通过思维锚点理解模型推理:Qwen3 和 DeepSeek-R1 的比较研究



不同的语言模型如何思考?一项使用思维锚点的机制可解释性研究揭示了关于推理进化的惊人见解。
引言
理解语言模型如何推理已成为人工智能安全和可解释性领域最重要的挑战之一。尽管我们可以观察模型的输出,但导致这些输出的内部推理过程在很大程度上仍然不透明。本研究引入了一种新颖的方法,通过**思维锚点**——对成功完成任务的概率有显著影响的关键句子——来审视模型推理的“黑箱”。
在 Bogdan 等人(2025)提出的原始思维锚点概念的基础上,我们使用我们的 Pivotal Token Search (PTS) 库实现了这一方法,以分析两种不同的语言模型:Qwen3-0.6B 和 DeepSeek-R1-Distill-Qwen-1.5B。我们的发现揭示了这些模型之间推理能力演变方式的意想不到的见解。
什么是思维锚点?
思维锚点是模型推理轨迹中对完成任务的成功概率有显著因果影响的句子。与专注于单个标记或注意力模式的传统可解释性方法不同,思维锚点捕捉对任务完成最重要的句子级推理步骤。
Bogdan 等人(2025)引入的方法通过以下方式工作:
- 使用带有
<think>标签的思维链提示**生成推理轨迹** - 使用反事实分析**识别关键句子**
- 通过比较有无每个句子时的成功概率来**衡量影响**
- **分析失败模式**以了解常见的推理陷阱
我们的 PTS 实现通过以下方式扩展了此方法:
- 收集每个思维锚点的全面元数据
- 生成用于聚类分析的 384 维语义嵌入
- 跟踪推理步骤之间的因果依赖关系
- 对失败模式进行分类以进行系统分析
数据集概览
思维锚点生成过程
为确保模型之间的公平比较,我们对 Qwen3 和 DeepSeek-R1 采用了相同的实验条件:
数据来源:这两个模型都在 GSM8K 数据集 的相同子集上进行了评估——这是一个用于数学推理的标准基准,包含小学数学应用题。
生成设置:使用我们的 PTS 库,我们以一致的参数生成了思维锚点:
- 相同的温度和采样设置
- 带有
<think>标签的相同提示模板,用于思维链推理 - 用于确定任务成功的相同神谕评估标准
- 一致的反事实分析方法
结果数据集:
- Qwen3-0.6B:来自 56 个数学推理查询的 148 个思维锚点
- DeepSeek-R1-Distill-Qwen-1.5B:来自 32 个数学推理查询的 110 个思维锚点
数据集大小的差异反映了模型不同的推理模式——Qwen3 为每个查询生成了更多样化的推理轨迹,而 DeepSeek-R1 生成了更集中、更简洁的推理步骤。
这两个数据集都可在 HuggingFace 上获取:
主要发现:不同推理架构的揭示
我们的分析揭示了这些模型在推理方法上的根本差异,揭示了挑战“更好”与“更差”推理的简单概念的独特认知架构。
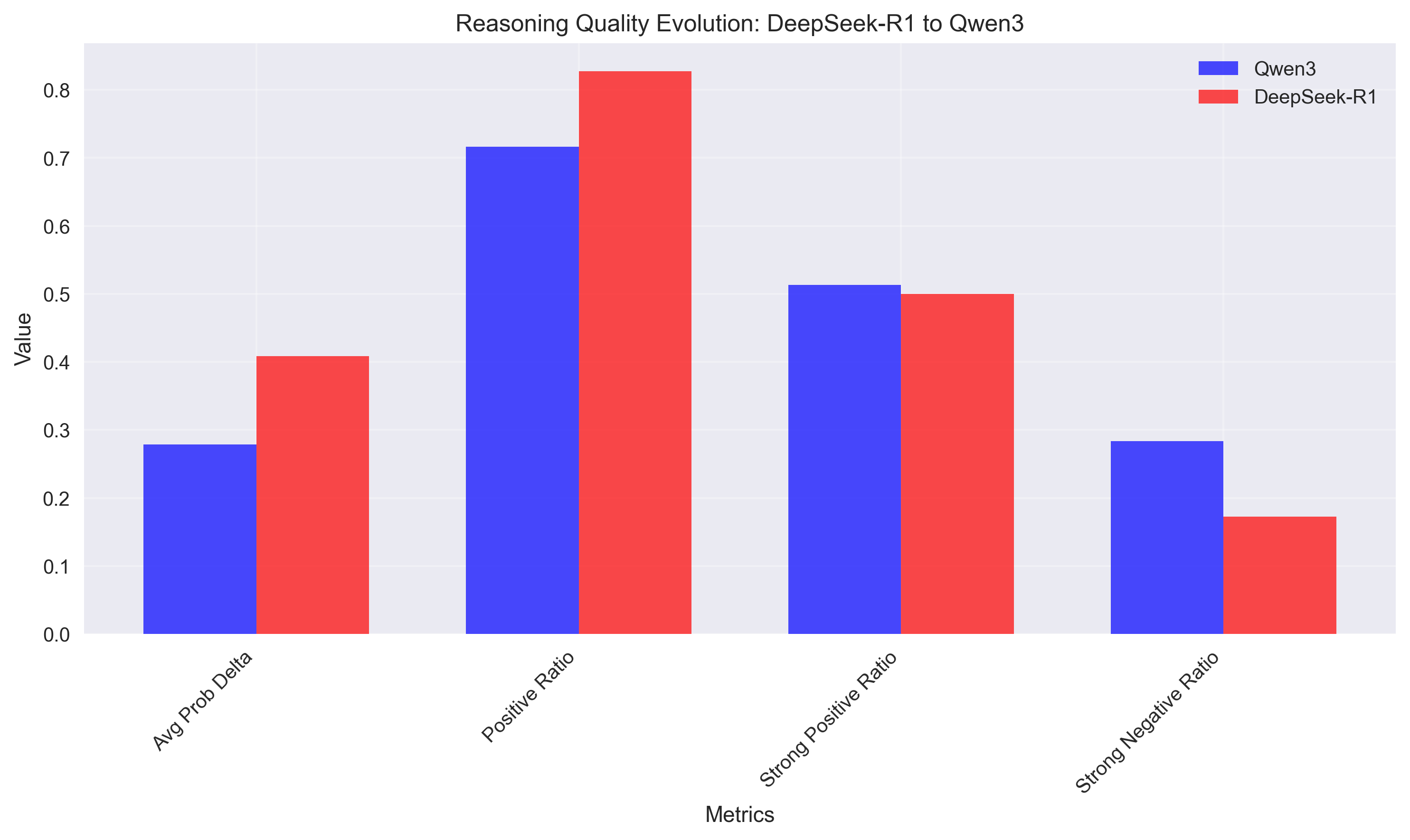
发现1:集中式与分布式推理策略
模型展现出根本不同的推理影响模式:
- DeepSeek-R1:平均 prob_delta 为 0.408(集中式推理)
- Qwen3:平均 prob_delta 为 0.278(分布式推理)
重要背景:DeepSeek-R1 是一个更大的模型(1.5B 参数),与 Qwen3(0.6B 参数)相比,并且似乎通过从更大的以推理为重点的模型中蒸馏而优化用于推理任务。
这揭示了什么:这些不同的 prob_delta 值并非表明优劣,而是暗示了不同的推理架构:
- DeepSeek-R1:更少的高影响力推理步骤——集中的认知努力
- Qwen3:更分布式的推理,影响力分散到多个步骤
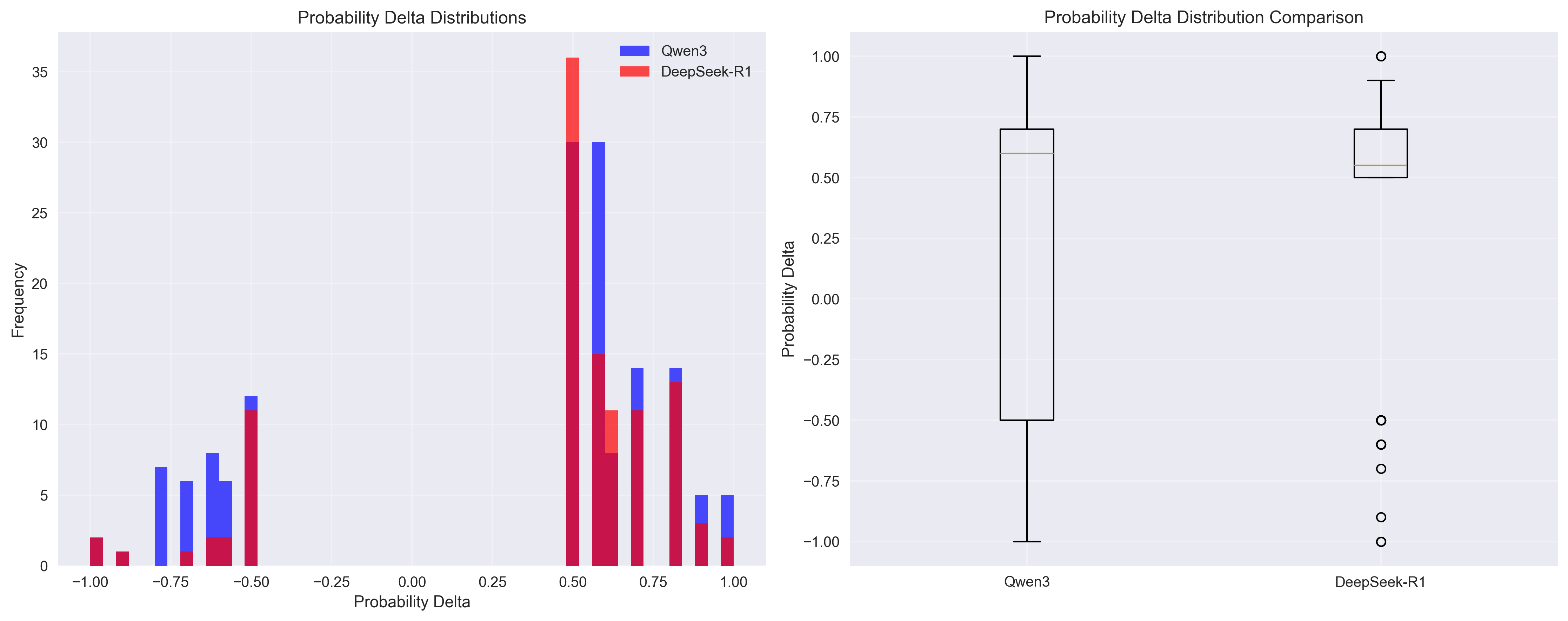
发现2:推理中的风险-回报概况
模型展现出反映其架构差异的独特风险-回报概况:
DeepSeek-R1:高置信度,一致性方法
- 更高的正向比率(82.7% 对 71.6%)
- 更紧密地围绕正值分布
- 更可预测的推理模式
- 风险调整质量得分:0.845
- 策略:更少、更可靠的推理步骤
Qwen3:探索性,高方差方法
- 更宽的影响分布
- 更极端的正负值
- 推理质量方差更高
- 风险调整质量得分:0.466
- 策略:更具实验性的推理,具有更高的潜在收益和风险
发现3:推理复杂性与可靠性之间的权衡
模型在推理复杂性与可靠性之间表现出不同的权衡:
Qwen3 - 复杂、多模式失败(3 种类型):
- 逻辑错误:32 例
- 计算错误:6 例
- 步骤缺失:4 例
- 解释:尝试更复杂的推理链,具有多种失败点
DeepSeek-R1 - 集中、一致的失败(1 种类型):
- 逻辑错误:19 例
- 解释:保持更简单、更集中的推理,失败模式集中
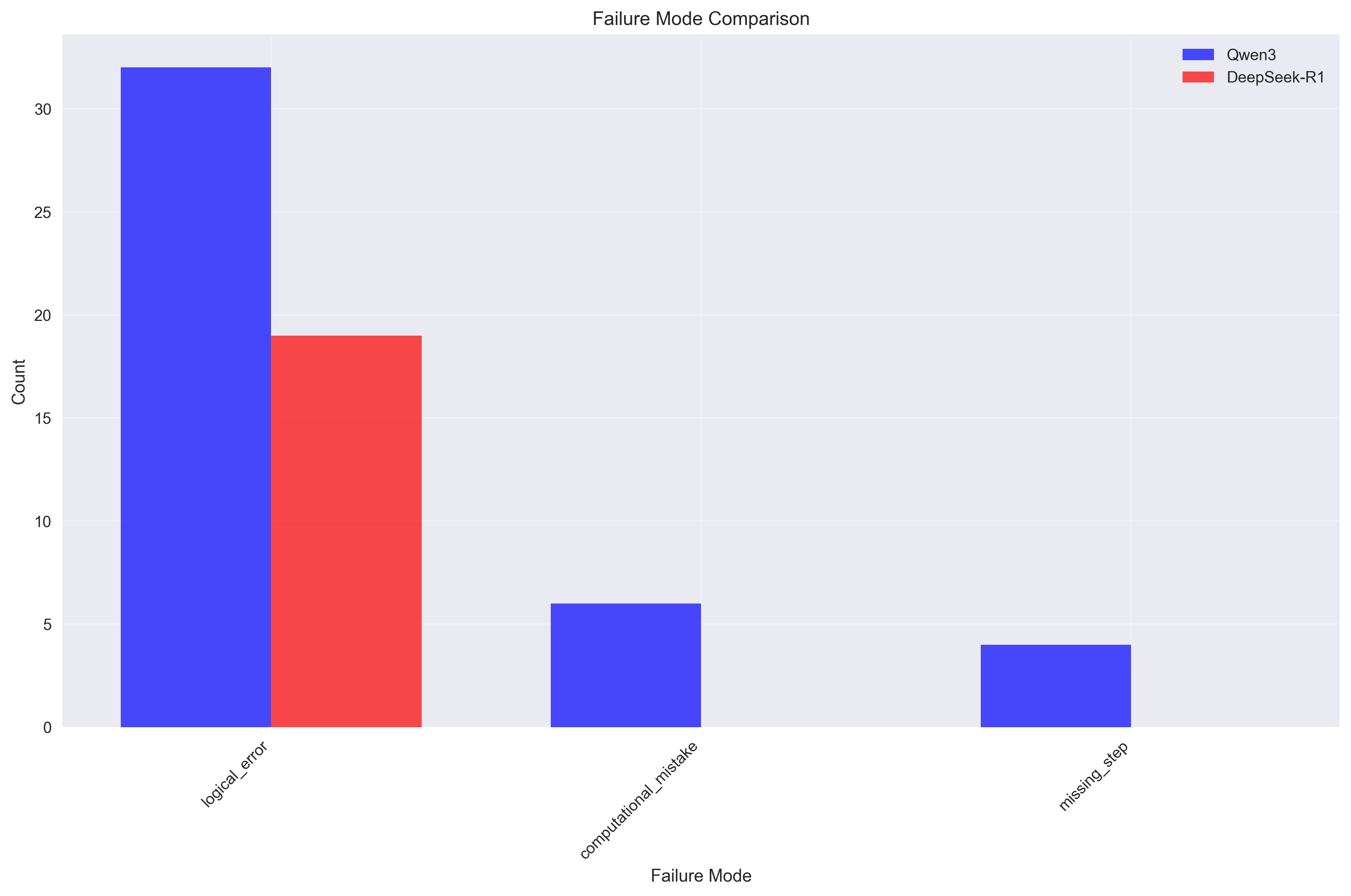
关键洞察:这揭示了推理系统设计中的根本权衡
- Qwen3:更高的复杂性 → 更多样化的能力,但也更多的失败模式
- DeepSeek-R1:更低的复杂性 → 更可靠,但可能通用性较差的推理
机制可解释性见解
认知架构差异
我们的分析揭示了这些模型在推理方法上的根本差异:
1. 推理粒度与处理风格
- Qwen3:平均句子长度更长(58.0 个字符)→以更大、更整合的块处理信息
- DeepSeek-R1:平均句子长度更短(47.7 个字符)→采用更原子化、循序渐进的推理
2. 优化目标
- DeepSeek-R1:针对推理可靠性和一致性进行优化(从专注于推理的模型中蒸馏而来)
- Qwen3:针对更广泛的功能进行优化,推理是其中一个组成部分
3. 架构权衡
- DeepSeek-R1:牺牲探索性以换取可靠性
- Qwen3:牺牲一致性以换取推理多样性
4. 推理个性 嵌入分析揭示了独特的聚类模式,表明模型已发展出不同的“推理个性”

案例研究:推理的实际应用
最具影响力的正面示例
Qwen3 (prob_delta = 1.000):
- 查询:“马克有一个花园,里面种着花。他种了三种不同颜色的植物……”
- 关键句子:“首先,我们需要弄清楚每种颜色的花朵数量……”
- 影响:这种系统的方法立即阐明了问题结构
DeepSeek-R1 (prob_delta = 1.000):
- 查询:“肯准备了一个包裹寄给他的兄弟……”
- 关键句子:“接下来,他添加了2 磅的软糖……”
- 影响:精确的量化和强调促使成功
最具影响力的负面示例
Qwen3 (prob_delta = -1.000):
- 查询:“斯奈德夫人过去将月收入的 40% 用于房租……”
- 关键句子:“4x = 0……”
- 失败模式:缺少步骤
- 影响:不完整的方程设置使整个解决方案脱轨
DeepSeek-R1 (prob_delta = -1.000):
- 查询:“利奥的任务分为三个部分……”
- 关键句子:“25 加 50 等于 75……”
- 失败模式:逻辑错误
- 影响:不正确的算术导致错误的结论
方法论与可复现性
思维锚点生成
所有思维锚点均使用相同的程序生成,以确保公平比较:
步骤 1:数据准备
- 两个模型都在相同的 GSM8K 问题上进行评估
- 使用
<think>标签进行推理的一致提示格式 - 用于成功评估的相同数学预言机
步骤 2:思维锚点提取
# Generate thought anchors for Qwen3
pts run --model="Qwen/Qwen3-0.6B" --dataset="gsm8k" --output-path="qwen3_thought_anchors.jsonl" --generate-thought-anchors
# Generate thought anchors for DeepSeek-R1
pts run --model="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B" --dataset="gsm8k" --output-path="deepseek_thought_anchors.jsonl" --generate-thought-anchors
# Export to HuggingFace
pts export --input-path="qwen3_thought_anchors.jsonl" --format="thought_anchors" --output-path="qwen3_export.jsonl"
pts export --input-path="deepseek_thought_anchors.jsonl" --format="thought_anchors" --output-path="deepseek_export.jsonl"
步骤 3:比较分析 所有分析均可使用我们的开源工具完全复现
- 数据收集:使用 PTS 库 在 GSM8K 上生成
- 分析管道:在分析存储库中可用
- 可视化:使用 matplotlib、seaborn 和 plotly 创建
- 统计分析:标准 scipy 和 numpy 方法
相同的生成过程确保观察到的差异反映的是真实的模型特性,而不是实验伪影。
局限性与未来工作
当前局限性
- 数据集大小:分别限制为 148 和 110 个思维锚点
- 领域特异性:专注于数学推理任务
- 模型大小:分析限于较小型模型(0.6B 和 1.5B 参数)
- 时间快照:单点分析,无纵向跟踪
未来方向
- 规模分析:扩展到更大的模型(7B、13B、70B 参数)
- 多领域:分析不同任务类型的推理
- 时间演化:跟踪模型训练过程中的推理变化
- 干预研究:通过实验测试因果关系
- 混合架构:开发结合两种推理方法的模型
结论
本研究展示了思维锚点作为理解模型推理的机制可解释性工具的强大功能。我们的主要发现揭示了语言模型推理架构多样性的根本见解:
- 不同的架构,而非优劣之分:模型针对不同的推理目标进行优化(一致性与探索性)
- 集中式与分布式推理:DeepSeek-R1 使用更少、高影响力的步骤,而 Qwen3 将推理分散到多个步骤
- 复杂性-可靠性权衡:更复杂的推理导致多样化的能力,但也带来多样化的失败模式
- 上下文依赖的优势:两种方法都不是普遍优越的——性能取决于应用需求
思维锚点方法,通过我们的 PTS 库实现,提供了一种可扩展的方法来理解模型推理,可应用于不同的架构、规模和领域。我们鼓励社区在此工作的基础上,开发更好的可解释性工具和更有效的人工智能系统。
参考文献
- Bogdan, P. C., Macar, U., Nanda, N., & Conmy, A. (2025). Thought Anchors: Which LLM Reasoning Steps Matter? arXiv preprint arXiv:2506.19143. 检索自 https://arxiv.org/abs/2506.19143
资源
- PTS 库:https://github.com/codelion/pts
- Qwen3 数据集:codelion/Qwen3-0.6B-pts-thought-anchors
- DeepSeek 数据集:codelion/DeepSeek-R1-Distill-Qwen-1.5B-pts-thought-anchors
- 分析代码:https://github.com/codelion/pts/tree/main/thought_anchors_analysis
本研究使用 Pivotal Token Search (PTS) 库进行机制可解释性分析。所有数据集和分析代码均可用于复现。