简化机器学习工作流:集成 MLFlow Tracking 与 LangTest 以增强模型评估



机器学习 (ML) 近年来呈指数级增长。随着开发的模型数量不断增加,对这些模型进行透明、系统、全面的跟踪的需求也日益增长。MLFlow 和 LangTest 应运而生:这两个工具结合在一起,为机器学习开发带来了革命性的方法。
MLFlow 旨在简化机器学习生命周期,管理从实验、可复现性到部署的一切。通过提供一个有组织的日志和版本控制框架,MLFlow Tracking 帮助团队确保其模型的开发和部署具有透明度和精确性。
另一方面,**LangTest** 已成为自然语言处理 (NLP) 和大型语言模型 (LLM) 评估领域的变革力量。LangTest 是一个开源 Python 工具包,致力于严格评估 AI 模型的多方面特性,尤其是在它们与实际应用结合时,为该领域的进步开辟了道路。该工具包揭示了模型的鲁棒性、偏见、准确性、毒性、公平性、效率、临床相关性、安全性、虚假信息、政治偏见等。该库的核心重点是深度、自动化和适应性,确保任何集成到实际场景中的系统都无可挑剔。
LangTest 的独特之处在于其测试方法
- **智能测试用例生成**:它不依赖于固定的基准,而是为每个模型和数据集定制评估场景。这种方法捕捉了模型行为的细微差别,确保了更准确的评估。

2. **全面的测试范围**:LangTest 拥有大量的测试,从鲁棒性检查和偏见评估到毒性分析和效率测试,确保模型既准确又符合道德规范。

3. **自动化数据增强**:除了单纯的评估,LangTest 还采用数据增强技术,主动增强模型训练,动态响应不断变化的数据环境。

4. **MLOps 集成**:LangTest 无缝集成到自动化 MLOps 工作流中,通过促进更新版本的自动化回归测试,确保模型随着时间的推移保持可靠性。

LangTest 已在 AI 社区引起轰动,展示了其在识别和解决重大负责任 AI 挑战方面的功效。凭借对众多语言模型提供商和大量测试的支持,它有望成为任何 AI 团队的宝贵资产。
为什么要将 MLFlow Tracking 与 LangTest 集成?

MLFlow 跟踪与 LangTest 在模型开发过程中的结合,彻底改变了我们处理机器学习的方式,使其更加透明、深入和高效。通过将 LangTest 的高级评估维度与 MLFlow 的跟踪功能无缝融合,我们创建了一个全面的框架,不仅根据准确性评估模型,还彻底记录每次运行的指标和见解。这种强大的协同作用使开发人员和研究人员能够发现历史趋势、做出明智的决策、比较模型变体、有效解决问题、鼓励协作、确保问责制并持续改进模型。这种集成促进了一种严谨的、数据驱动的方法,促进了更可靠、更公平、更优化的 AI 系统的创建,同时促进了与利益相关者的透明沟通。本质上,MLFlow 跟踪与 LangTest 的集成代表了一种超越传统界限的先进模型开发方法,最终交付了技术精湛且符合道德规范的模型。
MLFlow Tracking 和 LangTest 的集成类似于将强大的引擎 (MLFlow) 与先进的导航系统 (LangTest) 合并。这种协同作用实现了以下目标:
透明度:每次运行、每个指标和每个见解都将被记录。
效率:开发人员可以轻松发现历史趋势、排查问题并比较模型变体。
协作:透明的文档促进了更好的团队合作和知识共享。
问责制:每次更改、测试和结果都会被记录,以备将来参考。
简而言之,MLFlow 的高级跟踪与 LangTest 的评估指标完美结合,确保模型不仅准确,而且在道德和技术上都健全。
它是如何工作的?
以下代码提供了一种快速而简化的方法,使用 langtest 库评估命名实体识别模型。
- 安装:
!pip install langtest[transformers]
此行安装 **langtest** 库,并专门包含将其与 **transformers** 库一起使用所需的额外依赖项。Hugging Face 的 transformers 库提供了大量预训练模型,包括用于自然语言处理任务的模型。
导入和初始化
from langtest import Harness h = Harness(task='ner', model={"model":'dslim/bert-base-NER', "hub":'huggingface'})
首先,导入 langtest 库中的 Harness 类。然后,使用特定参数初始化 **Harness** 对象。**task** 参数设置为 **ner**,表示目标是命名实体识别 (NER)。**model** 参数指定要使用的模型,**dslim/bert-base-NER** 是从 Hugging Face 的模型中心选择的预训练模型。
- 测试生成和执行
h.generate().run()
Harness对象的 **generate**() 方法创建一组适用于 NER 任务和所选模型的测试用例。然后,**run**() 方法执行这些测试用例,评估模型在其上的性能。
通过 **mlflow_tracking=True** 标志,MLFlow 的跟踪功能随即启动。这就像:
h.report(mlflow_tracking=True)
!mlflow ui

幕后发生了什么?
**启动**:在报告方法中设置 **mlflow_tracking=True** 会将您带到本地托管的 MLFlow 跟踪服务器。
**表示**:每次模型运行都被描述为该服务器上的一个“实验”。每个实验都以模型名称唯一命名,并带有日期和时间戳。
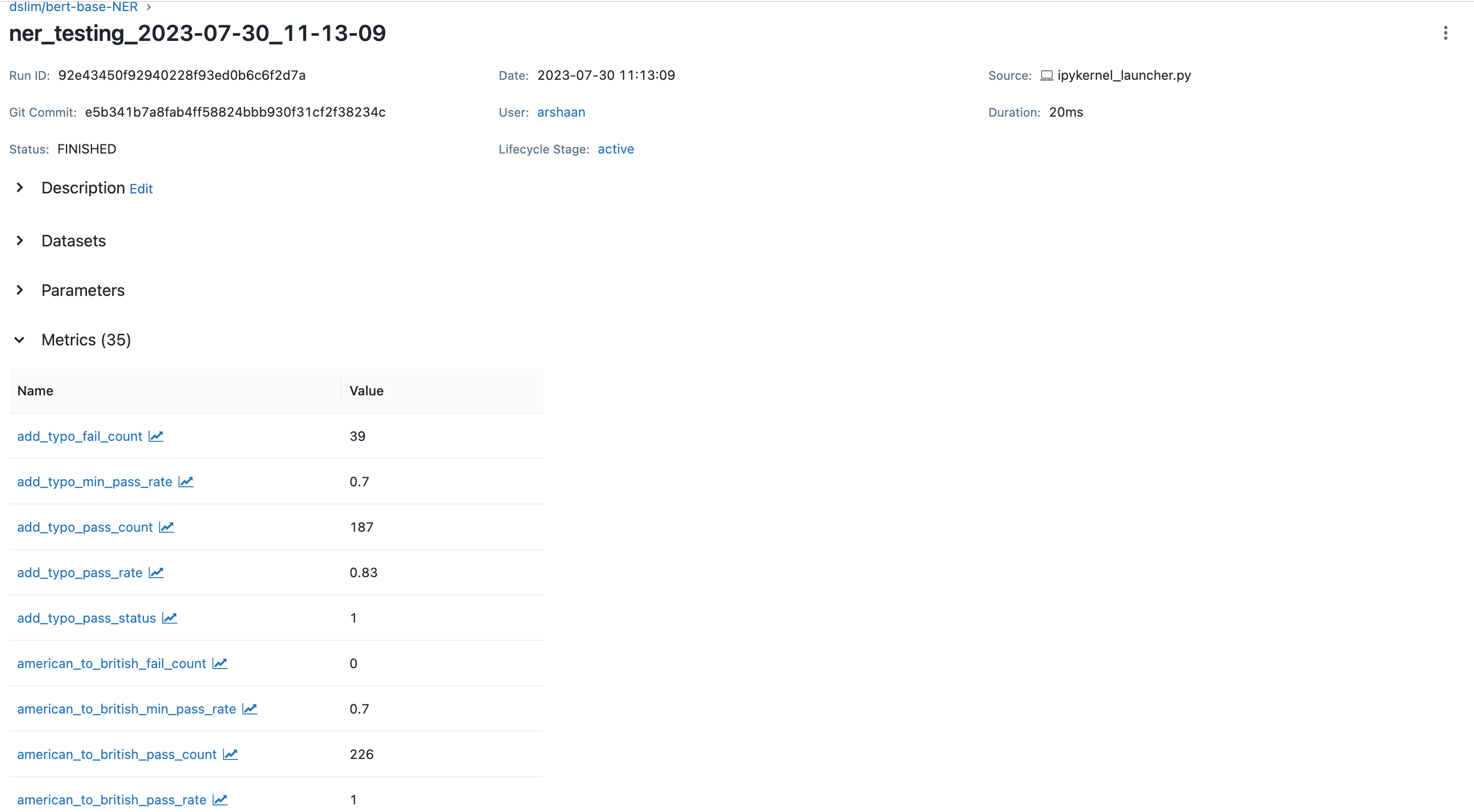
**详细日志**:想深入了解特定运行的指标?只需选择其名称。然后,您将进入一个详细的指标部分,其中包含所有相关数据。
**历史数据**:如果您重新运行模型(使用相同或不同的配置),MLFlow 会将其单独记录。这样,您就可以获得每次独特运行的模型行为快照。
**比较**:使用“比较”部分,可以轻松比较不同运行。
如果您想查看特定运行的指标和日志,只需选择关联的运行名称即可。这将引导您到指标部分,其中存储了该运行的所有日志详细信息。该系统提供了一种有组织、流线化的方式来跟踪每个模型在不同运行期间的性能。
跟踪服务器看起来是这样的,实验和运行名称指定如下:
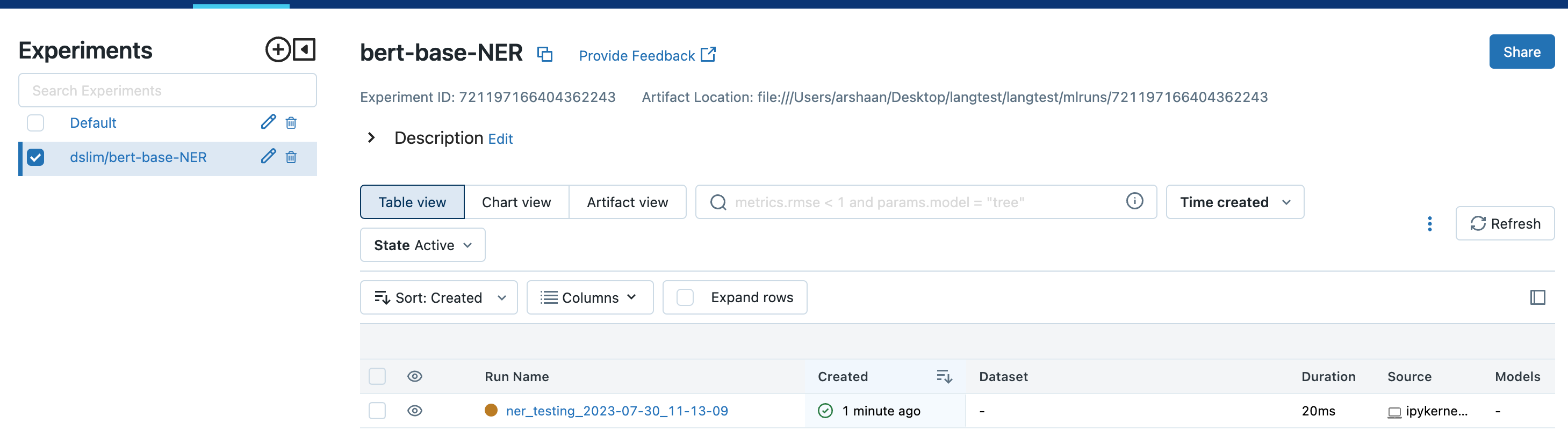
要检查指标,选择运行名称并转到指标部分。
如果您决定再次运行相同的模型,无论使用相同还是不同的测试配置,MLflow 都将将其记录为跟踪系统中的一个独立条目。
这些条目中的每一个都捕获了模型在运行时的特定状态,包括所选参数、模型的性能指标等等。这意味着,对于每次运行,您都可以获得模型在特定条件下的行为的全面快照。
然后,您可以使用比较部分对不同运行进行详细比较。
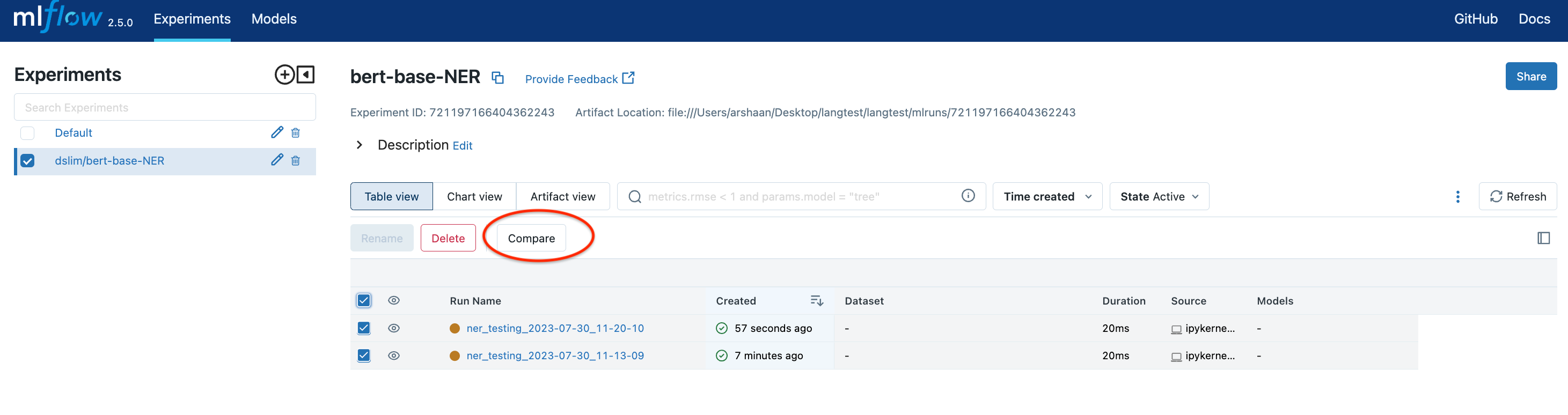
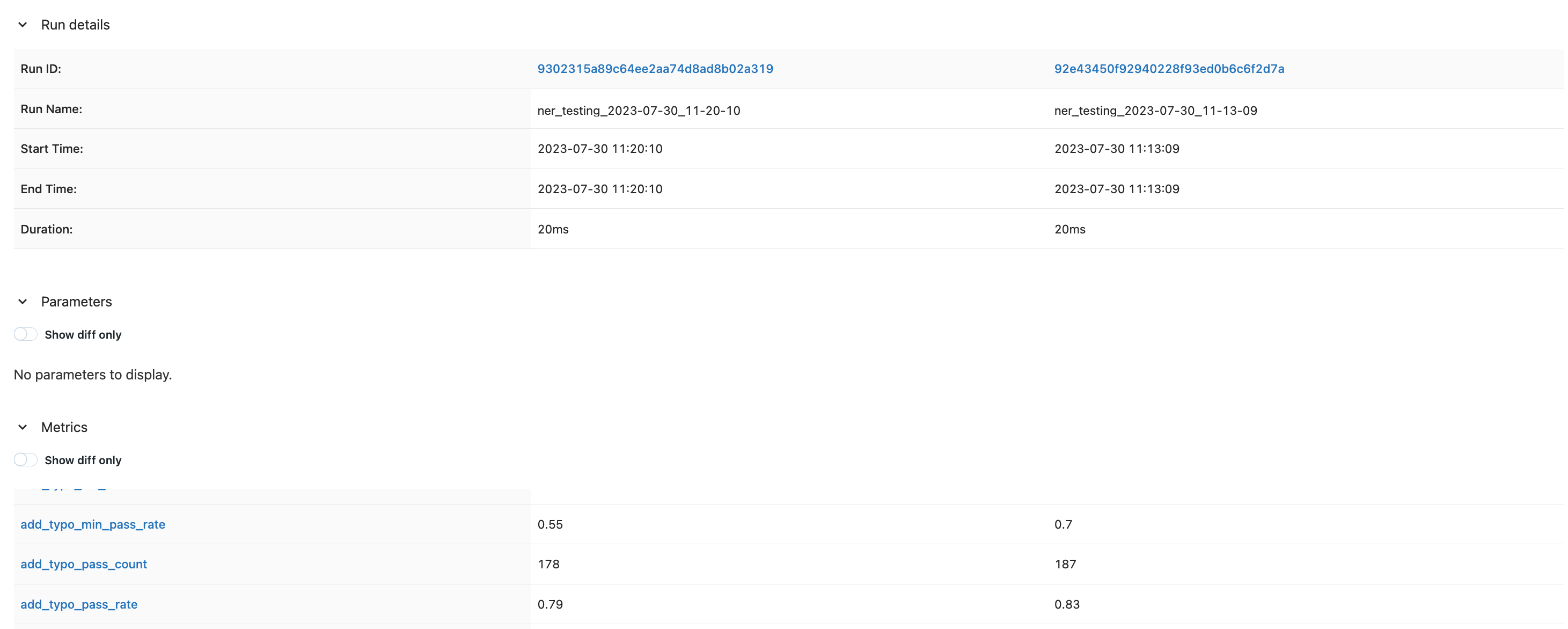
因此,MLflow 充当您的跟踪系统,记录每次运行的详细信息,并为模型的发展和性能提供历史背景。此功能对于在改进机器学习模型时保持严谨的数据驱动方法至关重要。
总结
MLFlow Tracking 和 LangTest 的结合提升了传统的模型开发过程,使其更加严谨、数据驱动和透明。无论您是经验丰富的机器学习开发人员还是刚入门,这种组合都为您提供了创建健壮、高效和符合道德规范的 AI 系统所需的工具。因此,下次您开始一个机器学习项目时,请记住利用 MLFlow 和 LangTest 的强大功能,以实现优化的开发旅程。