通过自动化数据增强提升您的 NLP 模型,增强性能




自然语言处理 (NLP) 领域受到了机器学习进步的巨大影响,导致语言理解和生成能力显著提高。然而,随着这些强大 NLP 模型的发展,新的挑战也随之出现。该领域的主要关注点之一是鲁棒性问题,它指的是模型在各种语言输入(包括非典型输入)上始终准确执行的能力。
您的 NLP 模型真的鲁棒吗? 🤔
为了确保 NLP 模型在各种实际场景中表现良好,识别模型问题至关重要。有几种方法可以做到这一点。
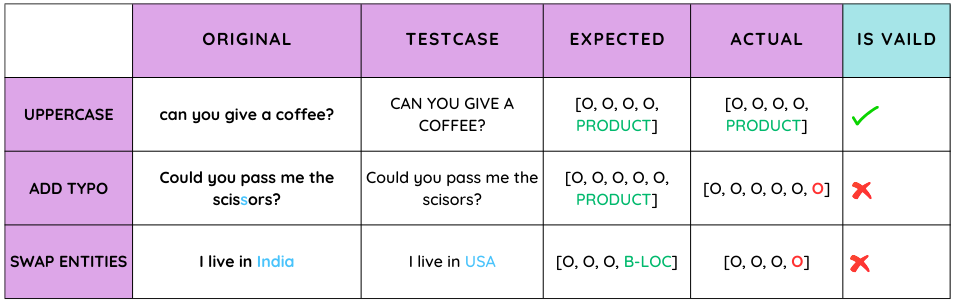
研究人员可以通过更改输入来测试模型的适应性和对**句子结构、标点符号**和**词序**变化的抵抗力。
引入**拼写错误、排版错误**和**语音变体**有助于确定模型处理噪声数据的能力。
评估模型对不同程度的**礼貌、正式程度**或**语气**的反应可以揭示其对上下文的敏感性。
此外,测试模型对模糊或比喻语言的理解能力可以揭示其局限性。在提示中交换关键信息或实体可以揭示模型是否保持准确的响应。最后,测试模型在域外或特定领域输入上的性能可以揭示其泛化能力。定期使用这些方法进行测试可以识别并解决问题,帮助 NLP 模型成为各种应用程序更有效、更可靠的工具。
在这篇博文中,我们将测试 NERPipeline 模型的鲁棒性并评估其性能,该模型在 f1 分数方面表现良好。
“有了高质量的数据集,您就可以构建一个出色的模型。有了出色的模型,您就可以取得伟大的成就。”
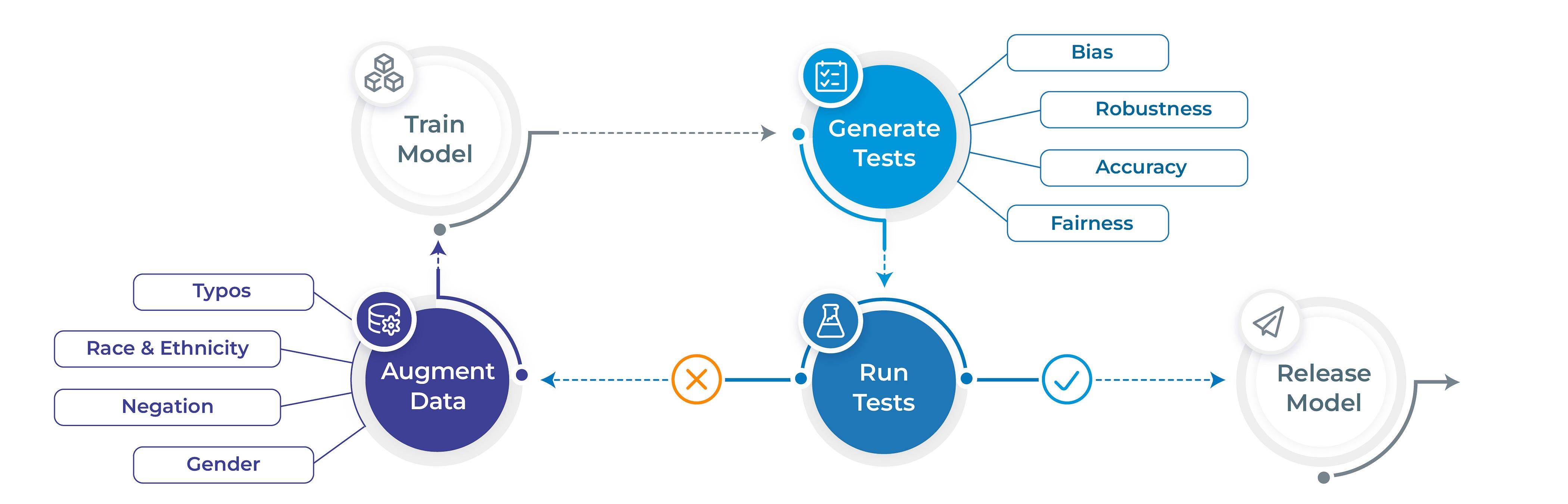
通过数据增强自动提高鲁棒性
数据增强是自然语言处理 (NLP) 领域中广泛使用的技术,旨在增加语言模型和其他 NLP 任务的训练数据的规模和多样性。此技术可以涉及从现有数据创建新的训练示例或完全生成新数据。
数据增强的好处是多方面的。首先,通过增加训练数据的规模和多样性,它有助于减少过拟合。当模型过度学习训练数据时,就会发生过拟合,导致在新数据上表现不佳。通过使用数据增强,模型接触到更大、更多样化的数据,这有助于它更好地泛化到新数据。其次,数据增强可以通过使其接触更广泛的语言变体和模式来提高模型的鲁棒性。这有助于使模型对输入数据中的错误更具抵抗力。
在 NLP 领域,Langtest 库提供两种类型的增强:比例增强和模板增强。比例增强基于鲁棒性和偏差测试,而模板增强基于用户输入数据提供的模板。该库还在不断开发新的增强技术,以提高 NLP 模型的性能。
**比例增强**可用于通过采用各种测试方法来改进数据质量,这些方法根据一组训练数据修改或生成新数据。此技术有助于为机器学习、预测建模和决策提供高质量和准确的结果。它对于解决模型的特定弱点特别有用,例如识别小写文本。
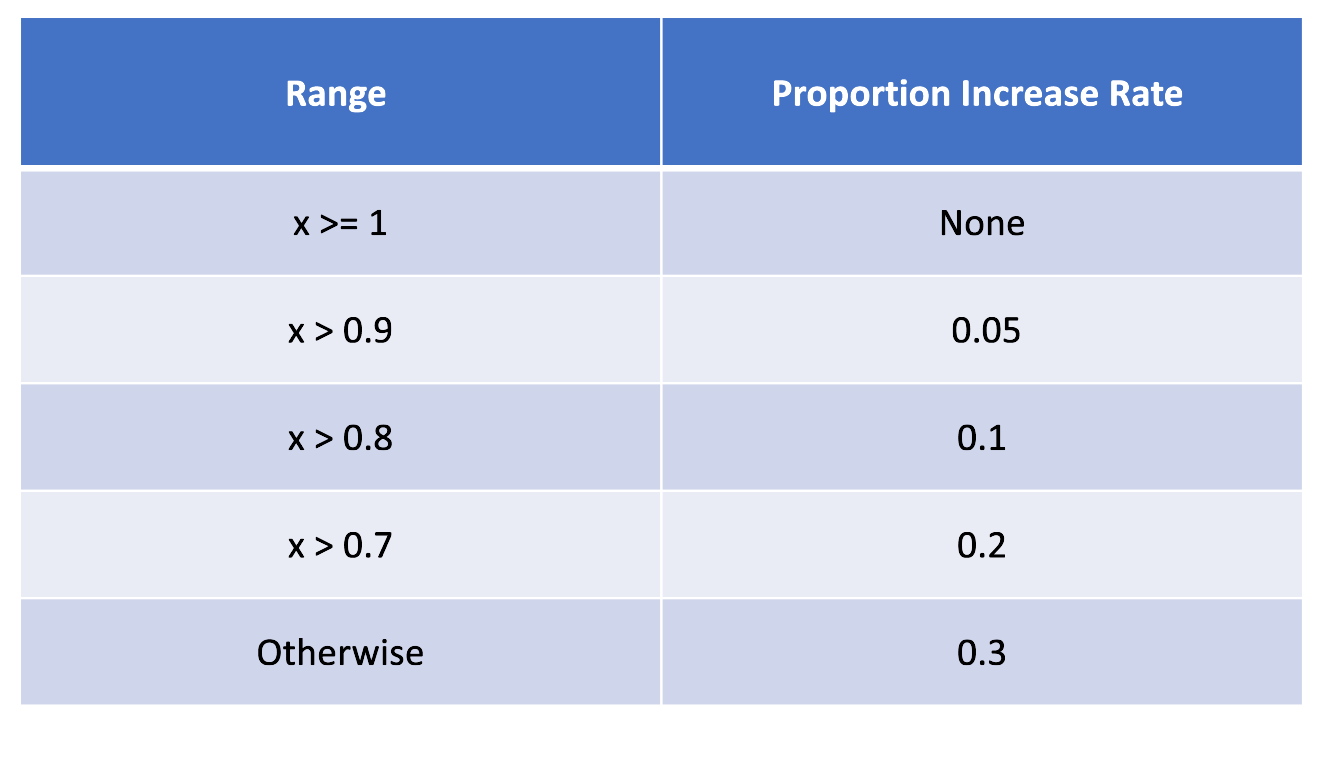
我们默认使用所提供模型的 Harness 测试报告中的最小通过率和通过率数据来计算比例。我们将最小通过率与通过率进行比较的结果称为“x”。如果 x 大于或等于 1,则情况未定义或不适用。如果 x 介于 0.9 和 1 之间,则分配的值为 0.05,表示适度增加。对于 x 介于 0.8 和 0.9 之间,相应的值变为 0.1,表示相对较高的增加。同样,当 x 介于 0.7 和 0.8 之间时,值变为 0.2,反映了显著增加。如果 x 小于或等于 0.7,则值为 0.3,表示较小比例的默认增加率。这种系统方法根据 x 值对不同的比例增加率进行分类,从而产生适应不同输入场景的结构化输出。
Langtest 库提供了一系列通过比例增强生成数据集的技术。这可以通过指定 export_mode 参数来完成,该参数提供各种值,例如 add、inplace 和 transformed。为了更好地理解 export_mode 参数及其不同的值,您可以参考随附的图像。
**添加模式:** 需要注意的是,任何生成的新句子都将添加到现有文件中。
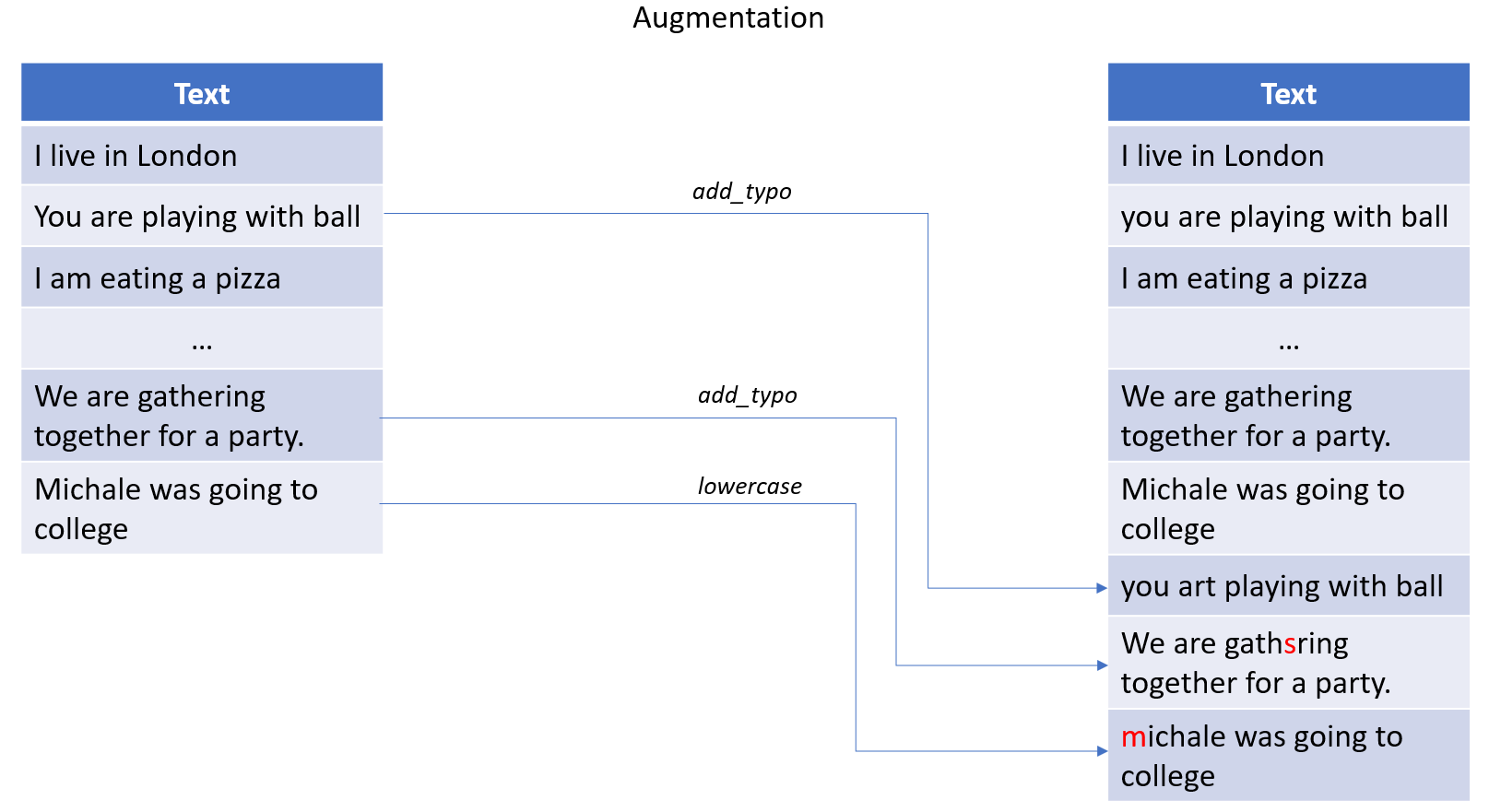
**就地模式:** 需要注意的是,通过从给定数据集中随机选择它们,根据 Harness 中的测试类型编辑句子。

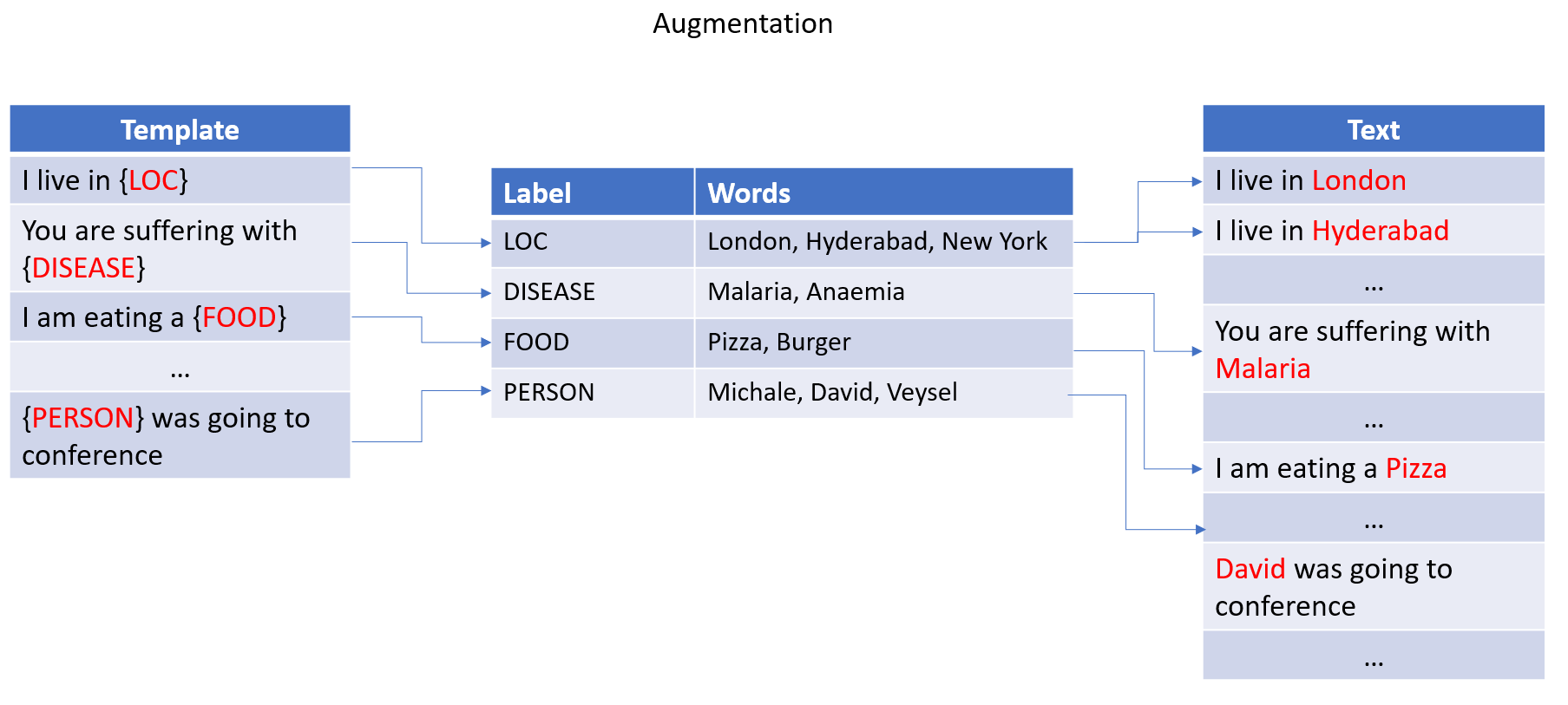
另一方面,**模板增强**涉及采用预先存在的模板或模式,并生成在结构和上下文上与原始输入相似的新数据。此方法严重依赖于用户提供的模板。通过使用此技术,可以进一步完善和训练 NLP 模型,以更好地理解语言的细微差别。
Langtest 库提供了一个名为**“模板增强”**的功能,可以通过利用提供的模板生成新的数据集。该过程涉及从现有数据集中提取标签和相应值,然后使用数据集中的标签将这些值替换为提供的模板。要可视化此过程,请参阅下图。
总而言之,数据增强是 NLP 数据管理的关键方面。通过增加训练数据的规模和多样性,可以更好地训练模型来处理各种语言变体和模式。然而,重要的是要注意,增强不是可以修复有根本缺陷的模型的灵丹妙药。虽然数据增强无疑有助于提高 NLP 模型的性能和鲁棒性,但它只是开发高质量和有效语言模型所需的一整套技术和工具中的一个方面。
让我向您介绍 Langtest。
Langtest 是一个开源 Python 库,提供一套测试来评估自然语言处理 (NLP) 和大型语言模型 (LLM) 的鲁棒性、偏差、毒性和准确性。该库包含各种测试,每个测试都可用于评估模型在特定维度上的性能。例如,鲁棒性测试评估模型抵御对抗性攻击的能力,偏差测试评估模型对人口统计学和其他形式偏差的敏感性,毒性测试评估模型识别和避免毒性语言的能力。
Langtest 的设计易于使用,只需一行代码即可轻松运行测试和评估模型性能。该库还包含一些有用的功能,例如内置的测试用例数据集以及保存或加载功能,可用于跟踪模型随时间推移的性能。
Langtest 是从事 NLP 和 LLM 工作的数据科学家、研究人员和开发人员的宝贵工具。该库可以帮助识别模型性能的潜在问题,也可以用于跟踪模型在训练和微调过程中的性能。
以下是使用 Langtest 的一些好处
**易于使用:** Langtest 具有一行代码,可轻松运行测试并评估模型性能。**多功能:** Langtest 包含各种测试,可用于评估模型在各种维度上的性能。**准确:** Langtest 使用各种技术来确保其测试结果准确。**开源:** Langtest 是开源的,这意味着任何人都可以免费使用它。
from langtest import Harness
harness = Harness(task="ner",
model="en_core_web_sm",
data="path/to/sample.conll",
hub="spacy")
# generate and evaluate the model
harness.generate().run()report()
让我们增强模型性能
为了提高模型性能,对其进行彻底测试至关重要。实现这一目标的一种方法是增加训练数据。这涉及向现有训练集添加更多数据,以便为模型提供更广泛的示例以供学习。通过这样做,模型可以提高其准确性和泛化到新数据的能力。然而,重要的是要确保额外数据是相关的,并且能够代表所要解决的问题。
!pip install langtest[johnsnowlabs]==1.4.0
以下是使用指定模型对训练数据进行增强的步骤。
- 从 johnsnowlabs 初始化模型。
from johnsnowlabs import nlp from langtest import Harness documentAssembler = nlp.DocumentAssembler()\ .setInputCol("text")\ .setOutputCol("document") tokenizer = nlp.Tokenizer()\ .setInputCols(["document"])\ .setOutputCol("token") embeddings = nlp.WordEmbeddingsModel.pretrained('glove_100d') \ .setInputCols(["document", 'token']) \ .setOutputCol("embeddings") ner = nlp.NerDLModel.load("models/trained_ner_model") \ .setInputCols(["document", "token", "embeddings"]) \ .setOutputCol("ner") ner_pipeline = nlp.Pipeline().setStages([ documentAssembler, tokenizer, embeddings, ner ]) ner_model = ner_pipeline.fit(spark.createDataFrame([[""]]).toDF("text")) - 使用 johnsnowlabs 中初始化的模型,从 Python 的 langtest 库初始化 Harness。
harness = Harness( task="ner", model=ner_model, data="sample.conll", hub="johnsnowlabs") - 使用 harness 类中的 configure() 函数配置测试,如下所示。在执行 generate() 和 save() 以保存生成的测试用例后,执行 run() 并通过调用 report() 生成报告。
harness.configure({ 'tests': { 'defaults': {'min_pass_rate': 0.65}, 'robustness': { 'uppercase': {'min_pass_rate': 0.80}, 'lowercase': {'min_pass_rate': 0.80}, 'titlecase': {'min_pass_rate': 0.80}, 'strip_punctuation': {'min_pass_rate': 0.80}, 'add_contraction': {'min_pass_rate': 0.80}, 'american_to_british': {'min_pass_rate': 0.80}, 'british_to_american': {'min_pass_rate': 0.80}, 'add_context': { 'min_pass_rate': 0.80, 'parameters': { 'ending_context': [ 'Bye', 'Reported' ], 'starting_context': [ 'Hi', 'Good morning', 'Hello'] } } } } }) # testing of model harness.generate().run().report()
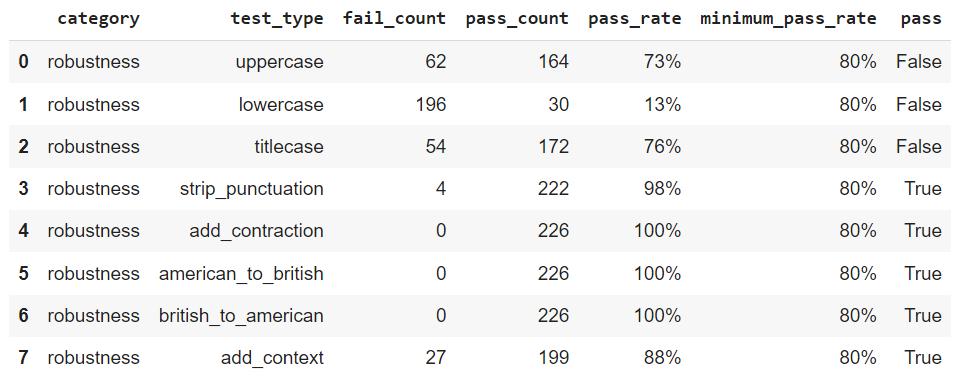
根据测试结果增强 CoNLL 训练集
比例值会自动计算,但如果您希望进行调整,可以通过调用 Langtest 库中 Harness 类中的 augment 方法来修改值。您可以使用字典或列表格式来自定义比例。
在字典格式中,键表示测试类型,值表示将以指定类型增强的测试实例的比例。例如,“add_typo”和“lowercase”的比例均为 0.3。
custom_proportions = {
'uppercase':0.3,
'lowercase':0.3
}
在列表格式中,您只需提供一个测试类型列表,以便从报告中选择进行增强,并且每种测试类型的比例值会自动计算。以下代码块中可以看到具有自定义比例的增强示例。
custom_proportions = [
'uppercase',
'lowercase',
]
让我们利用所提供模型的 harness 测试报告来增强训练数据。
# training data
data_kwargs = {
"data_source" : "path/to/conll03.conll",
}
# augment on training data
harness.augment(
training_data = data_kwargs,
save_data_path ="augmented_conll03.conll",
export_mode="transformed")
在增强型 CoNLL 上训练新的 NERPipeline 模型
要继续,您必须首先加载 NERPipeline 模型并开始使用增强数据进行训练。增强数据是通过随机选择训练数据的某些部分并根据 test_type 对其进行修改或添加来创建的。例如,如果数据集包含 100 个句子,并且模型未通过给定测试中的小写测试,则数据比例可以通过将最小通过率除以通过率来确定。
这将确保训练过程的一致性和有效性。
# load and train the model
embeddings = nlp.WordEmbeddingsModel.pretrained('glove_100d') \
.setInputCols(["document", 'token']) \
.setOutputCol("embeddings")
nerTagger = nlp.NerDLApproach()\
.setInputCols(["document", "token", "embeddings"])\
.setLabelColumn("label")\
.setOutputCol("ner")\
.setMaxEpochs(20)\
.setBatchSize(64)\
.setRandomSeed(0)\
.setVerbose(1)\
.setValidationSplit(0)\
.setEvaluationLogExtended(True) \
.setEnableOutputLogs(True)\
.setIncludeConfidence(True)\
.setOutputLogsPath('ner_logs')
training_pipeline = nlp.Pipeline(stages=[
embeddings,
nerTagger
])
conll_data = nlp.CoNLL().readDataset(spark, 'augmented_train.conll')
ner_model = training_pipeline.fit(conll_data)
ner_model.stages[-1].write().overwrite().save('models/augmented_ner_model')
harness = Harness.load(
save_dir="saved_test_configurations",
model=augmented_ner_model,
task="ner")
# evaluating the model after augmentation
harness.run().report()
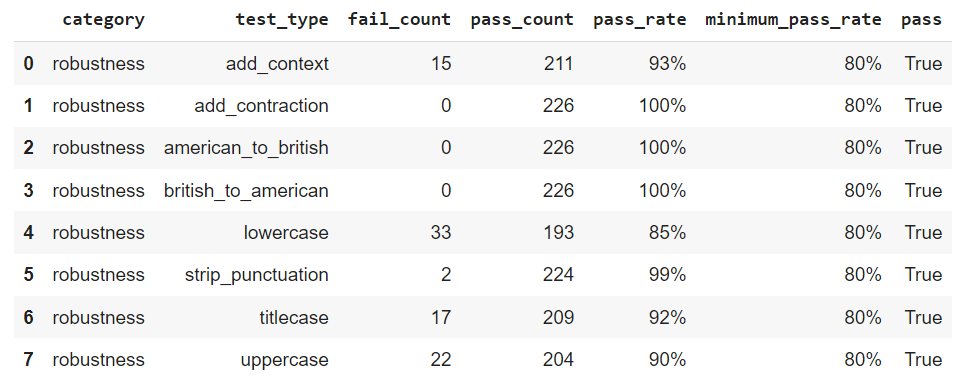
结论
总结我们的发现,NERPipeline 模型在小写测试中表现不佳。然而,在应用小写形式的增强后,其性能有了很大的改进。在评估 NERPipeline 模型在各种应用程序中的有效性时,考虑这些观察结果非常重要。
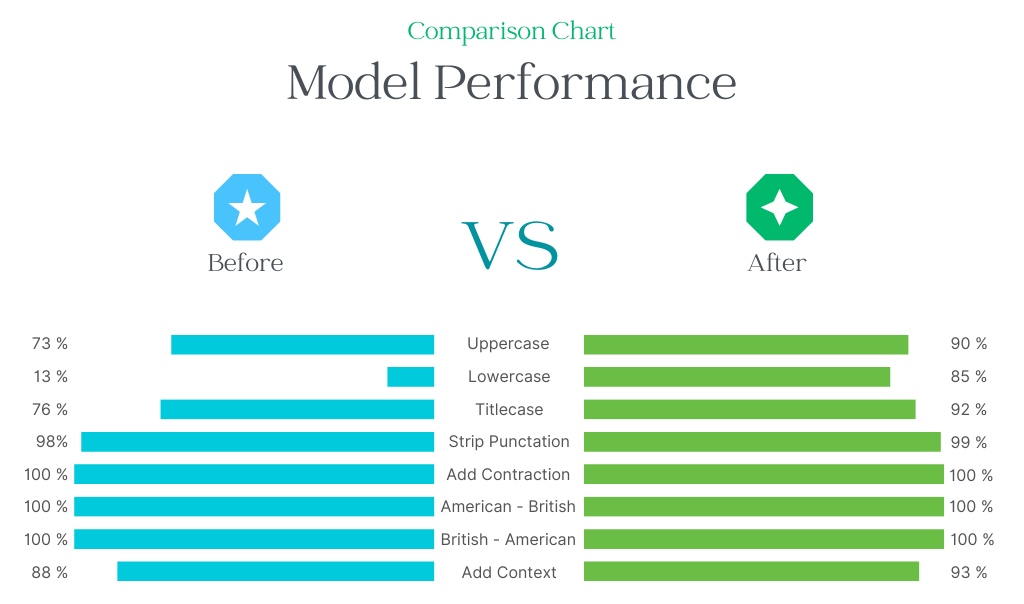
根据提供的图表,可以明显看出小写测试在增强前后的结果提高了 8 倍。同样,我们也可以看到其他测试的改进。如果您希望改进您的自然语言处理模型,那么考虑使用 Langtest (pip install langtest) 可能值得一试。不要再犹豫了,立即行动,开始增强您的 NLP 模型吧。
您是否尝试过使用比例增强笔记本? **点击这里**