Mergoo:高效构建您自己的 MoE LLM







Leeroo 团队:Majid Yazdani、Alireza Mohammadshahi、Arshad Shaikh
我们最近开发了 mergoo,一个用于轻松合并多个 LLM 专家并高效训练合并后 LLM 的库。现在,您可以高效地整合不同通用或领域 LLM 专家的知识。
🚀 在 mergoo 中,您可以
- 轻松合并多个开源 LLM
- 应用多种合并方法:专家混合、适配器混合和逐层合并
- 高效训练 MoE 无需从头开始
- 兼容 Hugging Face 🤗 模型和训练器

内容
引言
mergoo 旨在构建一个可靠且透明的管道,用于合并各种 LLM 专家(无论是通用型还是领域特定型)的知识。它整合了一系列集成技术,如专家混合、适配器混合和逐层合并,为 LLM 构建者提供了灵活性。一旦合并的 LLM 构建完成,您可以使用 Hugging Face 🤗 训练器(如 SFTrainer、PEFT、Trainer 等)对其进行进一步微调,以适应您的特定用例。
在以下部分,我们将概述两个示例,演示如何使用 MoE 从完全微调的 LLM 构建合并的 LLM,以及如何从 LoRA 微调的专家创建适配器混合 LLM。
完全微调 LLM 的混合
遵循 Branch-Train-Mix,可以通过将领域特定 LLM 专家的前馈参数作为专家汇集到专家混合(MoE)层中,并平均其余参数来集成这些专家。MoE 层可以稍后进行微调以学习词元级路由。
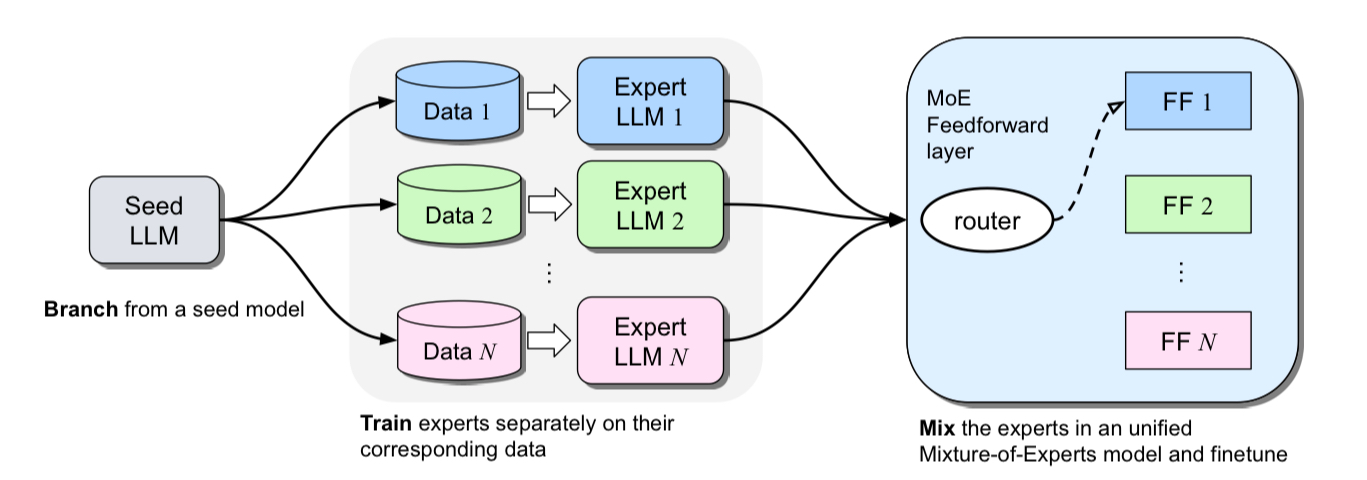
作为示例,我们集成了以下领域特定 LLM 专家
- 基础模型:meta-llama/Llama-2-7b-hf
- 代码专家:codellama/CodeLlama-7b-Python-hf
- WikiChat 专家:stanford-oval/Llama-2-7b-WikiChat-fused
指定合并配置
config = \
{
"model_type": "llama",
"num_experts_per_tok": 2,
"experts":[
{
"expert_name" : "base_expert",
"model_id" : "meta-llama/Llama-2-7b-hf"
},
{
"expert_name" : "expert_1",
"model_id" : "codellama/CodeLlama-7b-Python-hf"
},
{
"expert_name" : "expert_2",
"model_id" : "stanford-oval/Llama-2-7b-WikiChat-fused"
}
],
"router_layers":[
"gate_proj",
"up_proj",
"down_proj"
],
}
然后,构建合并后的专家检查点,并保存它
import torch
from mergoo.compose_experts import ComposeExperts
model_id = "mergoo_llama_code_wikichat"
expertmerger = ComposeExperts(config, torch_dtype=torch.float16)
expertmerger.compose()
expertmerger.save_checkpoint(model_id)
接下来,加载合并后 LLM 的检查点,然后在 Python Code Instruction 数据集上进一步微调
from mergoo.models.modeling_llama import LlamaForCausalLM
import torch
import datasets
import random
from trl import SFTTrainer
from transformers import TrainingArguments
# load the composed checkkpoint
model = LlamaForCausalLM.from_pretrained(
"mergoo_llama_code_wikichat",
device_map="auto",
torch_dtype=torch.bfloat16,
)# 'gate' / router layers are untrained hence loaded warning would appeare for them
# load the train dataset
dataset = datasets.load_dataset("iamtarun/python_code_instructions_18k_alpaca")['train']
dataset = dataset['prompt']
random.shuffle(dataset)
train_dataset = datasets.Dataset.from_dict(dict(prompt=dataset[:-1000]))
eval_dataset = datasets.Dataset.from_dict(dict(prompt=dataset[-1000:]))
# specify training arguments
trainer_args = TrainingArguments(
output_dir= "checkpoints/llama_moe",
per_device_train_batch_size = 1,
per_device_eval_batch_size = 1,
learning_rate= 1e-5,
save_total_limit=1,
num_train_epochs=1,
eval_steps= 5000,
logging_strategy="steps",
logging_steps= 25,
gradient_accumulation_steps=4,
bf16=True
)
trainer = SFTTrainer(
model,
args= trainer_args,
train_dataset= train_dataset,
eval_dataset= eval_dataset,
dataset_text_field="prompt",
)
# start training
trainer.train()
然后您可以将代码推送到 Huggingface Hub(请务必这样做!)
model.push_to_hub("mergoo_llama_code_wikichat_trained")
mergoo 还支持基于 mistral、bert 和 phi3 的专家。
适配器混合
mergoo 促进了将多个适配器(LoRA)合并到统一的 MoE 风格架构中。这是通过在微调的 LoRA 上应用门控和路由层来实现的。
构建适配器混合 LLM 的步骤:
- 收集一组具有相同基础模型的微调适配器(LoRA)
- 应用 mergoo 创建 MoE 风格的合并专家
- 在您的下游任务上微调合并后的专家
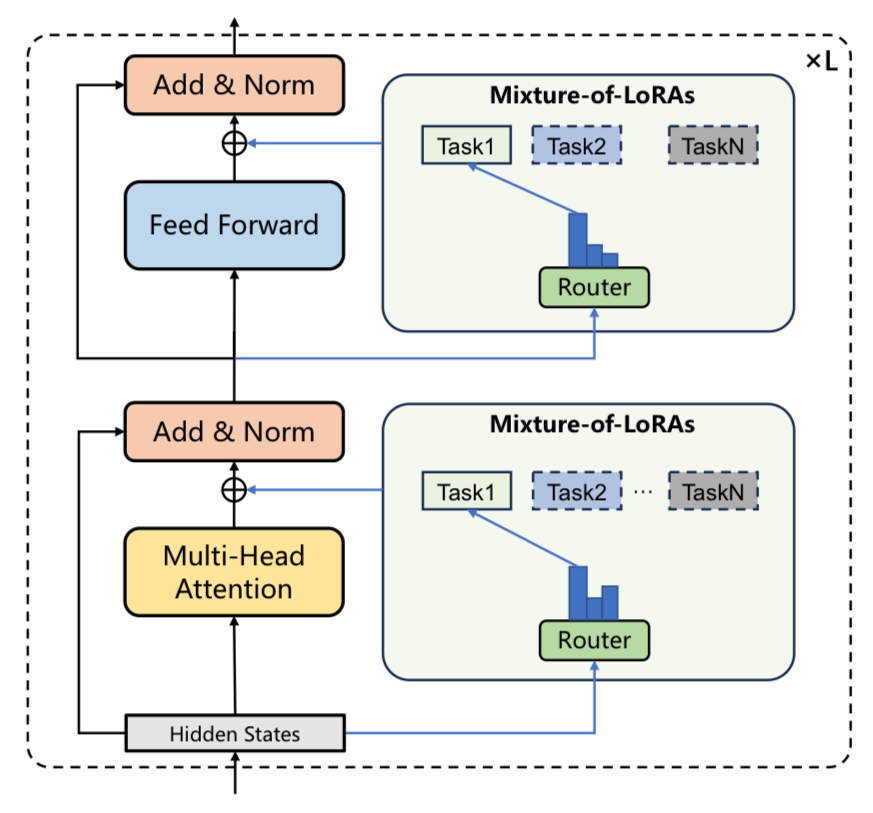
例如,以下专家可以为客户支持领域合并:
指定配置,然后构建合并后的检查点,如下所示
import torch
from mergoo.compose_experts import ComposeExperts
model_id = "mergoo_customer_suppoer_moe_lora"
config = {
"model_type": "mistral",
"num_experts_per_tok": 2,
"base_model": "mistralai/Mistral-7B-v0.1",
"experts": [
{
"expert_name": "adapter_1",
"model_id": "predibase/customer_support"
},
{
"expert_name": "adapter_2",
"model_id": "predibase/customer_support_accounts"
},
{
"expert_name": "adapter_3",
"model_id": "predibase/customer_support_orders"
}
],
}
expertmerger = ComposeExperts(config, torch_dtype=torch.bfloat16)
expertmerger.compose()
expertmerger.save_checkpoint(model_id)
注意:当合并的候选专家使用 LoRA 进行微调时,expert_name 以 adapter_ 开头。
您可以按照 完全微调 LLM 的混合 部分的定义,进一步微调合并后的专家。
结论
mergoo 可以可靠、透明地整合多个专家的知识。它支持多种集成技术,包括专家混合、适配器混合(MoE-LoRA)和逐层合并。合并后的 LLM 可以进一步在下游任务上进行微调,以提供可靠的专家。
了解更多
🔍 欲深入了解 mergoo,请查看我们的仓库。
🌍 在 Leeroo,我们的愿景是使人工智能普及到全球的每个人,而开源是实现这一愿景的基础性一步。加入 Leeroo,我们可以共同努力,将这一愿景变为现实!
领英、Discord、X、网站。





