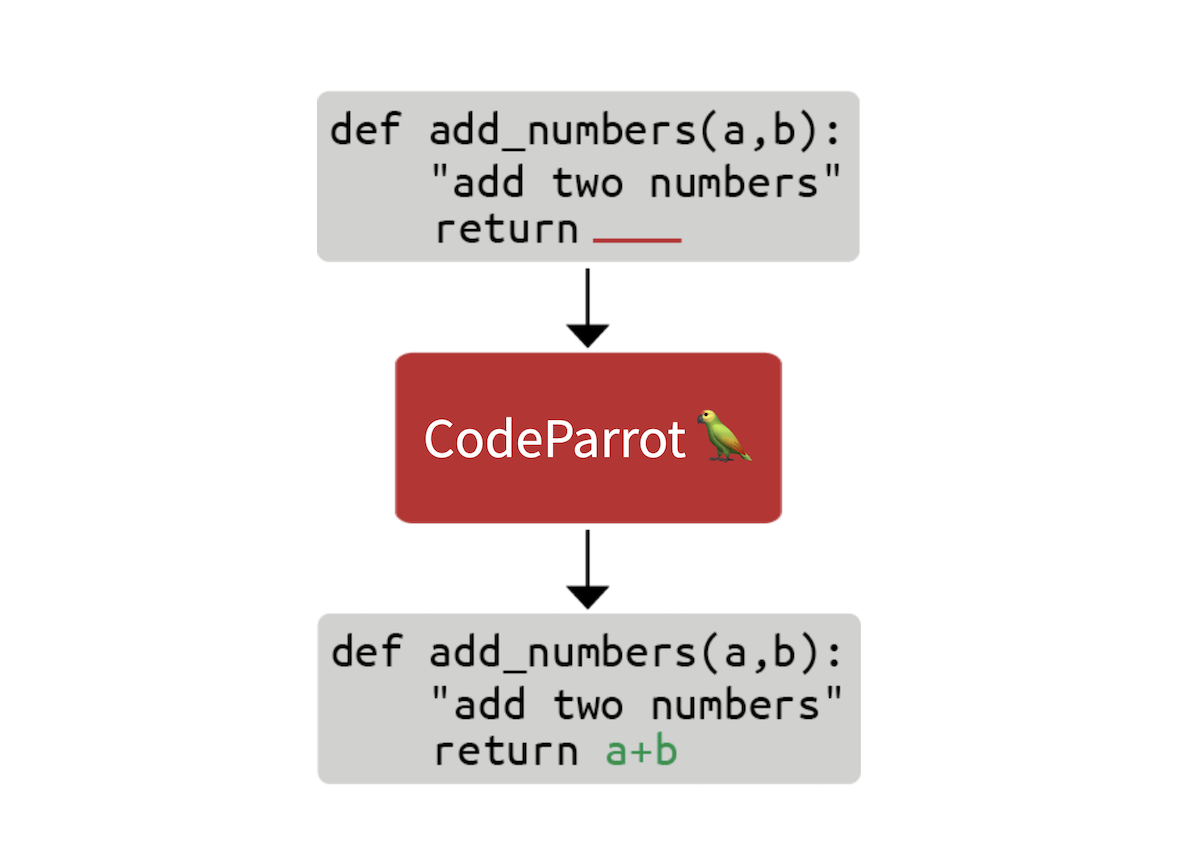
从零开始训练 CodeParrot 🦜







在这篇博客文章中,我们将探讨构建 GitHub CoPilot 背后的技术需要什么。GitHub CoPilot 是一个在程序员编码时提供建议的应用程序。在这个分步指南中,我们将学习如何从零开始训练一个名为 CodeParrot 🦜 的大型 GPT-2 模型。CodeParrot 可以自动完成你的 Python 代码 - 在这里试试看。让我们开始从零构建它吧!
创建大型源代码数据集
我们首先需要一个大型训练数据集。为了训练一个 Python 代码生成模型,我们访问了 Google BigQuery 上可用的 GitHub 数据转储,并筛选出所有 Python 文件。结果是一个 180 GB 的数据集,包含 2000 万个文件(可在此处获取:here)。经过初步训练实验后,我们发现数据集中的重复项严重影响了模型性能。进一步调查数据集后,我们发现:
- 0.1% 的唯一文件占所有文件的 15%
- 1% 的唯一文件占所有文件的 35%
- 10% 的唯一文件占所有文件的 66%
你可以在此 Twitter 帖子中了解更多我们的发现。我们删除了重复项,并应用了Codex 论文中发现的相同清理启发式方法。Codex 是 CoPilot 背后的模型,它是一个在 GitHub 代码上进行微调的 GPT-3 模型。
清理后的数据集仍然有 50GB 大小,可在 Hugging Face Hub 上获取:codeparrot-clean。有了这些,我们就可以设置一个新的分词器并训练模型。
初始化分词器和模型
首先我们需要一个分词器。让我们专门针对代码进行训练,以便它能很好地分割代码标记。我们可以采用现有的分词器(例如 GPT-2),并使用 train_new_from_iterator() 方法直接在我们的数据集上训练它。然后我们将其推送到 Hub。请注意,我们从代码示例中省略了导入、参数解析和日志记录,以保持代码块紧凑。但是你可以在这里找到包括预处理和下游任务评估在内的完整代码。
# Iterator for Training
def batch_iterator(batch_size=10):
for _ in tqdm(range(0, args.n_examples, batch_size)):
yield [next(iter_dataset)["content"] for _ in range(batch_size)]
# Base tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
base_vocab = list(bytes_to_unicode().values())
# Load dataset
dataset = load_dataset("lvwerra/codeparrot-clean", split="train", streaming=True)
iter_dataset = iter(dataset)
# Training and saving
new_tokenizer = tokenizer.train_new_from_iterator(batch_iterator(),
vocab_size=args.vocab_size,
initial_alphabet=base_vocab)
new_tokenizer.save_pretrained(args.tokenizer_name, push_to_hub=args.push_to_hub)
在Hugging Face 课程中了解更多关于分词器以及如何构建它们。
看到那个不起眼的 `streaming=True` 参数了吗?这个小小的改动影响巨大:它不再下载完整的(50GB)数据集,而是根据需要流式传输单个样本,从而节省了大量磁盘空间!请查看Hugging Face 课程以获取更多关于流式传输的信息。
现在,我们初始化一个新模型。我们将使用与 GPT-2 大型模型(1.5B 参数)相同的超参数,并调整嵌入层以适应我们的新分词器,同时增加一些稳定性调整。`scale_attn_by_layer_idx` 标志确保我们按层 ID 缩放注意力,而 `reorder_and_upcast_attn` 主要确保我们以全精度计算注意力以避免数值问题。我们将新初始化的模型推送到与分词器相同的仓库。
# Load codeparrot tokenizer trained for Python code tokenization
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name)
# Configuration
config_kwargs = {"vocab_size": len(tokenizer),
"scale_attn_by_layer_idx": True,
"reorder_and_upcast_attn": True}
# Load model with config and push to hub
config = AutoConfig.from_pretrained('gpt2-large', **config_kwargs)
model = AutoModelForCausalLM.from_config(config)
model.save_pretrained(args.model_name, push_to_hub=args.push_to_hub)
现在我们有了一个高效的分词器和一个全新初始化的模型,我们可以开始实际的训练循环了。
实现训练循环
我们使用 🤗 Accelerate 库进行训练,该库允许我们将训练从笔记本扩展到多 GPU 机器,而无需更改一行代码。我们只需创建一个加速器并进行一些参数整理。
accelerator = Accelerator()
acc_state = {str(k): str(v) for k, v in accelerator.state.__dict__.items()}
parser = HfArgumentParser(TrainingArguments)
args = parser.parse_args()
args = Namespace(**vars(args), **acc_state)
samples_per_step = accelerator.state.num_processes * args.train_batch_size
set_seed(args.seed)
现在,我们已经准备好进行训练了!让我们使用 `huggingface_hub` 客户端库来克隆包含新分词器和模型的仓库。我们将为此实验切换到一个新分支。通过这种设置,我们可以并行运行许多实验,最后只需将最好的一个合并到主分支。
# Clone model repository
if accelerator.is_main_process:
hf_repo = Repository(args.save_dir, clone_from=args.model_ckpt)
# Checkout new branch on repo
if accelerator.is_main_process:
hf_repo.git_checkout(run_name, create_branch_ok=True)
我们可以直接从本地仓库加载分词器和模型。由于我们处理的是大型模型,我们可能希望开启梯度检查点,以减少训练期间的 GPU 内存占用。
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(args.save_dir)
if args.gradient_checkpointing:
model.gradient_checkpointing_enable()
tokenizer = AutoTokenizer.from_pretrained(args.save_dir)
接下来是数据集。我们使用一个能生成固定上下文大小样本的数据集,使训练更简单。为了不过多浪费数据(有些样本太短或太长),我们可以将多个示例与 EOS 标记连接起来,然后分块。
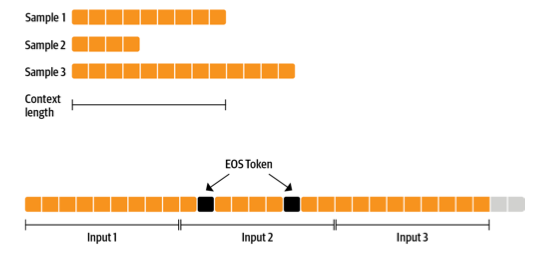
我们一起准备的序列越多,我们丢弃的令牌(上一图中灰色部分)的比例就越小。由于我们希望流式传输数据集而不是预先准备所有内容,因此我们使用 `IterableDataset`。完整的数据集类如下所示
class ConstantLengthDataset(IterableDataset):
def __init__(
self, tokenizer, dataset, infinite=False, seq_length=1024, num_of_sequences=1024, chars_per_token=3.6
):
self.tokenizer = tokenizer
self.concat_token_id = tokenizer.bos_token_id
self.dataset = dataset
self.seq_length = seq_length
self.input_characters = seq_length * chars_per_token * num_of_sequences
self.epoch = 0
self.infinite = infinite
def __iter__(self):
iterator = iter(self.dataset)
more_examples = True
while more_examples:
buffer, buffer_len = [], 0
while True:
if buffer_len >= self.input_characters:
break
try:
buffer.append(next(iterator)["content"])
buffer_len += len(buffer[-1])
except StopIteration:
if self.infinite:
iterator = iter(self.dataset)
self.epoch += 1
logger.info(f"Dataset epoch: {self.epoch}")
else:
more_examples = False
break
tokenized_inputs = self.tokenizer(buffer, truncation=False)["input_ids"]
all_token_ids = []
for tokenized_input in tokenized_inputs:
all_token_ids.extend(tokenized_input + [self.concat_token_id])
for i in range(0, len(all_token_ids), self.seq_length):
input_ids = all_token_ids[i : i + self.seq_length]
if len(input_ids) == self.seq_length:
yield torch.tensor(input_ids)
缓冲区中的文本将并行分词并连接起来。然后,分块的样本将被生成,直到缓冲区为空,然后该过程重新开始。如果我们将 `infinite` 设置为 `True`,数据集迭代器将在其末尾重新启动。
def create_dataloaders(args):
ds_kwargs = {"streaming": True}
train_data = load_dataset(args.dataset_name_train, split="train", streaming=True)
train_data = train_data.shuffle(buffer_size=args.shuffle_buffer, seed=args.seed)
valid_data = load_dataset(args.dataset_name_valid, split="train", streaming=True)
train_dataset = ConstantLengthDataset(tokenizer, train_data, infinite=True, seq_length=args.seq_length)
valid_dataset = ConstantLengthDataset(tokenizer, valid_data, infinite=False, seq_length=args.seq_length)
train_dataloader = DataLoader(train_dataset, batch_size=args.train_batch_size)
eval_dataloader = DataLoader(valid_dataset, batch_size=args.valid_batch_size)
return train_dataloader, eval_dataloader
train_dataloader, eval_dataloader = create_dataloaders(args)
在开始训练之前,我们需要设置优化器和学习率调度器。我们不想对偏差和 LayerNorm 权重应用权重衰减,因此我们使用一个辅助函数来排除它们。
def get_grouped_params(model, args, no_decay=["bias", "LayerNorm.weight"]):
params_with_wd, params_without_wd = [], []
for n, p in model.named_parameters():
if any(nd in n for nd in no_decay): params_without_wd.append(p)
else: params_with_wd.append(p)
return [{"params": params_with_wd, "weight_decay": args.weight_decay},
{"params": params_without_wd, "weight_decay": 0.0},]
optimizer = AdamW(get_grouped_params(model, args), lr=args.learning_rate)
lr_scheduler = get_scheduler(name=args.lr_scheduler_type, optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.max_train_steps,)
一个大问题是所有数据和模型将如何分布在多个 GPU 上。这听起来像是一项复杂的任务,但实际上只需要 🤗 Accelerate 的一行代码即可。
model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader)
在底层,它会使用分布式数据并行(DistributedDataParallel),这意味着每个批次都会被发送到每个拥有自己模型副本的 GPU 工作器。在那里,梯度会被计算,然后聚合以更新每个工作器上的模型。

我们还想时不时地在验证集上评估模型,所以让我们写一个函数来完成这项任务。这会自动以分布式方式完成,我们只需要从工作节点收集所有损失即可。我们还想报告困惑度。
def evaluate(args):
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(batch, labels=batch)
loss = outputs.loss.repeat(args.valid_batch_size)
losses.append(accelerator.gather(loss))
if args.max_eval_steps > 0 and step >= args.max_eval_steps:
break
loss = torch.mean(torch.cat(losses))
try:
perplexity = torch.exp(loss)
except OverflowError:
perplexity = float("inf")
return loss.item(), perplexity.item()
我们现在准备好编写主训练循环了。它看起来很像一个普通的 PyTorch 训练循环。在这里和那里,你可以看到我们使用的是加速器函数而不是原生的 PyTorch。此外,每次评估后,我们都会将模型推送到分支。
# Train model
model.train()
completed_steps = 0
for step, batch in enumerate(train_dataloader, start=1):
loss = model(batch, labels=batch, use_cache=False).loss
loss = loss / args.gradient_accumulation_steps
accelerator.backward(loss)
if step % args.gradient_accumulation_steps == 0:
accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
completed_steps += 1
if step % args.save_checkpoint_steps == 0:
eval_loss, perplexity = evaluate(args)
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.save_dir, save_function=accelerator.save)
if accelerator.is_main_process:
hf_repo.push_to_hub(commit_message=f"step {step}")
model.train()
if completed_steps >= args.max_train_steps:
break
当我们调用 `wait_for_everyone()` 和 `unwrap_model()` 时,我们确保所有工作器都已准备就绪,并且早期由 `prepare()` 添加的任何模型层都已移除。我们还使用了易于实现的梯度累积和梯度裁剪。最后,训练完成后,我们运行最后一次评估并保存最终模型,然后将其推送到 Hub。
# Evaluate and save the last checkpoint
logger.info("Evaluating and saving model after training")
eval_loss, perplexity = evaluate(args)
log_metrics(step, {"loss/eval": eval_loss, "perplexity": perplexity})
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(args.save_dir, save_function=accelerator.save)
if accelerator.is_main_process:
hf_repo.push_to_hub(commit_message="final model")
完成!这就是训练一个完整的 GPT-2 模型从头开始所需的所有代码,仅有不到 150 行。我们没有展示脚本的导入和日志,以使代码更紧凑。现在,让我们实际训练它吧!
有了这段代码,我们为即将出版的《Transformer 和自然语言处理》一书训练了模型:一个拥有 1.1 亿和 15 亿参数的 GPT-2 模型。我们使用一台 16 x A100 GPU 机器分别训练了这些模型 1 天和 1 周。足够的时间喝杯咖啡,读一两本书了!
评估
这对于预训练来说仍然是相对较短的训练时间,但我们已经可以观察到与类似模型相比良好的下游性能。我们根据 Codex 论文中引入的 OpenAI HumanEval 基准对模型进行了评估。它衡量了代码生成模型在近 200 个编程挑战上的性能。

请注意,CodeParrot 大约训练了 25-30B 个 token,而 GPT-neo 训练了 300B 个 token,Codex 训练了 300B (GPT-3 检查点) + 100B (代码) 个 token。因此,在这里你绝对物有所值。
但是,这个 *pass@k* 指标到底是什么?简单来说,它衡量的是给定模型生成的 *k* 个候选程序中,至少有一个程序通过编程问题单元测试的概率。自然,随着 k 的增加,该指标也会增加,因为更多的候选程序有可能解决编码挑战。你可以使用 `datasets` 来使用该指标
from datasets import load_metric
code_eval = datasets.load_metric("code_eval")
test_cases = ["assert add(2,3)==5"]
candidates = [["def add(a,b): return a*b", "def add(a, b): return a+b"]]
pass_at_k, results = code_eval.compute(references=test_cases, predictions=candidates, k=[1, 2])
print(pass_at_k)
# -> {'pass@1': 0.5, 'pass@2': 1.0}
您还可以使用 `datasets` 加载 OpenAI 的 HumanEval 数据集
from datasets import load_dataset
dataset = load_dataset("openai_humaneval")
现在,让我们看看漫长等待之后我们得到了什么!
结果
我们先从简单的开始,检查模型是否能编写一个函数,根据文件路径返回文件大小:
提示
def get_files_size(filename):
完成
"""
Returns the file size of a file.
:param filepath: The path to the file.
:type filepath: str
:return: The file size.
:rtype: int
"""
return os.path.getsize(filepath)
到目前为止一切顺利,但让我们更进一步,尝试一些更有趣的事情。构建生产就绪代码中最不令人兴奋的方面之一就是编写单元测试。让我们看看能否使用 CodeParrot 为我们完成这项工作!
提示
def is_even(value):
"""Returns True if value is an even number."""
return value % 2 == 0
# setup unit tests for is_even
import unittest
完成
class TestIsEven(unittest.TestCase):
"""Tests for is_even function."""
def test_is_even(self):
"""Test is_even function."""
self.assertTrue(is_even(0))
self.assertTrue(is_even(1))
self.assertTrue
尽管测试条件本身看起来不太对劲,但模型已经为我们构建了所有样板代码。仅此一项就可能非常有用,可以为我们节省几分钟时间!
但我们真正想要做的是构建更好的 Transformer 模型。让我们使用 CodeParrot 来帮助我们实现这一点。
提示
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# build a BERT classifier
完成
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased')
看几个例子固然不错,但现在你可能想亲自尝试一下。我们为此准备了一些在线演示!
演示
您可以在我们添加到 Hugging Face Spaces 的两个演示中试用这些模型。第一个演示可以让你快速生成代码,而第二个演示则可以让你用模型高亮显示代码以发现错误!
您也可以直接使用 `transformers` 库中的模型
from transformers import pipeline
pipe = pipeline('text-generation', model='lvwerra/codeparrot')
pipe('def hello_world():')
总结
在这篇简短的博客文章中,我们详细介绍了训练大型 GPT-2 模型 CodeParrot 🦜 用于代码生成的所有步骤。通过使用 🤗 Accelerate,我们构建了一个不到 200 行代码的训练脚本,该脚本可以轻松地扩展到多个 GPU。有了它,你现在就可以训练自己的 GPT-2 模型了!
这篇帖子简要介绍了 CodeParrot 🦜,但如果你对深入了解如何预训练这些模型感兴趣,我们建议阅读即将出版的《Transformer 和自然语言处理》一书中专门的章节。该章节提供了更多关于构建自定义数据集、训练新分词器时的设计考虑以及架构选择的详细信息。