优化故事:Bloom 推理






本文将带您了解我们如何构建高效推理服务器,为 https://huggingface.co/bigscience/bloom 提供支持的幕后故事。
我们在数周内将延迟降低了5倍(吞吐量增加了50倍)。我们想分享为实现如此显著的速度提升所经历的所有困难和史诗般的胜利。
许多不同的人在多个阶段参与其中,因此本文不会涵盖所有内容。请大家多多包涵,有些内容可能已经过时或完全错误,因为我们仍在学习如何优化超大型模型,并且新的硬件功能和内容不断涌现。
如果您最喜欢的优化方法没有被讨论或被不正确地呈现,我们深表歉意,请与我们分享,我们非常乐意尝试新事物并纠正我们的错误。
创建 BLOOM
这不言而喻,如果没有最初可访问的大型模型,也就没有优化其推理的真正理由。这是一项由许多不同人共同完成的非凡努力。
为了在训练期间最大化 GPU 利用率,我们探索了几种解决方案,最终选择 Megatron-Deepspeed 来训练最终模型。这意味着原始代码不一定与 transformers 库兼容。
移植到transformers
由于原始训练代码,我们着手做了一件我们经常做的事情:将现有模型移植到 transformers。目标是从训练代码中提取相关部分并在 transformers 中实现。这项工作由 Younes 负责。这绝不是一项小工作,因为它花费了将近一个月的时间和 200 次提交才完成。
有几点需要注意,它们将在后面再次提及。
我们需要有更小的模型 bigscience/bigscience-small-testing 和 bigscience/bloom-560m。这非常重要,因为它们更小,所以使用它们时一切都更快。
首先,你必须放弃最终能精确到字节地得到相同 logits 的希望。PyTorch 版本可能会改变内核并引入细微差异,而不同的硬件由于架构不同也可能产生不同的结果(而且出于成本考虑,你可能不想一直在一台 A100 GPU 上进行开发)。
为所有模型建立一套良好的严格测试套件非常重要
我们发现的最佳测试是使用一组固定的提示。你知道提示,你也知道需要确定性地完成的文本,所以是贪婪的。如果两个生成是相同的,你基本上可以忽略小的 logits 差异。每当你看到偏差时,你需要进行调查。这可能是你的代码没有做它应该做的事情,或者你实际上超出了该模型的领域,因此模型对噪声更敏感。如果你有几个提示并且提示足够长,你就不太可能偶然地对所有提示都触发这种情况。提示越多越好,越长越好。
第一个模型(small-testing)和大型 Bloom 模型一样是 bfloat16 格式,所以一切都应该非常相似,但它训练不多或者表现不佳,因此输出波动很大。这意味着我们在这些生成测试中遇到了问题。第二个模型更稳定,但它是在 float16 而不是 bfloat16 中训练和保存的。这使得两者之间有更大的误差空间。
公平地说,bfloat16 -> float16 转换在推理模式下似乎是正常的(bfloat16 主要用于处理大梯度,而推理中不存在大梯度)。
在这一步中,我们发现并实现了一个重要的权衡。因为 Bloom 是在分布式设置中训练的,所以部分代码对线性层进行了张量并行化,这意味着在单个 GPU 上作为单个操作运行相同的操作会产生不同的结果。这花费了一段时间才确定,我们面临的选择是要么实现100%的兼容性但模型速度慢得多,要么在生成中接受很小的差异但运行速度快得多且代码更简单。我们选择了一个可配置的标志。
首次推理 (PP + Accelerate)
Note: Pipeline Parallelism (PP) means in this context that each GPU will own
some layers so each GPU will work on a given chunk of data before handing
it off to the next GPU.
现在我们有了可用的 transformers 干净版本,可以开始运行它了。
Bloom 是一个 352GB 的模型(bf16 中有 176B 个参数),我们需要至少那么多的 GPU RAM 才能使其适应。我们曾短暂探索过在小型机器上卸载到 CPU,但推理速度慢了几个数量级,所以我们放弃了。
然后我们想基本上使用 pipeline。所以这是内部测试,也是 API 始终在底层使用的东西。
然而 pipelines 不具备分布式感知能力(这不是它们的目标)。在简短讨论选项后,我们最终使用 accelerate 新创建的 device_map="auto" 来管理模型的 shards。我们不得不解决一些 bug,并稍微修改 transformers 代码以帮助 accelerate 完成正确的工作。
它的工作原理是,将transformer的各个层进行拆分,并将模型的一部分分配给每个GPU。因此,GPU0 完成工作后,将其交给GPU1,以此类推。
最终,通过在顶部构建一个小型HTTP服务器,我们能够开始提供Bloom(大型模型)服务!!
起点
但我们甚至还没有开始讨论优化呢!
我们实际上有很多事情要做,整个过程就像纸牌城堡。在优化过程中,我们将修改底层代码,确保不会以某种方式破坏模型非常重要,而且这比你想象的更容易做到。
所以我们现在处于优化的第一步,我们需要开始测量并持续测量性能。因此,我们需要考虑我们关心什么。对于一个支持多种选项的开放式推理服务器,我们期望用户发送带有不同参数的许多查询,而我们关心的是:
我们能同时服务的用户数量(吞吐量) 平均用户被服务需要多长时间(延迟)?
我们用 locust 编写了一个测试脚本,它正是如此。
from locust import HttpUser, between, task
from random import randrange, random
class QuickstartUser(HttpUser):
wait_time = between(1, 5)
@task
def bloom_small(self):
sentence = "Translate to chinese. EN: I like soup. CN: "
self.client.post(
"/generate",
json={
"inputs": sentence[: randrange(1, len(sentence))],
"parameters": {"max_new_tokens": 20, "seed": random()},
},
)
@task
def bloom_small(self):
sentence = "Translate to chinese. EN: I like soup. CN: "
self.client.post(
"/generate",
json={
"inputs": sentence[: randrange(1, len(sentence))],
"parameters": {
"max_new_tokens": 20,
"do_sample": True,
"top_p": 0.9,
"seed": random(),
},
},
)
注意:这并非我们使用的最好或唯一的负载测试,但它始终是第一个运行的,以便在不同方法之间进行公平比较。在此基准测试中表现最佳并不意味着它是最佳解决方案。除了实际的现实世界性能外,还需要使用其他更复杂的场景。
我们希望观察各种实现的启动过程,并确保在负载下服务器能够正常进行熔断。熔断意味着服务器可以(快速地)响应,表示它不会回答您的查询,因为同时尝试使用它的人太多。这对于避免“死亡拥抱”至关重要。
在此基准测试中,初始性能(在 GCP 上使用 16xA100 40Go 机器,这是全程使用的机器)为:
请求/秒:0.3(吞吐量) 延迟:350毫秒/token(延迟)
这些数字并不理想。在开始工作之前,让我们估计一下我们能想象到的最佳成绩。操作数量的公式是 24Bsh^2 + 4𝐵s^2h24Bsh^2 + 4𝐵s^2h,其中 B 是批次大小,s 是序列长度,h 是隐藏维度。
我们来计算一下,单次前向传播得到 17 TFlop。查看 A100 的规格,它声称单卡 312 TFLOPS。这意味着单个 GPU 理论上可以达到 17 / 312 = 54ms/token。我们使用了 16 个这样的 GPU,因此在整台机器上是 3ms/token。这些数字请持保留态度,因为永远不可能达到这些数字,而且实际性能很少与规格相符。此外,如果计算不是您的限制因素,那么这不是您可以达到的最低点。知道您离目标有多远是很好的实践。在这种情况下,我们相差两个数量级,所以距离很远。此外,这个估计将所有浮点运算都用于延迟,这意味着一次只能处理一个请求(这没关系,因为您正在最大限度地利用您的机器,所以没有太多其他事情可以做,但是我们可以通过批处理更容易地获得更高的延迟和吞吐量)。
探索多种途径
Note: Tensor Parallelism (TP) means in this context that each GPU will own
part of the weights, so ALL gpus are active all the time and do less work.
Usually this comes with a very slight overhead that some work is duplicated
and more importantly that the GPUs regularly have to communicate to each other
their results to continue the computation
现在我们对现状有了很好的了解,是时候开始工作了。
我们根据团队成员和各自的知识尝试了许多不同的方法。
所有的努力都值得单独写一篇博客文章,所以我将只列出它们,解释一些最终的经验教训,并深入探讨当前服务器中使用的细节。从流水线并行(PP)到张量并行(TP)是延迟方面一个重要的变化。每个 GPU 将拥有部分参数,并且所有 GPU 将同时工作。因此,延迟应该会大幅降低,但代价是通信开销,因为它们需要定期相互通信结果。
值得注意的是,这是一个非常广泛的方法范围,其目的是有意地更多地了解每种工具以及它如何适应未来的工作。
将代码移植到JAX/Flax以在TPU上运行:
- 预计选择并行类型会更容易。因此,TP应该更容易测试。这是Jax设计的一大优点。
- 对硬件的限制更多,TPU 上的性能可能优于 GPU,并且 TPU 的供应商选择较少。
- 缺点是需要再次移植。不过,在我们的库中,无论如何都会受到欢迎。
结果
- 移植并不是一件容易的事,因为有些条件和内核很难正确复现。不过,仍然可以管理。
- 并行化一旦移植就很容易实现,值得称赞的是 Jax 的说法是正确的。
- 事实证明,Ray/与TPU工作器通信对我们来说是一个真正的痛苦。我们不知道是工具的问题、网络问题,还是仅仅是我们缺乏知识,但它比我们预期的更严重地减慢了实验和工作。我们启动了一个需要5分钟运行的实验,等待了5分钟什么也没发生,10分钟后仍然什么也没有,结果发现某个工作器宕机/没有响应,我们不得不手动进入,找出发生了什么,修复它,重启一些东西,然后重新启动,就这样我们浪费了半个小时。重复足够多次,浪费的时间就会迅速累积。我们想强调的是,这不一定是对我们使用的工具的批评,而是我们所拥有的主观体验仍然存在。
- 无法控制编译 一旦我们让它运行起来,我们尝试了几种设置,以找出哪种最适合我们设想的推理,结果发现很难从设置中猜测延迟/吞吐量会发生什么。例如,当 batch_size=1(每个请求/用户都是独立的)时,我们有 0.3 rps,延迟为 15ms/token(不要过多与本文中的其他数字进行比较,因为这是在不同的机器上,配置文件也大不相同),这很棒,但总吞吐量并不比我们使用旧代码时好多少。因此,我们决定添加批处理,当 BS=2 时,延迟增加了 5 倍,而吞吐量只增加了 2 倍……经过进一步调查,结果发现,直到 batch_size=16,每个 batch_size 都具有相同的延迟配置文件。因此,我们可以以 5 倍的延迟成本获得 16 倍的吞吐量。这还不错,但从数字来看,我们更喜欢更精细的控制。我们追求的数字源自 100ms、1s、10s、1mn 规则。
使用 ONNX/TRT 或其他编译方法
- 它们应该处理大部分优化工作
- 缺点是,通常需要手动处理并行性。
结果
- 结果发现,为了能够追踪/即时编译/导出(trace/jit/export)数据,我们需要重构 PyTorch 的一部分,以便它能轻松地与纯 PyTorch 方法融合。总的来说,我们发现通过留在 PyTorch 世界中,我们可以获得所需的大部分优化,从而保持灵活性,而无需投入过多的编码工作。另一点需要注意的是,由于我们是在 GPU 上运行,并且文本生成涉及多次前向传播,我们需要张量留在 GPU 上。有时,将张量发送到某个库,获得结果,执行 logits 计算(如 argmax 或采样),然后再将其反馈回去会很困难。将循环放入外部库意味着像 Jax 一样失去灵活性,因此这在我们的用例中没有被考虑。
DeepSpeed
- 这是支持训练的技术,用于推理似乎也很公平。
- 缺点是,以前从未用于/准备用于推理。
结果
- 我们很快就取得了令人印象深刻的结果,这大致与我们目前运行的最后一次迭代相同。
- 我们必须发明一种将 web 服务器(处理并发)置于 DeepSpeed 之上的方法,DeepSpeed 也拥有多个进程(每个 GPU 一个)。由于存在一个出色的库 Mii,它不符合我们设想的极其灵活的目标,但我们现在可能已经开始在其之上进行开发。(当前的解决方案将在稍后讨论)。
- 我们遇到的 DeepSpeed 最大的问题是缺乏稳定性。我们在 CUDA 11.4 上运行它时遇到了问题,而代码是为 11.6 构建的。我们从未真正解决的长期存在的问题是,会定期发生内核崩溃(Cuda 非法访问、维度不匹配等)。我们修复了其中很多问题,但在我们的 web 服务器的压力下,我们始终无法实现稳定性。尽管如此,我还是要感谢帮助我们的 Microsoft 团队,我们进行了非常愉快的对话,加深了我们对正在发生的事情的理解,并为我们后续工作提供了真正的见解。
- 我感觉的一个痛点是,我们的团队主要在欧洲,而微软在加利福尼亚,所以合作在时间上很棘手,我们可能因此浪费了一大块时间。这与技术部分无关,但承认合作的组织部分也同样重要是件好事。
- 另一点需要注意的是,DeepSpeed 依赖于
transformers来注入其优化,由于我们几乎持续更新代码,这使得 DeepSpeed 团队很难在我们的main分支上保持代码正常运行。很抱歉给您带来了不便,我想这就是为什么它被称为前沿技术的原因吧。
Web服务器构想
- 鉴于我们将运行一个免费服务器,用户将发送长文本、短文本,需要少量 token 或完整食谱,每个都带有不同的参数,因此这里必须做一些事情。
结果
- 我们使用出色的绑定 tch-rs 用
Rust重写了所有代码。Rust 的目标并非性能提升,而是对并行性(线程/进程)的更精细控制,以及在 web 服务器并发性和 PyTorch 并发性上进行更精细的调整。Python 因其 GIL 而臭名昭著,难以处理低级细节。 - 结果发现,大部分痛苦来自移植,之后实验就轻松多了。我们发现,只要对循环有足够的控制,即使在各种具有不同属性的请求的背景下,我们也能为每个人提供出色的性能。代码供好奇者参考,但它不附带任何支持或完善的文档。
- 它投入生产了几周,因为它对并行性更宽松,我们可以更有效地利用 GPU(使用 GPU0 处理请求 1,而 GPU1 处理请求 0)。我们将 RPS 从 0.3 提升到约 2.5,同时保持相同的延迟。最佳情况本应是将吞吐量提高 16 倍,但这里显示的数字是实际工作负载测量值,所以这还算不错。
纯 PyTorch
- 纯粹修改现有代码以使其更快,例如删除
reshape操作,使用更优化的内核等。 - 缺点是,我们必须自己编写 TP,而且我们有一个限制,即代码仍然符合我们的库(大部分)。
结果
- 下一章。
最终路线:PyTorch + TP + 1 个自定义内核 + torch.jit.script
编写更高效的 PyTorch 代码
列表上的第一项是删除最初实现中不必要的操作。有些可以通过查看代码并找出明显缺陷来发现。
- Alibi 在 Bloom 中用于添加位置嵌入,它在太多地方被计算,我们可以只计算一次,并且更有效率。
这是一个10倍的速度提升,最新版本还包含了填充!由于这一步只计算一次,实际速度并不重要,但总的来说减少操作次数和张量创建是一个好的方向。
当您开始分析时,其他部分会更清晰地展现出来,我们广泛使用了tensorboard 扩展
这提供了这种类型的图像,可以提供见解。
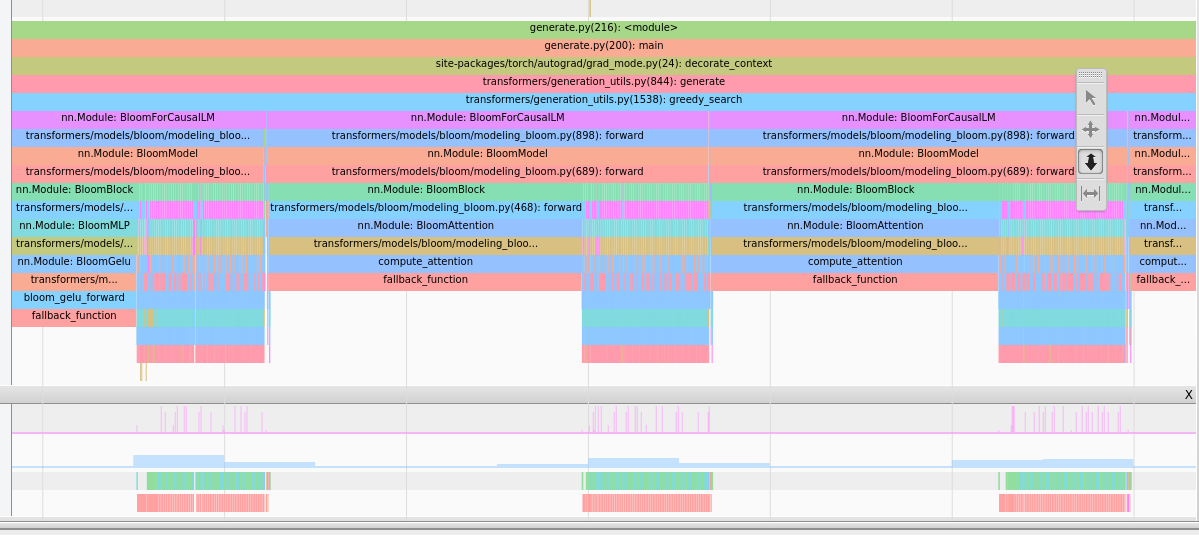 注意力占用大量时间,请注意这是 CPU 视图,因此长条不代表时间长,而是表示 CPU 正在等待上一步的 GPU 结果。
注意力占用大量时间,请注意这是 CPU 视图,因此长条不代表时间长,而是表示 CPU 正在等待上一步的 GPU 结果。 我们看到 `baddbmm` 之前有许多 `cat` 操作。
我们看到 `baddbmm` 之前有许多 `cat` 操作。例如,通过移除大量 reshape/transpose,我们发现: - 注意力是热点路径(这是预期的,但验证总是好的)。 - 在注意力中,由于大量的 reshape,许多内核实际上是复制操作。 - 我们可以通过重构权重本身和过去来移除 reshape。这是一个破坏性更改,但它确实显著提高了性能!
支持 TP
好的,我们已经移除了大部分唾手可得的优化,现在在 PP 中,延迟大致从 350ms/token 降低到 300ms/token。这使得延迟降低了 15%,但实际上它提供了更多,不过我们最初的测量并不十分严谨,所以就暂且沿用这个数字。
然后我们着手提供了一个 TP 实现。事实证明,它比我们预期的要快得多,实现只花了一个(有经验的)开发人员半天的时间。结果在这里。我们还能够复用其他项目的代码,这很有帮助。
延迟直接从 300ms/token 降至 91ms/token,这极大地改善了用户体验。一个简单的 20 token 请求从 6 秒缩短到 2 秒,从“缓慢”体验变为“略有延迟”。
此外,吞吐量也大幅提高到 10 RPS。吞吐量的提高是因为 batch_size=1 的查询与 batch_size=32 的查询花费相同的时间,此时吞吐量基本上在延迟成本上是“免费”的。
唾手可得的优化
现在我们有了 TP 实现,可以再次开始分析和优化。这是一个足够显著的转变,我们必须重新开始。
最突出的一点是,同步(ncclAllReduce)开始在负载中占据主导地位,这是预期的,这是同步部分,它确实需要一些时间。我们从未尝试过研究和优化这一点,因为它已经使用了 nccl,但那里可能仍然有一些改进空间。我们认为这很难做得更好。
第二点是,Gelu 运算符启动了许多逐元素内核,总的来说,它占用的计算份额比我们预期的要大。
我们进行了更改
def bloom_gelu_forward(x):
return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
到
@torch.jit.script
def bloom_gelu_forward(x):
return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
这将操作从多个小的逐元素内核(以及因此产生的张量复制)转换为单个内核操作!
这使得延迟从 91ms/token 降低到 81ms/token,直接提升了 10%!
但请注意,这并非可以随意使用的神奇黑箱,内核融合不一定会发生,或者之前使用的操作可能已经极其高效。
我们发现它效果很好的地方:
- 您有大量小/逐元素操作
- 您有一个热点,其中有一些难以去除的重塑和复制操作
- 当融合发生时。
史诗级失败
在我们的测试期间,我们也曾发现 Rust 服务器的延迟比 Python 服务器低 25%。这相当奇怪,但由于测量结果一致,并且因为移除内核可以提高速度,我们当时认为降低 Python 开销可能会带来不错的提升。
我们启动了一个为期 3 天的工作,旨在重新实现 torch.distributed 的必要部分,以便在 Rust 环境中运行 nccl-rs。我们让版本运行起来了,但与 Python 版本相比,生成结果有些异常。在调查问题期间,我们发现……我们忘记在 PyTorch 测量中移除分析器了……
那是一次史诗般的失败,因为移除它后,我们又回到了那 25% 的性能,然后两个代码运行速度都一样快。这正是我们最初预期的,Python 不应该成为性能瓶颈,因为它主要运行的是 torch cpp 的代码。最终,3 天的时间并不是世界末日,将来某个时候它可能还会派上用场,但仍然相当糟糕。在进行优化时,进行错误或具有误导性的测量是相当常见的,这最终会令人失望,甚至对整体产品有害。这就是为什么小步进行并尽快对结果抱有期望有助于控制这种风险。
另一个我们需要格外小心的地方是初始前向传播(没有 past)和后续前向传播(有 past)。如果你优化了第一个,你很可能会减慢后面更重要且占大部分运行时间的传播。另一个相当常见的罪魁祸首是测量的是 CPU 时间,而不是实际的 CUDA 时间,所以你在运行时需要 torch.cuda.synchronize() 以确保内核完成。
自定义内核
到目前为止,我们已经实现了接近 DeepSpeed 的性能,而无需 PyTorch 之外的任何自定义代码!相当棒。我们也不必在运行时批处理大小的灵活性上做出任何妥协!
但鉴于 DeepSpeed 的经验,我们希望尝试编写一个自定义内核,以在 torch.jit.script 无法为我们完成的 hot path 中融合一些操作。本质上是以下两行:
attn_weights = attention_scores.masked_fill_(attention_mask, torch.finfo(attention_scores.dtype).min)
attention_probs = F.softmax(attn_weights, dim=-1, dtype=torch.float32).to(input_dtype)
第一个 mask fill 会创建一个新的张量,它在这里只是为了告诉 softmax 运算符忽略这些值。此外,softmax 需要在 float32 上计算(为了稳定性),但在自定义内核中,我们可以限制必要的向上转换量,因此我们将它们限制在实际的总和和累加值上。
代码可以在此处找到。请记住,我们只有一个 GPU 架构作为目标,因此我们可以专注于此,而且我们(尚)不是编写内核的专家,因此可能有更好的方法来完成此操作。
这个自定义内核又带来了 10% 的延迟提升,从 81ms/token 降至 71ms/token 的延迟。同时保持了我们的灵活性。
之后,我们研究并探索了其他一些方法,例如融合更多算子、移除其他重塑操作,或将它们放置在其他位置。但没有任何尝试能对最终版本产生足够显著的影响。
Web服务器部分
就像 Rust 版本一样,我们必须实现带有不同参数的请求的批处理。由于我们处于 PyTorch 世界中,我们几乎完全控制正在发生的事情。由于我们处于 Python 中,我们有一个限制因素,即 torch.distributed 需要在多个进程而不是线程上运行,这意味着进程之间通信略微困难。最终,我们选择通过 Redis pub/sub 传输原始字符串,一次性将请求分发给所有进程。由于我们在不同的进程中,这样做比传输张量(它们更大)更容易。
然后我们不得不放弃使用 generate,因为这会将参数应用于批处理的所有成员,而我们实际上希望应用不同的参数集。幸运的是,我们可以重用较低级别的项,例如 LogitsProcessor,从而为我们节省大量工作。
所以我们重构了一个 generate 函数,它接受一个参数列表,并将其应用于批处理的每个成员。
最终用户体验的另一个非常重要的方面是延迟。由于我们为不同的请求设置了不同的参数集,我们可能会遇到以下情况:
20 token 请求需要 1.5 秒,而 250 token 请求需要 18 秒。如果一直进行批处理,我们就会让请求 250 token 的用户等待 18 秒,这在他看来就像我们以 900ms/token 的速度运行,这相当慢!
由于我们身处一个具有极高灵活性的 PyTorch 世界,我们可以做的是,一旦生成了前 20 个 token,就立即从批处理中提取第一个请求,并在请求的 1.5 秒内将其返回给该用户!我们还节省了相当于 230 个 token 的计算量。
因此,灵活性对于获得最佳延迟至关重要。
最后说明和疯狂想法
优化是一项永无止境的工作,与其他项目一样,20% 的工作通常能带来 80% 的结果。在某个时候,我们开始采用一种小型测试策略来找出我们的一些想法的潜在产出,如果测试没有产生显著结果,那么我们就放弃这个想法。一天带来 10% 的增长很有价值,两周带来 10 倍的增长也很有价值。两周带来 10% 的增长就不那么有趣了。
您尝试过...吗?
我们知道存在但由于各种原因未使用的事物。可能是我们觉得它不适合我们的用例,工作量太大,收益不够可观,甚至仅仅是因为我们有太多选项可以尝试,由于时间不足而放弃了一些选项。以下内容不分先后顺序。
- Cuda 图
- nvFuser (这就是
torch.jit.script的动力来源,所以我们确实使用了它。) - FasterTransformer
- Nvidia 的 Triton
- XLA (Jax 也在使用 xla !)
- torch.fx
- TensorRT
如果您最喜欢的工具在此处缺失,或者您认为我们遗漏了可能有用且重要的内容,请随时与我们联系!
Flash attention
我们曾简要研究过集成 Flash Attention,虽然它在第一次前向传播(没有 past_key_values)时表现极佳,但在使用 past_key_values 时并没有带来那么大的改进。由于我们需要对其进行调整,使其包含 alibi 张量进行计算,因此我们决定暂时不做这项工作(至少目前如此)。
OpenAI Triton
Triton 是一个构建 Python 自定义内核的优秀框架。我们希望更多地使用它,但到目前为止还没有。我们很期待看到它是否比我们的 Cuda 内核表现更好。当我们考虑这部分的选择时,直接用 Cuda 编写似乎是实现我们目标的最短路径。
填充和重塑
如本文所述,每次张量复制都有成本,而生产运行的另一个隐藏成本是填充。当两个查询长度差异很大时,您必须填充(使用虚拟 token)以使其适应正方形。这可能会导致许多不必要的计算。更多信息。
理想情况下,我们应该完全避免这些计算,并且永远不要进行重塑。Tensorflow 有 RaggedTensor 的概念,PyTorch 有 Nested tensors。这两者似乎都不如常规张量那么简化,但可能会让我们进行更少的计算,这始终是一个胜利。
在一个理想的世界里,整个推理都将用 CUDA 或纯 GPU 实现。考虑到我们融合操作时获得的性能提升,这看起来很理想。但它能达到什么程度,我们一无所知。如果更聪明的 GPU 人有想法,我们洗耳恭听!
致谢
所有这些工作都是许多 HF 团队成员合作的成果。排名不分先后,@ThomasWang @stas @Nouamane @Suraj @Sanchit @Patrick @Younes @Sylvain @Jeff (Microsoft) @Reza 以及所有 BigScience 组织。

