图像扩散在分形文本上




传统上,视觉模型和文本模型之间存在一道鸿沟——它们各自拥有自己的数据格式、训练任务和架构。
但是,如果文本数据可以视觉化表示,同时又不失其符号特性,从而实现文本生成的替代方法呢?
在本文中,我们将探讨如何将文本转换为有意义的视觉模式,以供图像扩散模型使用。
直觉
从计算机的角度来看,**文本**和**图像**都是字节序列。
这是Huggingface徽标的开头,采用HEX编码
xxd -ps huggingface.png | head -n2
# 89504e470d0a1a0a0000000d4948445200000200000002000806000000f4
# 78d4fa000000097048597300001d8700001d87018fe5f165000000197445
这是本网页的开头,它将显示在您的硬盘上
xxd -ps blog.html | head -n2
# 3c21444f43545950452068746d6c3e0a3c212d2d2073617665642066726f
# 6d2075726c3d28303035382968747470733a2f2f68756767696e67666163
除非您受过网络安全/取证方面的训练,否则很难分辨它们!
确实,“视觉”与“文本”的区别是以人为中心的。图像和文本是为了方便我们而封装计算机数据的构造。
当然,这些格式捕获了许多底层模式并加速了模型的训练。就像分词器是固定的但有效的语义理解捷径一样。
但我们创造了两个孤立的人工岛屿。
那么,让我们看看我们能否越过障碍。
"免责声明"
劫持图像模型以生成文本是一个出于好奇的小实验。我知道它对于严肃的项目来说是次优且不明智的。
然而,使用扩散架构生成文本正逐渐受到关注:Apple的Planner和Google的Gemini显示出令人鼓舞的结果,并挑战了自回归语言模型的现状。
目录
将文本编码为RGB数据
为了将视觉模型应用于文本数据,我们首先需要将字符进行视觉表示。
栅格化字体
通常,文本会根据您屏幕的分辨率进行栅格化。
但这种方法会将每个字符分解成许多像素,将离散符号简化为嘈杂的纹理

它将迫使模型从视觉碎片(像素)中恢复符号意义——本质上是学习阅读。
自定义RGB编码
相反,让我们尝试将每个字符表示为单个像素,以保留其身份,同时实现空间处理。
通常,文本以 Unicode 格式表示,长度为 32 位或 4 字节。
此空间仅分配了很小一部分,并且最高有效字节始终为零
np.array(list('Hilbert'.encode('utf-32-be'))).reshape((-1, 4))
# array([[ 0, 0, 0, 72],
# [ 0, 0, 0, 105],
# [ 0, 0, 0, 108],
# [ 0, 0, 0, 98],
# [ 0, 0, 0, 101],
# [ 0, 0, 0, 114],
# [ 0, 0, 0, 116]])
这意味着任何字符都可以用3个字节表示,就像颜色的RGB分量一样

在上图中,每个字符都由一个像素表示,其颜色为其 UTF 编码的颜色。结果大部分是蓝色,因为所有 ASCII 字符的红色和绿色通道都为 null。
Unicode 表中更靠后的字符,例如东亚文字(CJK 字符),覆盖了更广的颜色范围
np.array(list('ヒルベルト曲線'.encode('utf-32-be'))).reshape((-1, 4))
# array([[ 0, 0, 48, 210],
# [ 0, 0, 48, 235],
# [ 0, 0, 48, 217],
# [ 0, 0, 48, 235],
# [ 0, 0, 48, 200],
# [ 0, 0, 102, 242],
# [ 0, 0, 125, 218]])

仔细观察,这些颜色有明确的含义
- 标点符号几乎是黑色的,因为相关的代码点接近于0
- 字母表有不同的颜色,字母之间的变化更细微
- 大写字母的颜色更深,因为它们在UTF表中位于小写字母之前
混合通道
不过,颜色偏向蓝色,这对于视觉模型来说可能不寻常。
为了获得更平衡的颜色分布,可以采用不同的通道组合方式
__utf = np.array(list('Hilbert'.encode('utf-32-be'))).reshape((-1, 4))
np.stack([
__utf[..., 1] + __utf[..., -1],
__utf[..., 2] + __utf[..., -1],
__utf[..., -1]
], axis=-1) % 256
# array([[ 72, 72, 72],
# [105, 105, 105],
# [108, 108, 108],
# [ 98, 98, 98],
# [101, 101, 101],
# [114, 114, 114],
# [116, 116, 116]])
此方案将西方字符映射到灰度颜色渐变。

它增加了对比度,但以四舍五入到256时的一些不连续性为代价。

虽然存在替代方案,但此方法提供了一种直接而有效的视觉编码。
本文的其余部分,文本将以字符和RGB像素两种形式显示。
2D文本塑形
为了执行常规图像扩散,文本数据必须在保留语义的同时重新塑形为2D。
理想情况:ASCII 艺术
ASCII艺术是文本最接近图形渲染的方式

每个字符只用一个像素表示会失去字形本身的形状,但整体场景仍然可见。
就像常规文本一样,模型可以学习潜在的“意义”和字符的相关关联。
常规页面布局
常规文本更棘手,因为LLMs将其视为一维数组。
尽管我们以线性模式阅读,文本仍以2D形式写在诸如维基百科页面的载体上

为清晰起见,标签以叠加形式显示,但请记住,模型将只看到像素数据。
这种布局非常浪费,将近一半的区域被填充覆盖。
此外,高度轴上的注意力(红色部分)从一个句子跳到下一个句子,几乎没有捕捉到相关模式。
理想情况下,卷积核(黄色部分)处理的所有数据都应与其主要焦点相关。
固定大小分块
将文本分割成固定大小的块可以消除空白区域。

但是注意力模式仍然是断裂的,并且高度轴是不规则的。
沿希尔伯特曲线折叠
在空间中表示扁平数据的一种常见解决方案是将序列像线一样折叠起来

在上图中,颜色渐变表示顺序索引,以突出数据在空间中的布局方式。
上图所示的希尔伯特曲线以长度为4096的线覆盖了整个64 x 64的正方形。
这种布局特别有趣,因为它在两个轴上都保留了局部性。您可以看到不同尺度的正方形捕获了n-gram、句子和章节
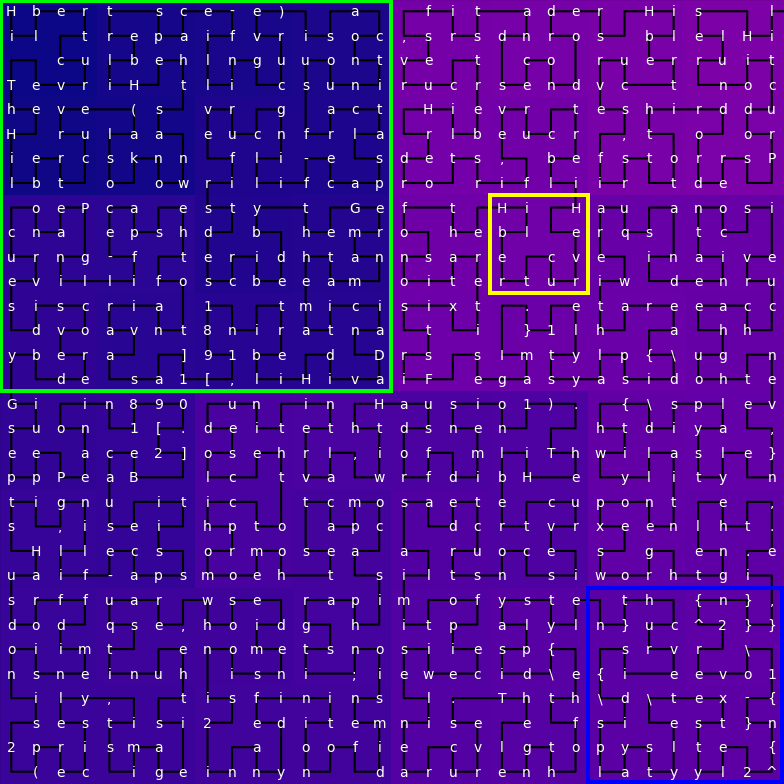
现在,不再是粗暴的一维注意力,而是可以在这种文本的视觉表示上运行卷积层。
与滑动窗口注意力类似,感受野随着层深度的增加而增长。卷积从处理单词开始,然后是句子,然后是章节等。
替代空间填充曲线
除了在曲线的每个位置放置单个字符外,还可以放置整个连续块。
这种混合布局不那么复杂,并且可以在局部性和可解释性之间取得平衡。
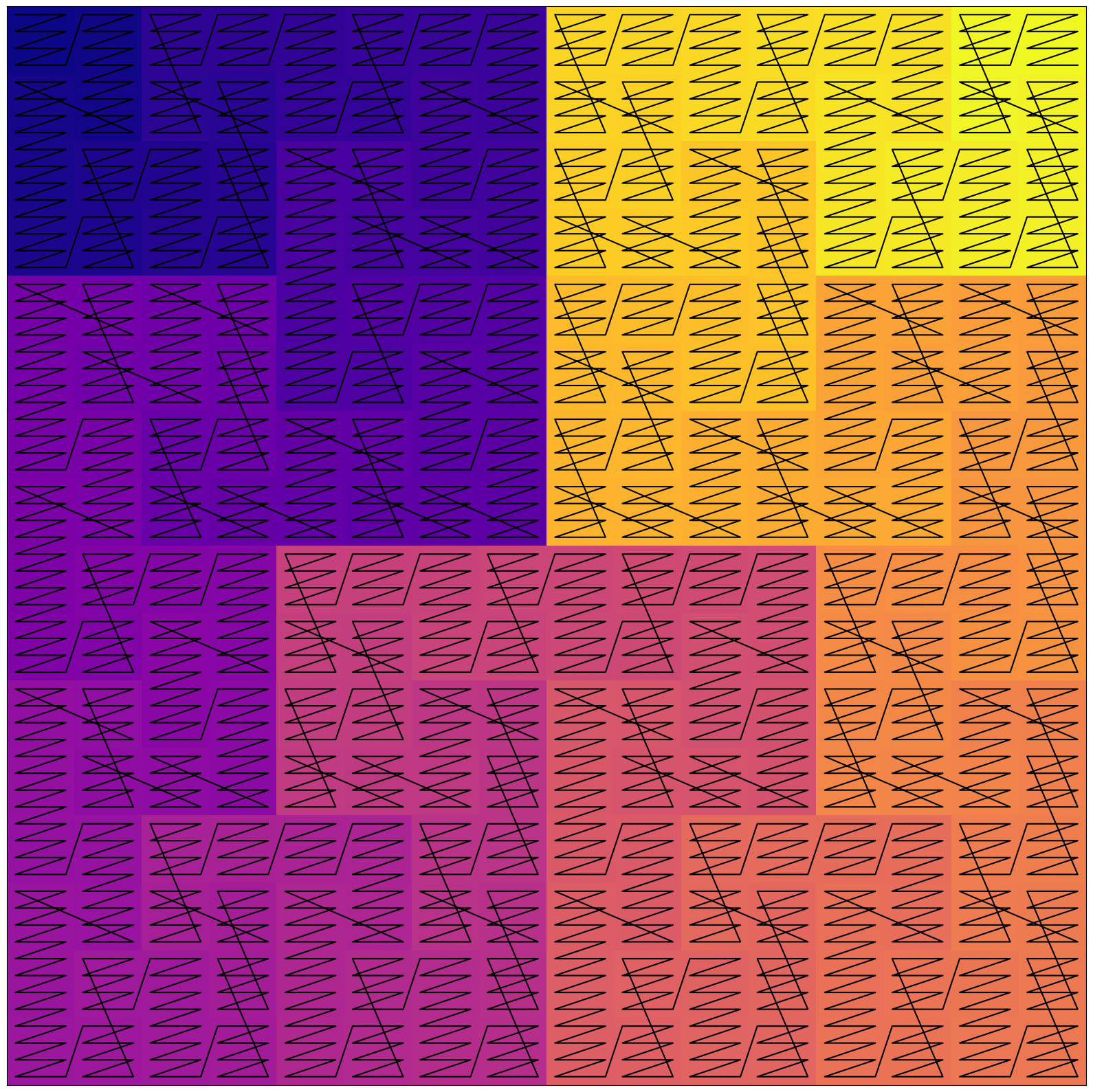
事实上,希尔伯特曲线是空间填充曲线的一个例子。这些曲线在许多领域用于在1D和2D空间之间进行映射
- 可视化基因组数据
- 用索引对数据库排序
- 跟踪物体以渲染纹理
- 映射IP地址空间
- 等等
尽管希尔伯特曲线在保留局部性方面表现更好,但其他曲线可能更容易被神经网络学习。更简单的Z序曲线看起来是一个不错的选择

不过,从斜线可以看出,曲线有不连续的跳跃:在每个尺度上,一个 Z 的末尾与下一个 Z 的开头不连接。
因此,在 1D 中靠近的两个点有时会在 2D 中被拉开。
扩展到更高维度
2D布局在概念说明方面很实用,但希尔伯特曲线可以推广到任意阶数。
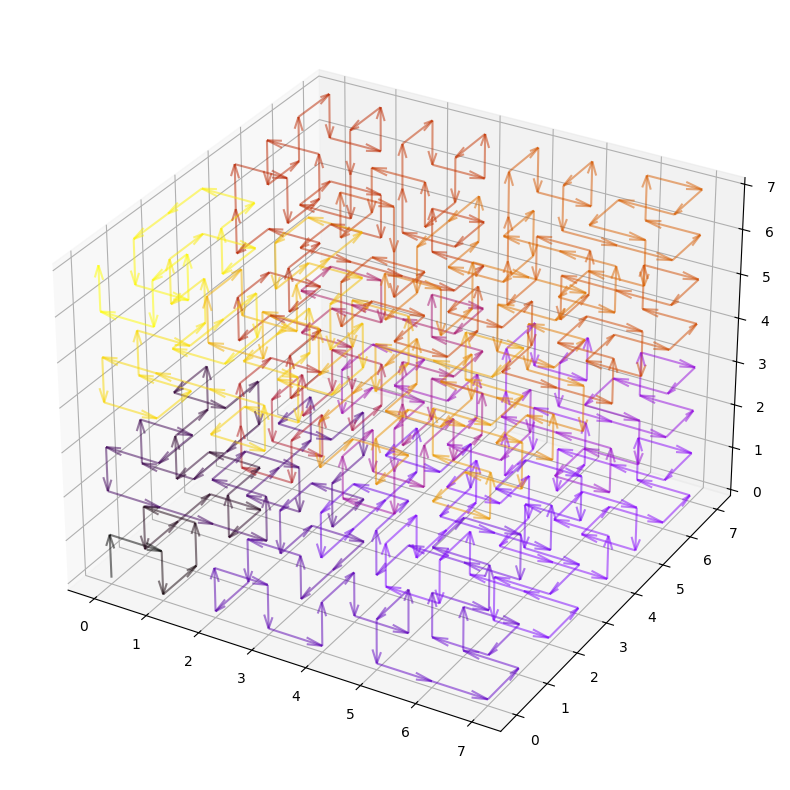
这允许将整个维基百科文章编码为一个$16^3$形状的立方体

在Minecraft中,这也被称为sculk方块!
虽然这与直接使用预训练图像扩散模型无关,但它可能对自定义文本扩散模型很有趣。
此外,此方案可以与额外的轴一起使用,以处理令牌级数据而不是纯字符。在2阶曲线的每个位置将字符分组为4个一组,可以得到令牌级编码。

由于实际使用的代码点很少,这种编码很可能被自编码器压缩。考虑到量化自编码器,`4 * 3`个通道可能会减少到只有`3`个。
三个(RGB)深度为256的通道将允许编码16,777,216个不同的令牌,这在2025年的标准下绰绰有余。
进一步推广
既然文本数据已按图像数据的方式准备好,就可以直接将其输入扩散模型。
对文本使用扩散功能将意味着什么?
文本放大
就像图像一样,ASCII 艺术也可以放大。
| 缩小 | 放大 |
|---|---|
 |
 |
这个概念也可以转移到常规文本上,甚至是在扁平序列上。
文本放大可以用来以不同的方式生成本文
- 补全:填充文章中缺失的部分
- 外画:从文章的特定部分生成其余部分
- 超分辨率:将草稿细化成一篇完整的文章
这些操作中的每一个都可以系统化为文本的训练任务。
文本缩小
图像较少见,但反向操作对于文本处理可能很有趣。
缩小将产生文章的摘要或分段,就像目录一样。
分形图案
有趣的是,缩放可以无限进行,它会生成分形图案。
下面是维基百科文章2D表示中“维度”概念的放大图
| 文本 | RGB |
|---|---|
 |
 |
它并不精确,但整体形状无限重复。这并非由于希尔伯特布局,在一维情况下也是如此。
事实上,文本本质上是自相似和递归的
- 单词由其他单词的集合定义
- 链接可以无限扩展成完整的网页
- 论文中的参考文献可以扩展成完整的论文
- 在Linux文件系统中,一切皆文件
- 文件树可以递归地展开和折叠
- 在代码中,有一个非常结构化的层次结构
- 抽象语法树可以递归地展开和折叠
一个给定的提示可以一步步地概括或扩展,就像一个多步CoT一样。
除了仅仅训练下一个标记外,底层结构可以被解析成多个任务。
例如,网页、网站和网站网络都具有逻辑信息分区。在不同尺度上进行训练将是完善当前训练任务的一种途径,而不一定需要收集更多数据。
其他应用
许多图像模型的能力都有直接的文本等效项
- 去噪:纠正语法、句法、拼写,改进文风
- 分段:结构化和总结长篇文档
- 风格转换:改写,改变语气
此外,图像生成领域的文献也暗示了潜在的好处,例如:
- 卷积层的感受野增长更快
- 卷积中上下文随深度平方增长
- 而滑动窗口则是线性增长
- 扩散模型的输出更加连贯
- “第一个”标记不会限制后续标记的可用路径
- 输出更流畅,多样性更高
- 采样和训练过程之间的差距正在缩小
- Min-SNR区分去噪阶段并细化采样步骤
- DREAM使训练和采样的去噪算法保持一致
下一步
这些实验表明,多模态已经植根于输入数据本身。
而且,文本生成很可能受益于图像生成的技术。
我们将在后续文章中探讨将图像模型应用于RGB文本并进行微调时实际发生的情况。
资源
- ASCII艺术数据集
- ASCII图像数据集
- 希尔伯特曲线维基百科文章
