某些通用能力的丧失。
RAG 和微调的实际应用示例
让我们探讨一些具体示例来说明 RAG 和微调的应用
RAG 示例:财务顾问聊天机器人。设想一个旨在提供个性化财务建议的聊天机器人。利用 RAG,聊天机器人可以访问包含最新市场数据、个人客户投资组合和财务法规的数据库。当用户询问“我现在最好的投资策略是什么?”时,聊天机器人会检索有关用户财务状况、当前市场趋势和适用法规的相关信息。然后,它利用这些上下文生成量身定制的响应。
微调示例:医疗诊断助手。考虑一个在医疗报告和诊断数据集上进行微调的 LLM。该模型专门用于理解医学术语并根据症状识别潜在诊断。当医生输入患者的症状时,经过微调的模型可以根据其在医学领域的专业训练建议可能的诊断并推荐进一步的检查。
混合方法:法律文件分析器。在某些情况下,RAG 和微调的组合可能会有益。对于法律文件分析器,基础模型可以在法律术语和文档结构上进行微调。然后,RAG 可用于从不断更新的数据库中检索相关的判例法和法规。这种方法将微调的专业理解与 RAG 的最新信息访问相结合。
数据管道的作用
无论选择 RAG 还是微调,**健壮的数据管道的开发都至关重要**。这些管道确保模型获得高质量、相关的数据。但这些管道到底包含什么?
对于 RAG,数据管道通常涉及**向量数据库、嵌入向量和语义层**的开发。这些组件协同工作,以高效地检索和处理 LLM 的相关信息。这些管道的复杂性凸显了拥有强大数据基础设施的重要性。
在微调的情况下,数据管道侧重于**准备和处理用于训练的专门数据集**。这涉及数据清洗、标记和扩充等任务。该数据集的质量直接影响微调模型的性能,强调了数据准备在微调过程中的关键作用。大型语言模型 (LLM) 彻底改变了自然语言处理,但通过专门的技术可以进一步增强其有效性。本文探讨了两种此类方法:**检索增强生成 (RAG) 和微调**。通过理解这些方法,数据科学家和 AI 从业者可以就是否针对其特定用例采用哪种技术做出明智的决定。
引言
人工智能世界正在迅速发展,LLM 处于这场变革的最前沿。随着这些模型变得越来越复杂,**对根据特定任务或领域定制模型的技术的需求也随之增长**。RAG 和微调已成为实现这一目标的两种主要方法。这些技术到底是什么,它们又有什么区别?本文旨在揭示 RAG 和微调的神秘面纱,全面概述其机制、优势和理想用例。
什么是检索增强生成 (RAG)?
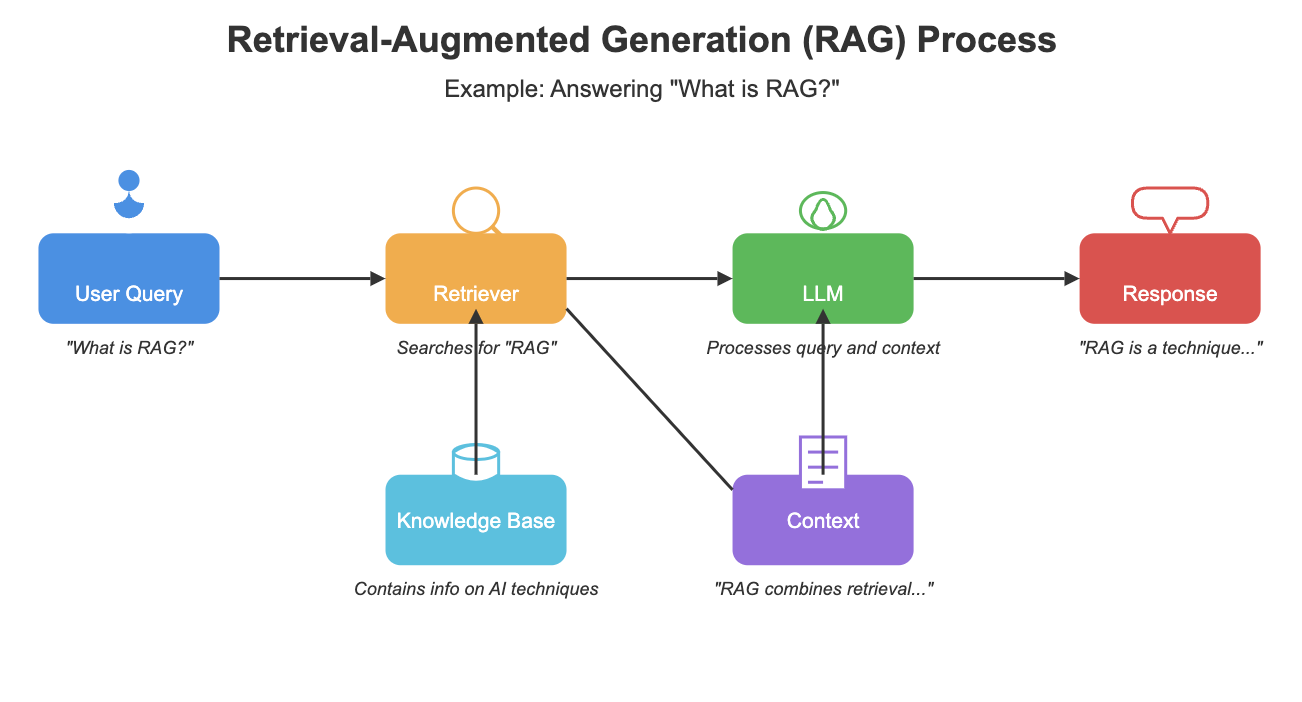
**检索增强生成(RAG),由 Meta 于 2020 年推出,是一种将 LLM 连接到精选的动态数据库的架构框架**。这种连接允许模型访问最新且可靠的信息并将其纳入其响应中。但这个过程到底是如何运作的呢?
当用户提交查询时,RAG 系统首先在其数据库中搜索相关信息。然后,检索到的数据与原始查询结合,并输入到 LLM 中。最后,**模型利用其预训练知识和检索到的信息提供的上下文生成响应**。这种方法使 LLM 能够生成更准确、更符合上下文的输出。
RAG 的主要优势之一是它能够增强安全性和数据隐私。与其他可能暴露敏感信息的方法不同,**RAG 将专有数据保留在安全的数据库环境中,从而实现严格的访问控制**。这一特性使得 RAG 对处理机密信息的企业特别有吸引力。
微调的力量
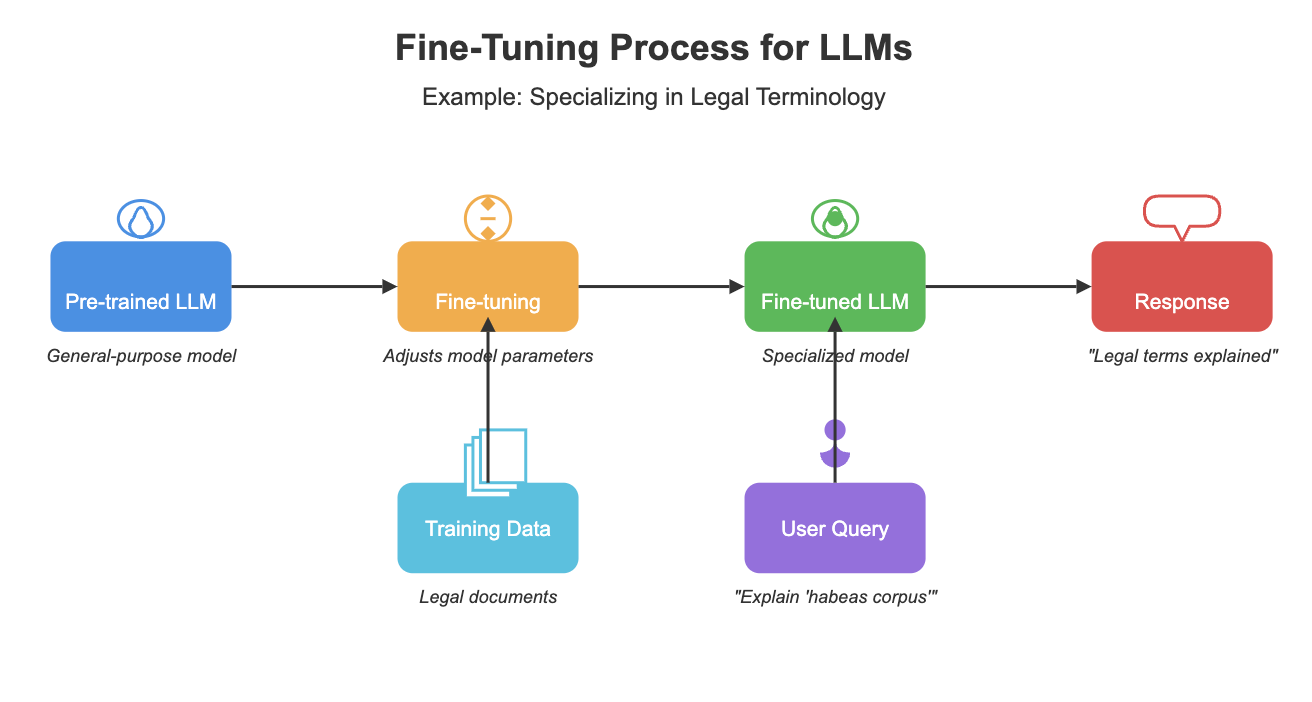
**微调涉及在较小、专门的数据集上训练 LLM,以调整其参数以适应特定任务或领域**。这个过程允许模型在处理特定类型的查询或生成领域特定内容方面变得更加熟练。但是,是什么让微调如此有效呢?
通过使模型与利基领域的细微差别和术语保持一致,**微调显著提高了模型在特定任务上的性能**。例如,Snorkel AI 的一项研究表明,一个经过微调的模型达到了与 GPT-3 模型相同的质量,同时体积小 1,400 倍,并且需要的真实标签不到 1%。
然而,微调并非没有挑战。**它需要大量的计算资源和高质量的带标签数据集**。此外,经过微调的模型可能会随着它们的专业化而失去一些通用能力。在决定是否采用微调时,必须仔细考虑这些因素。
选择正确的方法
从业者如何决定是为特定用例使用 RAG 还是微调?该决定通常取决于各种因素,包括**安全要求、可用资源以及手头任务的特异性**。



