隆重推出 🤗 Data Measurements Tool:一个用于查看数据集的交互式工具



tl;dr: 我们开发了一个可以在线使用、用于构建、测量和比较数据集的工具。
点击此处访问 🤗 Data Measurements Tool。
作为快速增长的机器学习数据集统一存储库的开发者(Lhoest 等人,2021),🤗 Hugging Face 团队一直致力于支持数据集文档的良好实践(McMillan-Major 等人,2021)。虽然静态(如果不断发展)文档代表了这一方向的必要第一步,但要很好地了解数据集的实际内容,需要有充分理由的测量以及与之交互的能力,动态可视化感兴趣的不同方面。
为此,我们推出了一款名为 🤗 Data Measurements Tool 的开源 Python 库和无代码界面,它结合了我们的 Dataset 和 Spaces Hubs 以及出色的 Streamlit 工具。该工具可用于帮助理解、构建、管理和比较数据集。
什么是 🤗 Data Measurements Tool?
Data Measurements Tool (DMT) 是一个交互式界面和开源库,它允许数据集创建者和用户自动计算对于负责任的数据开发有意义和有用的指标。
我们为什么要创建这个工具?
在人工智能开发中,对机器学习数据集的深思熟虑的策划和分析常常被忽视。目前人工智能中“大数据”的规范(Luccioni 等人,2021,Dodge 等人,2021)包括使用从各种网站抓取的数据,很少或根本不关注不同数据源代表的具体测量,也不关注它们可能如何影响模型学习内容的细节。尽管数据集标注方法有助于整理更符合开发者目标的数据集,但“测量”这些数据集不同方面的方法相当有限(Sambasivan 等人,2021)。
人工智能领域的新一波研究呼吁,从根本上改变该领域处理机器学习数据集的方式(Paullada 等人,2020,Denton 等人,2021)。这包括从一开始就定义数据集创建的细粒度要求(Hutchinson 等人,2021),根据问题内容和偏见问题策划数据集(Yang 等人,2020,Prabhu 和 Birhane,2020),并明确数据集构建和维护中固有的价值观(Scheuerman 等人,2021,Birhane 等人,2021)。尽管人们普遍认为数据集开发是一项应由许多不同学科的人员参与的任务,但实际上,与原始数据本身进行交互时常常存在瓶颈,因为这通常需要复杂的编码技能才能分析和查询数据集。
尽管如此,目前公开可用的工具很少,无法让不同学科的人员测量、查询和比较数据集。我们旨在帮助填补这一空白。我们借鉴了诸如 Know Your Data 和 Data Quality for AI 等最新工具,以及数据集文档的研究提案,例如 Vision and Language Datasets (Ferraro 等人,2015)、Datasheets for Datasets (Gebru 等人,2018) 和 Data Statements (Bender & Friedman 2019)。结果是一个用于数据集测量的开源库,以及一个用于详细数据集分析的配套无代码界面。
我何时可以使用 🤗 Data Measurements Tool?
🤗 Data Measurements Tool 可用于迭代探索一个或多个现有 NLP 数据集,并且很快将支持从头开始迭代开发数据集。它提供了根据数据集研究和负责任的数据集开发而形成的实用见解,使用户能够深入了解高级信息和特定项目。
使用 🤗 Data Measurements Tool 我能学到什么?
数据集基础知识
对数据集进行高层次概览
这开始回答“这个数据集是什么?它是否有缺失项?”之类的问题。你可以将其用作“健全性检查”,以确保你正在处理的数据集符合你的预期。
数据集描述(来自 Hugging Face Hub)
缺失值或 NaN 的数量
描述性统计
查看数据集的表面特征
这开始回答“这个数据集包含什么样的语言?它的多样性如何?”之类的问题。
数据集词汇量大小和词语分布,包括开放类词和封闭类词。
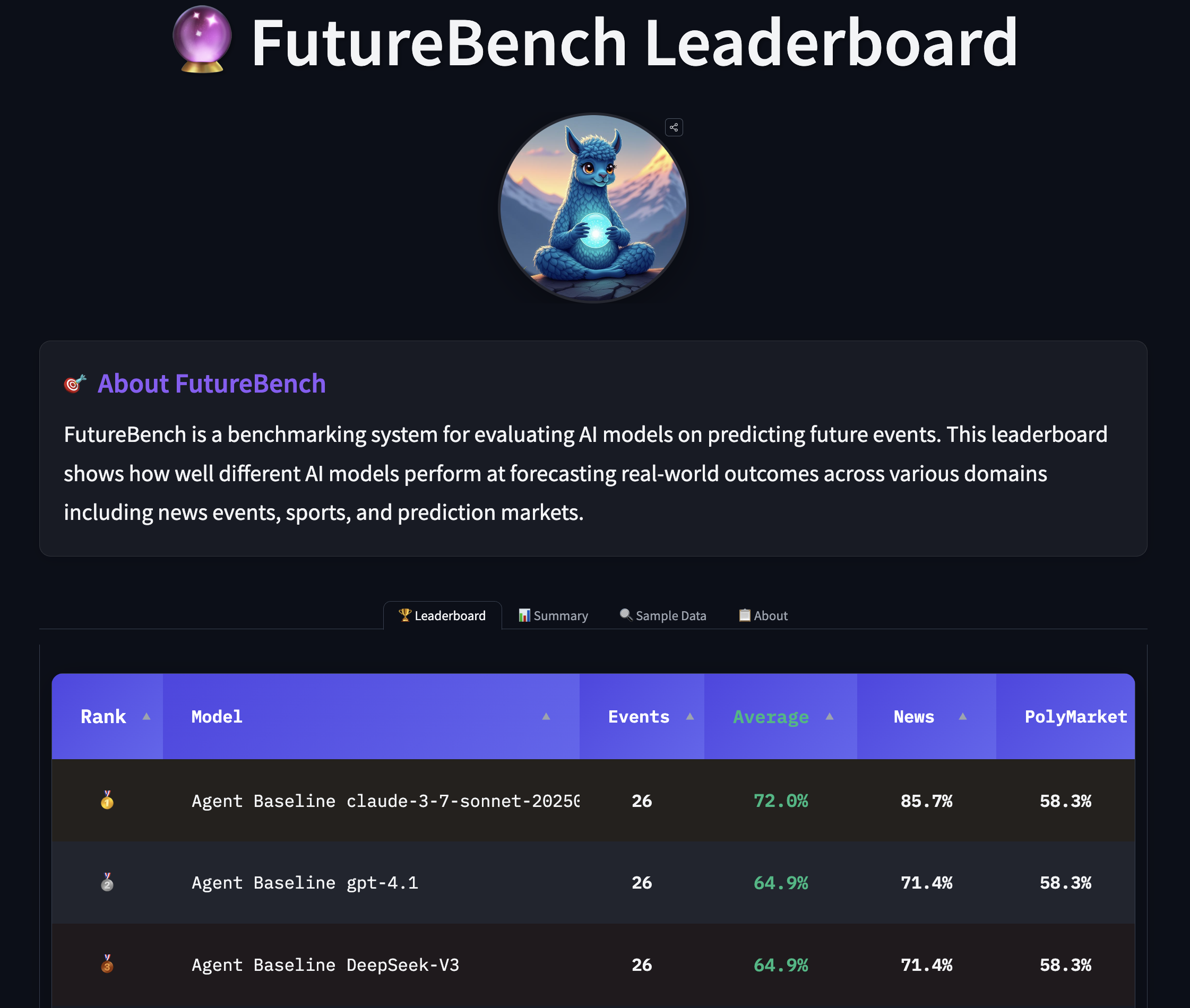
数据集标签分布和关于类别(不)平衡的信息。
实例长度的平均值、中位数、范围和分布。
数据集中重复项的数量及其重复次数。
你可以使用这些小部件来检查数据集中出现最多和最少的内容是否符合数据集的目标。这些测量旨在告知数据集是否能有效捕捉多种上下文,或者其捕捉范围是否更受限,并测量标签和实例长度的“平衡”程度。你还可以使用这些小部件来识别你可能希望删除的异常值和重复项。
分布统计
测量数据集中的语言模式
这开始回答“这个数据集中的语言行为如何?”之类的问题。
- 对齐普夫定律的遵循程度,该定律测量数据集中单词的分布与自然语言中单词预期分布的接近程度。
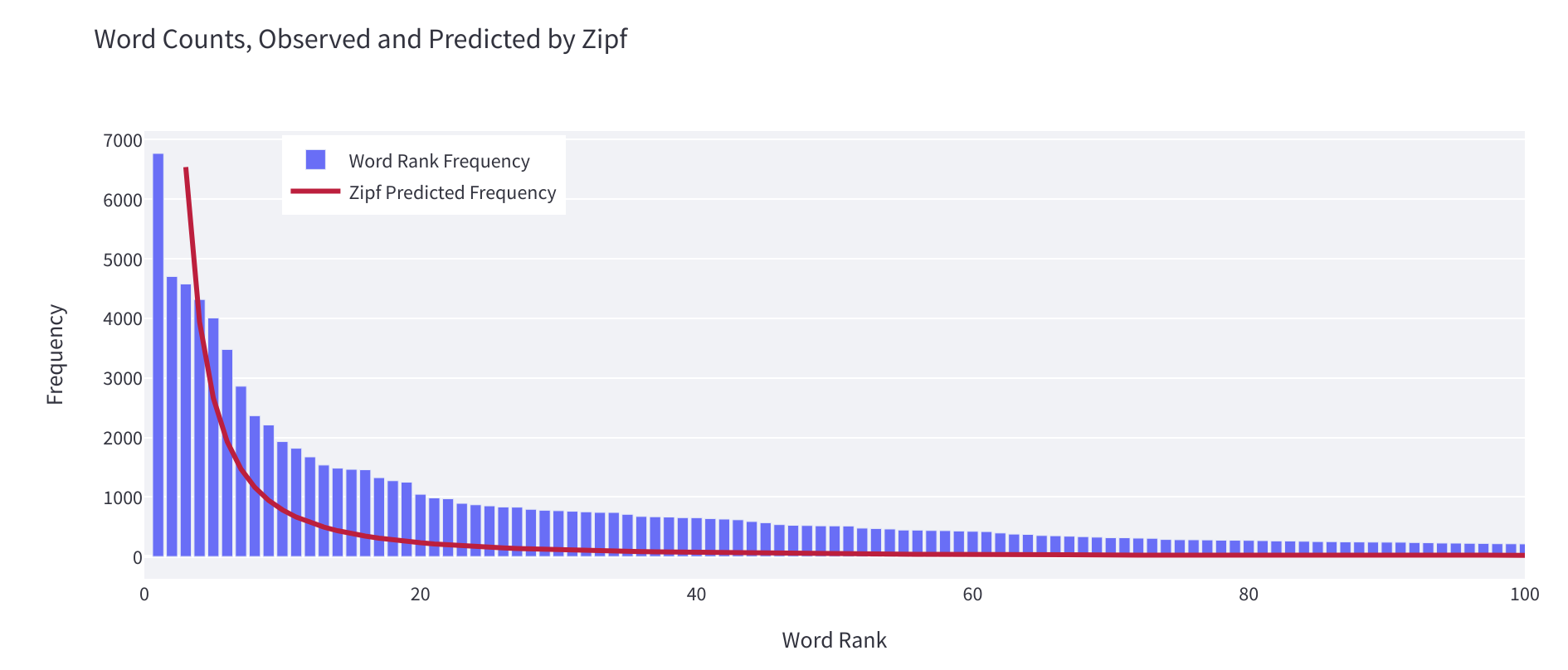
你可以用它来判断你的数据集是否代表了自然界中语言的典型行为,或者是否存在一些不自然的地方。如果你喜欢优化,那么你可以将这个小部件计算出的 alpha 值视为在数据集开发过程中尽可能接近 1 的值。关于不同语言中遵循齐普夫定律的 alpha 值的更多细节可在此处找到。
一般来说,如果 alpha 大于 2 或最小排名大于 10(仅供参考),则意味着你的分布对于自然语言来说相对不自然。这可能是数据集中混合了伪影(例如 HTML 标记)的迹象。你可以使用这些信息来清理数据集,或者指导你确定应如何分布添加到数据集中的进一步语言。
比较统计
这开始回答“这个数据集中有哪些主题、偏见和关联?”之类的问题。
嵌入聚类以确定数据集中任何相似语言的聚类。当数据集由成百上千个句子组成时,理解其中表示的文本多样性可能具有挑战性。根据相似性度量对这些文本项进行分组可以帮助用户了解它们的分布。我们展示了数据集中文本字段的层次聚类,该聚类基于 Sentence-Transformer 模型和最大点积 单链接准则。要探索这些聚类,你可以:
- 将鼠标悬停在节点上以查看 5 个最具代表性的示例(已去重)
- 在文本框中输入一个示例,以查看它与哪个叶子聚类最相似
- 按 ID 选择一个聚类以显示其所有示例
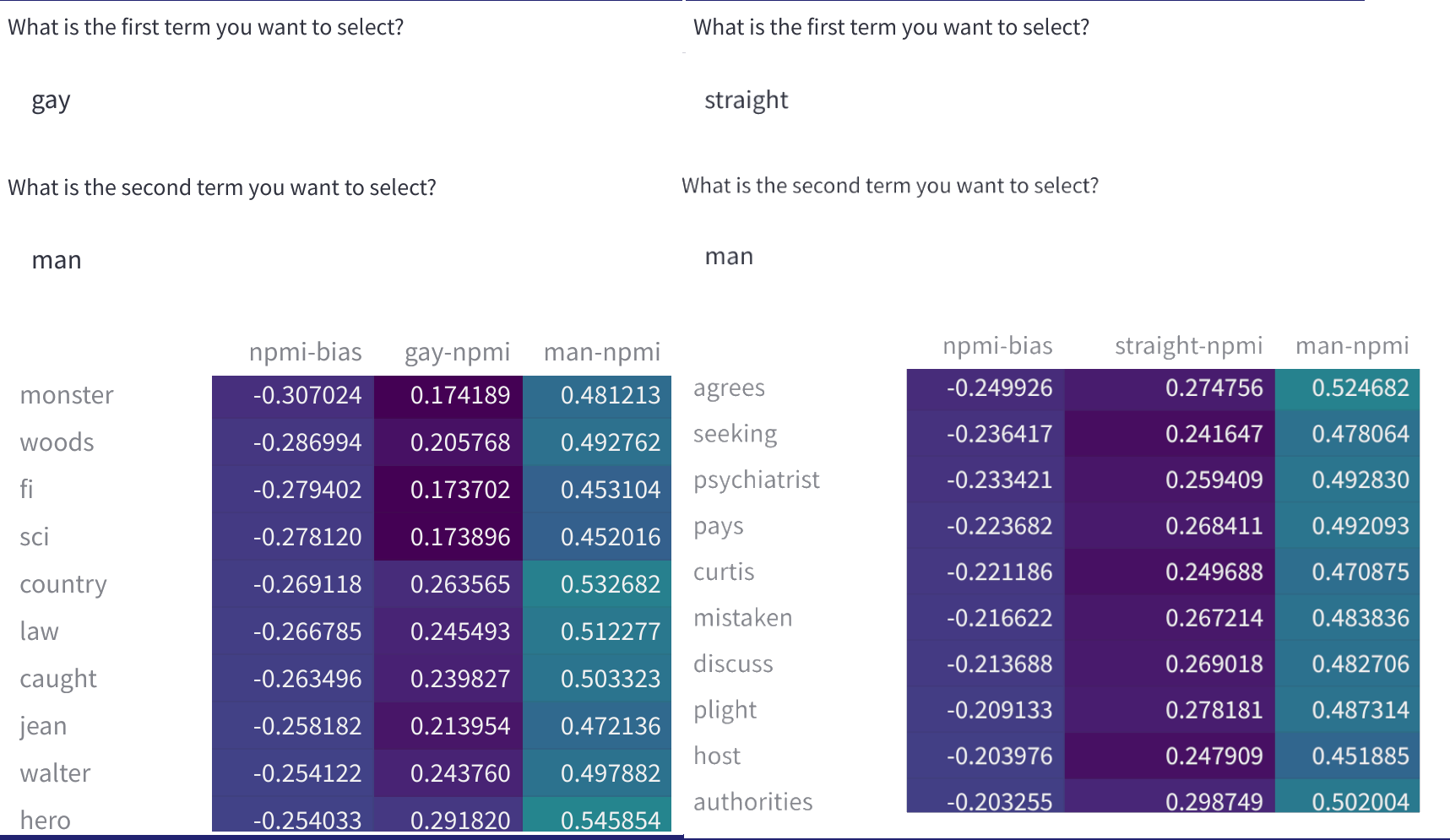
数据集中词对之间的标准化点互信息 (nPMI),可用于识别有问题的刻板印象。你可以将其用作处理数据集“偏见”的工具,这里的“偏见”指的是针对性别和性取向等身份群体的刻板印象和偏见。我们将在不久的将来添加更多术语。
🤗 Data Measurements Tool 的开发状态如何?
我们目前展示了该工具的 alpha 版本 (v0),演示了它在 Dataset Hub 上可用的一些流行英语数据集(例如 SQuAD、imdb、C4 等)上的实用性,并提供了上述功能。我们为 nPMI 可视化选择的词汇是我们正在使用的数据集中频繁出现的身份术语的子集。
在未来几周和几个月内,我们将扩展该工具以:
- 涵盖 🤗 Datasets 库中更多语言和数据集。
- 为用户提供数据集和迭代数据集构建的支持。
- 为工具本身添加更多特性和功能。例如,我们将支持为 nPMI 可视化添加您自己的术语,以便您可以选择对您最重要的词汇。
致谢
感谢 Thomas Wolf 发起了这项工作,以及 🤗 团队的其他成员(Quentin、Lewis、Sylvain、Nate、Julien C.、Julien S.、Clément、Omar 和许多其他人!)提供的帮助和支持。