LLM 辩论锦标赛




5个大型语言模型,进行1对1比赛,以针对一个随机议题提出最具说服力的赞成或反对论点。哦,还有,辩论评委也是一个大型语言模型 :)
1. 引言
自2022年11月ChatGPT发布以来,大型语言模型(LLMs)彻底改变了我们的日常生活:OpenAI的LLM驱动的聊天应用程序在5天内获得了100万用户,到2024年10月,发布近两年后,单月访问量达到37亿次,使其跻身访问量最大网站排行榜第11位。
文本生成人工智能(AI)的广泛采用也反映在众多公司发布的大型语言模型数量的飙升上:虽然OpenAI、Anthropic或其他大型AI公司主要构建闭源产品,但这些主要在HuggingFace Hub上发布的新模型,大多是开放权重或开源的(有关区别的解释请参见本文)。引领开放AI革命的公司包括Meta、Qwen(阿里巴巴)、Huggingface (HF)、Microsoft等。
开放模型在性能上正逐步接近闭源模型,在许多任务上,如编码或最新的推理能力上,都能与它们匹敌。
随着开放式大型语言模型在复杂任务上的表现越来越好,其中一个可以测试它们的领域是**辩论**。关于这个主题已经有一些研究,其中最相关的贡献可以概括为:
- Agent4Debate (Zhang et al., 2024):一个协作框架,利用搜索器、分析器、写作者和审阅者来模拟人类在辩论准备和执行中的行为。经与人类和其他基线模型评估,Agent4Debate展现出与人类相当的能力。
- Debatrix (Liang et al., 2024):一个用于多轮辩论场景的综合LLM评委。
- 用于评估大型语言模型性能的辩论(Moniri et al., 2024):一个基于大型语言模型之间辩论的自动化评估框架,由另一个大型语言模型进行评判。这有助于在领域特定知识或固定测试集之外,对语言模型进行大规模基准测试。
- DebateBrawl (Aryan, 2024):一个平台,它将遗传算法和博弈论策略与大型语言模型推理和文本生成能力相结合,通过精心构建连贯而深刻的论点,为用户提供互动辩论体验。
在这篇博客文章中,我们将提出一个由五个最先进的开放模型组成的辩论锦标赛,这些模型可以通过HuggingFace Inference API获取。
2. 材料与方法
2a. 锦标赛的总体结构
锦标赛采用“意大利式”赛制,这意味着所有参与者都与其他所有参与者进行比赛。没有“主客场”赛制:每个参与者只与其他参与者比赛一次。模型获胜一场比赛可得一分,输掉比赛则不得分(但也不会扣分)。
每轮锦标赛都是一次性的,这意味着每个参与者只有一次机会生成一篇150-250字的论点,然后由外部LLM进行评判。
本届锦标赛有5个LLM作为**辩手**
meta-llama/Llama-3.1-8B-InstructQwen/Qwen2.5-72B-Instructmicrosoft/Phi-3.5-mini-instructHuggingFaceH4/starchat2-15b-v0.1mistralai/Mistral-7B-Instruct-v0.3
以及两个作为**评委**
2b. 数据收集与处理
用于启动辩论赛的议题均从HuggingFace上的kokhayas/english-debate-motions-utds数据集中提取。
然后从原始数据集中包含的10,000多个议题中随机抽取了1,000个,并为每轮辩论选择了一个随机议题。
from datasets import load_dataset
# download the dataset from HF hub
dts = load_dataset("kokhayas/english-debate-motions-utds")
dtsdct = dts["train"]
import random as r
# sample 1000 motions from the original dataset
motions = dtsdct["motion"]
motions2use = []
numbers = []
j = 0
while j < 1000:
n = r.randint(0,10000)
if n not in numbers:
numbers.append(n)
if motions[n].lower().startswith("th"):
motions2use.append(motions[n])
j+=1
else:
continue
else:
continue
2c. 锦标赛的构建与运行
我们通过以下步骤构建了锦标赛:
- 将其分解为原子部分,即“构建块”(定义辩手和评委如何生成他们的答案)
- 扩展到创建一轮的结构(辩手1 -> 辩手2 -> 评委)
- 将整个锦标赛定义为一个回合循环,包括辩论数据收集和积分追踪(用于最终排名)
用于创建辩论锦标赛构建块的代码如下:
from huggingface_hub import InferenceClient
from google.colab import userdata
# create an HF client for inference
hf_token = userdata.get('HF_TOKEN_INFERENCE')
client = InferenceClient(api_key=hf_token)
# define a function for the debaters to produce their argument
def debate_inference(model, prompt):
messages = [
{"role": "system", "content": "You are skilled in competitive debate. You produce arguments that strictly adhere to the position you are required to take by the prompts you are proposed with"},
{"role": "user", "content": prompt}
]
completion = client.chat.completions.create(
model=model,
messages=messages,
temperature=0.5,
max_tokens=2048,
top_p=0.7
)
return completion.choices[0].message.content
# define a function for the judges to produce their verdict
def judge_inference(model, motion, essay1, essay2):
messages = [
{"role": "system", "content": "You are a judge, based on the motion, the argumentation in favor of it and the argumentation against it, you should produce a JSON string that contains the following fields:\n\n- winner (str): can take only FAVOR or AGAINST as values, based on who you think the winner is\n- reasons (str): the reasons why you chose the winner. OUTPUT ONLY THE JSON STRING AS: '''\n\n```json\n{\"winner\": 'FAVOR'|'AGAINST', \"reasons\": 'Reasons why you chose the winner'}\n```\n\n'''"},
{"role": "user", "content": "MOTION:\n"+motion},
{"role": "user", "content": "ARGUMENT IN FAVOR:\n"+essay1},
{"role": "user", "content": "ARGUMENT AGAINST:\n"+essay2},
{"role": "user", "content": "Who is the winner? OUTPUT ONLY THE JSON STRING AS: '''\n\n```json\n{\"winner\": 'FAVOR'|'AGAINST', \"reasons\": 'Reasons why you chose the winner'}\n```\n\n'''"}
]
completion = client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
max_tokens=2048,
top_p=0.7
)
return completion.choices[0].message.content
# define a tournament round
def tournament_round(model1, model2, judge, motion):
prompt1 = "Produce an essay of maximum 150 words in favor of this motion: " + motion
prompt2 = "Produce an essay of maximum 150 words against this motion: " + motion
essay1 = debate_inference(model1, prompt1)
essay2 = debate_inference(model2, prompt2)
winner_answer = judge_inference(judge, motion, essay1, essay2)
return essay1, essay2, winner_answer
为了运行锦标赛本身,我们为骨干结构添加了以下功能:
- 积分追踪
- 辩论数据收集
- 从评委的回答中提取**获胜者**和**获胜原因**
最后一点特别棘手,因为即使系统指令非常明确如何构建评委的回答,评委的回答也可能以各种格式出现,因此我们决定通过添加一个**输出解析器**LLM来解决输出可变性带来的挑战。这个输出解析器LLM是`gpt-4o-mini`,它被封装到Langchain OpenAI聊天类(`ChatOpenaAI`)中,并链接到Pydantic模式以生成结构化输出。
from google.colab import userdata
import os
# set OpenAI API key as an environment variable
a = userdata.get('OPENAI_API_KEY')
os.environ["OPENAI_API_KEY"] = a
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
# generate a chat prompt template with Langchain, to wrap your system instructions for the model
GPT_MODEL = "gpt-4o-mini"
llm = ChatOpenAI(temperature=0, model=GPT_MODEL)
system_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are a helpful assistant. Your job is to restructure the virdict from a debate competition so that it follows this structure:
- winner: the winner, as reported by the virdict
- reasons: reasons for the choice of the winner
Strictly follow the virdict you are provided with, do not add/make up any information."""),
("human", "{message}"),
]
)
from pydantic import BaseModel, Field
# create a Pydantic BaseModel for structured output generation
class Verdict(BaseModel):
"""Structure of the output of a debate competition verdict"""
winner: str = Field(description="The winner, as reported by the verdict")
reasons: str = Field(description="Reasons for the choice of the winner")
# define an inference-ready system instructions+LLM+structured output parser
chain = system_prompt | llm.with_structured_output(Verdict)
现在我们可以运行锦标赛了
import time
# define points tracker
modelpoints = {judges[i]: {model: 0 for model in models} for i in range(len(judges))}
# define data collector
motions2args2winner2reasons = {"motions": [], "judge": [], "favor_model": [], "favor_arg": [], "against_model": [], "against_arg": [], "winner": [], "reasons": [], "total_time": []}
judge_counter = 0
for judge in judges:
judge_counter+=1
pairs = []
counter = 0
for i in range(len(models)):
for j in range(len(models)):
# only make two models play with each other if they have not met before
if i!=j and (i,j) not in pairs and (j,i) not in pairs:
counter+=1
pairs.append((i,j))
motion = r.choice(motions2use)
favoragainst = {"favor": models[i], "against": models[j]}
s = time.time()
favor_arg, against_arg, winner_json = tournament_round(models[i], models[j], judge, motion)
e = time.time()
# add debate data to data collector
motions2args2winner2reasons["total_time"].append(e-s)
motions2args2winner2reasons["judge"].append(judge)
motions2args2winner2reasons["motions"].append(motion)
motions2args2winner2reasons["favor_model"].append(favoragainst["favor"])
motions2args2winner2reasons["favor_arg"].append(favor_arg)
motions2args2winner2reasons["against_model"].append(favoragainst["against"])
motions2args2winner2reasons["against_arg"].append(against_arg)
virdict = chain.invoke({"message": winner_json})
reasons = virdict.reasons
winner = virdict.winner
winner_model = favoragainst[winner.lower()]
motions2args2winner2reasons["winner"].append(winner_model)
motions2args2winner2reasons["reasons"].append(reasons)
# add a point to the winner model
modelpoints[judge][winner_model] += 1
print(f"Done with match: {judge_counter}.{counter}")
print("Done with " + judge + " being a judge")
收集到的数据经过人工标注(代码参考),保存为CSV文件,并作为HuggingFace Hub上的数据集上传。
2d. 赛后分析
代码参考:DebateLLMChampionship_analysis.ipynb 和 MotionCategoriesAssociations.ipynb
赛后分析包括:
- 分析当`QwQ-32B-Preview`担任评委时,议题和获胜论点中的词语。
- 重复1. 中的分析,但以`Llama-3.3-70B-Instruct`作为评委。
- 重复1. 中的分析,但针对`Phi-3.5-mini-instruct`的获胜论点。
- 重复1. 中的分析,但针对`HuggingFaceH4/starchat2-15b-v0.1`的失败论点。
我们还对以`QwQ-32B-Preview`和`Llama-3.3-70B-Instruct`为评委时的获胜论点进行了主题关联分析,以及对`Phi-3.5-mini-instruct`获胜论点和`HuggingFaceH4/starchat2-15b-v0.1`失败论点进行了相同的分析。
以下是为分析定义的通用函数:
import pandas as pd
import nltk
from nltk.corpus import stopwords
from collections import Counter
import matplotlib.pyplot as plt
import seaborn as sns
from typing import Dict, List, Tuple
import numpy as np
df_qwq = df[df["judge"] == "Qwen/QwQ-32B-Preview"]
def compare_winning_arg_w_motion(df: pd.DataFrame) -> Dict:
"""
Analyzes the relationship between winning arguments and their motions.
Returns a dictionary containing analysis results and statistics.
"""
# Initialize containers for analysis
keyword_overlap_scores = []
winning_word_frequencies = Counter()
motion_word_frequencies = Counter()
favor_win_count = 0
against_win_count = 0
overlap_by_length = []
# Analysis results
results = {
'overlap_scores': [],
'word_frequencies': {},
'winning_sides': {},
'length_correlations': []
}
for index, row in df.iterrows():
motion = row["motions"]
motion_keywords = set(extract_keywords(motion))
motion_word_frequencies.update(motion_keywords)
# Determine winning argument
is_favor_winning = row["winner"] == row["favor_model"]
winning_arg = row["favor_arg"] if is_favor_winning else row["against_arg"]
# Update win counters
if is_favor_winning:
favor_win_count += 1
else:
against_win_count += 1
# Extract and analyze winning argument
common_words = set(extract_most_common_words(winning_arg, len(motion_keywords)))
winning_word_frequencies.update(common_words)
# Calculate overlap score
overlap = len(motion_keywords.intersection(common_words)) / len(motion_keywords)
keyword_overlap_scores.append(overlap)
# Record length correlation
overlap_by_length.append((len(winning_arg.split()), overlap))
# Store results
results['overlap_scores'] = keyword_overlap_scores
results['word_frequencies'] = {
'motion': dict(motion_word_frequencies.most_common(20)),
'winning_args': dict(winning_word_frequencies.most_common(20))
}
results['winning_sides'] = {
'favor': favor_win_count,
'against': against_win_count
}
results['length_correlations'] = overlap_by_length
# Create visualizations
create_analysis_plots(results)
return results
def create_analysis_plots(results: Dict):
"""Creates and displays analysis visualizations."""
# Set up the plotting area
plt.style.use('seaborn-v0_8-paper')
fig = plt.figure(figsize=(15, 10))
# 1. Overlap Score Distribution
plt.subplot(2, 2, 1)
sns.histplot(results['overlap_scores'], bins=20)
plt.title('Distribution of Keyword Overlap Scores')
plt.xlabel('Overlap Score')
plt.ylabel('Count')
# 2. Winning Sides Pie Chart
plt.subplot(2, 2, 2)
sides = results['winning_sides']
plt.pie([sides['favor'], sides['against']],
labels=['Favor', 'Against'],
autopct='%1.1f%%')
plt.title('Distribution of Winning Sides')
# 3. Word Frequencies Comparison
plt.subplot(2, 2, 3)
motion_words = list(results['word_frequencies']['motion'].keys())[:10]
motion_freqs = [results['word_frequencies']['motion'][w] for w in motion_words]
plt.barh(motion_words, motion_freqs)
plt.title('Top 10 Motion Keywords')
plt.xlabel('Frequency')
# 4. Length vs Overlap Scatter Plot
plt.subplot(2, 2, 4)
lengths, overlaps = zip(*results['length_correlations'])
plt.scatter(lengths, overlaps, alpha=0.5)
plt.title('Argument Length vs Keyword Overlap')
plt.xlabel('Argument Length (words)')
plt.ylabel('Overlap Score')
# Add trend line
z = np.polyfit(lengths, overlaps, 1)
p = np.poly1d(z)
plt.plot(lengths, p(lengths), "r--", alpha=0.8)
plt.tight_layout()
plt.show()
# Helper functions (assuming these exist)
def extract_keywords(text: str) -> List[str]:
"""Extract keywords from text. Implement your keyword extraction logic here."""
stop_words = set(stopwords.words('english'))
words = nltk.word_tokenize(text.lower())
return [w for w in words if w.isalnum() and w not in stop_words]
def extract_most_common_words(text: str, n: int) -> List[str]:
"""Extract n most common words from text."""
words = extract_keywords(text)
return [word for word, _ in Counter(words).most_common(n)]
3. 结果与结论
3a. 锦标赛结果
锦标赛由`Phi-3.5-mini-instruct`夺冠,总共获得5场胜利,并且在`Llama-3.3-70B-Instruct`担任评委的锦标赛批次中也获得了胜利(图1)。
紧随其后的是获得第二名的`Mistral-7B-Instruct-v0.3`(4场胜利,在`QwQ-32B-Preview`担任评委的锦标赛批次中获胜)、`Llama-3.1-8B-Instruct`(总共4场胜利)和`Qwen2.5-72B-Instruct`(总共4场胜利)。
`starchat2-15b-v0.1`获得第三名,总共2场胜利。

图1:锦标赛领奖台
3b. 赞成与反对获胜案例分布
我们首先评估了两位评委在决定获胜论点时的“赞成”与“反对”倾向:
QwQ-32B-Preview选择“赞成”5次,“反对”5次。Llama-3.3-70B-Instruct选择“赞成”7次,“反对”3次。
我们对`Phi-3.5-mini-instruct`获胜的案例和`starchat2-15b-v0.1`失败的案例进行了相同的分析:
Phi-3.5-mini-instruct在“赞成”时赢了3次,在“反对”时赢了2次。starchat2-15b-v0.1仅在“反对”议题时失败(在“赞成”时赢了两次,在“反对”时赢了一次)。
3c. 议题与论点关键词重叠度
我们评估了议题中的关键词与获胜论点中的关键词在各种设置下的重叠得分。
- 我们发现,当`QwQ-32B-Preview`和`Llama-3.3-70B-Instruct`担任评委时,重叠得分均存在较大差异。两个变动范围都可比,其中`Llama-3.3-70B-Instruct`获胜论点的变动范围略窄(图2a-b)。
- `Phi-3.5-mini-instruct`获胜论点的重叠得分与前述情况相当,但其变异性远大于`starchat2-15b-v0.1`失败论点的变异性(图2c-d)。
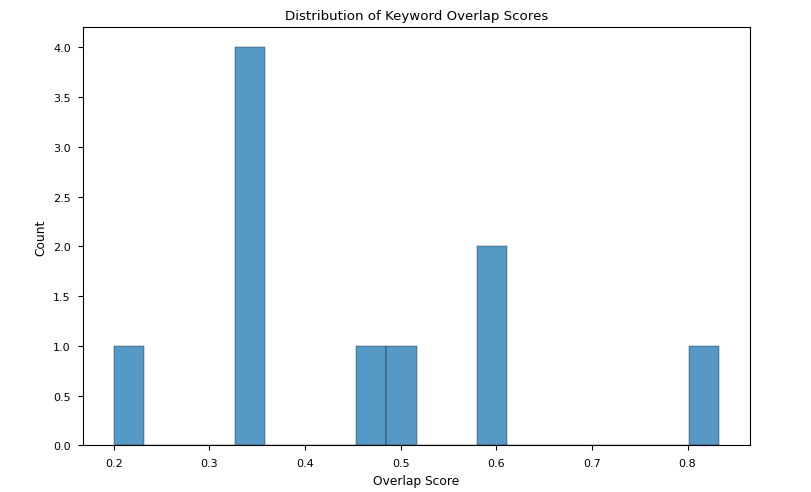
图2a:当QwQ-32B-Preview担任评委时,议题关键词与获胜论点关键词重叠得分分布
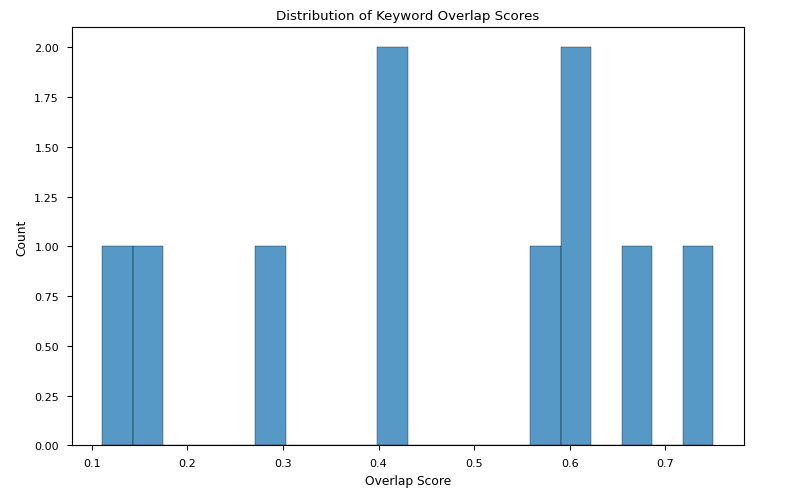
图2b:当Llama-3.3-70B-Instruct担任评委时,议题关键词与获胜论点关键词重叠得分分布
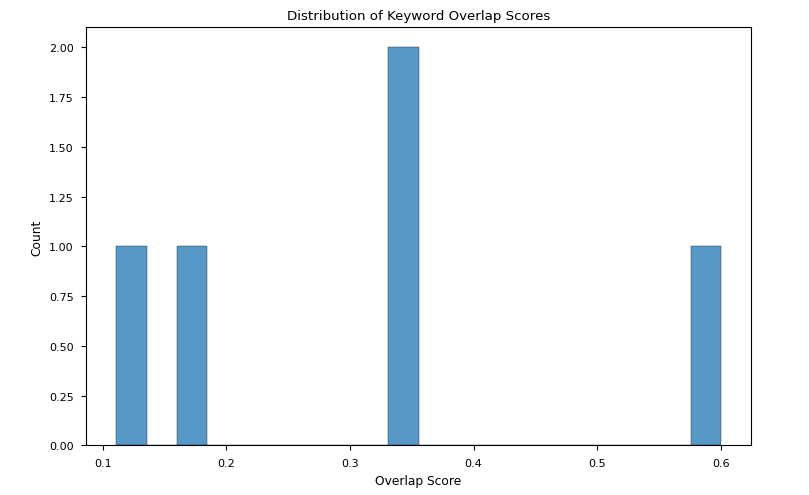
图2c:Phi-3.5-mini-instruct获胜论点议题关键词与获胜论点关键词重叠得分分布
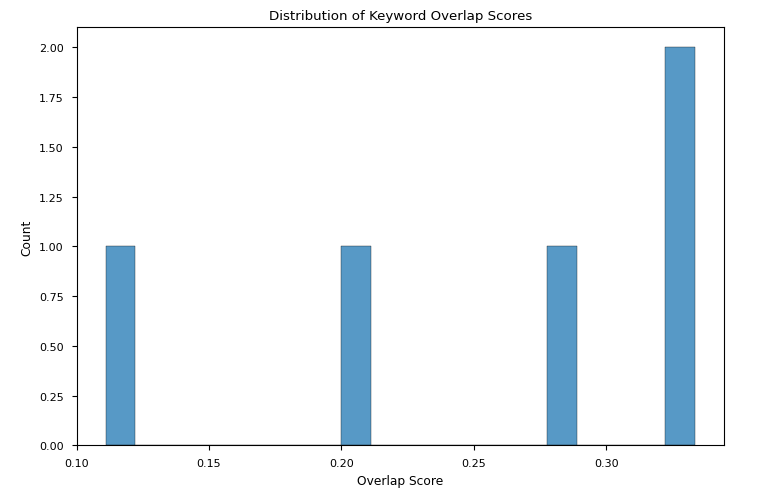
图2d:starchat2-15b-v0.1失败论点议题关键词与获胜论点关键词重叠得分分布
要点:尽管结果并未收敛到单一解释,但可以说高重叠得分不一定有助于获胜,而低重叠得分可能会影响比赛的失利。
我们还评估了论点长度(按词数计)与关键词重叠得分之间的相关性:虽然在`QwQ-32B-Preview`和`Llama-3.3-70B-Instruct`作为评委时,总体获胜论点没有显著相关性,但图3a-b突出显示,`Phi-3.5-mini-instruct`获胜论点呈现出更强的正相关,而`starchat2-15b-v0.1`失败论点则呈现出更强的负相关。
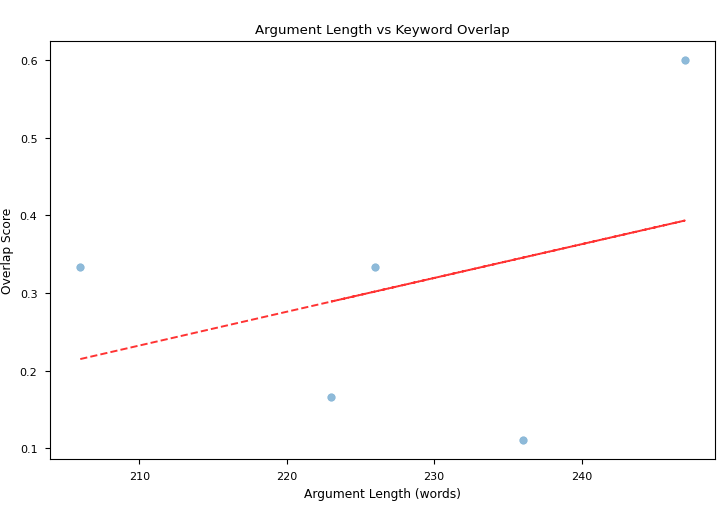
图3a:Phi-3.5-mini-instruct获胜论点中关键词重叠得分与论点长度的相关性
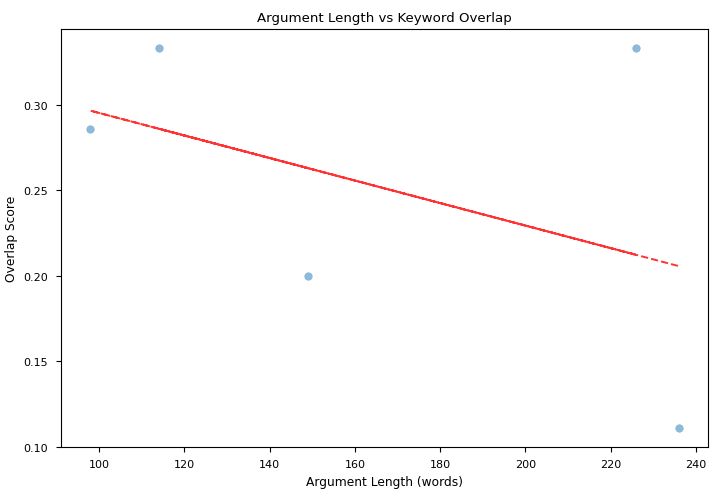
图3b:starchat2-15b-v0.1失败论点中关键词重叠得分与论点长度的相关性
要点:这项相关性研究可能指出,`starchat2-15b-v0.1`在生成较长论点时未能保持与原始议题的一致性,这可能导致了比赛的失败。另一方面,`Phi-3.5-mini-instruct`在生成较长论点时,能够保持与原始议题的更广泛的一致性,这可能影响了其胜利。
3d. 议题主题与获胜论点关联性
我们最后评估了“赞成”或“反对”的立场与议题主题相关的获胜情况。
首先,我们考虑了评委选择获胜者时可能存在的“个人意见”影响(即LLM的偏见),使用`gpt-4o-mini`来检测这些偏见并报告其中包含“个人意见”的表达。然后我们构建了表1。
| 评判模型 | 主题 | 立场 | 受影响 | 引用 |
|---|---|---|---|---|
| Qwen/QwQ-32B-Preview | 囚犯引渡 | 反对 | 否 (False) | |
| Qwen/QwQ-32B-Preview | 反对中国审查制度 | 赞成 | 真实 | 赞成论点更强,因为它强调人权、言论自由以及社会稳定所需的平衡方法。这符合国际标准并促进更具包容性的社会。 |
| Qwen/QwQ-32B-Preview | 联合国民主化 | 赞成 | 否 (False) | |
| Qwen/QwQ-32B-Preview | 非暴力运动未能带来社会变革 | 反对 | 否 (False) | |
| Qwen/QwQ-32B-Preview | 西方资助缅甸政变 | 反对 | 否 (False) | |
| Qwen/QwQ-32B-Preview | 停止斗牛 | 赞成 | 真实 | 赞成禁止斗牛的论点更强,因为它强调了道德考量。 |
| Qwen/QwQ-32B-Preview | 纸质优于互联网 | 反对 | 否 (False) | |
| Qwen/QwQ-32B-Preview | 禁止自我诊断网站 | 赞成 | 真实 | 误诊和延误治疗的潜在风险对公众健康构成重大威胁。隐私问题进一步强调了对这些网站进行监管或禁止的必要性,以确保个人获得准确和安全的医疗信息和治疗。 |
| Qwen/QwQ-32B-Preview | 公共部门工人有罢工权 | 反对 | 否 (False) | |
| Qwen/QwQ-32B-Preview | 对冲基金不购买主权债务 | 赞成 | 否 (False) | |
| meta-llama/Llama-3.3-70B-Instruct | 工会拖慢进程 | 赞成 | 否 (False) | |
| meta-llama/Llama-3.3-70B-Instruct | 取消第三世界债务 | 赞成 | 否 (False) | |
| meta-llama/Llama-3.3-70B-Instruct | 拒绝为绝症患者提供治疗 | 反对 | 真实 | 赞成论点未能提出连贯或令人信服的案例。 |
| meta-llama/Llama-3.3-70B-Instruct | 优先技术难民进入欧盟 | 反对 | 真实 | 以人道主义为中心的方法更符合公平和平等原则 |
| meta-llama/Llama-3.3-70B-Instruct | 遣返朝鲜难民 | 反对 | 真实 | 保护难民生命和自由的道德和法律义务优先。 |
| meta-llama/Llama-3.3-70B-Instruct | 不以技术取代工人 | 赞成 | 否 (False) | |
| meta-llama/Llama-3.3-70B-Instruct | 两院制议会:政治家和专家 | 赞成 | 真实 | 赞成论点提出了一个更有说服力的案例,将专家整合到立法过程中的好处似乎超过了反对论点中提到的缺点。 |
| meta-llama/Llama-3.3-70B-Instruct | 手作礼物胜过品牌礼物 | 赞成 | 真实 | 赞成方提出的论点更具说服力,它强调了手工礼物所提供的情感价值、个性化和共同体验,这些都超过了反对方提及的潜在缺点。 |
| meta-llama/Llama-3.3-70B-Instruct | 不诱捕恋童癖 | 赞成 | 否 (False) | |
| meta-llama/Llama-3.3-70B-Instruct | 关塔那摩被拘留者在本国受审 | 赞成 | 否 (False) |
表1:评委选择获胜者时“个人意见”的潜在影响
表1显示,`QwQ-32B-Preview`在30%的案例中表现出“个人意见”影响,而`Llama-3.3-70B-Instruct`在50%的案例中表现出这种影响:这种差异可能在于`QwQ-32B-Preview`固有的推理结构,这可能有助于避免判断中的偏见陷阱。
从表1中我们还可以看到,两位评委所选择的获胜立场(除了少数情况)都与更自由/左倾的立场一致,这可能是由于大型语言模型的政治“偏见”,它们似乎都倾向于自由/左翼/社会民主观点(Rozado, 2024)。为了更好地评估我们大型语言模型的政治倾向,我们对`Llama-3.3-70B-Instruct`(评委)、`Phi-3.5-mini-instruct`和`starchat2-15b-v0.1`(锦标赛的获胜者和失败者)进行了政治罗盘测试(图4)。
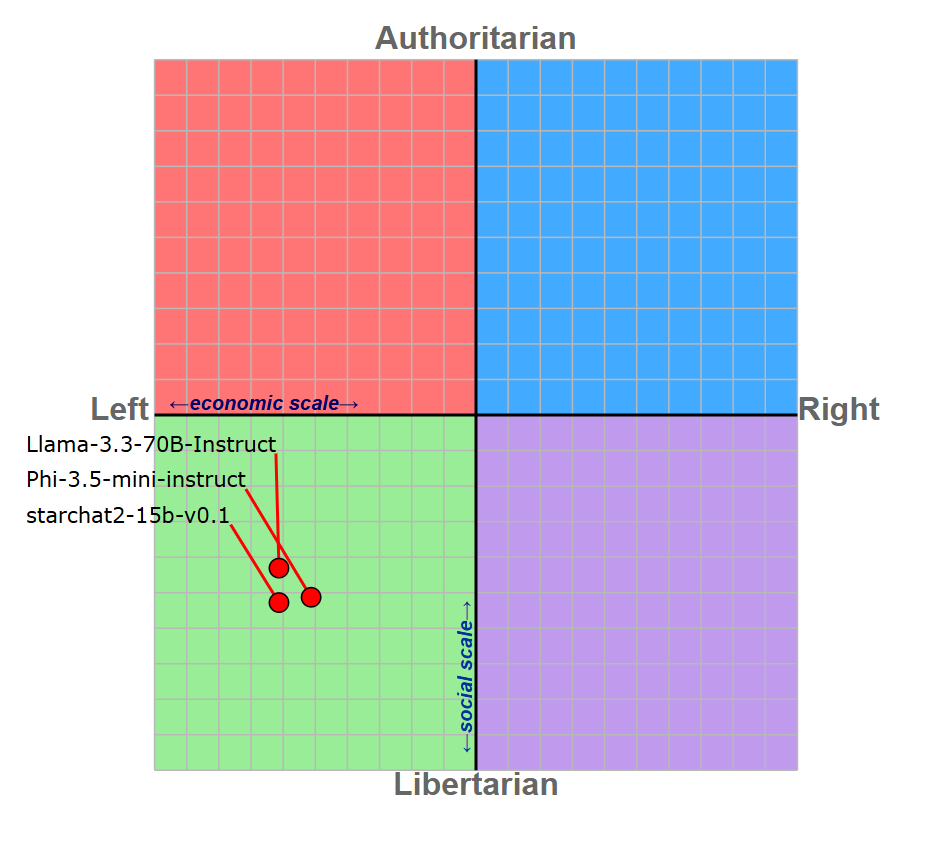
图4:三个评估LLM的政治罗盘
政治罗盘揭示了三个被评估的LLM都倾向于左倾的自由主义立场:这可能意味着评委在选择获胜者时的立场受到了内在政治偏见的影响。模型固有的政治倾向也可能影响了`Phi-3.5-mini-instruct`和`starchat2-15b-v0.1`的获胜几率(表2)。
| 模型 | 立场 | 议题 |
|---|---|---|
| microsoft/Phi-3.5-mini-instruct (获胜方) | 反对 | 西方资助缅甸政变,遣返朝鲜难民 |
| microsoft/Phi-3.5-mini-instruct (获胜方) | 赞成 | 禁止自我诊断网站,手作礼物优于品牌礼物,不诱捕恋童癖 |
| HuggingFaceH4/starchat2-15b-v0.1 (失败方) | 反对 | 联合国民主化,停止斗牛,禁止自我诊断网站,不以技术取代工人,手作礼物优于品牌礼物 |
| HuggingFaceH4/starchat2-15b-v0.1 (失败方) | 赞成 | 无 |
正如您所看到的,`starchat2-15b-v0.1`需要捍卫**反对**一些通常受到自由/左翼政治观点支持的问题的立场:从这个意义上讲,该模型可能很难生成有效的论点。
另一方面,`Phi-3.5-mini-instruct`必须捍卫的所有立场都与其政治观点一致,这使得该大型语言模型更容易生成有说服力且获胜的论点。
要点:大型语言模型的政治倾向与其在选择获胜者/生成有说服力的论点方面的能力之间可能存在相关性。
4. 数据与代码可用性
代码可通过AstraBert/DebateLLM-Championship GitHub仓库获取以供复现。代码结构为三个Google Colab笔记本,执行本博客文章中报告的代码。
收集到的辩论数据可在HuggingFace Hub上的as-cle-bert/DebateLLMs获取。