🤗 Datasets 中音频和视觉文档的更新

开放和可复现的数据集对于推进良好的机器学习至关重要。同时,随着大型语言模型的火箭式发展,数据集的规模也呈指数级增长。2020 年,Hugging Face 推出了 🤗 Datasets,这是一个致力于以下目标的库:
- 通过一行代码访问标准化数据集。
- 用于快速高效处理大规模数据集的工具。
感谢社区的贡献,我们在 Datasets Sprint 期间添加了数百个多种语言和方言的 NLP 数据集!🤗 ❤️
但是文本数据集仅仅是开始。数据以更丰富的格式表示,例如 🎵 音频、📸 图像,甚至音频和文本或图像和文本的组合。在这些数据集上训练的模型能够实现令人惊叹的应用程序,例如描述图像中的内容或回答有关图像的问题。
🤗 Datasets 团队一直在构建工具和功能,以尽可能简单地处理这些数据集类型,从而提供最佳的开发者体验。我们在此过程中添加了新的文档,帮助您了解如何加载和处理音频和图像数据集。
快速开始
快速开始是新用户了解库功能TLDR(太长不读)的首选之地。因此,我们更新了“快速开始”以包含如何使用 🤗 Datasets 处理音频和图像数据集。选择您想处理的数据集模态,然后查看如何加载和处理数据集的端到端示例,以便使用 PyTorch 或 TensorFlow 进行训练。
快速开始中新增的功能还有 to_tf_dataset 函数,它能将数据集转换为 tf.data.Dataset,就像母熊照顾幼崽一样细心。这意味着您无需编写任何代码即可从数据集中打乱和加载批次,使其与 TensorFlow 良好配合。一旦将数据集转换为 tf.data.Dataset,您就可以使用常用的 TensorFlow 或 Keras 方法训练模型。
立即查看 快速开始,了解如何处理不同的数据集模态并尝试新的 to_tf_dataset 函数!

专用指南
每种数据集模态在加载和处理方式上都有其细微差别。例如,当您加载音频数据集时,音频信号会由 Audio 特征自动即时解码和重采样。这与加载文本数据集大不相同!
为了使所有特定于模态的文档更易于查找,我们新增了专门的章节,其中包含重点介绍如何加载和处理每种模态的指南。如果您正在寻找有关处理特定数据集模态的信息,请首先查看这些专用章节。同时,非特定且可广泛使用的函数则记录在“通用用法”部分。以这种方式重新组织文档将使我们能够更好地扩展到未来计划支持的其他数据集类型。
查看专用指南,了解更多关于加载和处理不同模态数据集的信息。
ImageFolder
通常,🤗 Datasets 用户会编写数据集加载脚本以下载并生成具有适当 train 和 test 分割的数据集。借助 ImageFolder 数据集构建器,您无需编写任何代码即可下载和生成图像数据集。加载图像分类的图像数据集就像确保您的数据集组织在一个文件夹中一样简单,如下所示:
folder/train/dog/golden_retriever.png
folder/train/dog/german_shepherd.png
folder/train/dog/chihuahua.png
folder/train/cat/maine_coon.png
folder/train/cat/bengal.png
folder/train/cat/birman.png
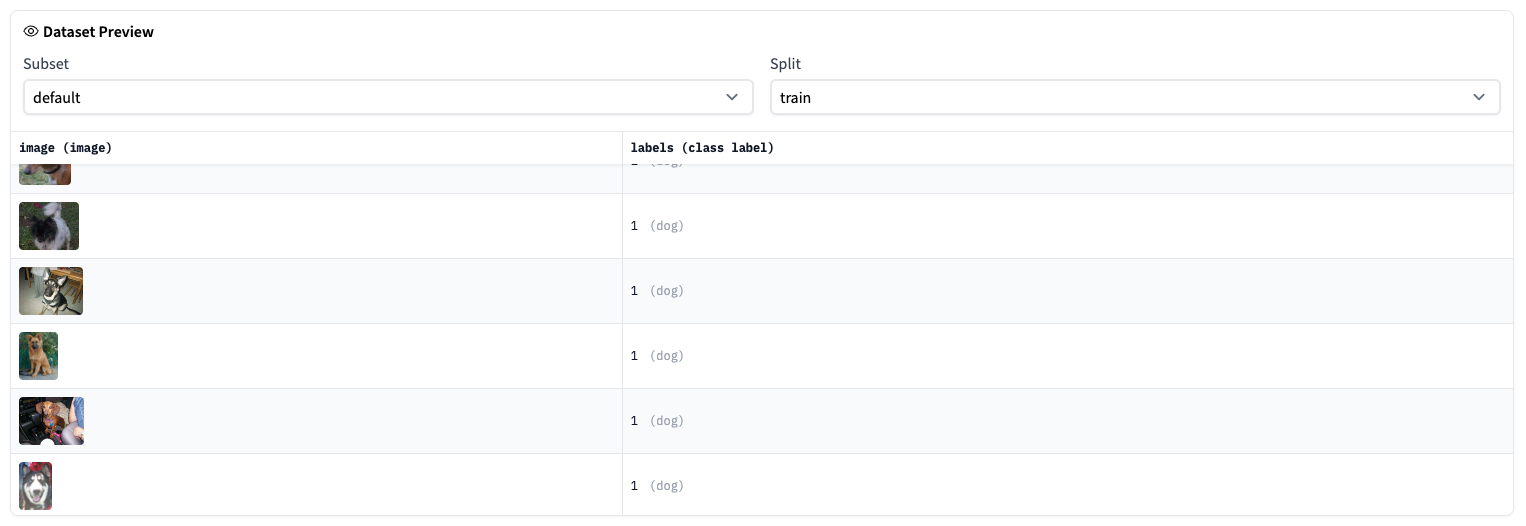
图像标签是根据目录名称在 label 列中生成的。ImageFolder 让您能够立即开始使用图像数据集,省去了编写数据集加载脚本所需的时间和精力。
但等等,这还不止!如果您有一个文件包含图像数据集的一些元数据,ImageFolder 也可以用于其他图像任务,如图像字幕和目标检测。例如,目标检测数据集通常包含**边界框**,即图像中识别物体位置的坐标。ImageFolder 可以使用此文件将边界框和类别元数据链接到文件夹中对应的图像。
{"file_name": "0001.png", "objects": {"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}}
{"file_name": "0002.png", "objects": {"bbox": [[810.0, 100.0, 57.0, 28.0]], "categories": [1]}}
{"file_name": "0003.png", "objects": {"bbox": [[160.0, 31.0, 248.0, 616.0], [741.0, 68.0, 202.0, 401.0]], "categories": [2, 2]}}
dataset = load_dataset("imagefolder", data_dir="/path/to/folder", split="train")
dataset[0]["objects"]
{"bbox": [[302.0, 109.0, 73.0, 52.0]], "categories": [0]}
如果您有一个包含所需信息的元数据文件,可以使用 ImageFolder 加载几乎任何类型的图像任务的图像数据集。查看 ImageFolder 指南了解更多信息。
接下来是什么?
就像 🤗 Datasets 库的第一次迭代标准化了文本数据集并使其变得非常容易下载和处理一样,我们也非常高兴能将同样的易用性带给音频和图像数据集。通过这样做,我们希望用户能更轻松地训练、构建和评估各种模态的模型和应用程序。
在接下来的几个月里,我们将继续添加新功能和工具,以支持处理音频和图像数据集。🤗 Hugging Face 内部消息称,很快就会推出一个名为 AudioFolder 的东西!🤫 在等待期间,您可以随意查看音频处理指南,然后亲身体验像 GigaSpeech 这样的音频数据集。
如果您对音频和图像数据集的使用有任何疑问和反馈,请加入论坛。如果您发现任何 bug,请提交 GitHub Issue,以便我们及时处理。
感觉更有冒险精神?为不断壮大的社区驱动的音频和图像数据集集合贡献一份力量吧,尽在 Hub!在 Hub 上创建一个数据集仓库并上传您的数据集。如果您需要帮助,请在您的仓库的社区选项卡上发起讨论,并 @ 🤗 Datasets 团队成员,他们会帮助您完成这项任务!

