在 Vertex AI 上部署 🤗 ViT



在之前的文章中,我们展示了如何将 🤗 Transformers 中的 Vision Transformers (ViT) 模型 本地部署到 Kubernetes 集群上。本文将向您展示如何在 Vertex AI 平台上部署相同的模型。您将获得与基于 Kubernetes 的部署相同的可伸缩性级别,但代码量显著减少。
本文是基于上面链接的两篇旧文章构建的。如果您还没有阅读它们,建议您查看一下。
您可以在文章开头的 Colab Notebook 中找到一个完整的示例。
什么是 Vertex AI?
根据 Google Cloud:
Vertex AI 提供了工具来支持您整个机器学习工作流程,涵盖不同的模型类型和不同级别的机器学习专业知识。
在模型部署方面,Vertex AI 提供了一些重要的功能,并采用统一的 API 设计:
身份验证
基于流量的自动扩缩
模型版本控制
不同模型版本之间的流量拆分
速率限制
模型监控和日志记录
支持在线和批量预测
对于 TensorFlow 模型,它提供了各种现成的实用程序,您将在本文中了解它们。但它也对 PyTorch 和 scikit-learn 等其他框架提供类似的支持。
要使用 Vertex AI,您需要一个已启用结算的 Google Cloud Platform (GCP) 项目,并启用以下服务:
Vertex AI
Cloud Storage
重温服务模型
您将使用与前两篇文章中相同的TensorFlow 中实现的 ViT B/16 模型。您将模型与相应的预处理和后处理操作一起序列化,以减少训练-服务偏差。请参阅详细讨论此内容的第一篇文章。最终序列化的 SavedModel 的签名如下所示:
The given SavedModel SignatureDef contains the following input(s):
inputs['string_input'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_string_input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['confidence'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall:0
outputs['label'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall:1
Method name is: tensorflow/serving/predict
该模型将接受图像的base64 编码字符串,执行预处理,运行推理,最后执行后处理步骤。这些字符串经过 base64 编码以防止在网络传输过程中进行任何修改。预处理包括将输入图像大小调整为 224x224 分辨率,将其标准化到 [-1, 1] 范围,并将其转置为 channels_first 内存布局。后处理包括将预测的 logits 映射到字符串标签。
要在 Vertex AI 上执行部署,您需要将模型工件保存在Google Cloud Storage (GCS) 存储桶中。随附的 Colab Notebook 展示了如何创建 GCS 存储桶并将模型工件保存到其中。
使用 Vertex AI 的部署工作流程
下图描绘了在 Vertex AI 上部署已训练的 TensorFlow 模型的工作流程。
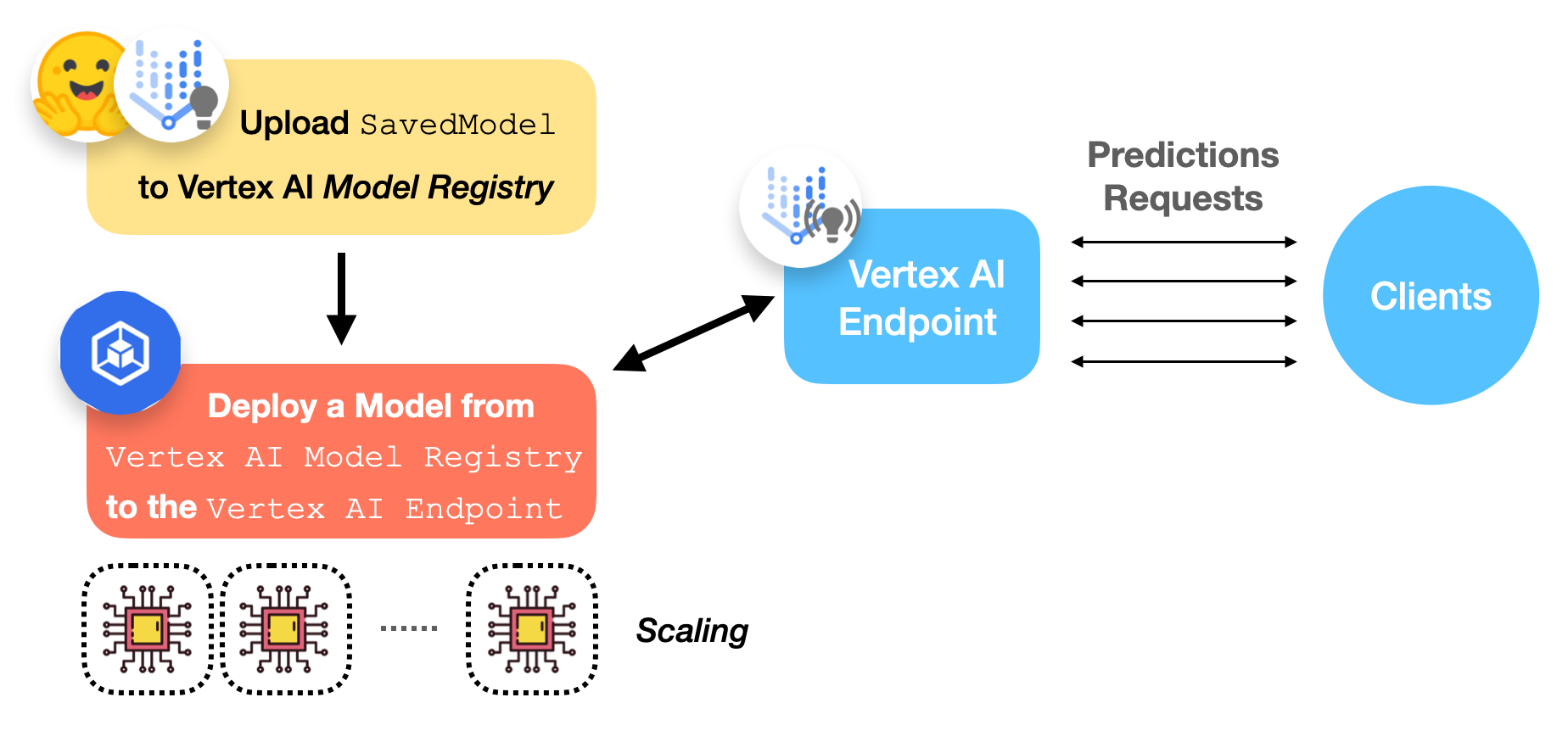
现在我们来讨论一下 Vertex AI 模型注册表和端点是什么。
Vertex AI 模型注册表
Vertex AI 模型注册表是一个完全托管的机器学习模型注册表。关于“完全托管”这里有几点需要注意。首先,您无需担心模型的存储方式和位置。其次,它管理同一模型的不同版本。
这些功能对于生产中的机器学习非常重要。构建一个能保证高可用性和安全性的模型注册表绝非易事。此外,由于我们无法控制黑盒机器学习模型的内部,通常会遇到需要将当前模型回滚到旧版本的情况。Vertex AI 模型注册表使我们能够轻松实现这些目标。
目前支持的模型类型包括 TensorFlow 的 SavedModel、scikit-learn 和 XGBoost。
Vertex AI 端点
从用户的角度来看,Vertex AI 端点只是提供一个端点来接收请求并发送响应。然而,它在底层为机器学习操作人员提供了许多可配置的选项。以下是一些您可以选择的配置:
模型版本
VM 的 CPU、内存和加速器规格
计算节点的最小/最大数量
流量拆分百分比
模型监控窗口长度及其目标
预测请求采样率
执行部署
google-cloud-aiplatform Python SDK 提供了易于使用的 API 来管理 Vertex AI 上部署的生命周期。它分为四个步骤:
- 上传模型
- 创建端点
- 将模型部署到端点
- 发起预测请求。
在这些步骤中,您将需要 google-cloud-aiplatform Python SDK 中的 ModelServiceClient、EndpointServiceClient 和 PredictionServiceClient 模块来与 Vertex AI 交互。
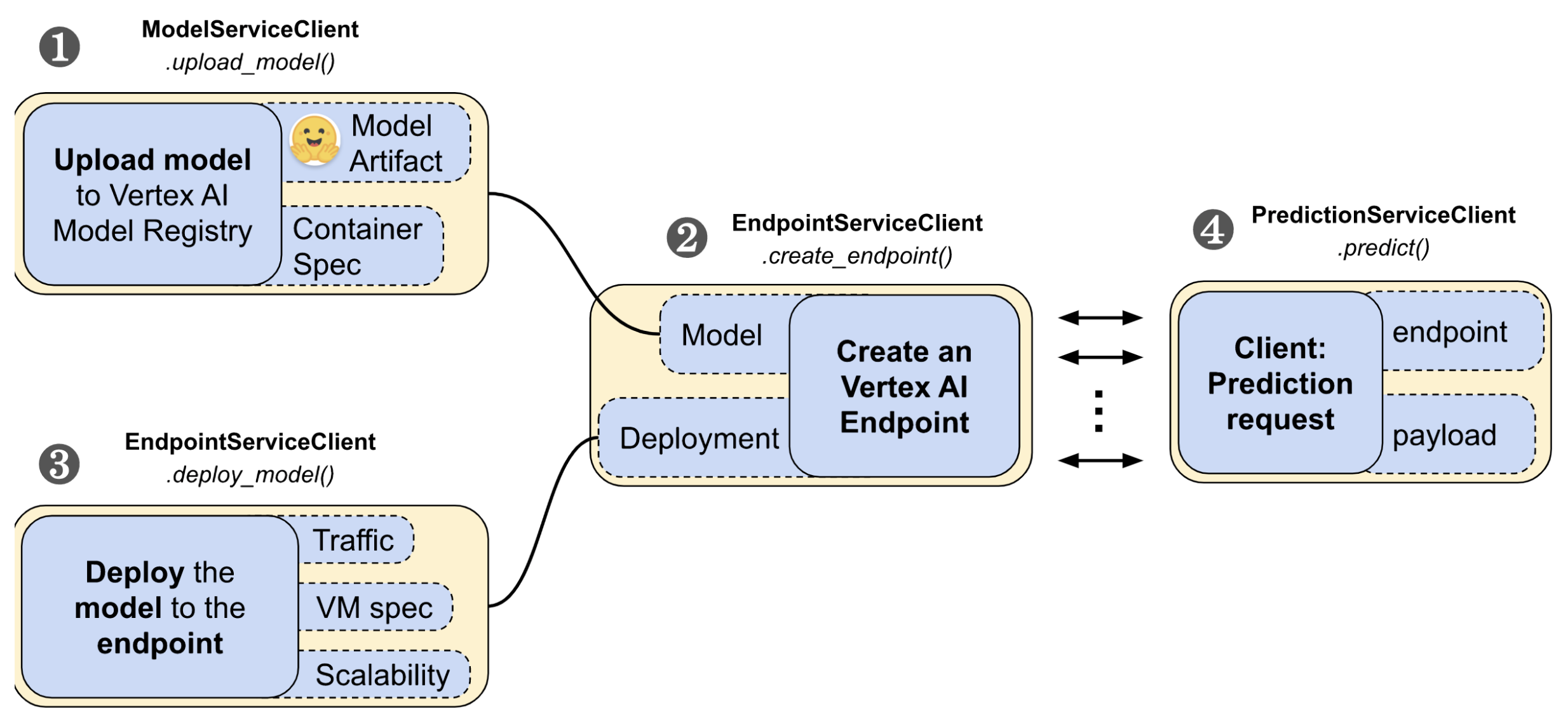
1. 工作流程的第一步是将 SavedModel 上传到 Vertex AI 的模型注册表
tf28_gpu_model_dict = {
"display_name": "ViT Base TF2.8 GPU model",
"artifact_uri": f"{GCS_BUCKET}/{LOCAL_MODEL_DIR}",
"container_spec": {
"image_uri": "us-docker.pkg.dev/vertex-ai/prediction/tf2-gpu.2-8:latest",
},
}
tf28_gpu_model = (
model_service_client.upload_model(parent=PARENT, model=tf28_gpu_model_dict)
.result(timeout=180)
.model
)
我们来逐一分析代码:
GCS_BUCKET表示您的 GCS 存储桶的路径,其中存储了模型工件(例如,gs://hf-tf-vision)。在
container_spec中,您提供一个 Docker 镜像的 URI,该镜像将用于提供预测服务。Vertex AI 提供预构建镜像来服务 TensorFlow 模型,但您也可以在使用不同框架时使用自定义 Docker 镜像(示例)。model_service_client是一个ModelServiceClient对象,它公开了将模型上传到 Vertex AI 模型注册表的方法。PARENT被设置为f"projects/{PROJECT_ID}/locations/{REGION}",它允许 Vertex AI 确定模型在 GCP 内部的范围。
2. 接下来您需要创建一个 Vertex AI 端点:
tf28_gpu_endpoint_dict = {
"display_name": "ViT Base TF2.8 GPU endpoint",
}
tf28_gpu_endpoint = (
endpoint_service_client.create_endpoint(
parent=PARENT, endpoint=tf28_gpu_endpoint_dict
)
.result(timeout=300)
.name
)
在这里,您使用的是 endpoint_service_client,它是一个 EndpointServiceClient 对象。它允许您创建和配置 Vertex AI 端点。
3. 现在您要执行实际的部署了!
tf28_gpu_deployed_model_dict = {
"model": tf28_gpu_model,
"display_name": "ViT Base TF2.8 GPU deployed model",
"dedicated_resources": {
"min_replica_count": 1,
"max_replica_count": 1,
"machine_spec": {
"machine_type": DEPLOY_COMPUTE, # "n1-standard-8"
"accelerator_type": DEPLOY_GPU, # aip.AcceleratorType.NVIDIA_TESLA_T4
"accelerator_count": 1,
},
},
}
tf28_gpu_deployed_model = endpoint_service_client.deploy_model(
endpoint=tf28_gpu_endpoint,
deployed_model=tf28_gpu_deployed_model_dict,
traffic_split={"0": 100},
).result()
在这里,您将上传到 Vertex AI 模型注册表的模型与您在上述步骤中创建的端点链接在一起。您首先在 tf28_gpu_deployed_model_dict 下定义部署的配置。
在 dedicated_resources 下,您正在配置:
min_replica_count和max_replica_count处理您部署的自动扩缩方面。machine_spec允许您定义部署硬件的配置:machine_type是用于运行 Docker 镜像的基础机器类型。底层自动缩放器将根据流量负载对此机器进行缩放。您可以从支持的机器类型中选择一个。accelerator_type是将用于执行推理的硬件加速器。accelerator_count表示要连接到每个副本的硬件加速器数量。
请注意,提供加速器并非在 Vertex AI 上部署模型的必需条件。
接下来,您将使用上述规范部署端点:
tf28_gpu_deployed_model = endpoint_service_client.deploy_model(
endpoint=tf28_gpu_endpoint,
deployed_model=tf28_gpu_deployed_model_dict,
traffic_split={"0": 100},
).result()
请注意您如何定义模型的流量分割。如果您有多个版本的模型,您可以定义一个字典,其中键表示模型版本,值表示模型应该服务的流量百分比。
通过模型注册表和管理端点的专用界面,Vertex AI 可以让您轻松控制部署的重要方面。
Vertex AI 大约需要 15 到 30 分钟来确定部署范围。完成后,您应该能够在控制台上看到它。
执行预测
如果您的部署成功,您可以通过发出预测请求来测试已部署的端点。
首先,准备一个 base64 编码的图像字符串:
import base64
import tensorflow as tf
image_path = tf.keras.utils.get_file(
"image.jpg", "http://images.cocodataset.org/val2017/000000039769.jpg"
)
bytes = tf.io.read_file(image_path)
b64str = base64.b64encode(bytes.numpy()).decode("utf-8")
4. 下面的实用程序首先准备一个实例列表(本例中只有一个实例),然后使用预测服务客户端(类型为PredictionServiceClient)。serving_input 是已服务模型的输入签名键的名称。在这种情况下,serving_input 是 string_input,您可以从上面显示的 SavedModel 签名输出中验证。
from google.protobuf import json_format
from google.protobuf.struct_pb2 import Value
def predict_image(image, endpoint, serving_input):
# The format of each instance should conform to
# the deployed model's prediction input schema.
instances_list = [{serving_input: {"b64": image}}]
instances = [json_format.ParseDict(s, Value()) for s in instances_list]
print(
prediction_service_client.predict(
endpoint=endpoint,
instances=instances,
)
)
predict_image(b64str, tf28_gpu_endpoint, serving_input)
对于部署在 Vertex AI 上的 TensorFlow 模型,请求负载需要以特定方式格式化。对于处理图像等二进制数据的模型(如 ViT),它们需要经过 base64 编码。根据官方指南,每个实例的请求负载需要如下所示:
{serving_input: {"b64": base64.b64encode(jpeg_data).decode()}}
predict_image() 实用程序根据此规范准备请求负载。
如果部署一切顺利,当您调用 predict_image() 时,您应该会得到如下输出:
predictions {
struct_value {
fields {
key: "confidence"
value {
number_value: 0.896659553
}
}
fields {
key: "label"
value {
string_value: "Egyptian cat"
}
}
}
}
deployed_model_id: "5163311002082607104"
model: "projects/29880397572/locations/us-central1/models/7235960789184544768"
model_display_name: "ViT Base TF2.8 GPU model"
然而,请注意,这并非获取使用 Vertex AI 端点进行预测的唯一方法。如果您前往端点控制台并选择您的端点,它将显示两种不同的获取预测的方法:
也可以避免 cURL 请求,并在不使用 Vertex AI SDK 的情况下以编程方式获取预测。请参阅此笔记本以了解更多信息。
既然您已经了解了如何使用 Vertex AI 部署 TensorFlow 模型,那么现在让我们讨论一下 Vertex AI 提供的一些有益功能。这些功能可帮助您更深入地了解您的部署。
使用 Vertex AI 进行监控
Vertex AI 还允许您在没有任何配置的情况下监控您的模型。从端点控制台,您可以获取有关端点性能和分配资源利用率的详细信息。
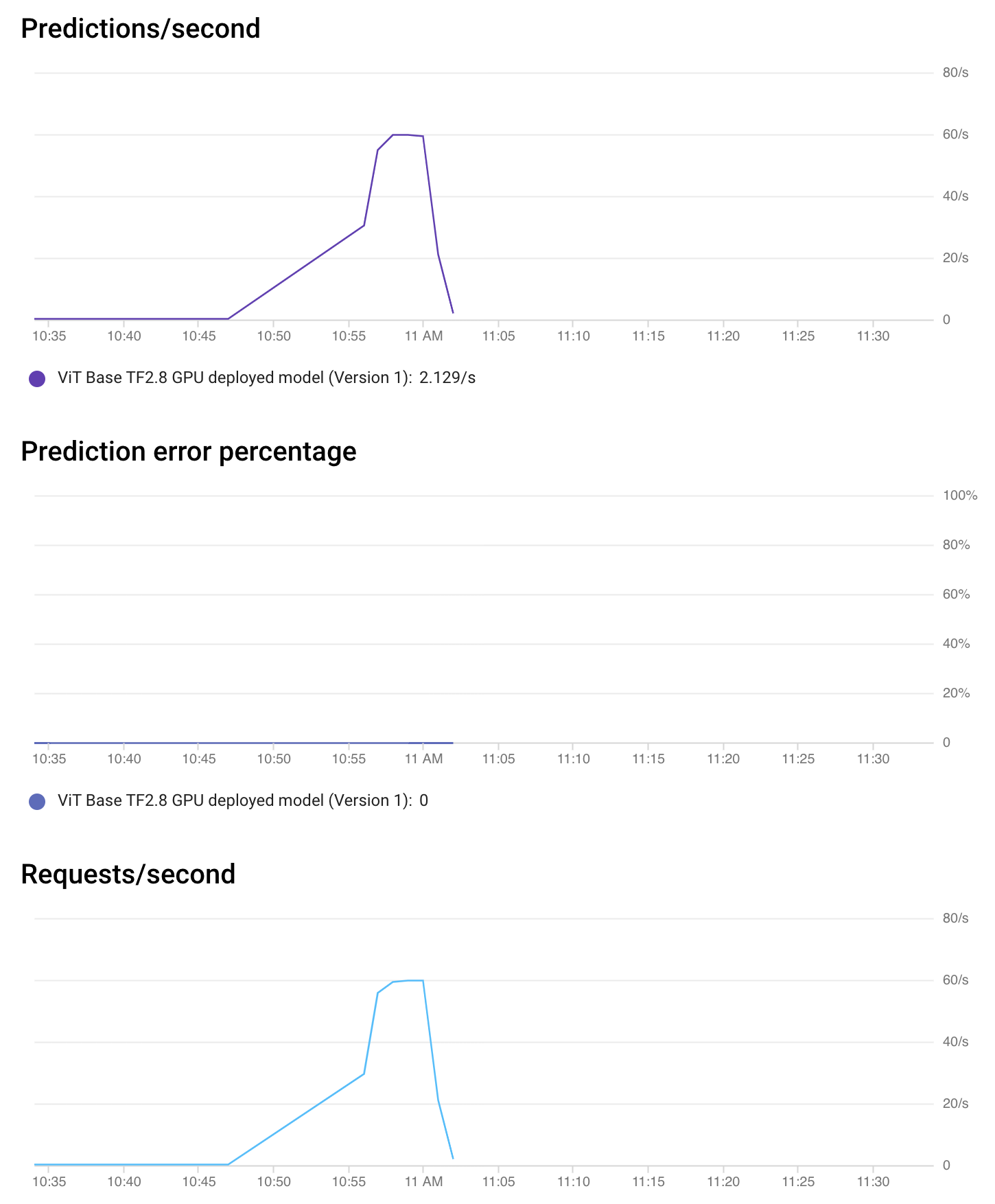
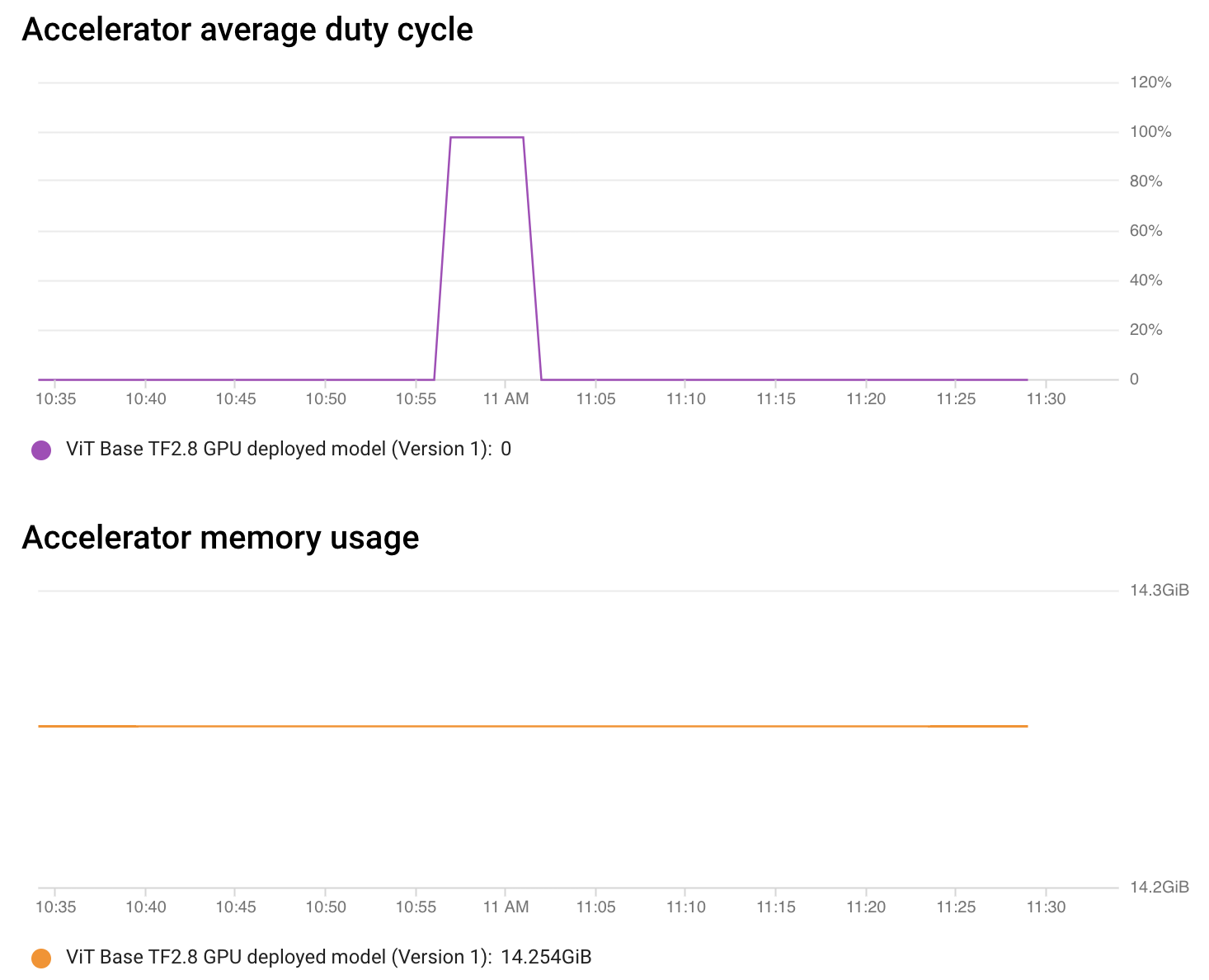
如上图所示,在短时间内,加速器负载(利用率)约为 100%,这令人赏心悦目。其余时间,没有请求需要处理,因此一切都处于空闲状态。
这种类型的监控有助于您快速标记当前部署的端点并根据需要进行调整。也可以请求监控模型解释。请参阅此处了解更多信息。
本地负载测试
我们使用 Locust 进行了本地负载测试,以更好地了解端点的限制。下表总结了请求统计信息:

在表中显示的所有不同统计数据中,平均值 (ms) 指的是端点的平均延迟。Locust 发起了大约 17230 个请求,报告的平均延迟为 646 毫秒,这令人印象深刻。在实践中,您会希望通过分布式方式进行负载测试来模拟更真实的流量。请参阅此处了解更多信息。
此目录包含了解我们如何进行负载测试所需的所有信息。
定价
您可以使用GCP 费用估算器来估算使用成本,精确的小时定价表可在此处找到。值得注意的是,您仅在节点处理实际预测请求时才被收费,并且您需要计算带 GPU 和不带 GPU 的价格。
对于自定义训练模型的 Vertex Prediction,我们可以选择从 n1-standard-2 到 n1-highcpu-32 的 N1 机器类型。本文中使用了 n1-standard-8,它配备了 8 个 vCPU 和 32GB 内存。
| 机器类型 | 每小时价格 (美元) |
|---|---|
| n1-standard-8 (8vCPU, 30GB) | $ 0.4372 |
此外,当您将加速器连接到计算节点时,将根据您想要的加速器类型额外收费。我们在本博客文章中使用了 NVIDIA_TESLA_T4,但几乎所有现代加速器,包括 TPU 都支持。您可以在此处找到更多信息。
| 加速器类型 | 每小时价格 (美元) |
|---|---|
| NVIDIA_TESLA_T4 | $ 0.4024 |
行动呼吁
🤗 Transformers 中的 TensorFlow 视觉模型集合正在不断壮大。它现在支持使用 SegFormer 实现最先进的语义分割。我们鼓励您将本文中学到的部署工作流程扩展到 SegFormer 等语义分割模型。
结论
在本文中,您学习了如何使用 Vertex AI 平台提供的易用 API 部署视觉 Transformer 模型。您还了解了 Vertex AI 的功能如何通过让您专注于声明性配置并消除复杂部分来使模型部署过程受益。Vertex AI 还通过自定义预测路由支持 PyTorch 模型的部署。请参阅此处了解更多详情。
该系列首先向您介绍了 TensorFlow Serving,用于在本地部署 🤗 Transformers 中的视觉模型。在第二篇文章中,您学习了如何使用 Docker 和 Kubernetes 扩展该本地部署。我们希望本系列关于 TensorFlow 视觉模型在线部署的文章对您将机器学习工具箱提升到新水平有所帮助。我们迫不及待地想看看您使用这些工具能构建出什么。
致谢
感谢 Google 机器学习开发者关系项目团队为我们提供 GCP 积分,用于进行实验。

