Repetita iuvant(重复有益):如何改进 AI 代码生成





导言:Codium-AI 实验
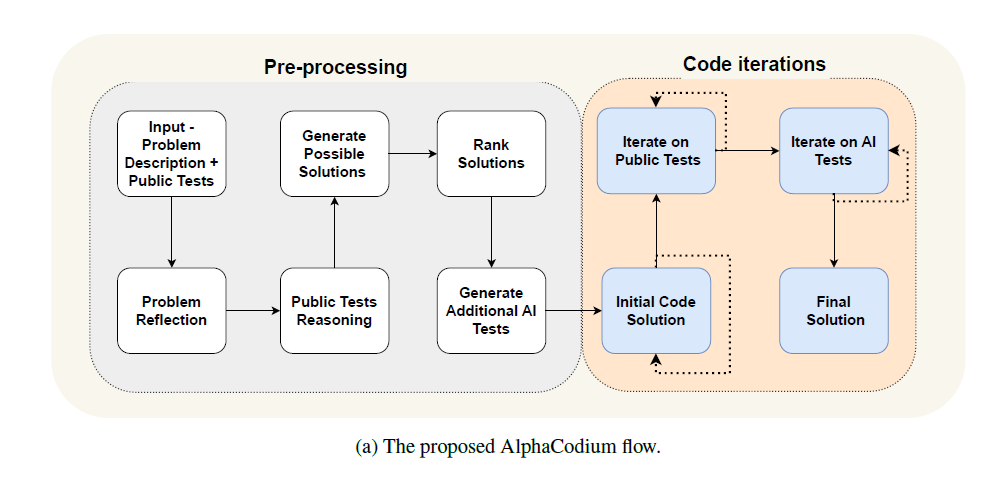
这张图片取自 Codium-AI 一月份的论文(Ridnik 等人,2024),其中他们介绍了 AlphaCodium,它展示了很可能是以 AI 为中心的代码生成的未来。
因此,理解这种工作流程不仅对开发者至关重要,对偶尔需要进行一些编码的非技术人员也同样重要:让我们以一贯的简单明了的方式对其进行分解,以便(几乎)所有人都能理解!
想测试某种类似 AlphaCodium 的实现吗?前往我构建的这个空间!
0. 起点
0a. 数据集
AlphaCodium(图片中的工作流程名称)旨在解决 CodeContest 中包含的复杂编程问题。CodeContest 是一个竞技编程数据集,包含大量问题,代表了 LLM 各种推理挑战。
使用 CodeContest 数据集的两大优势在于:
- 存在公共测试(开发人员在竞赛期间可以访问的输入值和结果集,以查看其代码的性能)和众多私有测试(仅评估人员可访问)。这非常重要,因为私有测试可以避免“过拟合”问题,这意味着它们可以防止 LLM 生成完美适应公共测试的代码以通过它们,而实际上代码并没有以通用方式工作。总而言之,私有测试可以避免误报。
- CodeContest 问题不仅仅是“难以解决”:它们包含 LLM 在努力泛化所呈现的问题时通常不会注意到的细微细节和微妙之处。
0b. 竞争模型
其他模型或流程也致力于解决代码生成中复杂推理的平滑化挑战;Codium-AI 论文中明确提及的两个模型是:
- Google Deepmind 的 AlphaCode 专门针对 CodeContest 进行了微调:它会生成数百万个解决方案,然后根据它们与问题表示的匹配程度逐步选择较小的部分。最终,只保留 1-10 个解决方案。尽管当时它取得了令人印象深刻的结果,但其计算负担使其不适合日常用户。
- Le 等人(2023)的 CodeChain 旨在增强模块化代码生成能力,使输出更接近熟练开发人员的产物。这通过一系列自我修订实现,由先前生成的代码片段引导。
剧透一下:根据论文中报告的基准,它们都没有 AlphaCodium 表现出色。
1. 流程
1a. 自然语言推理
正如本文开头图片所示,AlphaCodium 的工作流程分为两个部分。第一部分包含主要涉及自然语言的思维过程,因此我们可以称之为“自然语言推理(NLR)”阶段。
- 我们首先从包含问题和公共测试的提示开始。
- 然后,我们要求 LLM 对问题进行“出声推理”。
- 同样的推理过程也适用于公共测试。
- 在对问题进行了一些思考之后,模型输出第一批潜在解决方案。
- 然后要求 LLM 根据其对问题和公共测试的适用性对这些解决方案进行排名。
- 为了进一步测试模型对初始问题的理解,我们要求它生成其他测试,我们将使用这些测试来评估代码解决方案的性能。
1b. 编码测试迭代
第二部分包括使用公共测试和 AI 生成的测试进行实际代码执行和评估。
- 我们确保初始代码解决方案没有错误:如果没有,我们会重新生成它,直到达到最大迭代限制或生成一个看起来没有错误的解决方案。
- 然后,公共测试由模型的代码接管:我们寻找在多次迭代中通过失败次数最多的解决方案;此解决方案将传递给 AI 测试。
- 最后一步是根据 AI 生成的输入/输出来测试代码:最符合它们的解决方案将作为最终解决方案返回,并将使用私有测试进行评估。
第二部分可能会给我们留下一些问题,例如:如果模型没有理解问题并生成了错误的测试怎么办?如果存在损坏的 AI 生成测试,我们如何防止代码退化?
这些问题将在下一节中解决。
2. 性能提升方案
2a. 面向生成的变通方法
Codium-AI 科学家首先关注的目标是自然语言推理的生成和编码解决方案的产生。
- 他们让模型以简洁有效的方式进行推理,明确要求它以项目符号的形式组织其思路:事实证明,当要求 LLM 推理问题时,这种策略可以提高输出的质量。
- AI 被要求以 YAML 格式生成输出,这种格式比 JSON 格式更容易生成和解析,同时还可以消除提示工程的所有麻烦,并允许解决高级问题。
- 直接问题和单块解决方案被推迟,以利于推理和探索。对模型施加“压力”以找到最佳解决方案通常会导致幻觉,并使 LLM 陷入困境而无法回头。
2b. 面向代码的变通方法
第 1 节末尾的问题是 AlphaCodium 的重要问题,可能会严重影响其性能——但论文作者找到了解决方案:
- 软决策和自我验证以应对错误的 AI 生成测试:我们不要求模型以“是”/“否”的明确答案评估其测试,而是让它推理其测试、代码和输出的正确性。这导致了“软决策”,使模型能够调整其测试。
- 锚点测试避免代码退化:假设 AI 测试即使在修订后也是错误的,那么代码解决方案可能是正确的,但仍然无法通过 LLM 生成的测试。在这种情况下,模型会继续修改其代码,使其不可避免地不适合真实解决方案:为避免这种退化,AlphaCodium 识别“锚点测试”,即代码通过的公共测试,并且在 AI 测试迭代后也应通过,以便保留作为解决方案。
3. 结果
当直接要求 LLM 从问题生成代码(直接提示方法)时,经过 AlphaCodium 增强的开源(DeepSeek-33B)和闭源(GPT3.5 和 GPT4)模型表现优于其基础对应模型,其中 GPT4 的性能提升了 2.3 倍(从 19% 到 44%)尤为突出。
与 AlphaCode 和 CodeChain 的比较则使用 pass@k 指标(即生成 k 个解决方案通过测试的百分比)进行:AlphaCodium 在 GPT3.5 和 GPT4 上的 pass@5 均高于 AlphaCode 的 pass@1k@10(1000 个初始解决方案和 10 个选定的最终解决方案)和 pass@10k@10,尤其是在验证阶段。CodeChain 在 GPT3.5 上的 pass@5 也低于 AlphaCodium 的结果。
总的来说,这种自我纠正和自我推理的方法似乎比模型本身或其他复杂工作流程能带来更好的性能。
结论:我们将如何应对所有这些未来?
AlphaCodium 的工作流程代表了一种可靠且稳健的方法,可以通过有效结合 NLR 和纠正迭代来提高模型在代码生成方面的性能。
这个流程易于理解,涉及的 LLM 调用数量比 AlphaCode 少 4 个数量级,并且即使对于非专业编码人员,也能提供快速可靠的解决方案。
剩下的问题是:我们将如何应对所有这些未来?我们是否会投入越来越多的数据和训练来构建更好的编码模型?我们会依靠 LLM 的微调或单语义属性来提高它们在某些下游任务上的性能吗?或者我们会开发越来越好的工作流程来改进基础的、未经微调的模型?
没有简单的答案:我们将拭目以待未来会带给我们什么(或者,也许,我们会给未来带来什么)。
参考资料
- Ridnik T, Kredo D, Friedman I 和 Codium AI Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering。ArXiv (2024)。https://doi.org/10.48550/arXiv.2401.08500
- GitHub 存储库