⚗️ 🧑🏼🌾 让我们一起构建领域特定数据集







社区由不同的领域和专业知识组成。我们使用语言模型执行需要专业知识的复杂任务。因此,让我们构建反映这种深度和多样性的数据集,以便我们能够训练和评估同样多样化的模型!
这是一个协作项目,旨在为训练模型引导您的领域特定数据集。目标是创建一个工具共享,以便社区用户可以与领域专家协作,并发布全新的数据集。
TL;DR
我们正在构建领域特定数据集!您需要一名机器学习工程师和一名领域专家。他们可以是同一个人。请访问下面的这个空间开始构建您的数据集。
为什么我们需要领域特定数据集?
大型语言模型(LLMs)正越来越多地被用作人类参与者在社会科学、用户测试、标注任务和意见调查等领域的经济替代品。然而,LLMs 在复制特定人类细微差别和专业知识方面的效用受到训练限制。模型在通常存在偏见、不完整或无法代表其旨在复制的各种人类经验的大规模数据集上进行训练。这个问题影响了特定专业领域以及训练数据中代表性不足的群体。此外,构建能够代表该领域的人工数据集有助于提高模型在该领域的性能。
这个项目的目标是什么?
该项目的目标是与领域专家分享和协作,以创建可用于训练模型的领域特定数据集。我们旨在创建一套工具,帮助用户与领域专家协作创建能够代表该领域的数据集。我们旨在在中心开放共享数据集,并分享构建这些数据集的工具和技能。
我如何贡献?
🧑🏼🔬 如果您是领域专家,您可以通过分享您的专业知识并与我们协作来创建领域特定数据集。我们正在与用户合作开发应用程序,帮助您定义种子数据并创建数据集。我们还在开发帮助您标注数据集和提高数据集质量的工具。
🧑🏻🔧 如果您是一名(有抱负的)机器学习工程师,您可以设置项目及其工具。您可以运行合成数据生成管道。甚至可能着手训练模型。
它将如何运作?
我制作了这个端到端过程的视频演练。它大约有 20 分钟,并指导您了解可能需要考虑的一些事项,以获得可用的数据集

1. 选择一个领域并寻找合作者
我们首先选择一个领域并寻找可以帮助我们创建数据集的合作者。
🧑🏼🔬 如果您是领域专家,您可以找一位机器学习工程师帮助您创建数据集。
🧑🏻🔧 如果您是机器学习工程师,您可以找一位领域专家帮助您创建数据集。
🧑🚀 如果您两者兼顾,您可以从定义种子数据和创建数据集开始。
2. 设置您的项目
首先,您需要设置项目及其工具。为此,我们使用 此应用程序
3. 定义领域知识
接下来,我们需要让领域专家定义种子数据。这是用于创建数据集的数据。一旦定义了种子数据,我们将其添加到数据集存储库中。
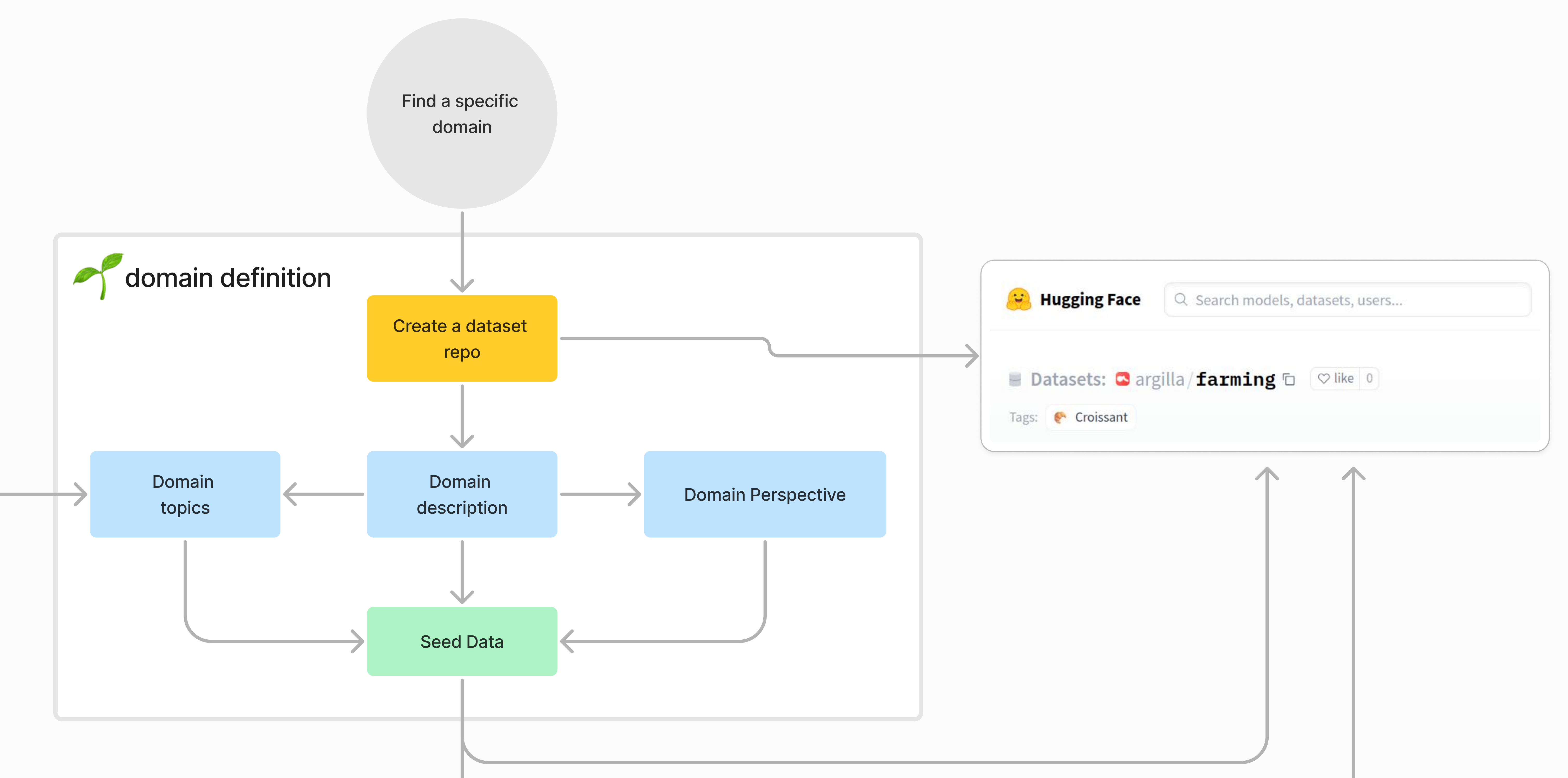
领域主题是领域专家希望包含在数据集中的主题。例如,如果领域是农业,领域主题可以是“土壤”、“作物”、“天气”等。
领域描述是对该领域的描述。例如,如果领域是农业,领域描述可以是“农业是种植作物和饲养牲畜以获取食物、纤维、生物燃料、药用植物和其他用于维持和改善人类生活的产品。”
领域视角是领域专家希望包含在数据集中的视角。例如,如果领域是农业,领域视角可以是“农民”、“农业科学家”、“农业经济学家”等。
4. 使用 distilabel 生成数据集
接下来,我们可以从种子数据生成数据集。
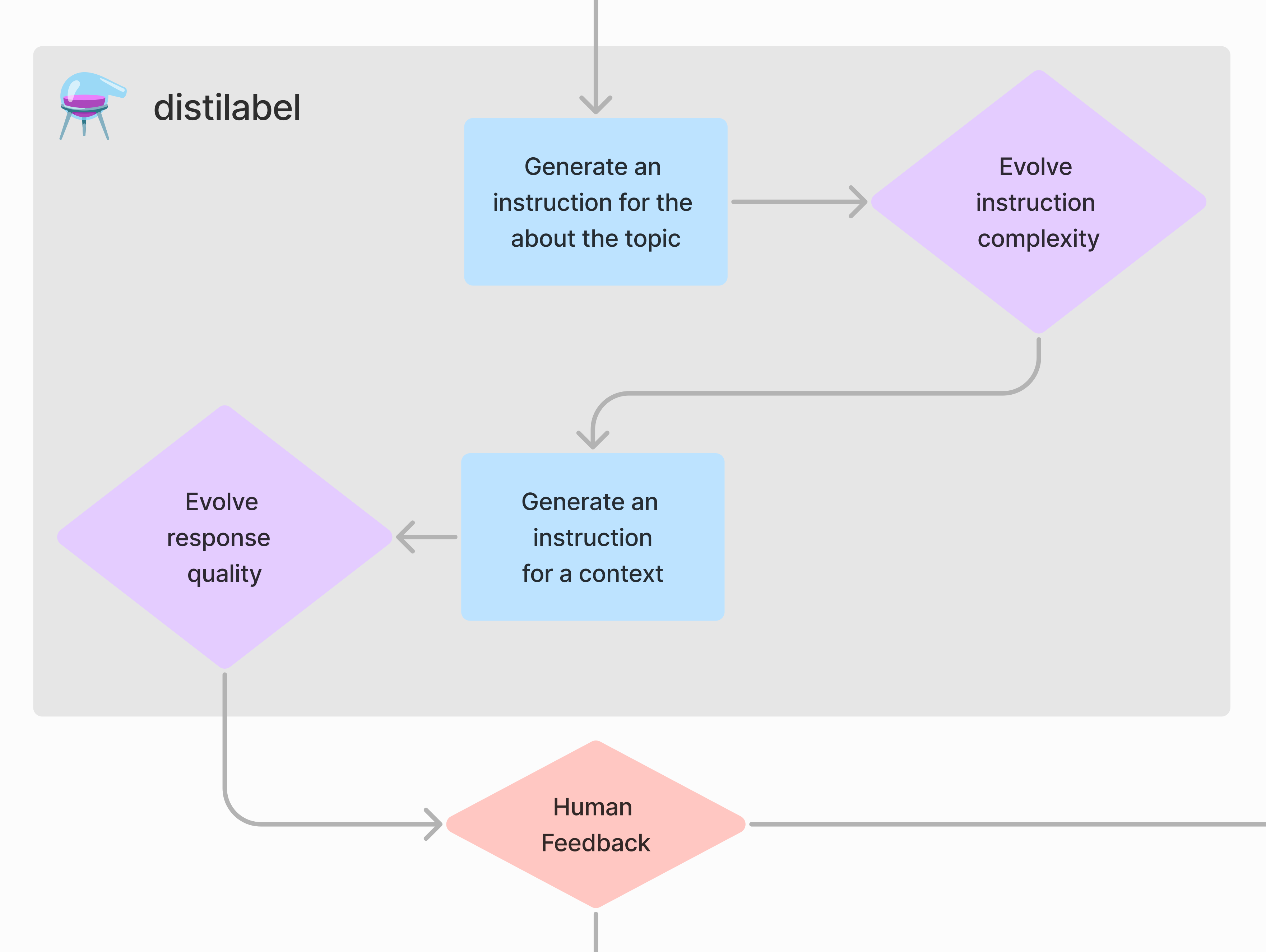
- 该管道获取主题和视角并为数据集生成指令,然后大型语言模型(LLM)会演进这些指令以创建更多指令。
- 该管道获取指令并为数据集生成响应,然后 LLM 会演进这些响应以创建更高质量的响应。
5. 审查和分享数据集
最后,管道将数据集推送到中心和 Argilla 空间。然后,领域专家可以通过标注数据集和提高数据集质量来审查数据集。完成后,机器学习工程师可以将数据集推送到中心。
🧑🚀 开始吧!
要开始您的项目,请访问这个空间。应用程序中重复提供了说明。





