Rank-Stabilized LoRA:释放LoRA微调的潜力







引言
随着大型语言模型(LLMs)对计算和内存的需求日益增长,参数高效微调(PEFT)方法已成为微调LLMs的常用策略。其中最受欢迎的PEFT方法之一,也是许多其他PEFT方法的基础,是低秩适应(LoRA)方法。LoRA的工作原理是固定原始预训练模型的参数,并向选定的层添加可训练的低秩“适配器”进行微调。
原始LoRA工作的一个重要发现是,使用非常低秩(即4到32)的适配器进行微调可以表现良好,并且这种性能不会随着秩的增加而进一步提高。然而,事实证明,这种在极低秩下性能饱和的主要原因并非学习流形的固有维度非常低,而是由于LoRA在极低适配器秩之外的学习受阻。
秩稳定LoRA(rsLoRA)方法证明了LoRA存在这一局限性,并且可以通过简单地将LoRA适配器除以其秩的平方根来纠正。
在这篇文章中,我们将概述rsLoRA PEFT方法,然后演示如何使用它通过直接偏好优化(DPO)对OpenChat 3.5模型进行人类反馈优化,以获得比LoRA显著优越的性能。rsLoRA方法现已在Hugging Face的PEFT软件包中提供,我们将提供示例代码,展示在使用该软件包配置LoRA时启用它有多么容易。
LoRA方法综述
LoRA架构通过在原始模型的部分权重矩阵中添加可调“适配器”来修改预训练模型。具体来说,适配器是(通常是低秩)矩阵乘积,它由可训练参数、,以及一个缩放因子,其中是一个超参数。请注意,适配器的矩阵秩至多为r。LoRA用以下形式替换了原始预训练权重矩阵:
当LoRA架构进行微调时,原始权重被冻结,只有被训练。
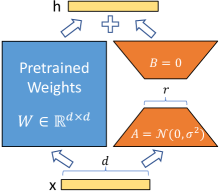
LoRA的主要优点是当时微调所需的时间和内存减少。在实践中,使用LoRA训练的秩非常低(例如4到32),例如,对于Mistral 7B或Llama 2 7B,这远低于其模型维度4096。这种用法是典型的,因为进一步增加LoRA适配器的秩并不会带来性能上的好处,反而会增加计算要求。正如我们将在下一节中看到的,这种限制是由缩放因子施加的,它减慢了此非常小秩范围之外的学习速度,并且通过用rsLoRA替换正确的适配器缩放因子,可以获得更高秩下的更好性能。
使用rsLORA的秩稳定适配器
在秩稳定LoRA(rsLoRA)的工作中,通过在秩较大时检查适配器的学习轨迹,理论上证明了为了不使每个适配器的激活和梯度幅度爆炸或减小,必须设置
这项工作还通过实验表明,这种缩放因子的设置可以随着秩的增加而改善学习,即使在低秩状态下也是如此。这些发现纠正了“非常低的适配器秩足以获得最大性能”这一持续存在的错误观念,这种观念一直过高估计了基础模型微调的固有维度是低维的程度。
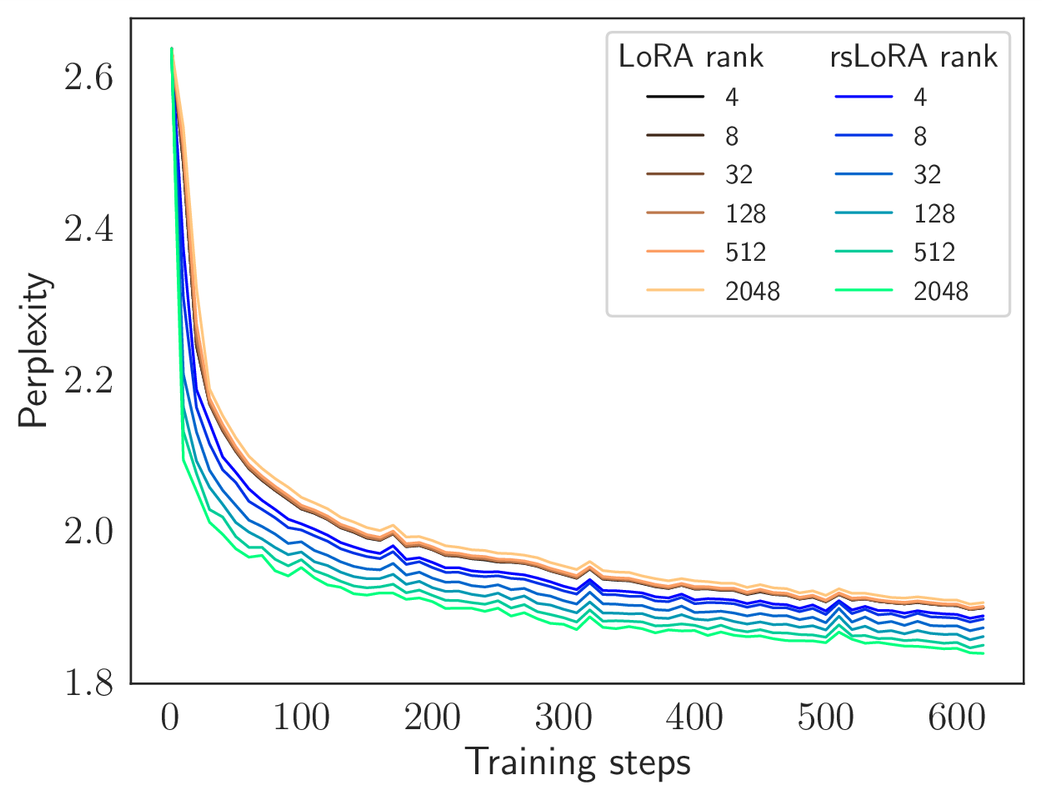
当然,对于了解这项工作的人来说,只需通过将每个适配器的超参数替换为适当的,就可以替换LoRA中的缩放因子,其中设置为
因此,
Hugging Face的PEFT软件包允许用户通过将LoRA配置中的选项use_rslora = True设置为自动执行此操作。具体而言,在初始化LoraConfig时,可以添加此标志,如下所示
from peft import LoraConfig, get_peft_model
base_model = AutoModelForCausalLM.from_pretrained(...)
# initialize the config as usual but with "use_rslora = True"
lora_config = LoraConfig(..., use_rslora = True)
peft_model = get_peft_model(base_model, lora_config)
在下一节中,我们将演示rsLoRA在微调中的优势和用法示例。
使用rsLoRA进行微调
为了说明rsLoRA与LoRA的用法和效用,我们以使用DPO在人类聊天偏好数据集UltraFeedback上微调OpenChat 3.5的实际用例进行演示,并随后对MT-Bench评估进行基准测试。
我们使用Hugging Face对齐调整包alignment-handbook来调整模型。设置训练所需的一切就是创建一个“recipe”yaml文件,该文件配置了我们训练和模型的参数。我们使用了示例配置alignment-handbook/recipes/zephyr-7b-beta/dpo/config_full.yaml中定义的所有默认值,除了LoRA参数的更改,以及为了与评估和OpenChat 3.5的提示结构保持一致而更改的聊天模板
# Model arguments
model_name_or_path: openchat/openchat_3.5
torch_dtype: auto
use_flash_attention_2: true
# LoRA arguments
use_peft: true
lora_r: 256
lora_alpha: 256 # using rsLoRA with an alpha of 16 and rank 256 means, lora_alpha = 16*(256**.5) = 256
lora_dropout: 0.1
lora_target_modules:
- q_proj
- k_proj
- o_proj
- up_proj
- gate_proj
# Data training arguments
# template used by OpenChat 3.5 in MT-Bench with FastChat
chat_template: "{{ bos_token }} {% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ 'GPT4 Correct User:' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ 'GPT4 Correct Assistant' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ 'GPT4 Correct Assistant:' }}{% endif %}\n{% endfor %}"
dataset_mixer:
HuggingFaceH4/ultrafeedback_binarized: 1.0
dataset_processing:
task: "dpo"
dataset_splits:
- train_prefs
- test_prefs
preprocessing_num_workers: 12
# DPOTrainer arguments
bf16: true
beta: 0.1
do_eval: true
evaluation_strategy: epoch
eval_steps: 100
gradient_accumulation_steps: 1
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: false
hub_model_id: openchat
learning_rate: 5.0e-7
log_level: info
logging_steps: 10
lr_scheduler_type: linear
max_length: 1024
max_prompt_length: 512
num_train_epochs: 1
optim: adafactor
output_dir: /home/ubuntu/openchat/openchat-rslora-r256
per_device_train_batch_size: 12
per_device_eval_batch_size: 12
push_to_hub: false
save_strategy: "no"
save_total_limit: null
seed: 42
warmup_ratio: 0.1
report_to: wandb
run_name: "openchat-rslora-r256"
然后,通过以下命令运行DPO训练
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file alignment-handbook/recipes/accelerate_configs/deepspeed_zero3.yaml alignment-handbook/scripts/run_dpo.py <path to recipe>.yaml
请再次注意,要默认使用rsLoRA而不是手动更改lora_alpha,只需在LoraConfig的初始化中添加use_rslora=True即可,这在alignment-handbook代码库中将在alignment-handbook/src/alignment /model_utils.py中进行更改
peft_config = LoraConfig(
r=model_args.lora_r,
lora_alpha=model_args.lora_alpha,
lora_dropout=model_args.lora_dropout,
bias="none",
task_type="CAUSAL_LM",
target_modules=model_args.lora_target_modules,
modules_to_save=model_args.lora_modules_to_save,
+ use_rslora=True
)
我们对rsLoRA运行了上述配置,使用了较低(但比LoRA通常使用的大)的秩256。为了与LoRA进行比较,我们将配置设置lora_alpha: 16进行了更改(别忘了同时更改output_dir)。我们还通过设置lora_r: 16运行了LoRA,以便与LoRA的典型用法进行比较。
我们在配备8个40GB Nvidia A100的节点上进行训练,秩256的训练时间为2小时19分22秒,秩16的训练时间为2小时06分45秒。这意味着在此设置下,训练低秩而不是极低秩(例如256 vs 16)的额外成本可以忽略不计,然而,正如我们在下一节的评估中看到的那样,rsLoRA可以释放更高秩的额外性能。
评估
为了评估我们模型的性能,我们使用FastChat包在MT-Bench上进行基准测试。我们按照该包的llm-judge readme中的说明运行MT-bench评估。
首先,使用以下命令生成我们模型对设置问题的响应
python fastchat/llm_judge/gen_model_answer.py --model-path [output_dir] --model-id openchat_3.5_[EXTRA_LABEL]
注意,[output_dir]应设置为我们在上面训练的yaml中配置的模型output_dir路径。这会将生成的答案保存到data/mt_bench/model_answer/openchat_3.5_[EXTRA_LABEL].jsonl中。
之后,我们运行基准测试脚本,该脚本使用GPT4对响应进行评分
export OPENAI_API_KEY=XXXXXX # set the OpenAI API key
python fastchat/llm_judge/gen_judgment.py --model-list openchat_3.5 openchat_3.5_lora_r16 openchat_3.5_lora_r256 openchat_3.5_rslora_r256
判断结果将保存到data/mt_bench/model_judgment/gpt-4_single.jsonl中。
最后,我们展示了选定模型的得分。
python show_result.py --model-list openchat_3.5 openchat_3.5_lora_r16 openchat_3.5_lora_r256 openchat_3.5_rslora_r256
| 模型 | MT-Bench 第一轮 | MT-Bench 第二轮 | MT-Bench 平均 |
|---|---|---|---|
| 基础模型:OpenChat 3.5 | 8.20625 | 7.375 | 7.790625 |
| 微调:LoRA 秩16 | 8.3375 | 7.525 | 7.93125 |
| 微调:LoRA 秩256 | 8.3 | 7.625 | 7.9625 |
| 微调:rsLoRA 秩256 | 8.425 | 7.75 | 8.0875 |
我们看到,两种方法都改善了原始的OpenChat 3.5模型,但LoRA秩16和秩256的训练差异不大,而rsLoRA解锁了更高秩的性能,几乎将基础模型和秩16 LoRA之间的差异增加了一倍,达到了8.0875的最佳分数,而且只增加了13分钟的训练时间!
结论
总之,rsLoRA方法不仅通过解锁更高适配器秩的有效使用来扩展可实现的性能范围,而且还提供了在计算资源和微调性能之间取得最佳平衡的灵活性。请务必使用rsLoRA进行秩稳定,以释放LoRA风格适配器的真正潜力!





