Hugging Face 如何加速 Witty Works 写作助手的开发






Witty Works 与 Hugging Face 专家加速计划的成功故事。
如果您有兴趣更快地构建机器学习解决方案,请访问专家加速计划登陆页面,并在此处联系我们!
业务背景
随着信息技术的不断发展和重塑我们的世界,在行业内创造一个更加多元化和包容的环境势在必行。Witty Works 创建于 2018 年,旨在应对这一挑战。Witty Works 最初是一家咨询公司,为组织提供如何变得更加多元化的建议,最初帮助他们使用包容性语言撰写招聘广告。为了扩大这一努力,他们在 2019 年构建了一个 Web 应用,帮助用户用英语、法语和德语撰写包容性招聘广告。他们迅速扩大了范围,推出了一款作为浏览器扩展的写作助手,可以自动修复和解释电子邮件、领英帖子、招聘广告等中潜在的偏见。其目的是提供一种内部和外部沟通的解决方案,通过提供解释突出显示的词语和短语背后潜在偏见的微学习片段,来促进文化变革。
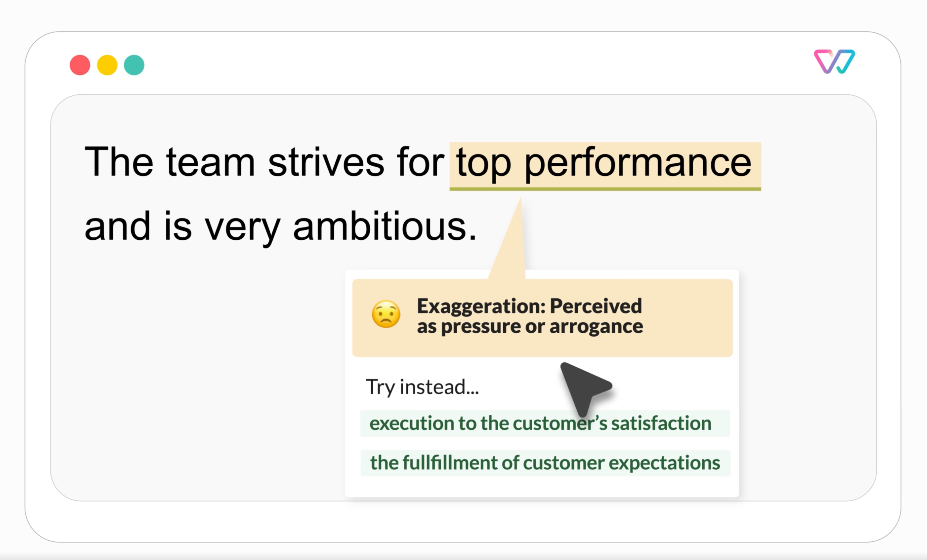
写作助手建议示例
初步实验
Witty Works 最初选择了一种基本的机器学习方法,从零开始构建他们的助手。通过使用预训练的 spaCy 模型进行迁移学习,该助手能够:
- 分析文本并将单词转换为词元,
- 进行语言学分析,
- 从文本中提取语言特征(复数和单数形式、性别)、词性标签(代词、动词、名词、形容词等)、词语依赖关系标签、命名实体识别等。
通过使用语言特征,根据特定的知识库检测和过滤单词,该助手可以实时高亮非包容性单词并建议替代方案。
挑战
词汇库中大约有 2300 个德语和英语的非包容性词汇和习语。上述基本方法对 85% 的词汇都行之有效,但对于依赖上下文的词汇则失败了。因此,任务是构建一个依赖上下文的非包容性词汇分类器。这样的挑战(理解上下文而非识别语言特征)促使他们使用 Hugging Face 的 Transformer 模型。
Example of context dependent non-inclusive words:
Fossil fuels are not renewable resources. Vs He is an old fossil
You will have a flexible schedule. Vs You should keep your schedule flexible.
Hugging Face 专家提供的解决方案
最初选择的方法是标准的 Transformer 模型(用于提取特定非包容性词汇的词元嵌入)。Hugging Face 专家建议从上下文词嵌入切换到上下文句子嵌入。在这种方法中,句子中每个词的表示都依赖于其周围的上下文。
Hugging Face 专家建议使用 Sentence Transformers 架构。该架构为整个句子生成嵌入。语义相似的句子之间的距离被最小化,而语义疏远的句子之间的距离被最大化。
在这种方法中,Sentence Transformers 使用孪生网络和三元组网络结构来修改预训练的 Transformer 模型,以生成“具有语义意义的”句子嵌入。
由此产生的句子嵌入作为基于 KNN 或逻辑回归的经典分类器的输入,以构建一个依赖上下文的非包容性词汇分类器。
Elena Nazarenko, Lead Data Scientist at Witty Works:
“We generate contextualized embedding vectors for every word depending on its
sentence (BERT embedding). Then, we keep only the embedding for the “problem”
word’s token, and calculate the smallest angle (cosine similarity)”
要微调一个基于标准 Transformer 的分类器,例如一个简单的 BERT 模型,Witty Works 需要大量的标注数据。每个被标记词的类别都需要数百个样本。然而,这样的标注过程成本高昂且耗时,这是 Witty Works 无法承担的。
Hugging Face 专家建议使用 Sentence Transformers 微调库(也称为 SetFit),这是一个用于小样本微调 Sentence Transformers 模型的高效框架。结合对比学习和语义句子相似性,SetFit 仅用极少的标注数据就能在文本分类任务上实现高准确率。
Julien Simon, Chief Evangelist at Hugging Face:
“SetFit for text classification tasks is a great tool to add to the ML toolbox”
Witty Works 团队发现,每个特定词汇只需 15-20 个标注句子,性能就足够了。
Elena Nazarenko, Lead Data Scientist at Witty Works:
“At the end of the day, we saved time and money by not creating this large data set”
减少句子数量对于确保模型训练快速和模型运行高效至关重要。然而,这对于另一个原因也是必要的:Witty 明确采用高度监督/基于规则的方法来主动管理偏见。减少句子数量对于减少手动审查训练句子的工作量非常重要。
对于 Witty Works 来说,一个主要挑战是部署一个低延迟的模型。没有人期望等待 3 分钟才能得到改进文本的建议!Hugging Face 和 Witty Works 都尝试了几个 Sentence Transformers 模型,并最终选择了 mpnet-base-v2,并结合了逻辑回归和 KNN。
在 Google Colab 上进行初步测试后,Hugging Face 专家指导 Witty Works 在 Azure 上部署模型。由于模型速度足够快,因此无需进行优化。
Elena Nazarenko, Lead Data Scientist at Witty Works:
“Working with Hugging Face saved us a lot of time and money.
One can feel lost when implementing complex text classification use cases.
As it is one of the most popular tasks, there are a lot of models on the Hub.
The Hugging Face experts guided me through the massive amount of transformer-based
models to choose the best possible approach.
Plus, I felt very well supported during the model deployment”
成果与总结
每个词汇的训练句子数量从 100-200 个减少到 15-20 个。Witty Works 实现了 0.92 的准确率,并以最小的 DevOps 投入成功在 Azure 上部署了自定义模型!
Lukas Kahwe Smith CTO & Co-founder of Witty Works:
“Working on an IT project by oneself can be challenging and even if
the EAP is a significant investment for a startup, it is the cheaper
and most meaningful way to get a sparring partner“
在 Hugging Face 专家的指导下,Witty Works 通过采用 Hugging Face 的方式实施新的机器学习工作流,节省了时间和金钱。
Julien Simon, Chief Evangelist at Hugging Face:
“The Hugging way to build workflows:
find open-source pre-trained models,
evaluate them right away,
see what works, see what does not.
By iterating, you start learning things immediately”
🤗 如果您或您的团队有兴趣通过 Hugging Face 专家加速您的机器学习路线图,请访问 hf.co/support 了解更多信息。

