自动化负责任AI:整合Hugging Face与LangTest以构建更稳健的模型

在不断发展的自然语言处理(NLP)领域,保持创新前沿不仅是一种愿望,更是一种必然。想象一下,你能够无缝集成 Hugging Face 模型中心的最先进模型,轻松利用各种数据集,严格测试你的模型,编写全面的报告,并最终提升你的 NLP 项目。这听起来可能像个梦想,但在这篇博文中,我们将揭示如何将这个梦想变为现实。
无论你是一位经验丰富的 NLP 从业者,寻求提升工作流程,还是一位渴望探索 NLP 前沿的新手,这篇博文都将成为你的指南。加入我们,深入探讨这种协同作用的各个方面,揭示提升你的 NLP 项目到前所未有卓越水平的秘密。
在这篇博客中,我们将探讨 Hugging Face(你获取最先进 NLP 模型和数据集的首选来源)与 LangTest(你 NLP 流水线的测试和优化秘密武器)之间的集成。我们的任务明确:赋予你所需的知识和工具,将你的 NLP 项目提升到新的高度。在整个博客中,我们将深入探讨这种强大集成的各个方面,从利用 Hugging Face 的模型中心和数据集到使用 LangTest 进行严格的模型测试。因此,请为一场通往 NLP 卓越的丰富旅程做好准备,在那里,创新的界限是无限的。
LangTest 库
LangTest 是一个多功能且全面的工具,可与各种 NLP 资源和库无缝集成。通过支持 JohnSnowLabs、Hugging Face 和 spaCy,LangTest 为用户提供了使用其首选 NLP 框架的灵活性,使其成为各个领域的从业者不可或缺的资产。此外,LangTest 的功能不仅限于框架,还提供了与 OpenAI 和 AI21 等众多 LLM 源的兼容性,使用户能够在其 NLP 流水线中利用各种语言模型的强大功能。这种多功能性确保了 LangTest 能够满足 NLP 专业人员的不同需求,使其成为他们追求 NLP 卓越的宝贵工具。

LangTest 无缝支持 Hugging Face 模型和数据集,简化了这些强大 NLP 资源的项目集成。无论您需要用于各种 NLP 任务的最先进模型,还是多样化、高质量的数据集,LangTest 都能简化流程。通过 LangTest,您可以快速访问、加载和微调 Hugging Face 模型,并轻松集成其数据集,确保您的 NLP 项目建立在创新和可靠性的坚实基础之上。
利用 Hugging Face 模型中心
Hugging Face 模型中心是机器学习领域最大的集合之一,拥有令人印象深刻的预训练 NLP 模型阵列。无论您是从事文本分类、命名实体识别、情感分析还是任何其他 NLP 任务,Hub 中都有一个模型在等着您。Hub 汇集了 NLP 社区的集体智慧,使您可以轻松发现、共享和微调模型以满足您的特定需求。
您只需一行代码即可在 LangTest 中加载和测试 Hugging Face 模型中心上任何支持任务的模型。只需将 hub 指定为“huggingface”并给出模型名称,即可开始!
from langtest import Harness
harness = Harness(
task="text-classification",
model={
"model": "charlieoneill/distilbert-base-uncased-finetuned-tweet_eval-offensive",
"hub": "huggingface"
}
)
在 LangTest 中使用 Hugging Face 数据集

获取高质量和多样化的数据集与拥有正确的模型同样重要。幸运的是,Hugging Face 生态系统不仅仅提供预训练模型,还提供了丰富的精选数据集,以丰富您的 NLP 项目。在本节中,我们将探讨如何将 Hugging Face 数据集无缝集成到 LangTest 中,为您的 NLP 工作创建一个动态且数据丰富的环境。
1. Hugging Face 数据集的优势:
深入探索 Hugging Face 数据集的世界,您将发现一个庞大的数据集集合,涵盖多种语言和领域。这些数据集经过精心整理和格式化,可轻松集成到您的 NLP 工作流中。
2. 使用 LangTest 进行数据准备:
虽然访问数据集至关重要,但了解如何有效准备和使用它们同样重要。LangTest 通过提供无缝数据加载功能来解决这个问题。您可以通过在一行代码中指定几个参数来将任何数据集集成到您的工作流中。这些参数是:
“source”与 hub 参数类似,用于设置数据来源。
“data_source”是数据集的名称或路径。
“split”、“subset”、“feature_column”和“target_column”可以根据您的数据进行设置,LangTest 数据处理器将为您加载数据。
from langtest import Harness
harness = Harness( task="text-classification", model={ "model": "charlieoneill/distilbert-base-uncased-finetuned-tweet_eval-offensive", "hub": "huggingface" }, data={ "source":"huggingface", "data_source":"tweet_eval", "feature_column":"text", "target_column":"label", } )
使用 LangTest 进行模型测试
这不仅仅是选择合适的模型和数据集;它还涉及对模型进行严格的测试和微调,以确保它们表现最佳。我们旅程的这一部分将带我们深入 LangTest 的核心,在这里我们将探索模型测试和验证的关键步骤。
LangTest 允许您在许多类别中进行测试,例如*准确性*、*稳健性*和*偏差*。您可以在此处查看测试列表并详细检查它们。您还可以从我们的教程笔记本中查看这些测试的示例。在这篇博客中,我们将重点关注稳健性测试,并将尝试通过在 LangTest 增强数据集上重新训练来改进我们的模型。
测试准备
您可以查阅 LangTest 文档或教程以获取详细的配置视图。我们使用来自 HF 模型中心的“lvwerra/distilbert-imdb”模型和来自 HF 数据集的“imdb”数据集。我们将继续对该模型进行稳健性测试。
from langtest import Harness
harness = Harness(
task = "text-classification",
model={"model":'lvwerra/distilbert-imdb', "hub":"huggingface"},
data={
"source": "huggingface",
"data_source": "imdb",
"split":"test[:100]"
},
config={
"tests": {
"defaults": {"min_pass_rate": 1.0},
"accuracy": {"min_micro_f1_score": {"min_score": 0.7}},
'robustness': {
'titlecase':{'min_pass_rate': 0.60},
'strip_all_punctuation':{'min_pass_rate': 0.96},
'add_typo':{'min_pass_rate': 0.96},
'add_speech_to_text_typo':{'min_pass_rate': 0.96},
'adjective_antonym_swap':{'min_pass_rate': 0.96},
'dyslexia_word_swap':{'min_pass_rate': 0.96}
},
}
}
)
在创建具有所需测试和参数的 harness 对象后,我们即可运行测试。首先我们运行 .generate(),然后使用 .testcases() 查看结果。
harness.generate()
harness.testcases()
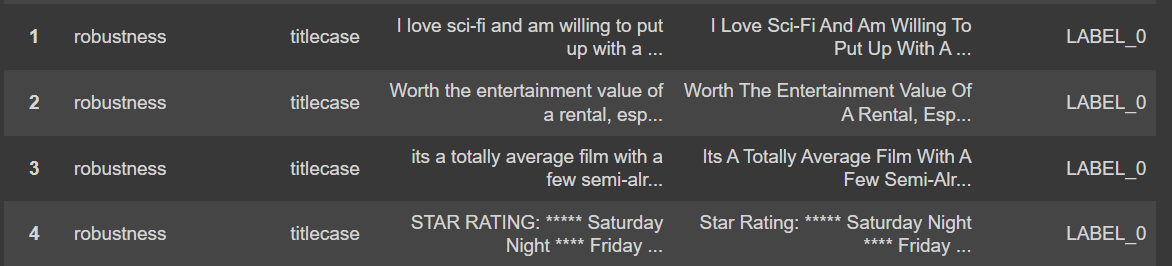
编写综合报告
我们将从剖析综合报告的关键组成部分开始。了解其结构和基本要素将使您能够明智地使用报告,同时增强模型或分析结果。我们可以使用 .report() 函数轻松创建不同格式的报告。在本博客中,我们将继续使用默认格式(pandas DataFrame)。
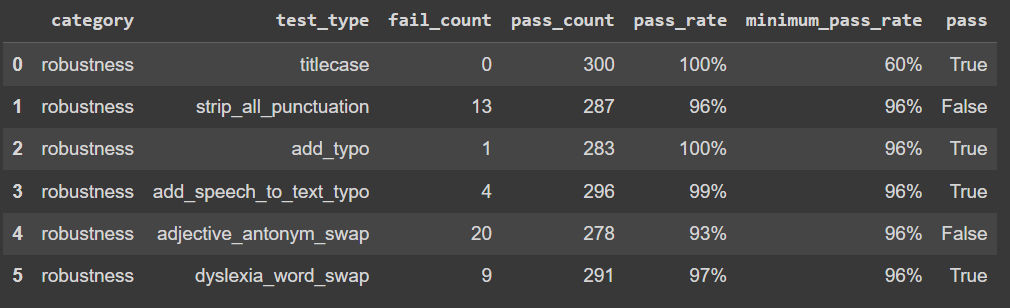
我们可以看到我们的模型在 adjective_antonym_swap 和 strip_all_punctuation 测试中失败,并且在其他测试中也得到了一些失败结果。LangTest 允许您使用测试结果自动创建增强训练集。它根据测试结果按比例扰动给定数据集。
提升模型:测试洞察
在追求 NLP 卓越的道路上,测试模型只是一个开始。真正的魔力在于你利用这些测试洞察力来提升你的 NLP 模型。在我们旅程的这一部分,我们将探讨 LangTest 如何帮助你利用这些洞察力来增强你的模型,并突破 NLP 性能的界限。
创建增强微调数据集
LangTest 的增强功能使您能够生成富含扰动样本的数据集,这是改进和增强 NLP 模型的关键一步。此功能使您能够在训练数据中引入变化和多样性,最终生成更稳健、更强大的模型。借助 LangTest,您拥有了通过增强数据集和强化模型来应对各种实际挑战的工具,从而将您的 NLP 卓越水平提升到新的高度。
让我们看看如何仅用几行代码即可实现此功能
harness.augment(
training_data = {
"source": "huggingface",
"data_source": "imdb",
"split":"test[300:500]"
},
save_data_path = "augmented.csv",
export_mode = "transform"
)
使用增强数据集训练模型
当使用增强数据集训练模型时,一个宝贵的资源是 Hugging Face 关于微调预训练模型的指南。本指南将作为您的路线图,提供有效微调 transformer 模型的基本见解和技术。通过遵循此资源,您可以驾驭将预训练模型适应特定 NLP 任务的复杂过程,同时利用 LangTest 生成的增强数据集。LangTest 的数据增强能力与 Hugging Face 的微调指南之间的这种协同作用,为您提供了优化模型和实现 NLP 卓越所需的知识和工具:微调预训练模型。
我们不会深入探讨模型训练的细节,但您可以查看包含所有必要代码的完整笔记本,以遵循本博客的步骤。
笔记本.
评估增强模型的性能
使用增强数据和 Hugging Face 的微调指南对模型进行微调后,NLP 卓越之路的下一个关键步骤是评估模型的性能。在本节中,我们将探讨全面的技术和指标,以评估您的增强模型在各种 NLP 任务中的表现。我们将深入探讨准确率、精确率、召回率、F1 分数等领域,确保您全面了解模型的优势和需要改进的方面。在本节结束时,您将能够很好地衡量增强模型的真实影响,并就进一步的改进做出明智的决定,为实现卓越的 NLP 性能奠定基础。
