使用 AutoNLP 和 Prodigy 进行主动学习


在机器学习的背景下,主动学习是一个迭代地添加标注数据、重新训练模型并将其提供给最终用户的过程。这是一个无休止的过程,需要人工交互来标注/创建数据。在本文中,我们将讨论如何使用 AutoNLP 和 Prodigy 来构建一个主动学习流水线。
AutoNLP
AutoNLP 是 Hugging Face 创建的一个框架,可以帮助你几乎无需任何编码就在自己的数据集上构建最先进的深度学习模型。AutoNLP 建立在 Hugging Face 的 transformers、datasets、inference-api 和许多其他工具的坚实基础上。
通过 AutoNLP,你可以在自己的自定义数据集上训练最先进的 transformer 模型,对其进行微调(自动),并将其提供给最终用户。所有使用 AutoNLP 训练的模型都是最先进的,并且可用于生产环境。
在撰写本文时,AutoNLP 支持的任务包括二元分类、回归、多类别分类、词元分类(例如命名实体识别或词性标注)、问答、摘要等。你可以在此处找到所有支持任务的列表。AutoNLP 支持英语、法语、德语、西班牙语、印地语、荷兰语、瑞典语等多种语言。它还支持使用自定义分词器的自定义模型(以防你的语言不被 AutoNLP 支持)。
Prodigy
Prodigy 是由 Explosion(spaCy 的创造者)开发的一款标注工具。它是一个基于网络的工具,可以让你实时标注数据。Prodigy 支持自然语言处理(NLP)任务,如命名实体识别(NER)和文本分类,但它不仅限于 NLP!它还支持计算机视觉任务,甚至可以创建你自己的任务!你可以试用 Prodigy 的演示:此处。
请注意,Prodigy 是一个商业工具。你可以在此处了解更多信息。
我们选择 Prodigy 是因为它是一款非常流行的数据标注工具,并且可以无限定制。它的设置和使用也非常简单。
数据集
现在开始本文最有趣的部分。在查看了大量数据集和不同类型的问题后,我们在 Kaggle 上偶然发现了 BBC 新闻分类数据集。该数据集曾用于一次课堂竞赛,可以从此处获取。
我们来看看这个数据集

我们可以看到这是一个分类数据集。其中有一个 Text 列,是新闻文章的文本,还有一个 Category 列,是文章的类别。总共有 5 个不同的类别:business(商业)、entertainment(娱乐)、politics(政治)、sport(体育)和 tech(科技)。
使用 AutoNLP 在这个数据集上训练一个多类别分类模型简直是小菜一碟。
步骤 1:下载数据集。
步骤 2:打开 AutoNLP 并创建一个新项目。
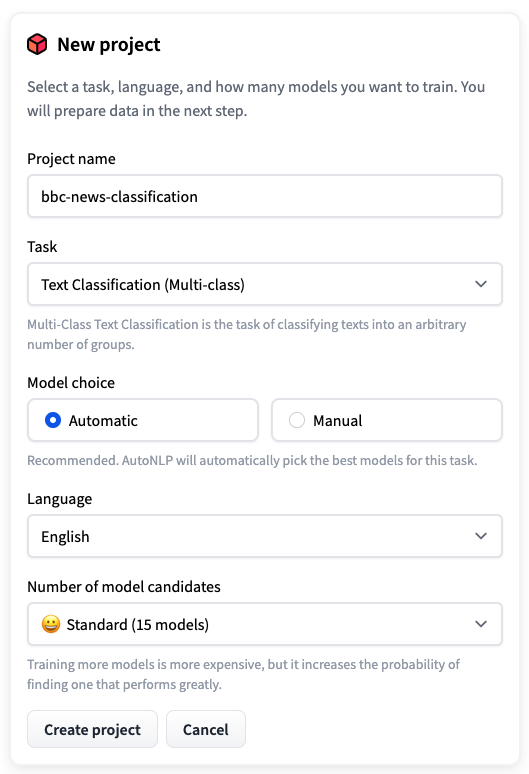
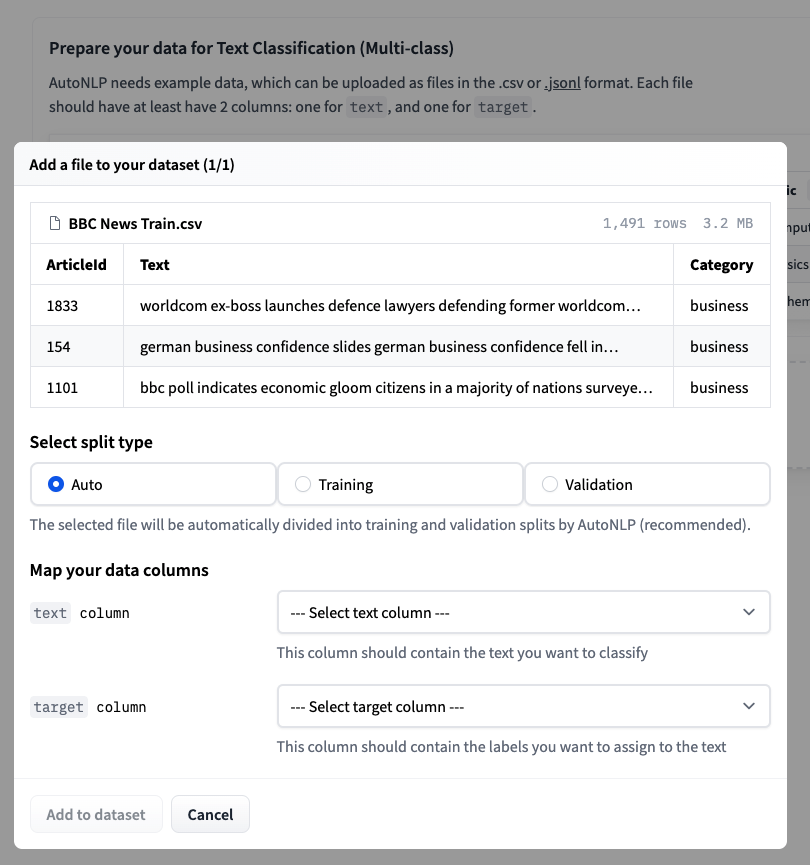
步骤 3:上传训练数据集并选择自动拆分。
步骤 4:接受定价并训练模型。
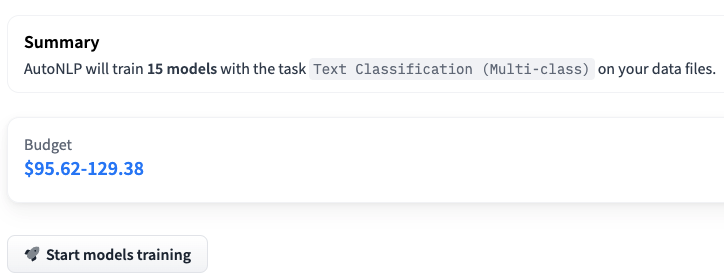
请注意,在上面的例子中,我们正在训练 15 个不同的多类别分类模型。AutoNLP 的定价可以低至每个模型 10 美元。AutoNLP 会自动为你选择最佳模型并进行超参数调优。所以,现在我们只需要坐下来,放松,等待结果。
大约 15 分钟后,所有模型都完成了训练,结果已经准备好了。看起来最好的模型获得了 98.67% 的准确率!
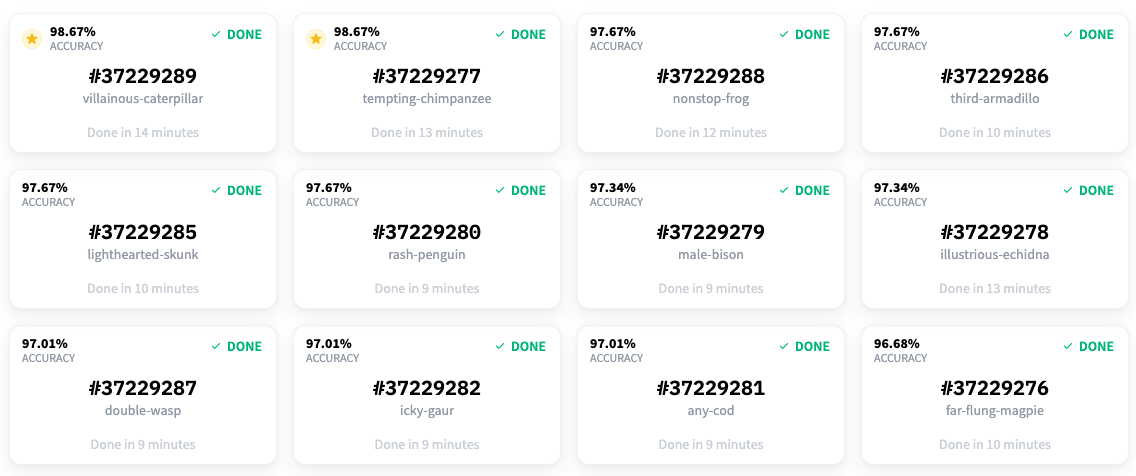
所以,我们现在能够以 98.67% 的准确率对数据集中的文章进行分类!但是等等,我们之前谈论的是主动学习和 Prodigy。它们去哪儿了?🤔 我们确实使用了 Prodigy,我们很快就会看到。我们用它来为这个数据集进行命名实体识别任务的标注。在开始标注部分之前,我们觉得如果能有一个项目,不仅能检测新闻文章中的实体,还能对它们进行分类,那就太酷了。这就是为什么我们基于现有的标签构建了这个分类模型。
主动学习
我们使用的数据集确实有类别,但没有实体识别的标签。因此,我们决定使用 Prodigy 为另一个任务标注数据集:命名实体识别。
一旦你安装了 Prodigy,你只需运行
$ prodigy ner.manual bbc blank:en BBC_News_Train.csv --label PERSON,ORG,PRODUCT,LOCATION
我们来看看这些不同的值
bbc是将由 Prodigy 创建的数据集。blank:en是正在使用的spaCy分词器。BBC_News_Train.csv是将用于标注的数据集。PERSON,ORG,PRODUCT,LOCATION是将用于标注的标签列表。
运行上述命令后,你可以访问 prodigy 的网页界面(通常在 localhost:8080)并开始标注数据集。Prodigy 的界面非常简单、直观且易于使用。界面如下所示
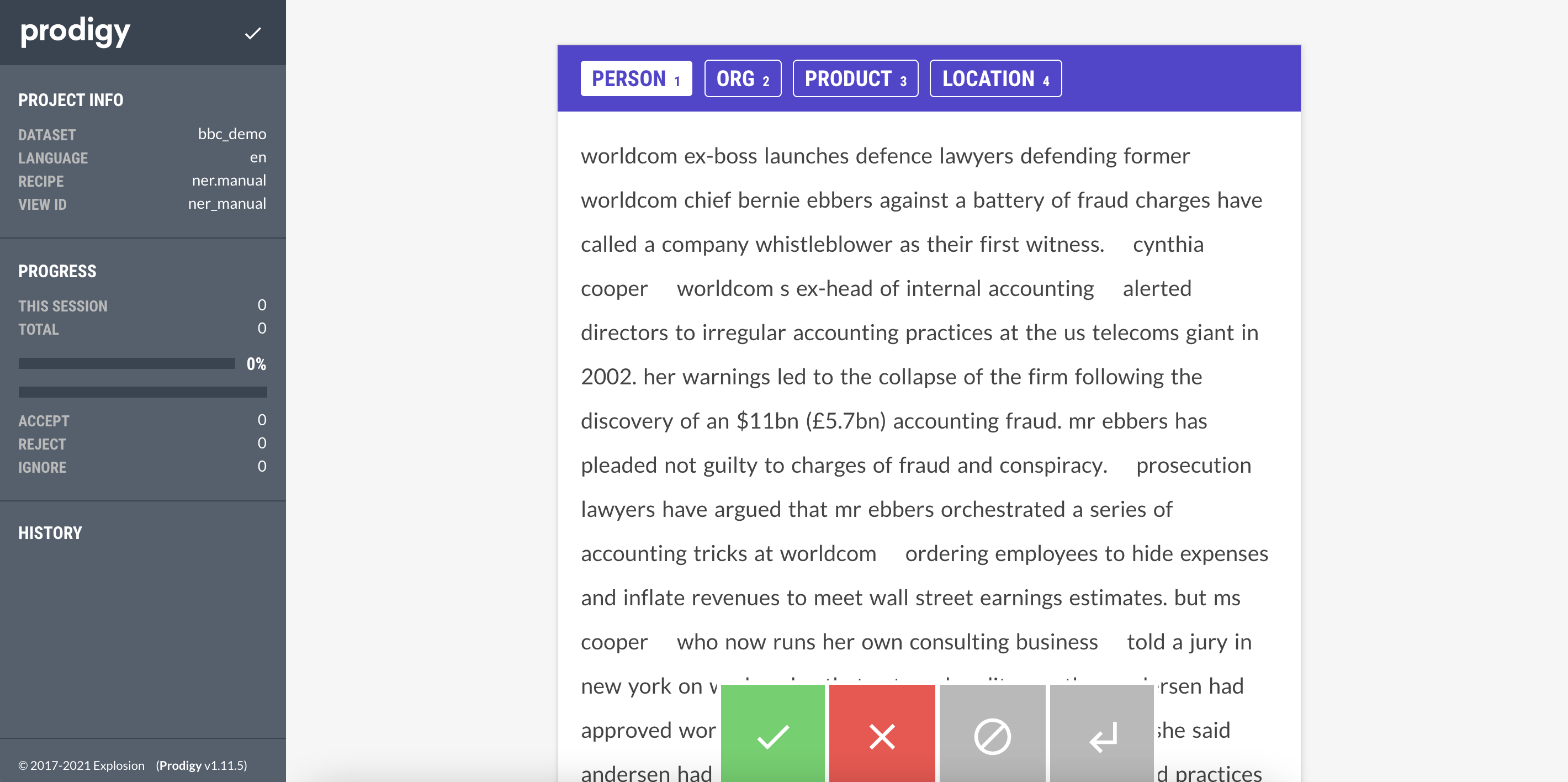
你所要做的就是选择要标注的实体(PERSON, ORG, PRODUCT, LOCATION),然后选择属于该实体的文本。完成一个文档后,你可以点击绿色按钮,Prodigy 会自动为你提供下一个未标注的文档。
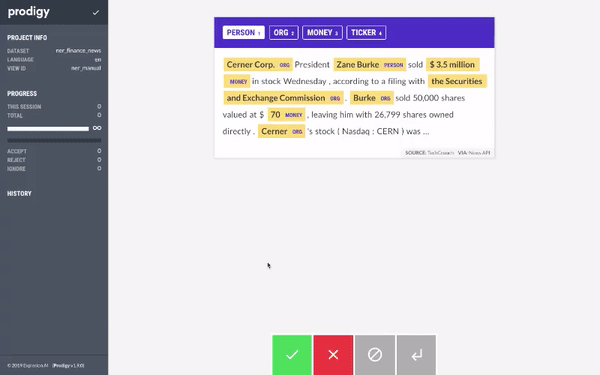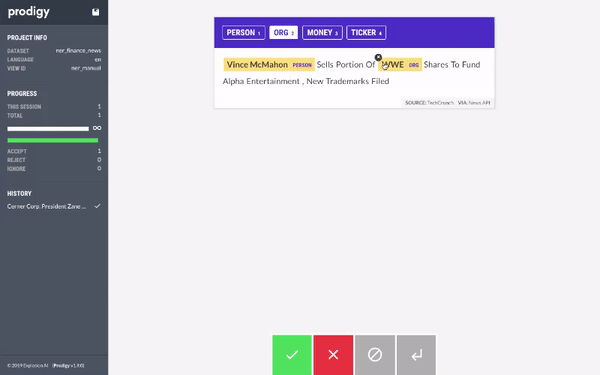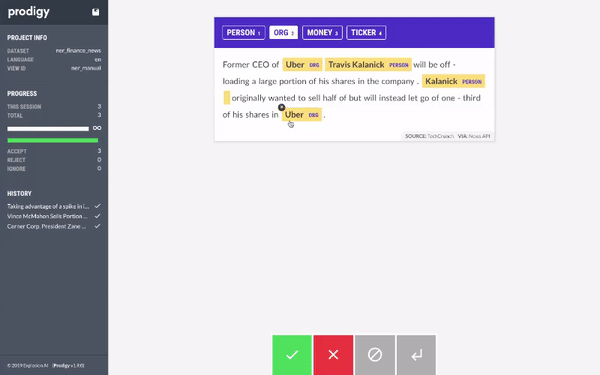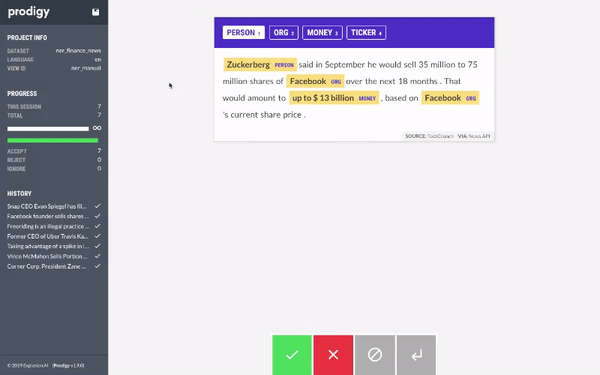
我们开始使用 Prodigy 标注数据集。当我们有大约 20 个样本时,我们使用 AutoNLP 训练了一个模型。Prodigy 不会以 AutoNLP 格式导出数据,所以我们写了一个快速简陋的脚本将数据转换为 AutoNLP 格式
import json
import spacy
from prodigy.components.db import connect
db = connect()
prodigy_annotations = db.get_dataset("bbc")
examples = ((eg["text"], eg) for eg in prodigy_annotations)
nlp = spacy.blank("en")
dataset = []
for doc, eg in nlp.pipe(examples, as_tuples=True):
try:
doc.ents = [doc.char_span(s["start"], s["end"], s["label"]) for s in eg["spans"]]
iob_tags = [f"{t.ent_iob_}-{t.ent_type_}" if t.ent_iob_ else "O" for t in doc]
iob_tags = [t.strip("-") for t in iob_tags]
tokens = [str(t) for t in doc]
temp_data = {
"tokens": tokens,
"tags": iob_tags
}
dataset.append(temp_data)
except:
pass
with open('data.jsonl', 'w') as outfile:
for entry in dataset:
json.dump(entry, outfile)
outfile.write('\n')
这将为我们提供一个 JSONL 文件,可以用于使用 AutoNLP 训练模型。步骤将与之前相同,只是在创建 AutoNLP 项目时我们将选择 Token Classification(词元分类)任务。使用我们最初的数据,我们用 AutoNLP 训练了一个模型。最好的模型准确率约为 86%,但精确率和召回率为 0。我们知道模型什么都没学到。这很明显,因为我们只有大约 20 个样本。
在标注了大约 70 个样本后,我们开始看到一些结果。准确率上升到 92%,精确率为 0.52,召回率约为 0.42。我们取得了一些结果,但仍然不尽如人意。在下图中,我们可以看到这个模型在一个未见过的样本上的表现。
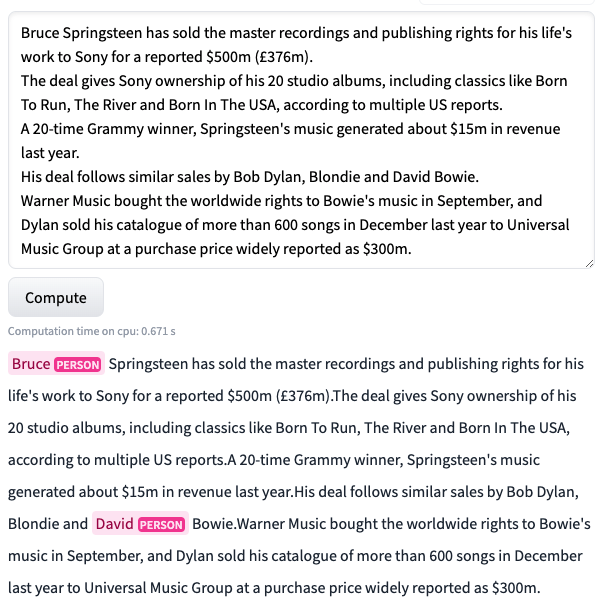
正如你所看到的,模型表现得还很吃力。但这比以前好多了!之前,模型甚至无法在相同的文本中预测出任何东西。至少现在,它能够识别出 Bruce 和 David 是人名。
因此,我们继续努力。我们又标注了一些样本。
请注意,在每次迭代中,我们的数据集都在变大。我们所做的只是将新的数据集上传到 AutoNLP,让它完成剩下的工作。
在标注了大约 150 个样本后,我们开始得到一些不错的结果。准确率上升到 95.7%,精确率为 0.64,召回率约为 0.76。
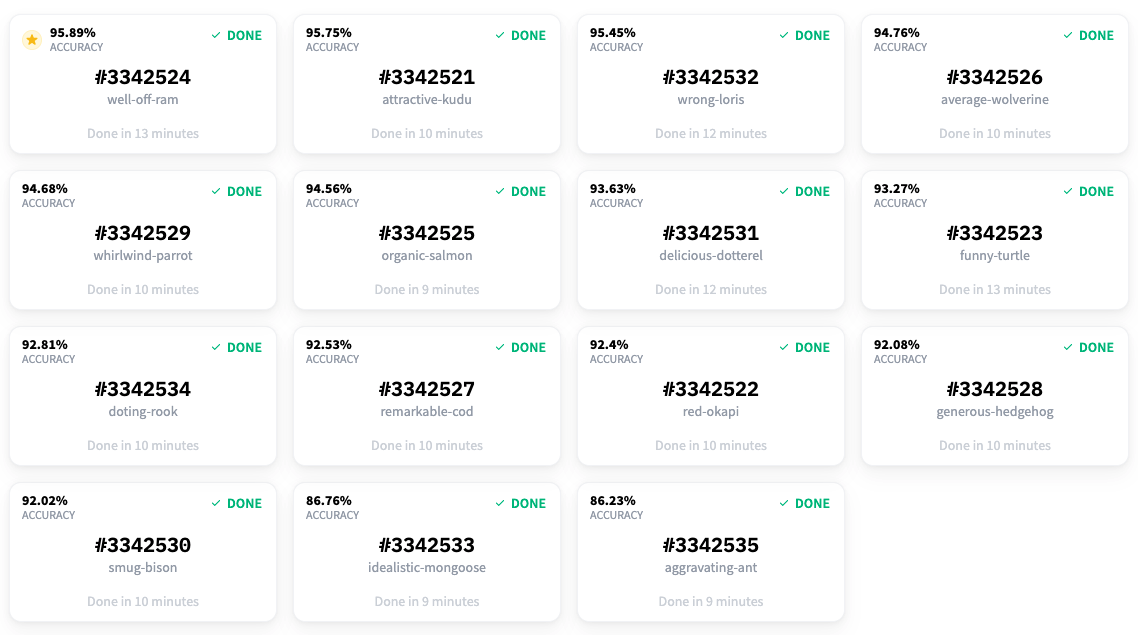
让我们看看这个模型在同一个未见过的样本上的表现如何。
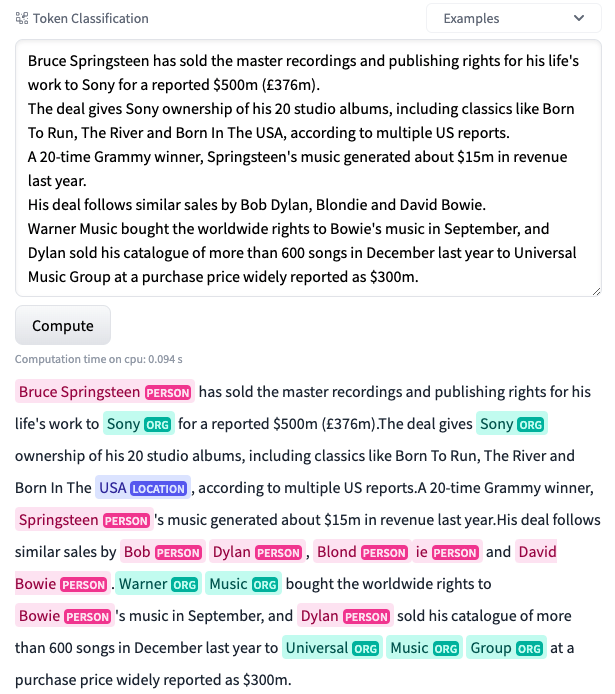
哇!这太棒了!正如你所看到的,模型现在的表现非常出色!它能够检测出同一文本中的许多实体。精确率和召回率仍然有点低,因此我们继续标注更多数据。在标注了大约 250 个样本后,我们在精确率和召回率方面取得了最好的结果。准确率上升到约 95.9%,精确率和召回率分别为 0.73 和 0.79。此时,我们决定停止标注并结束实验过程。下图显示了随着我们向数据集中添加更多样本,最佳模型的准确率是如何提高的
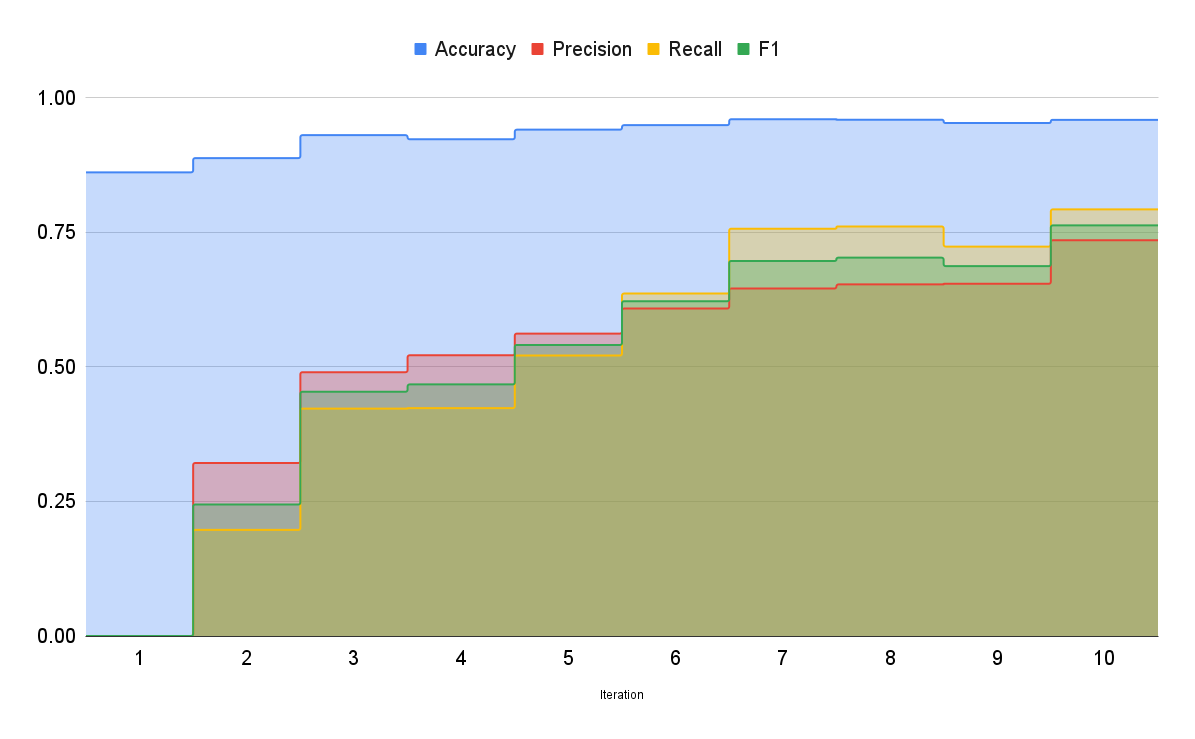
众所周知,更多相关数据会带来更好的模型,从而产生更好的结果。通过这次实验,我们成功创建了一个不仅可以对新闻文章中的实体进行分类,还可以对其进行归类的模型。使用 Prodigy 和 AutoNLP 这样的工具,我们只投入时间和精力来标注数据集(而 Prodigy 提供的界面甚至使这个过程变得更简单)。AutoNLP 为我们节省了大量的时间和精力:我们不必去弄清楚该使用哪些模型、如何训练它们、如何评估它们、如何调整参数、使用哪种优化器和调度器、预处理、后处理等等。我们只需要标注数据集,让 AutoNLP 完成其他所有工作。
我们相信,借助 AutoNLP 和 Prodigy 这样的工具,创建数据和最先进的模型变得非常容易。而且由于整个过程几乎不需要任何编码,即使没有编码背景的人也可以创建通常不对公众开放的数据集,使用 AutoNLP 训练自己的模型,并与社区中的其他人分享模型(或者仅仅用于他们自己的研究/业务)。
我们已经开源了使用此过程创建的最佳模型。你可以在此处尝试。标注好的数据集也可以在此处下载。
模型之所以能达到最先进水平,完全归功于它们所训练的数据。

