投资性能:利用 LLM 洞察力微调小型模型——CFM 案例研究













概述:本文深入探讨了资本基金管理公司 (CFM) 如何利用开源大型语言模型 (LLM) 和 Hugging Face (HF) 生态系统来优化金融数据的命名实体识别 (NER)。通过利用LLM 辅助标注以及HF 推理端点并使用Argilla改进数据,该团队将准确性提高了6.4%,并降低了运营成本,实现了比单独使用大型 LLM 便宜 80 倍的解决方案。
在这篇文章中,您将学习到
- 如何使用 LLM 进行高效数据标注
- 利用 LLM 洞察力微调紧凑模型的步骤
- 在 Hugging Face 推理端点上部署模型以实现可扩展的 NER 应用程序
这种结构化方法兼具准确性和成本效益,非常适合实际的金融应用。
| 模型 | F1-分数(零样本) | F1-分数(微调) | 推理成本(每小时) | 成本效益 |
|---|---|---|---|---|
| GLiNER | 87.0% | 93.4% | $0.50 (GPU) / $0.10 (CPU) | 便宜高达 80 倍 |
| SpanMarker | 47.0% | 90.1% | $0.50 (GPU) / $0.10 (CPU) | 便宜高达 80 倍 |
| Llama 3.1-8b | 88.0% | 不适用 | $4.00 | 中等 |
| Llama 3.1-70b | 95.0% | 不适用 | $8.00 | 高成本 |
Capital Fund Management (CFM) 是一家总部位于巴黎的另类投资管理公司,在纽约市和伦敦也设有团队,目前管理的总资产达 155 亿美元。
CFM 采用科学的金融方法,利用量化和系统化方法制定卓越的投资策略。
CFM 一直与 合作,以了解机器学习的最新进展,并利用开源技术的强大功能来支持其广泛的金融应用。此次合作的主要目标之一是探索 CFM 如何有效利用开源大型语言模型 (LLM) 来增强其现有机器学习用例。量化对冲基金依靠大量数据来为买卖特定金融产品提供决策依据。除了金融市场(例如价格)的标准数据源外,对冲基金也越来越多地从新闻文章等替代数据中提取洞察力。将新闻纳入全自动化交易策略面临的一个主要挑战是准确识别文章中提及的产品或实体(例如,公司、股票、货币)。虽然 CFM 的数据提供商提供这些标签,但它们可能不完整,需要进一步验证。
CFM 探索了多种方法来改进金融实体识别,包括使用 LLM 和小型模型的零样本 NER、使用 Hugging Face 推理端点和 Argilla 的 LLM 辅助数据标注,以及在精选数据集上微调小型模型。这些方法不仅利用了大型模型的多功能性,还解决了实际金融应用中成本和可扩展性的挑战。
在开源模型中,Meta 的 Llama 3.1 系列因其在各项基准测试中的强大性能而脱颖而出,使其成为生成合成注释的首选。这些 LLM 在创建高质量标注数据集方面发挥了关键作用,结合了自动化和人工专业知识,以简化标注过程并提高金融 NER 任务中的模型性能。
目录
金融新闻和股价整合数据集上的命名实体识别 (NER)
我们在这个用例中关注的重点是从金融新闻和股价整合数据集 (FNSPID) (FNSPID) 中提取新闻标题中的公司名称。它由新闻标题和与彭博社、路透社、Benzinga 等多个来源对应的股票代码相关的文章组成。在分析了各种新闻来源后,我们发现来自 Benzinga 的新闻没有缺失的股票代码值。该数据集的子集包含约 90 万个样本。因此,我们决定将数据集缩小到 Benzinga 标题,以进行更一致和可靠的分析。
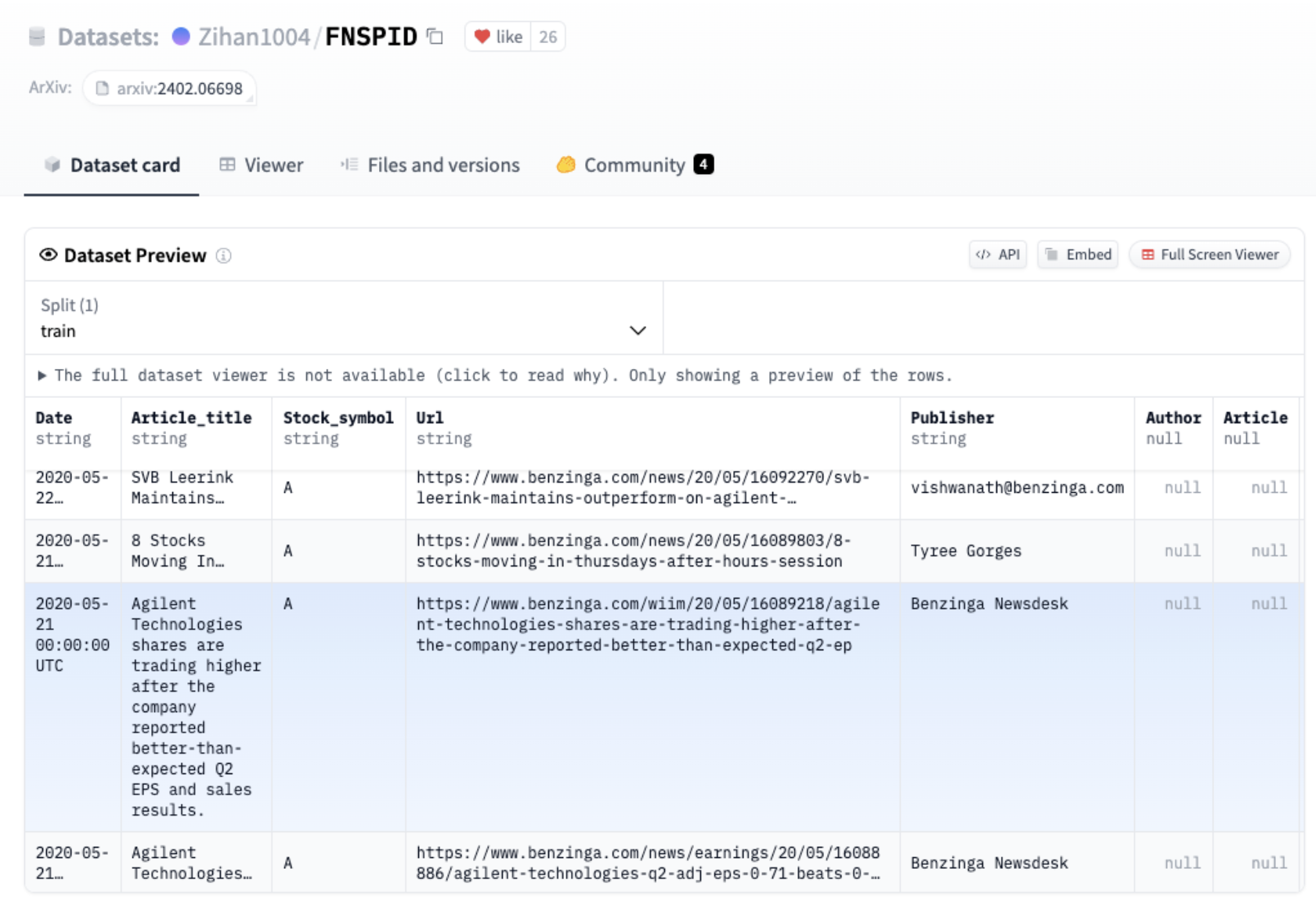
FNSPID 数据集预览
{"example 1": "Black Diamond Stock Falling After Tweet"} -> Black Diamond
{"example 2": "Dun & Bradstreet Acquires Avention For $150M"} -> Dun & Bradstreet, Avention
{"example 3": "Fast Money Picks For April 27"} -> No company
任务的示例样本和目标预测
Llama 辅助的数据标注
为了有效比较不同的方法,我们首先需要整合一个可靠的数据集,作为评估候选方法的基础。该数据集将用于测试模型在零样本设置中的性能,并作为微调的基础。
我们使用 Llama 辅助数据标注来简化和增强标注过程,让 Llama 3.1 为数据集样本生成标签。然后使用开源数据标注平台 Argilla 手动审查这些自动生成的标签。这种方法使我们能够加快标注过程,同时确保标注的质量。
使用 Hugging Face 推理端点 部署 Llama3.1-70b-Instruct
为了安全快速地访问 Llama3.1-70-Instruct 部署,我们选择了 Hugging Face 推理端点。
Hugging Face 推理端点为在生产环境中部署机器学习模型提供了简单安全的解决方案。它们使开发人员和数据科学家能够构建 AI 应用程序,而无需管理基础设施,将部署简化到只需几次点击即可完成。
要访问推理端点,我们以 CapitalFundManagement 组织的成员身份登录 Hugging Face Hub,然后访问服务网址 https://ui.endpoints.huggingface.co。要开始新的部署,我们点击 New,然后选择 meta-llama/Llama-3.1-70B-Instruct。
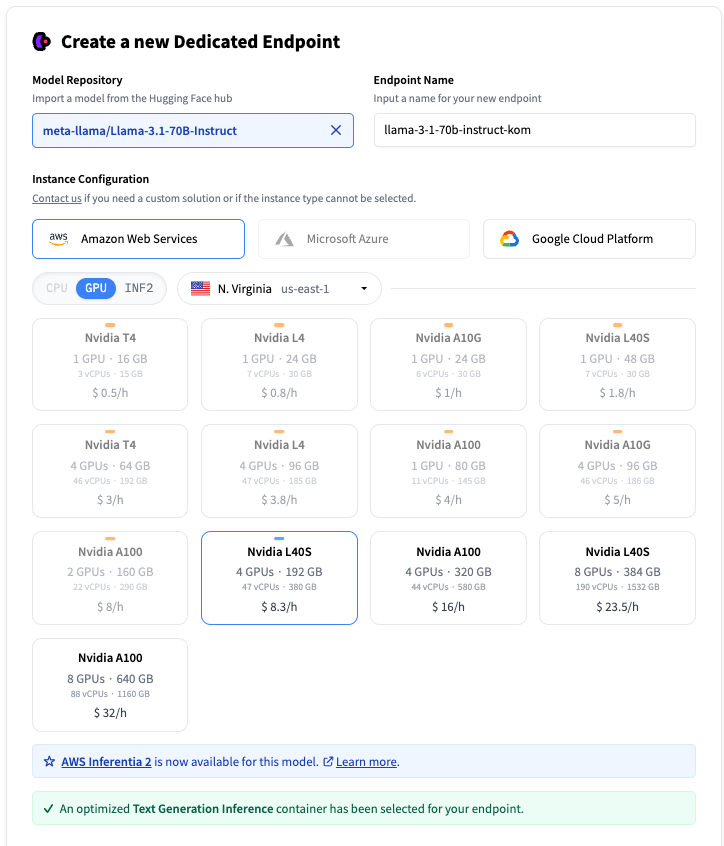
在推理端点 UI 上创建端点
您可以选择硬件将托管在哪个云提供商、区域以及实例类型。推理端点会根据模型大小建议实例类型,该实例类型应足以运行模型。此处选择了一个带有 4 个 Nvidia L40S 的实例。当选择 LLM 时,会自动选择一个运行 文本生成推理 的容器,以优化推理。
点击“创建端点”后,部署即告创建,端点将在几分钟内准备就绪。有关推理端点设置的更多信息,请访问 https://huggingface.co/docs/inference-endpoints。
端点在推理端点 UI 上运行
一旦我们的端点运行起来,我们将使用提供的端点 URL 向其发送请求。
为 NER 提示 Llama
在发送请求之前,我们需要设计一个能够有效引导模型生成所需输出的提示。经过多轮测试,我们将提示构建为多个部分,以准确地处理任务:
角色定义:模型被定位为具有强大英语能力的金融专家。
任务说明:模型被指示提取新闻标题中提及的与股票相关的公司名称,同时排除标题中常见的股票指数。
预期输出:模型必须返回一个包含以下内容的字典:
"result":精确的公司名称或股票代码。"normalized_result":与"result"中对应的标准化公司名称。
少量样本示例:一系列输入-输出示例,用于演示预期行为并确保在不同输入之间保持一致的性能。这些示例帮助模型理解如何区分相关实体并正确格式化其输出。每个示例都展示了不同的标题结构,以使模型为各种实际情况做好准备。
SYSTEM_PROMPT = “””
###Instructions:###
You are a financial expert with excellent English skills.
Extract only the company names from the following headlines that are related to a stock discussed in the article linked to the headline.
Do not include stock indices such as "CAC40" or "Dow Jones".
##Expected Output:##
Return a dictionary with:
A key "result" containing a list of company names or stock symbols. Make sure to return them exactly as they are written in the text even if the original text has grammatical errors. If no companies or stocks are mentioned, return an empty list.
A key "normalized_result" containing the normalized company names corresponding to the entries in the "result" list, in the same order. This list should have the same size as the "result" list.
##Formatting:##
Do not return companies not mentioned in the text.
##Example Outputs##
Input: "There's A New Trading Tool That Allows Traders To Trade Cannabis With Leverage"
Output: {"result": [], "normalized_result": []}
Input: "We explain AAPL, TSLA, and MSFT report earnings"
Output: {"result": ["AAPL", "TSLA", "MSFT"], "normalized_result": ["Apple", "Tesla", "Microsoft"]}
Input: "10 Biggest Price Target Changes For Friday"
Output: {"result": [], "normalized_result": []}
Input: "'M' is For Microsoft, and Meh"
Output: {"result": ["Microsoft"], "normalized_result": ["Microsoft"]}
Input: "Black Diamond: The New North Face? (BDE, VFC, JAH, AGPDY.PK)"
Output: {"result": ['Black Diamond', 'North Face', 'BDE', 'VFC','JAH','AGPDY.PK'], "normalized_result": ['Black Diamond','The North Face', 'BPER Banca', 'VF Corporation','Jarden Corporation','AGP Diagnostics']}
“””
从端点获取预测
现在我们已经准备好了提示和端点,下一步是使用数据集中的标题发送请求。为了高效地完成此操作,我们将使用 `huggingface_hub` 库中的 `AsyncInferenceClient`。这是 `InferenceClient` 的异步版本,基于 `asyncio` 和 `aiohttp` 构建。它允许我们向端点发送多个并发请求,从而使数据集的处理更快、更高效。
from huggingface_hub import AsyncInferenceClient
# Initialize the Hugging Face AsyncInferenceClient
client = AsyncInferenceClient(base_url="https://your-endpoint-url.huggingface.cloud")
为确保模型返回结构化输出,我们将使用带有特定 Pydantic 模式 `Companies` 的引导。
from pydantic import BaseModel
from typing import List, Dict, Any
# This class defines the expected structure for the output using Pydantic.
class Companies(BaseModel):
"""
Pydantic model representing the expected LLM output.
Attributes:
result (List[str]): A list of company names or results from the LLM.
normalized_result (List[str]): A list of 'normalized' company names, i.e., processed/cleaned names.
"""
result: List[str]
normalized_result: List[str]
grammar: Dict[str, Any] = {
"type": "json_object",
"value": Companies.schema()
# This instructs the LLM to return a JSON with "result" and "normalized_result" as keys
}
我们还设置了生成参数
max_tokens: int = 512 # Maximum number of tokens to generate in the response
temperature: float = 0.1 # Controls randomness in the output (lower values are more deterministic)
现在我们定义用于向端点发送请求和解析输出的函数
async def llm_engine(messages: List[Dict[str, str]]) -> str:
"""
Function to send a request to the LLM endpoint and get a response.
Args:
messages (List[Dict[str, str]]): A list of messages to pass to the LLM.
Returns:
str: The content of the response message or 'failed' in case of an error.
"""
try:
# Send the request to the LLM endpoint asynchronously
response = await client.chat_completion(
messages=messages,
model="ENDPOINT", # Replace with your model endpoint
temperature=temperature,
response_format=grammar,
max_tokens=max_tokens
)
# Extract the content of the response message
answer: str = response.choices[0].message.content
return answer
except Exception as e:
# Handle any exceptions that occur during the request
print(f"Error in LLM engine: {e}")
return "failed"
def parse_llm_output(output_str: str) -> Dict[str, Any]:
"""
Parse the JSON-like output string from an LLM into a dictionary.
Args:
output_str (str): The string output from an LLM, expected to be in JSON format.
Returns:
Dict[str, Any]: A dictionary parsed from the input JSON string with a 'valid' flag.
"""
try:
# Parse the JSON string into a dictionary
result_dict: Dict[str, Any] = json.loads(output_str)
result_dict["valid"] = True
return result_dict
except json.JSONDecodeError as e:
# Handle JSON parsing errors and return a default structure
print(f"Error decoding JSON: {e}")
return {
"result": [output_str],
"normalized_result": [output_str],
"valid": False
}
我们用一个例子来测试端点
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": "Some stocks i like buying are AAPL, GOOG, AMZN, META"}
]
response = await llm_engine(messages)
print(parse_llm_output(response))
{"normalized_result": ["Apple", "Alphabet", "Amazon", "Meta Platforms"], "result": ["AAPL", "GOOG", "AMZN", "META"]}
现在,我们创建一个 `process_batch` 函数来处理以可管理批次发送请求,防止 API 端点过载或达到速率限制。这种批处理方法使我们能够高效地并发处理多个请求,而不会使服务器饱和,从而降低超时、拒绝请求或节流的风险。通过控制请求流,我们确保了稳定的性能、更快的响应时间以及更容易的错误处理,同时最大限度地提高了吞吐量。
import asyncio
async def process_batch(batch):
"""
Get the model output for a batch of samples.
This function processes a batch of samples by sending them to the LLM and
gathering the results concurrently.
Args:
batch (List[Dict[str, str]]): A list of dictionaries where each dictionary
contains the data for a single sample, including
an "Article_title".
Returns:
List[str]: A list of responses from the LLM for each sample in the batch.
"""
list_messages = []
# Loop through each sample in the batch
for sample in batch:
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": sample["Article_title"]}
]
list_messages.append(messages)
# Use asyncio.gather to send requests to the LLM concurrently for all message sequences
return await asyncio.gather(*[llm_engine(messages) for messages in list_messages])
我们将在数据集上运行推理
from datasets import load_dataset, Dataset
#Streaming data from Huggingface Hub to avoid downloading the entire dataset
dataset = load_dataset("Zihan1004/FNSPID", streaming=True)
iterable_dataset = iter(dataset["train"])
# Create a batch of samples from remote dataset
def get_sample_batch(iterable_dataset, batch_size):
batch = []
try:
for _ in range(batch_size):
batch.append(next(iterable_dataset))
except StopIteration:
pass
return batch
然后我们创建主推理循环
#Main loop
batch_size = 128
i= 0
len_extracted = 0
while True:
batch = get_sample_batch(iterable_dataset, batch_size)
#batch = samples[i * batch_size : (i+1) * batch_size]
predictions = await process_batch(batch)
parsed_predictions = [parse_llm_output(_pred) for _pred in predictions]
try :
parsed_dataset = [
{"Article_title": sample["Article_title"],
"predicted_companies": pred["result"],
"normalized_companies":pred.get("normalized_result", ""),
"valid": pred["valid"]} for sample, pred in zip(batch, parsed_predictions)
]
except Exception as e :
print(i,e)
continue
# Write parsed_dataset to a JSON file
with open(os.path.join(CHECKPOINT_DATA, f"parsed_dataset_{i}.json"), 'w') as json_file:
json.dump(parsed_dataset, json_file, indent=4) # Use json.dump to write data to a JSON file
len_extracted += len(parsed_dataset)
i+= 1
print(f"Extracted: {len_extracted} samples")
if len(batch) < batch_size:
break
推理运行时,我们可以直接从用户界面监控流量。
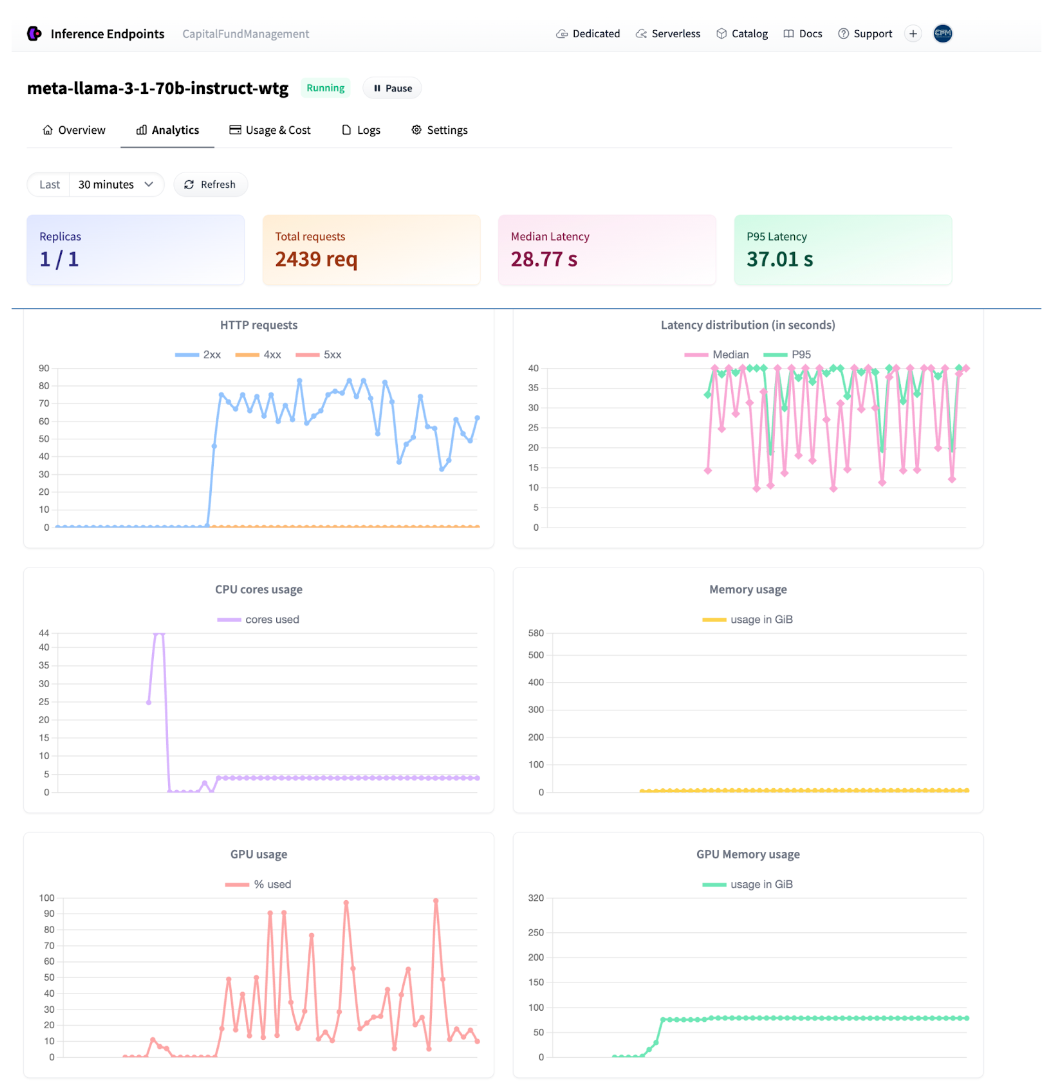
端点分析
处理整个 90 万样本的数据集大约需要 8 小时,花费约 70 美元。
使用 Argilla 审查预测
利用 LLM 生成的标注数据,下一步是整理一个高质量的子集,以确保对不同方法(包括零样本和微调方法)进行可靠评估。这个经过仔细审查的数据集还将作为微调小型模型的基础。LLM 标注的整个数据集也可以在 弱监督 框架中用于微调。
数据集抽样和分割
为了创建可管理大小的样本进行审查,我们使用 LLM 标签并通过 模糊匹配 和 rapidfuzz 库对公司名称进行聚类。我们应用 cdist 函数计算公司之间的 Levenshtein 距离,并以 85 的阈值进行聚类。为每个聚类选择一个代表性公司,并相应地映射 Llama 预测。最后,我们从每个与公司相关的聚类中抽取 5% 的新闻标题,并从不含任何公司的新闻标题中抽取 5%,最终得到一个包含 2714 个样本的数据集。
然后利用元数据,将采样数据集分为三个部分:
训练:2010 年至 2016 年的新闻,用于训练小型机器学习模型——2405 个样本
验证:2017 年至 2018 年的新闻,用于超参数调整——204 个样本
测试:2019 年至 2020 年的新闻,用于评估模型在未见数据上的表现——105 个样本
创建完成后,我们设置了一个标注工具 Argilla,以简化标注过程。
Argilla 是一个开源工具,集成到 Hugging Face 生态系统中,擅长收集各种 AI 项目的人工反馈。无论您是处理传统的 NLP 任务(如文本分类和 NER)、微调大型语言模型 (LLM) 以进行检索增强生成 (RAG) 或偏好调整,还是开发多模态模型(如文本到图像系统),Argilla 都提供了高效收集和优化反馈所需的工具。这确保您的模型根据高质量、经过人工验证的数据不断改进。
Argilla 界面可以直接通过 Hugging Face Spaces 设置,这也是我们选择的方法。请查看文档以启动您自己的界面,并前往 https://huggingface.co/new-space。
在 Hub 上创建 Argilla Space
Argilla 在 Spaces 上的主页
Argilla 数据集视图
界面创建后,我们可以使用 Argilla Python SDK 以编程方式连接到它。为了准备好进行注释,我们遵循了以下步骤:
- 我们使用设置中提供的凭据连接到我们的界面。
import argilla as rg
client = rg.Argilla(
api_url="https://capitalfundmanagement-argilla-ner.hf.space",
api_key="xxx",
headers={"Authorization": f"Bearer {HF_TOKEN}"},
verify = False)
- 我们为标注创建指导原则,并生成特定任务的数据集。在这里,我们指定了 SpanQuestion 任务。然后,我们使用定义的设置生成训练、验证和测试数据集对象。
import argilla as rg # Import the Argilla library.
# Define the label for token classification (e.g., "Company").
labels = ["Company"]
# Define settings for the annotation task.
settings = rg.Settings(
guidelines="Classify individual tokens according to the specified categories, ensuring that any overlapping or nested entities are accurately captured.",
fields=[rg.TextField(name="text", title="Text", use_markdown=False)],
questions=[rg.SpanQuestion(
name="span_label",
field="text",
labels=labels,
title="Classify the tokens according to the specified categories.",
allow_overlapping=False,
)],
)
# Create datasets with the same settings for training, validation, and testing.
train_dataset = rg.Dataset(name="train", settings=settings)
train_dataset.create()
valid_dataset = rg.Dataset(name="valid", settings=settings)
valid_dataset.create()
test_dataset = rg.Dataset(name="test", settings=settings)
test_dataset.create()
- 我们用来自不同数据集的新闻标题填充数据集。
train_records = [rg.Record(fields={"text": title}) for title in train_df["Article_title"]]
valid_records = [rg.Record(fields={"text": title}) for title in valid_df["Article_title"]]
test_records = [rg.Record(fields={"text": title}) for title in test_df["Article_title"]]
train_records_list = [{"id": record.id, "text": record.fields["text"]} for record in train_records]
valid_records_list = [{"id": record.id, "text": record.fields["text"]} for record in valid_records]
test_records_list = [{"id": record.id, "text": record.fields["text"]} for record in test_records]
train_dataset.records.log(train_records)
valid_dataset.records.log(valid_records)
test_dataset.records.log(test_records)
- 在此步骤中,我们整合了来自各种模型的预测。具体来说,我们将 Llama 3.1 预测添加到 Argilla 中,其中每个实体都表示为一个字典,包含起始索引、结束索引和标签(在本例中为“Company”)。
train_data = [{"span_label": entity,"id": id,} for id, entity in zip(train_ids, train_entities_final)]
valid_data = [{"span_label": entity,"id": id,} for id, entity in zip(valid_ids, valid_entities_final)]
test_data = [{"span_label": entity,"id": id,} for id, entity in zip(test_ids, test_entities_final)]
train_dataset.records.log(records=train_data, batch_size = 1024)
valid_dataset.records.log(records=valid_data, batch_size = 1024)
test_dataset.records.log(records=test_data, batch_size = 1024)
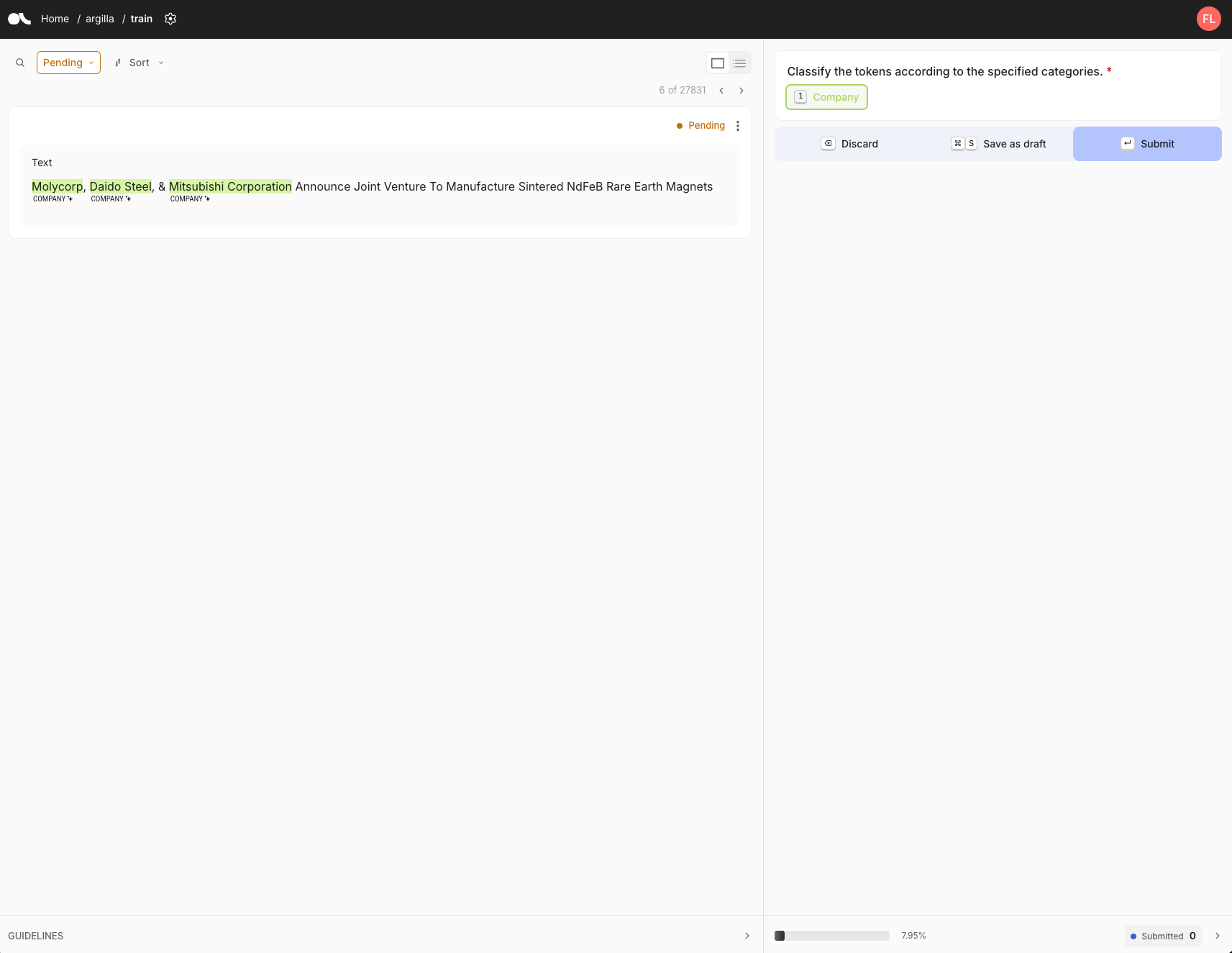
Argilla 标注视图
标注界面显示待标注的文本及其状态(待处理或已提交)。标注指南显示在屏幕右侧。在这种情况下,我们有一个标签:“公司”。要标注,我们首先选择标签,然后在句子中突出显示相关文本。选择所有实体后,我们单击“提交”以完成标注。
标注时长
使用预计算的 Llama 标签显著加快了标注过程,将每个样本的时间缩短到仅 5 到 10 秒, 而原始、未经处理的样本大约需要 30 秒。这种效率带来了显著的时间节省,使我们能够在大约 8 小时内完成 2,714 个样本的标注。 对于比 NER 更复杂的任务,预计算标签或生成所节省的时间效益更为显著。
金融 NER 零样本方法的性能
有了一个高质量、经过审查的数据集,我们现在可以尝试不同的零样本 NER 方法。我们测试了四种模型:
小型语言模型
- GLINER
- SpanMarker 大型语言模型 (LLM):
- Llama-3.1-8b
- Llama-3.1-70b
- GLiNER
GLiNER 是一种紧凑、多功能的 NER 模型,它利用像 BERT 这样的双向转换器来识别各种实体类型,克服了传统模型受限于预定义实体的局限性。与大型自回归模型不同,GLiNER 将 NER 视为一种将实体类型与文本中的跨度匹配的任务,并使用并行处理以提高效率。它为 LLM 提供了一种实用且资源高效的替代方案,在零样本场景中提供了强大的性能,而无需支付与大型模型相关的高计算成本。
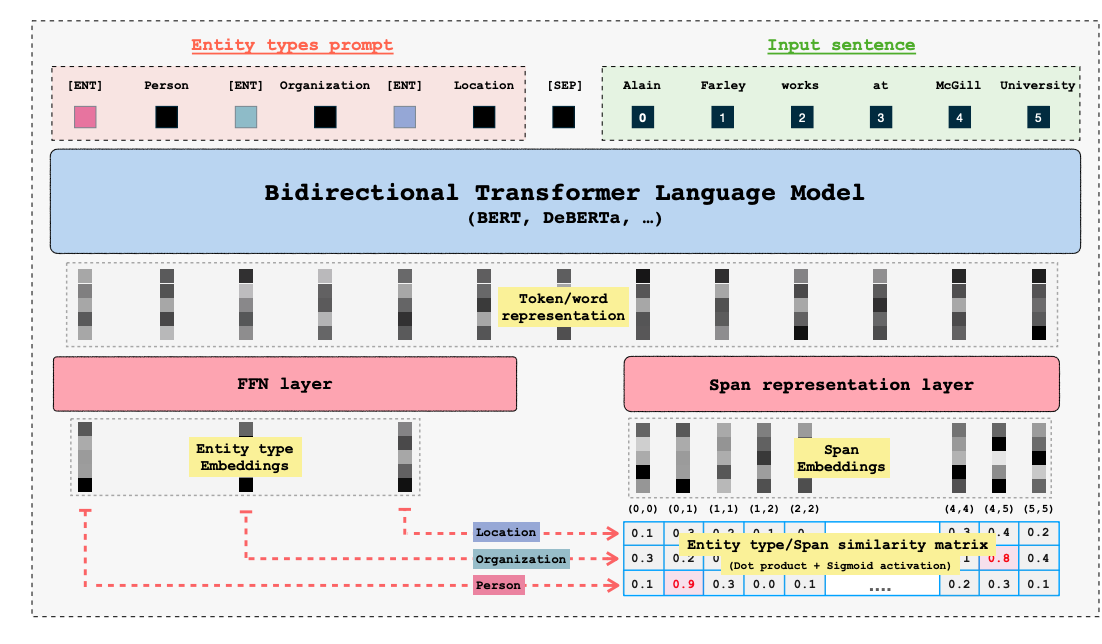
GLiNER 架构源自 原始论文<
GLiNER 提供三种模型变体:
- GLiNER-Small-v2.1(5000 万参数)
- GLiNER-Medium-v2.1(9000 万参数)
- GLiNER-Large-v2.1(3 亿参数)
与 Llama-3.1-70b 等 LLM 相比,GLiNER 模型更紧凑、更具成本效益,并且在 NER 任务中更高效,而 LLM 通常提供更广泛的灵活性,但模型更大且资源密集。GLiNER medium 可以在 Hugging Face Space 上试用:https://huggingface.co/spaces/tomaarsen/gliner_medium-v2.1 对于我们的实验,我们关注特定的 GLiNER 变体 EmergentMethods/gliner_medium_news-v2.1 ,该变体已在 EmergentMethods/AskNews-NER-v0 上进行了微调,旨在提高各种主题的准确性,特别是长上下文新闻实体识别提取。要使用 GLiNER,您可以安装基于 Hugging Face transformers 库的 gliner 包。
!pip install gliner
然后,使用 GLiNER 进行 NER 就像这样简单:
from gliner import GLiNER
model = GLiNER.from_pretrained("EmergentMethods/gliner_large_news-v2.1")
text = """
EMCOR Group Company Awarded Contract for Installation of Process Control Systems for Orange County Water District's Water Purification Facilities
"""
labels = ["company"] # Add other entities that you want to detect here
entities = model.predict_entities(text, labels, threshold=.5)
#threshold indicates the minimum probability the model should have for the returned entities.
for entity in entities:
print(entity["text"], "=>", entity["label"])
输出
“EMCOR Group => company"
对于样本列表,可以使用 `batch_text` 方法
from gliner import GLiNER
model = GLiNER.from_pretrained("EmergentMethods/gliner_large_news-v2.1")
batch_text = [
"EMCOR Group Company Awarded Contract for Installation of Process Control Systems for Orange County Water District's Water Purification Facilities",
"Integra Eyes Orthopedics Company - Analyst Blog"
]
labels = ["company"] # Add other entities that you want to detect here
batch_entities = model.batch_predict_entities(batch_text, labels, threshold=.5)
#threshold indicates the minimum probability the model should have for the returned entities.
for entities in batch_entities:
for entity in entities:
print(entity["text"], "=>", entity["label"])
输出
“EMCOR Group => company" #correct predictions
"Integra Eyes Orthopedics Company => company" #incorrect predictions, ground truth Integra
在先前整理的 2714 个样本的标注数据集上,零样本结果的 F1 分数为 87%。
GLiNER 模型在从文本中提取公司名称方面表现良好,但在某些情况下(例如公司以股票代码形式提及时)仍有不足。它还会将对股票行业的通用引用(如“医疗保健股票”或“工业股票”)错误地分类为公司名称。尽管在许多情况下有效,但这些错误突出表明需要进一步完善以提高在区分公司和更广泛的行业术语方面的准确性。
- SpanMarker SpanMarker 是一个用于使用 BERT、RoBERTa 和 DeBERTa 等常见编码器训练强大 NER 模型的框架。它与 🤗 Transformers 库紧密结合,可以很好地利用它。因此,SpanMarker 对于任何熟悉 Transformers 的人来说都将直观易用。我们选择了这个变体 tomaarsen/span-marker-bert-base-orgs,它在 FewNERD、CoNLL2003 和 OntoNotes v5 数据集上进行训练,可用于 NER。这个 SpanMarker 模型使用 bert-base-cased 作为底层编码器。它专门用于识别组织。它可以用于推理,预测
ORG(组织)标签,如下所示:
from span_marker import SpanMarkerModel
# Download from the 🤗 Hub
model = SpanMarkerModel.from_pretrained("tomaarsen/span-marker-bert-base-orgs")
# Run inference
entities = model.predict("Enernoc Acquires Energy Response; Anticipates Deal Will Add to 2013 EPS")
for entity in entities:
print(entity["span"], "=>", entity["label"])
输出
“EMCOR Group => ORG" #correct predictions
"Energy Response => ORG" #incorrect
在先前整理的 2714 个样本的标注数据集上,零样本结果的 F1 分数为 47%。SpanMarker 模型在提取准确的公司名称方面表现良好,但倾向于识别出过多的不正确实体。这是因为它的训练基于更广泛的“组织”类别,其中包括非营利组织、政府机构、教育机构和运动队等实体。因此,它有时会将这些实体与公司名称混淆,导致在某些语境中过度提取和结果不够精确。
- Llama3.1-8b 和 Llama3.1-70b
我们测试了 Llama3.1 模型的 2 个变体,包括我们用于整理真实示例的 70b 版本。我们使用了上面介绍的提示。在我们标注的子集上,我们得到了以下结果:
| 模型 | Llama 3.1 8b | Llama 3.1 70b |
|---|---|---|
| F1-分数 | 88% | 95% |
性能回顾
| 模型 | GLiNER | SpanMarker | Llama 3.1 8b | Llama 3.1 70b |
|---|---|---|---|---|
| F1-分数 | 87% | 47% | 88% | 95% |
在本次实验中,我们比较了 GLiNER 和 SpanMarker 等小型模型与 Llama 3.1-8b 和 Llama 3.1-70b 等 LLM 的性能。GLiNER (87% F1) 等小型模型在准确性和计算效率之间取得了良好的平衡,使其成为资源受限场景的理想选择。相比之下,LLM 虽然资源密集型,但提供了更高的准确性,其中 Llama 3.1-70b 实现了 95% 的 F1 分数。这凸显了在 NER 任务中选择小型模型和 LLM 之间,性能与效率之间的权衡。现在让我们看看在微调紧凑模型时性能有何不同。
利用 LLM 辅助标注数据集微调紧凑模型的性能提升
微调
利用我们之前创建的训练/验证/测试子集,我们在具有单个 Nvidia A10 GPU 的 AWS 实例上对 GLiNER 和 SpanMarker 进行了微调。GLiNER 的微调示例可在此处访问 这里,SpanMarker 的微调示例可在此处访问 这里。微调这些模型就像运行以下代码一样简单,其中 train_dataset 和 valid_dataset 已创建为 Hugging Face 数据集。
import numpy as np
from gliner import GLiNER, Trainer
# calculate number of epochs
batch_size = 4
learning_rate=5e-6
num_epochs = 20
model=GLiNER.from_pretrained("EmergentMethods/gliner_medium_news-v2.1")
data_collator = DataCollator(model.config, data_processor=model.data_processor, prepare_labels=True)
log_dir = create_log_dir(model_path, model_name, learning_rate, batch_size, size, model_size, timestamp=False)
training_args = TrainingArguments(
output_dir=log_dir, # Optimizer, model, tokenizer states
logging_dir = log_dir,
overwrite_output_dir = 'True',
learning_rate=learning_rate, # Learning rate
weight_decay=0.01, # Weight decay
others_lr=1e-5, # learning rate
others_weight_decay=0.01, # weight decay
lr_scheduler_type="linear", # learning rate scheduler
warmup_ratio=0.1, # Warmup steps ratio
per_device_train_batch_size=batch_size, # Training batch
per_device_eval_batch_size=batch_size, # Evaluation batch
focal_loss_alpha=0.75, # Focal loss alpha parameter
focal_loss_gamma=2, # Focal loss gamma parameter
num_train_epochs=num_epochs, # training epochs
save_strategy="epoch", # Save the model at the end of each epoch
save_total_limit=2, # Keep only the best model
metric_for_best_model="valid_f1",
use_cpu=False, # Use GPU
report_to="tensorboard", # Report to TensorBoard
logging_steps=100, # Steps between logging
evaluation_strategy="epoch", # Evaluate every few steps
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
tokenizer=model.data_processor.transformer_tokenizer,
data_collator=data_collator,
compute_metrics=custom_compute_metrics
)
trainer.train()
训练运行了 20 个 epochs,我们保存了在验证集上获得最高 F1 分数的检查点。
性能比较
| 模型 | gliner-medium-news | Gliner-medium-news 微调 | SpanMarker | SpanMarker 微调 | Llama 3.1 8b | Llama 3.1 70b |
|---|---|---|---|---|---|---|
| 测试集 F1-分数 | 87.0% | 93.4% | 47.0% | 90.1% | 80.0% | 92.7% |
在此次更新的比较中,我们评估了模型在微调后的 F1 分数。GLiNER-medium-news 模型在微调后从 87.0% 提高到 93.4%,显示出显著的准确性提升。同样,SpanMarker 经过微调后从 47.0% 提高到 90.1%,使其更具竞争力。同时,Llama 3.1-8b 和 Llama 3.1-70b 在开箱即用状态下表现良好,F1 分数分别为 80.0% 和 92.7%,未经微调。此比较强调,微调像 GLiNER 和 SpanMarker 这样的小型模型可以显著提升性能,以较低的计算成本与大型 LLM 媲美。
Llama 3.1-70b 模型每次推理的成本至少为每小时 8 美元,明显高于紧凑型模型,后者可以在每小时约 0.50 美元的 GPU 实例上运行——便宜 16 倍。此外,紧凑型模型甚至可以部署在 CPU 实例上,每小时成本低至约 0.10 美元,便宜 80 倍。这凸显了小型模型在资源受限环境中的显著成本优势,同时在针对特定任务进行微调时,无需牺牲具有竞争力的性能。
弱监督与 LLM 辅助标注
在本次实验中,我们探讨了两种关键的 NER 数据标注方法:弱监督和 LLM 辅助标注。虽然弱监督能够实现合成数据的可扩展训练,但我们的研究结果表明,它无法达到与手动标注数据训练的模型相同的准确性水平。对于 1,000 个样本,手动标注需要 3 小时,F1 分数为 0.915,而 Llama 3.1-70b 推理仅需 2 分钟,但 F1 分数略低,为 0.895。速度和准确性之间的权衡取决于任务的要求。
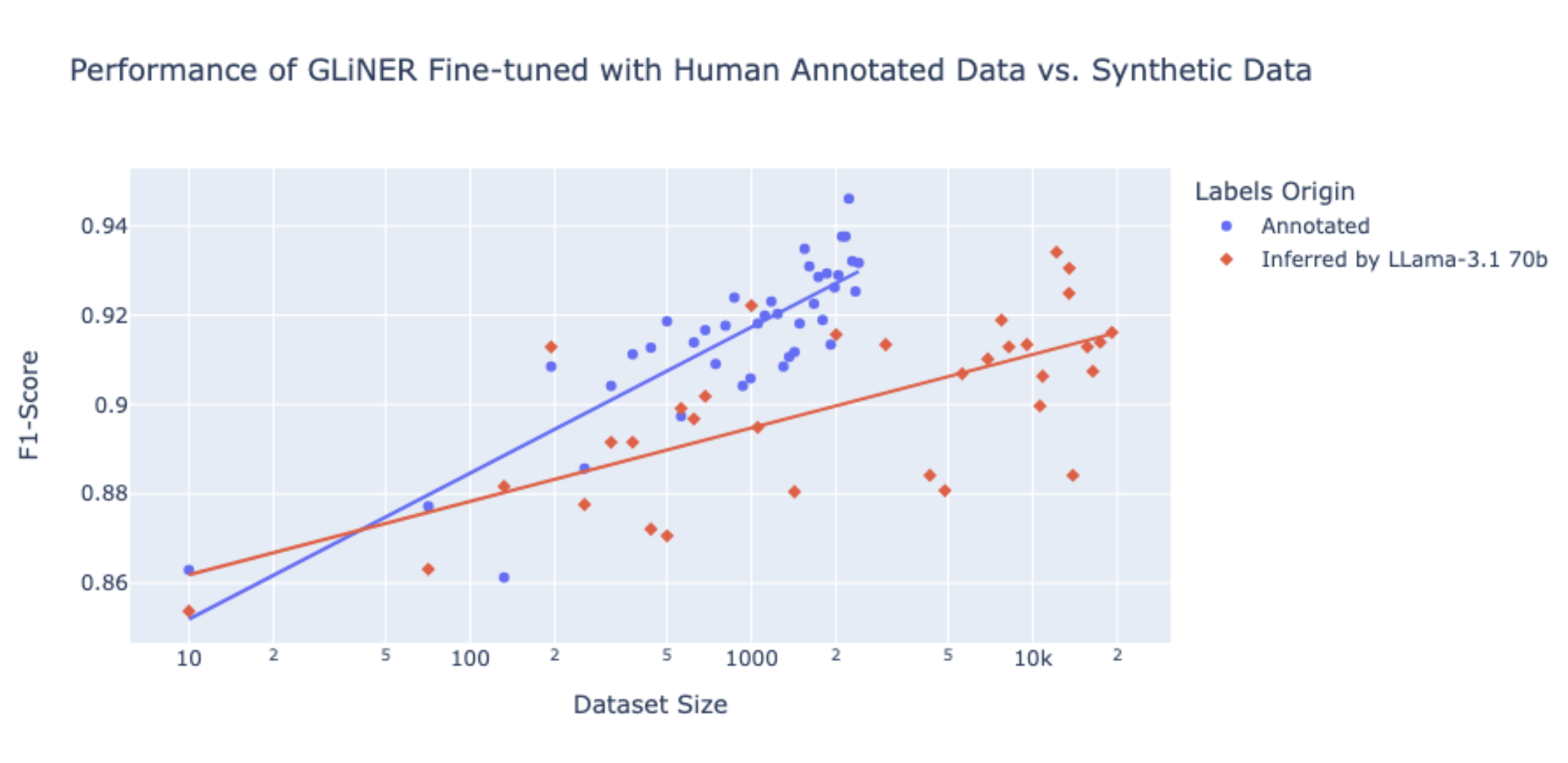
弱监督与 LLM 辅助标注
该图比较了 GLiNER 在人工标注数据上微调与 Llama-3.1 70b 推断的合成数据在不同数据集大小下的性能。蓝色点代表在人工标注数据上训练的模型获得的 F1 分数,红色点代表由 Llama-3.1 70b 推断的模型获得的 F1 分数。随着数据集大小的增加,在人工标注数据上微调的模型始终优于使用合成数据的模型,实现了更高的 F1 分数。这表明,虽然在人工标注上微调的模型能带来更高的准确性,但使用 Llama-3.1 70b 进行的 LLM 辅助标注 仍然可以提供相当大的价值,尤其是在手动标注资源有限的情况下。即使 LLM 推断数据的 F1 分数略低,但在各种数据集大小下仍具有竞争力。LLM 可以快速生成大量标注,为高效扩展数据集创建提供了实用解决方案,使其在时间和成本限制至关重要的场景中具有优势。
结论
我们的实验表明,虽然像 Llama 3.1 这样的大型模型开箱即用就能提供卓越的性能,但通过 LLM 辅助标注微调像 GLiNER 和 SpanMarker 这样的小型模型可以显著提高准确性,以更低的成本与 LLM 媲美。这种方法突出了利用 LLM 洞察力投资微调小型模型如何为金融 NER 任务提供一种经济高效、可扩展的解决方案,使其成为对准确性和资源效率都至关重要的实际应用的理想选择。







