使用 Hugging Face Optimum 将 Transformers 模型转换为 ONNX







每天都有成百上千的 Transformers 实验和模型被上传到 Hugging Face Hub。进行这些实验的机器学习工程师和学生使用各种框架,如 PyTorch、TensorFlow/Keras 等。这些模型已经被数千家公司使用,并构成了 AI 驱动产品的基础。
如果您在生产环境中部署 Transformers 模型,我们建议首先将它们导出为一种序列化格式,以便在专门的运行时和硬件上加载、优化和执行。
在本指南中,您将了解到:
让我们开始吧!🚀
如果您有兴趣优化您的模型以实现最高效率运行,请查看 🤗 Optimum 库。
1. 什么是 ONNX?
ONNX 或开放神经网络交换 (Open Neural Network eXchange) 是一种表示机器学习模型的开放标准和格式。ONNX 定义了一套通用的算子和一个通用的文件格式,用于在包括 PyTorch 和 TensorFlow 在内的各种框架中表示深度学习模型。
当模型导出为 ONNX 格式时,这些算子被用来构建一个计算图 (通常称为“中间表示”),它表示数据在神经网络中的流动过程。
重要提示: ONNX 不是一个运行时。ONNX 仅是一种表示格式,可以与像 ONNX Runtime 这样的运行时一起使用。您可以在这里找到支持的加速器列表。
2. 什么是 Hugging Face Optimum?
Hugging Face Optimum 是一个开源库,是 Hugging Face Transformers 的扩展,它提供了一个统一的性能优化工具 API,以在加速硬件上实现训练和运行模型的最大效率,包括用于在 Graphcore IPU 和 Habana Gaudi 上优化性能的工具包。
Optimum 可用于转换、量化、图优化、加速训练和推理,并支持 transformers pipelines。
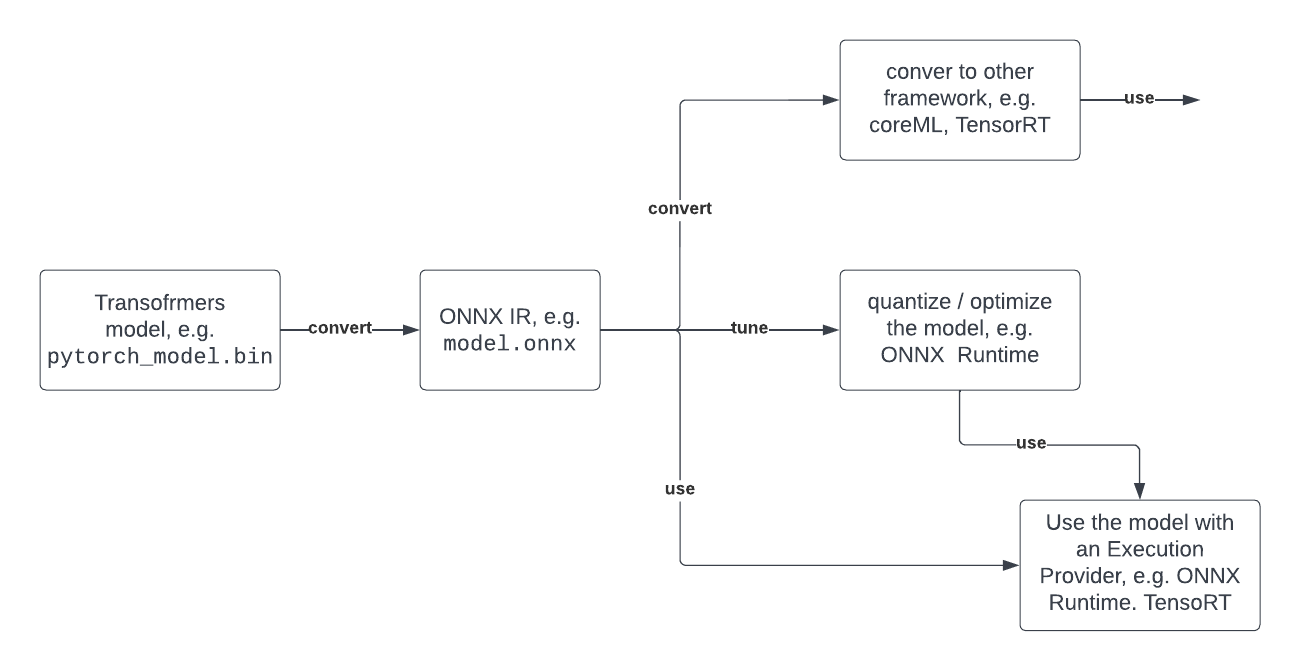
下面您可以看到一个典型的开发者旅程,展示了如何利用 Optimum 和 ONNX。
3. 支持哪些 Transformers 架构?
所有支持的 Transformers 架构列表可以在 Transformers 文档的 ONNX 部分中找到。以下是可转换为 ONNX 并使用 Hugging Face Optimum 优化的最常用架构的摘录:
- ALBERT
- BART
- BERT
- DistilBERT
- ELECTRA
- GPT Neo
- GPT-J
- GPT-2
- RoBERTa
- T5
- ViT
- XLM
- ...
4. 如何将 Transformers 模型 (BERT) 转换为 ONNX?
目前有三种方法可以将您的 Hugging Face Transformers 模型转换为 ONNX。在本节中,您将学习如何使用所有三种方法导出用于“文本分类”的 distilbert-base-uncased-finetuned-sst-2-english,从底层的 torch API 到最用户友好的高层 optimum API。每种方法都会做完全相同的事情。
使用 torch.onnx 导出 (底层)
torch.onnx 允许您通过 export 方法将模型检查点转换为 ONNX 图。但您必须提供许多值,如 input_names、dynamic_axes 等。
您首先需要安装一些依赖项
pip install transformers torch
使用 export 导出我们的检查点
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# load model and tokenizer
model_id = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
dummy_model_input = tokenizer("This is a sample", return_tensors="pt")
# export
torch.onnx.export(
model,
tuple(dummy_model_input.values()),
f="torch-model.onnx",
input_names=['input_ids', 'attention_mask'],
output_names=['logits'],
dynamic_axes={'input_ids': {0: 'batch_size', 1: 'sequence'},
'attention_mask': {0: 'batch_size', 1: 'sequence'},
'logits': {0: 'batch_size', 1: 'sequence'}},
do_constant_folding=True,
opset_version=13,
)
使用 transformers.onnx 导出 (中层)
transformers.onnx 允许您通过利用配置对象将模型检查点转换为 ONNX 图。这样您就不必为 dynamic_axes 等提供复杂的配置。
您首先需要安装一些依赖项
pip install transformers[onnx] torch
使用 transformers.onnx 导出我们的检查点。
from pathlib import Path
import transformers
from transformers.onnx import FeaturesManager
from transformers import AutoConfig, AutoTokenizer, AutoModelForSequenceClassification
# load model and tokenizer
model_id = "distilbert-base-uncased-finetuned-sst-2-english"
feature = "sequence-classification"
model = AutoModelForSequenceClassification.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
# load config
model_kind, model_onnx_config = FeaturesManager.check_supported_model_or_raise(model, feature=feature)
onnx_config = model_onnx_config(model.config)
# export
onnx_inputs, onnx_outputs = transformers.onnx.export(
preprocessor=tokenizer,
model=model,
config=onnx_config,
opset=13,
output=Path("trfs-model.onnx")
)
使用 Optimum 导出 (高层)
Optimum 推理包含使用 ORTModelForXxx 类将原生 Transformers 模型转换为 ONNX 的方法。要将您的 Transformers 模型转换为 ONNX,您只需向 from_pretrained() 方法传递 from_transformers=True,您的模型就会被加载并转换为 ONNX,其底层利用了 transformers.onnx 包。
您首先需要安装一些依赖项
pip install optimum[onnxruntime]
使用 ORTModelForSequenceClassification 导出我们的检查点
from optimum.onnxruntime import ORTModelForSequenceClassification
model = ORTModelForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english",from_transformers=True)
使用 Optimum 进行转换的最大好处是,您可以立即使用该 model 来运行预测,或将其加载到 pipeline 中。
5. 下一步是什么?
既然您已经成功将 Transformers 模型转换为 ONNX,现在就可以使用整套优化和量化工具了。可能的后续步骤包括:
- 使用 onnx 模型通过 Optimum 和 Transformers Pipelines 进行加速推理
- 对您的模型应用静态量化,以获得约 3 倍的延迟改进
- 使用 ONNX runtime 进行训练
- 将您的 ONNX 模型转换为 TensorRT 以提高 GPU 性能
- ...
如果您有兴趣优化您的模型以实现最高效率运行,请查看 🤗 Optimum 库。
感谢阅读!如果您有任何问题,请随时通过 Github 或在论坛上与我联系。您也可以在 Twitter 或 LinkedIn 上与我联系。



