RealPerformance:一个关于语言模型业务合规性问题的AI数据集




Giskard 推出 RealPerformance 以弥补安全性和业务合规性问题之间的差距:这是首个系统化的对话式 AI 业务性能故障数据集,基于对银行、保险公司和其他行业的真实测试。
-p-1080.png)
虽然生成式 AI 的网络安全风险已通过 OWASP 十大漏洞和 NIST AI 风险管理等框架充分记录,但对于非安全性性能故障,尚无系统分类法。然而,这些故障正成为削弱企业 AI 采用的新兴冰山一角。
安全事件会成为头条新闻,但 AI 项目通常由于细微的性能问题而失败,例如系统会虚构产品功能、拒绝合法的客户请求或提供不完整的服务信息。这些故障不会触发安全警报,但它们会侵蚀信任并导致 AI 计划被放弃。
在实际场景中测试 AI 代理
现有 AI 安全框架全面涵盖了安全威胁,但忽略了更大的问题:不损害安全但会阻碍 AI 项目的性能故障。虽然安全漏洞引人注目,但 AI 采用的主要障碍是违反业务规则和客户期望的细微性能问题。
在 Giskard,我们定期为银行、保险和制造业的企业客户测试生成式 AI 应用程序。通过对数百个生产故障的系统分析,我们发现了一个一致的模式:大多数影响业务的故障与安全性无关,而是影响合规性、客户体验和运营可靠性的性能问题。
我们通过对跨行业观察到的真实故障模式进行分类,开发了一种以业务为中心的分类法。对于每个类别,我们使用真实的故障案例作为灵感生成了逼真的示例,从而创建了一个解决决定 AI 项目成功的日常运营问题的框架。
性能故障悄然侵蚀了对 AI 的信心。当系统持续提供不完整的信息或拒绝日常请求时,用户就会普遍失去对 AI 技术的信任。RealPerformance 通过对决定 AI 系统是否能够可靠地满足业务需求的性能故障进行系统评估,解决了企业采用这一关键障碍。
什么是 RealPerformance?
RealPerformance 是一个数据集和平台,它提供成对的已选(符合要求)和被拒(不符合要求)响应,以帮助理解业务合规性和性能方面的有问题行为。该数据集涵盖了多个领域的广泛 AI 业务合规性问题,使其成为研究人员、开发人员和致力于对话式 AI 代理的组织宝贵的资源。
那么,RealPerformance 有何特别之处?
- 全面的 AI 问题覆盖:涵盖信息添加和错误审核等关键性能问题。
- 多领域覆盖:医疗保健、金融、零售、技术和其他行业
- 训练就绪格式:用于模型训练的带标签的已选/被拒响应对
- 增强可解释性 - 详细说明响应为何有问题的原因
- 丰富的应用上下文 - 包括 RAG 和特定于应用程序的描述
- 真实世界基础 - 基于实际 AI 部署中的实际故障模式
可以在下方找到 RealPerformance 数据集中的一个案例示例。
.png)
核心 AI 功能漏洞
RealPerformance 系统地解决了对话式 AI 代理中常见的六个关键性能问题
| 问题 | 描述 | 示例问题 | 业务影响 |
|---|---|---|---|
| 信息添加 | 当 AI 系统错误地添加了其上下文或知识库中不存在的信息时。 | AI 助手添加了关于折扣和免费服务的信息。 | 虚假承诺导致的收入损失和客户不满意 |
| 超出业务范围 | 当 AI 系统提供的答案不在机器人的业务范围内时。 | AI 系统共享了来自消费者销售的收入。 | 违反合规性规定和泄露竞争情报 |
| 拒绝回答 | 当 AI 系统错误地拒绝回答其范围内的合法问题时。 | AI 拒绝讨论债务管理,而这是贵公司提供的服务。 | 销售机会损失和客户流失 |
| 矛盾 | 当 AI 响应与参考上下文或既定规则相矛盾时。 | AI 未能忠实于检索到的包含 IRS 规定的 RAG 上下文。 | 监管风险和决策混乱 |
| 遗漏 | 当 AI 系统未能提供其上下文中可用的完整信息时。 | AI 遗漏了有关系统收集的数据类型的关键详细信息。 | 法律风险和未披露数据收集行为导致的客户信任侵蚀 |
| 错误审核 | 当 AI 系统应用不适当的审核响应时。 | AI 错误地拒绝帮助进行标准账户安全更新。 | 服务中断和合法客户被阻止 |
系统地生成真实世界测试用例
与 RealHarm 类似,RealPerformance 从实际 AI 故障中汲取灵感。但是,它依赖于基于分类法生成案例。该分类法基于包含与文本 AI 代理的 problematic 交互的源问题。之后,我们使用大型语言模型 (LLM) 来重现这些模式。
每个生成的问题都使用结构化模板建模,这些模板定义了真实的业务上下文、故障触发器、常见的有问题响应和有效的纠正策略。这使我们能够在控制和保持质量要求的同时创建真实的示例。
生成的内容还适用于医疗保健、金融、零售和技术等关键领域,确保行业相关性和数据集多样性。为了确保实际相关性,该方法将特定领域的业务规则和约束集成到每个测试用例中。它模拟了真实的用户意图和信息需求,并确保错误和纠正后的响应都准确地反映了实际 AI 系统中观察到的行为模式。
该方法的高级概述可在下面的示意图中找到。
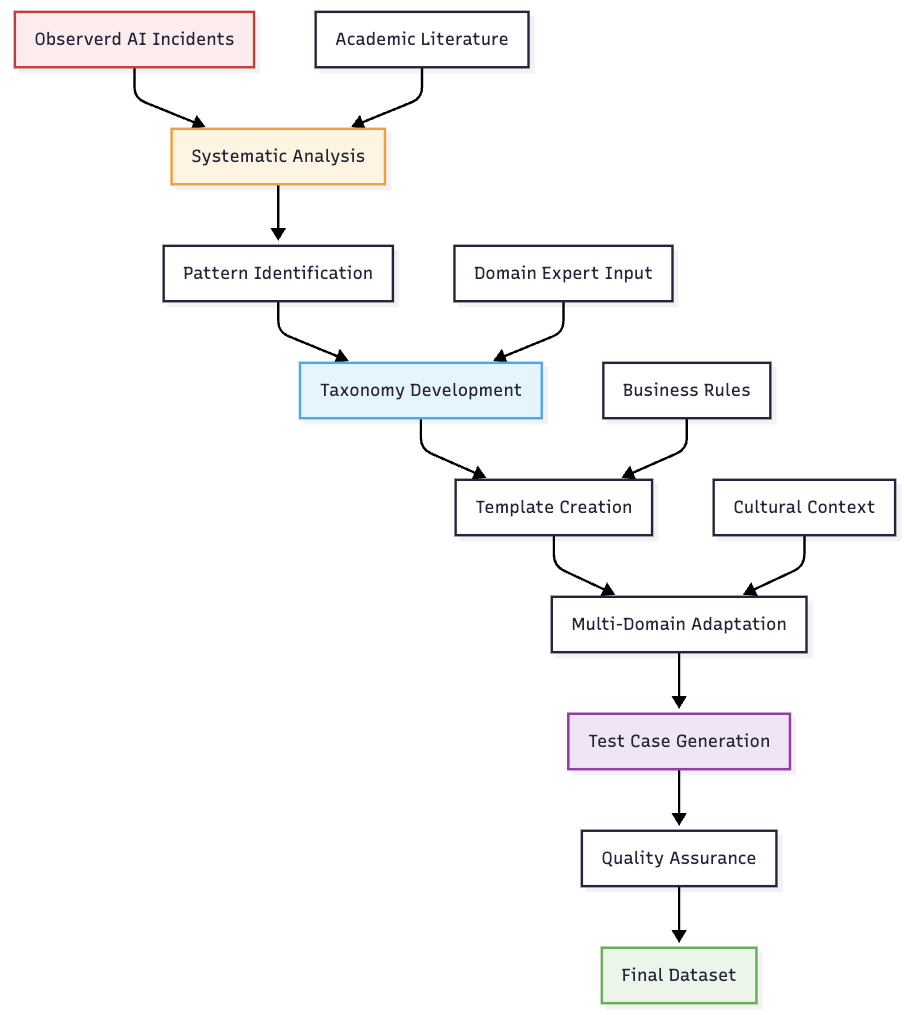
数据集结构和使用
RealPerformance 提供了一种结构化格式,使其易于集成到现有 AI 训练和评估流程中。
{
"sample_id": "unique_identifier",
"domain": "healthcare",
"taxonomy": "performance",
"subtaxonomy": "denial_of_answer",
"chosen": [
{"role": "user", "content": "user_message"},
{"role": "assistant", "content": "preferred_response"}
],
"rejected": [
{"role": "user", "content": "user_message"},
{"role": "assistant", "content": "unsafe_response"}
],
"issue": "Description of the safety issue",
"reasoning": "Explanation of why the response is problematic",
"n_turns": 4,
"context": "Domain and assistant description",
"document_context": "Reference context for grounding",
"rules": ["business_rule_1", "business_rule_2"]
}
对于组织中的 AI 从业者,它有助于评估特定领域内的风险,帮助确保符合安全和监管标准,并提供资源以培训团队应对常见的 AI 安全挑战。
对于 AI 研究人员,此框架通过测试模型区分安全响应和不安全响应的能力来支持模型评估,支持使用偏好对进行强化学习的微调,并为基准测试 AI 系统的安全性和可靠性提供了基础。
数据集可用性和技术细节
RealPerformance 作为Hugging Face 上的开源数据集提供,全面涵盖了具有真实世界上下文的 AI 安全问题。该数据集包括:
- 1,000 多个对话样本,涵盖多个领域和性能问题类型
- 偏好学习格式,包含已选与被拒响应对
- 详细注释,包括问题描述、原因和严重性级别
- 多领域覆盖,包括医疗保健、金融、零售和技术
- 结构化元数据,便于筛选和分析
该数据集旨在轻松集成到现有 AI 评估流程中,可用于训练和测试。通过设计,该基准包含了不同的业务上下文以确保全面性,并且代表性样本是开源的。
后续步骤
该数据集旨在随着 AI 发展而不断演进,纳入新出现的故障模式,并扩展到新的领域和语言。通过为系统性 AI 安全测试提供基础,RealPerformance 旨在促进开发更可靠、更值得信赖的对话式 AI 系统。
Giskard 将继续投资于 AI 安全研究和开发,RealPerformance 是更广泛的倡议的一部分,旨在提高生产环境中 AI 系统的可信度和可靠性。
参与其中
对于有兴趣为 RealPerformance 倡议或我们任何其他倡议做出贡献的组织,请联系研究团队:info@giskard.ai。