开源嵌入模型和大型语言模型(LLM)在网络导航方面优于Gemini和OpenAI,并且速度更快、成本更低







TL;DR
- LaVague是一个用于构建AI网络代理的大型动作模型框架。
- 我们使用RAG(检索增强生成)技术,通过HTML将自然语言指令(例如:“点击‘登录’”),转化为浏览器动作(例如:生成并执行Selenium代码)。
- 我们开发了评估指标,例如用于检索的真实网页元素的召回率。
- 我们比较了不同的开源和专有LLM在给定指令下生成正确Selenium代码的能力。
- 我们发现,像bge-small这样的本地嵌入模型性能与OpenAI或Gemini等API背后的专有模型相当,同时更便宜、更快速。
- 我们发现,像Codestral这样的开源LLM性能与Gemini等专有API相当,但GPT-4o仍然占据主导地位。
背景
LLM已经解锁了构建能为我们行动的AI代理的能力。由于它们能够生成控制其他系统的代码,例如通过生成Selenium代码,现在AI可以执行网络操作了。
LaVague是一个开源的大型动作模型(LAM)框架,用于构建AI网络代理。LAM是专门生成动作的AI模型,通常是输出要调用的函数及其参数,或直接生成并执行执行该动作的代码。
我们在文档中提供了几个可构建的不同代理的示例。
虽然LLM极具潜力,但它们有一个问题:评估其性能。与执行分类或回归的常规机器学习系统(如推荐系统)不同,LLM生成任意文本,这很难评估。
例如,在网络动作生成中,生成选择器和代码以定位特定元素的方法有很多种。可以使用XPath、ID等。
因此,我们需要一个可靠的指标来评估生成的动作是否按用户预期执行。如果没有良好的评估,就不可能优化动作生成管道。
本文的重点
由于LaVague的使命是促进Agent的广泛构建,我们致力于分享开源数据集,以评估和改进LAMs,并提供使评估变得容易的工具。
在本文中,我们将分享我们关于评估不同LLM生成正确Selenium代码的实验,使用我们准备好的数据集以简化评估,以及用于快速测量LLM动作生成能力的评估工具。
LaVague的工作流程
在检查动作生成模型的评估之前,快速回顾LaVague的工作原理以了解工作流程如何细分并更好地评估每个模块是很重要的。
LaVague的整体构想
LaVague是一个用于构建AI网络代理的大型动作模型框架。我们的目标是让开发者能够轻松设计、部署和分享他们的代理,以实现网络任务自动化。
我们首先定义LaVague Agent架构中的几个关键元素:
- 目标: 目标是用户希望网络代理实现的全局目标。例如:“登录我的账户并把我的用户名改为The WaveHunter。”
- 指令: 指令是实现用户目标所需的一个较小的步骤。例如:“找到用户名输入字段并输入文本‘user123’。”
- 世界模型(World Model): 世界模型分析用户目标和网页的当前状态,以生成下一步所需指令,从而最终实现目标。
- 动作引擎(Action Engine): 动作引擎接收指令,并生成执行此动作所需的自动化代码。
- 驱动器(Driver): 网页驱动器既用于执行动作引擎生成的动作代码,又通过屏幕截图和网页当前状态的HTML源代码为世界模型提供感知。
注意: 我们在此将“动作引擎”称为人们通常所说的“大型动作模型”。我们更倾向于称其为“动作引擎”,因为大型动作模型不一定是为了特定动作而训练的模型。如果经过适当的提示工程,我们可以将像GPT4这样的通用LLM重新用于生成动作代码,这正是我们所做的。
因此,我们将使用“动作引擎”来指代负责动作生成的模块。
整体工作流程
之前描述的所有元素都在以下工作流程中相互作用:
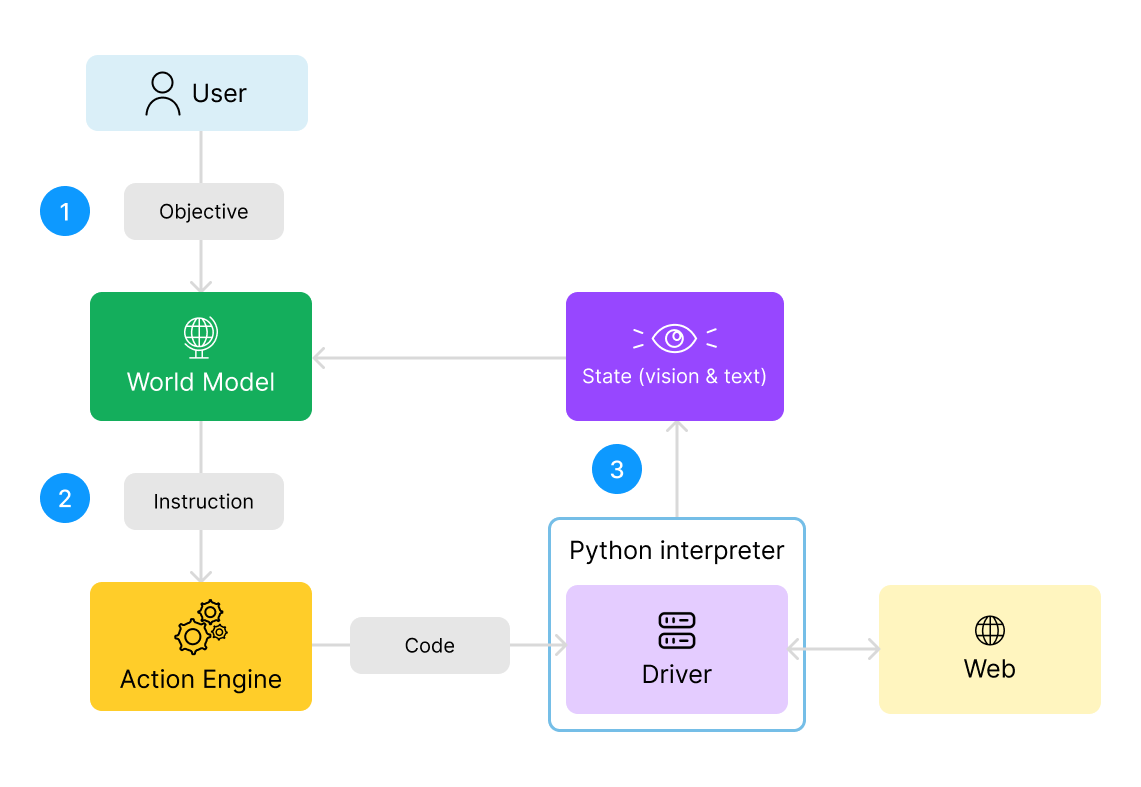
- 世界模型处理用户的全局目标。它考虑此目标以及通过屏幕截图和HTML代码获得的网页状态,并生成实现此目标所需的下一步,即文本指令。
- 该指令被发送到动作引擎,然后动作引擎生成执行此步骤所需的自动化代码并执行它。
- 然后,世界模型接收新的文本和图像数据,即新的屏幕截图和更新后的源代码,以反映网页的最新状态。有了这些信息,它就可以生成实现目标所需的下一步指令。
- 这个过程重复进行,直到目标达成!
Action Engine详解
正如我们所见,主要有两个模块执行大部分工作:
- 世界模型利用来自世界的观察和目标,进行高级推理和规划,并向动作引擎输出低级指令。
- 动作引擎接收这些低级指令并实际执行所需的动作。
我们将在这里重点介绍动作引擎,因为如果没有对动作生成进行良好评估,我们就无法衡量世界模型提供正确指令的能力。
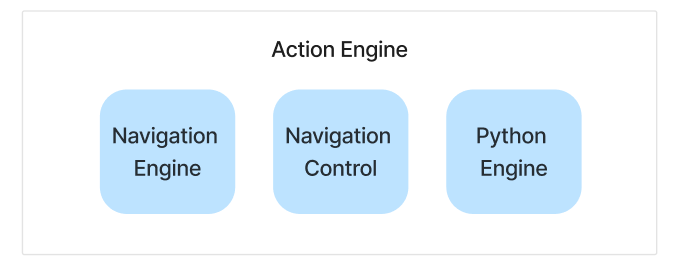
我们的动作引擎有三个主要引擎可供使用:
- 🚄 导航引擎: 生成并执行Selenium代码,以在网页上执行动作。
- 🐍 Python引擎: 生成并执行不涉及网页导航或交互的任务代码,例如信息提取。
- 🕹️ 导航控制: 执行常用的导航任务,无需额外的LLM调用。目前我们涵盖了:向上滚动、向下滚动和等待。
您可以在我们的文档中找到有关我们动作引擎的更多信息。
目前,我们的Python引擎只有一个功能,导航控制用于不需要思考的事情,例如等待或滚动,因此我们将在评估中省略这些。
我们将重点关注导航引擎,它承担了大部分工作:给定“点击‘日历’”之类的指令,它实际上会生成代码来执行该动作。
我们希望评估导航引擎生成正确执行所需动作代码的能力,这是我们AI网络代理的关键组成部分。
Navigation Engine详解
为了最佳评估导航引擎,我们将研究其工作原理,以了解其运作方式。这将使我们能够将评估分解为相关的子模块。
导航引擎的输入包括:
- 当前浏览页面的HTML
- 世界模型的指令,例如“点击PEFT部分”
它分为两个阶段:
它分为两个阶段:
- 检索当前页面相关的HTML片段
- 使用检索到的片段生成相关动作
例如,给定请求“点击PEFT部分”,我们得到以下片段:
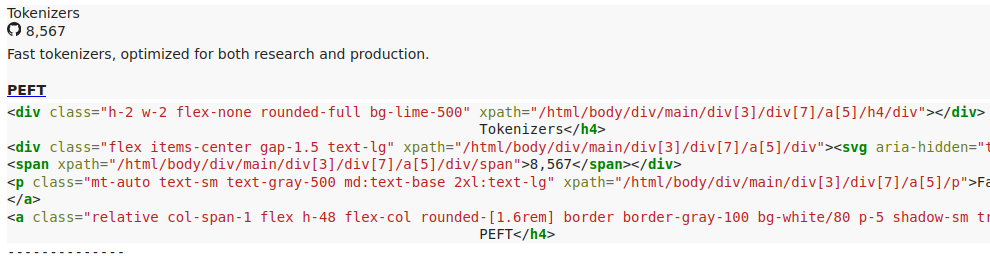
检索到的HTML片段示例
通过将这些片段与指令一起注入到LLM中,我们得到以下代码:

生成的动作代码示例
您可以在我们的文档中找到有关导航引擎的更多信息。
现在我们已经更精确地定义了框架的工作方式以及我们想要评估的模块,接下来让我们关注数据和指标。
评估数据
我们将使用两个数据集进行评估:
我们使用的格式包含以下主要字段:
- 原始HTML:要交互的页面的HTML
- 查询:要执行的指令,例如“点击创建账户”
- 完整XPath:要交互的真实元素的XPath
评估指标
鉴于我们的RAG工作流程,分两步评估整个系统非常重要:
- 检索器能否始终找到HTML中正确的片段来回答给定的请求?
- 给定这些片段,LLM能否生成正确的动作?
这在评估RAG管道时是相对经典的,其中召回率和精确率用于评估检索器,并为生成的代码提供一些指标。在这里,我们将对检索器和LLM的动作生成使用相似的指标:后端节点ID召回率和真实元素的精确率。
这里我们假设我们可以访问要交互元素的真实XPath。我们使用的数据集就是这种情况。
检索器评估
我们的目标是衡量检索器查找真实元素的能力。
以下是评估给定检索前的步骤:
- 首先,我们为页面的每个元素注入一个唯一的ID,称为后端节点ID。
- 然后使用真实XPath,我们识别真实元素。
- 然后我们获取其outerHTML,其中包含真实的后端节点ID。
现在来评估我们的检索器检索到的片段:
- 我们提取检索到的片段的后端节点ID。
- 我们计算真实后端节点ID的召回率/精确率。
###LLM评估
我们的目标是衡量LLM在给定包含要交互元素信息的真实HTML片段时,识别正确XPath并生成正确代码的能力。
我们将采用与检索器相似的方法:
- 我们生成用于定位特定元素的代码。
- 我们提取其outerHTML中包含的后端节点ID。
- 我们计算真实后端节点ID的召回率/精确率。
注意:我们选择对LLM使用真实ID召回率/精确率,而本可以使用其他指标,例如交并比(Intersection over Union)。然而,在撰写本文时,我们的数据集大多是静态的,但某些元素并非以相同方式系统加载,这使得难以利用纯视觉指标。
结果
![]()
您可以点击上方Colab链接,查看并运行我们将在这里讨论的模型评估代码。
我们还在文档中提供了如何使用我们的评估工具的说明。
由于接口相对简单,我们将更多地关注不同设置在TheWave和WebLinx上的结果及其解释。
检索
我们研究了不同嵌入模型对检索器性能(后端节点ID召回率)和成本的影响。
我们尝试了bge-small-en-v1.5、OpenAI text-embedding-3-large和Gemini text-embedding-004。

本地bge-small、OpenAI和Gemini嵌入的比较
首先,我们发现所有这些模型都提供了相似的召回率/精确率。
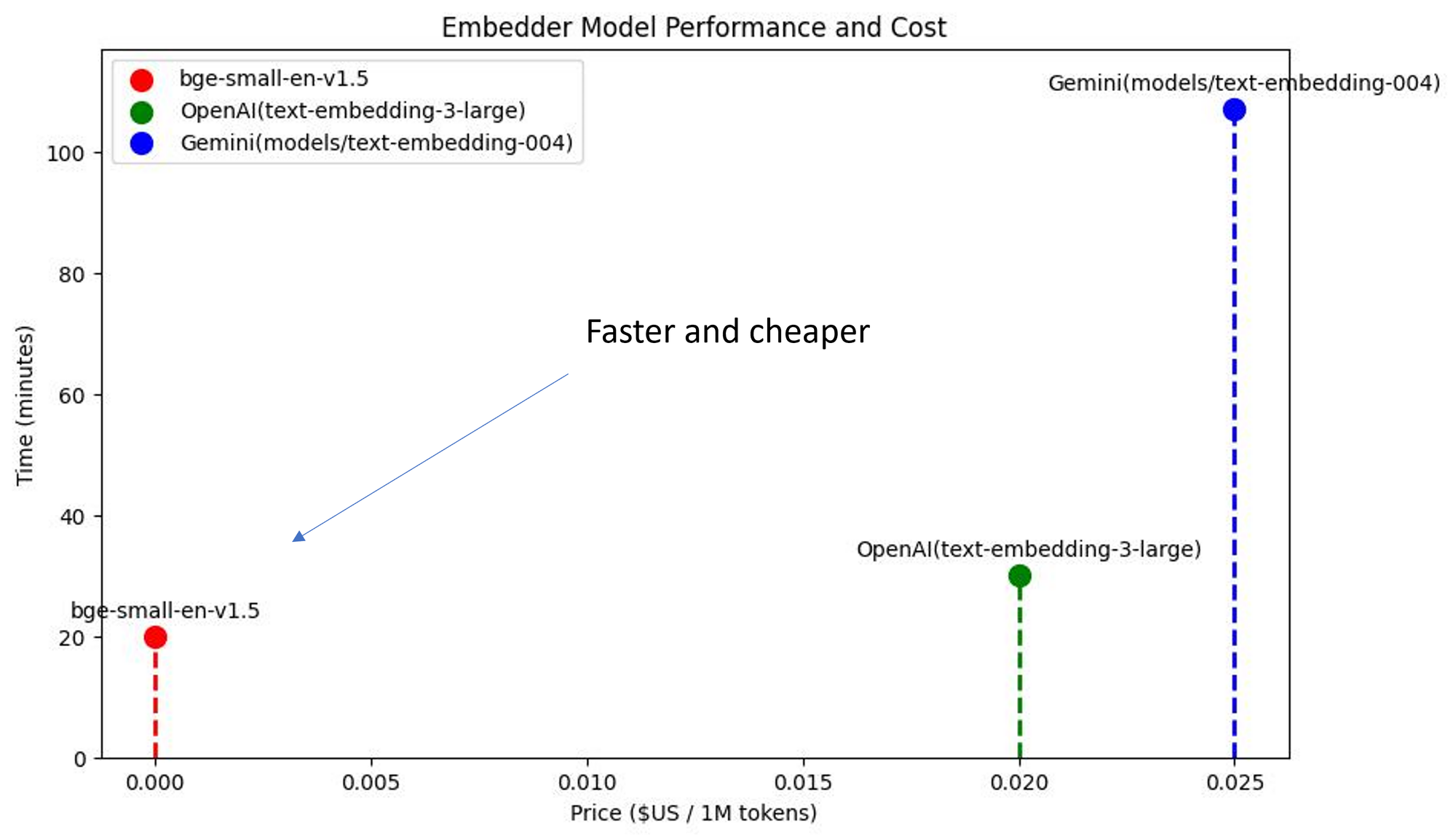
不同嵌入模型在基准测试和价格方面的推理时间比较
其次,我们研究了在整个基准测试中评估检索器所需的时间。我们还研究了与每种解决方案相关的每token价格。
我们发现,在相同性能(精确率/召回率)下,bge-small比专有模型更快、更便宜!
LLM
我们还研究了不同模型在输入包含交互元素信息的适当HTML片段时,生成正确动作的能力。
我们评估了多个模型,从Llama3 8b等开源模型,到通过Mistral的Codestral访问的GPT-4o等专有API。
因为我们不知道Gemini和OpenAI等专有API的参数数量,所以我们无法就性能/参数比进行真正的点对点比较。
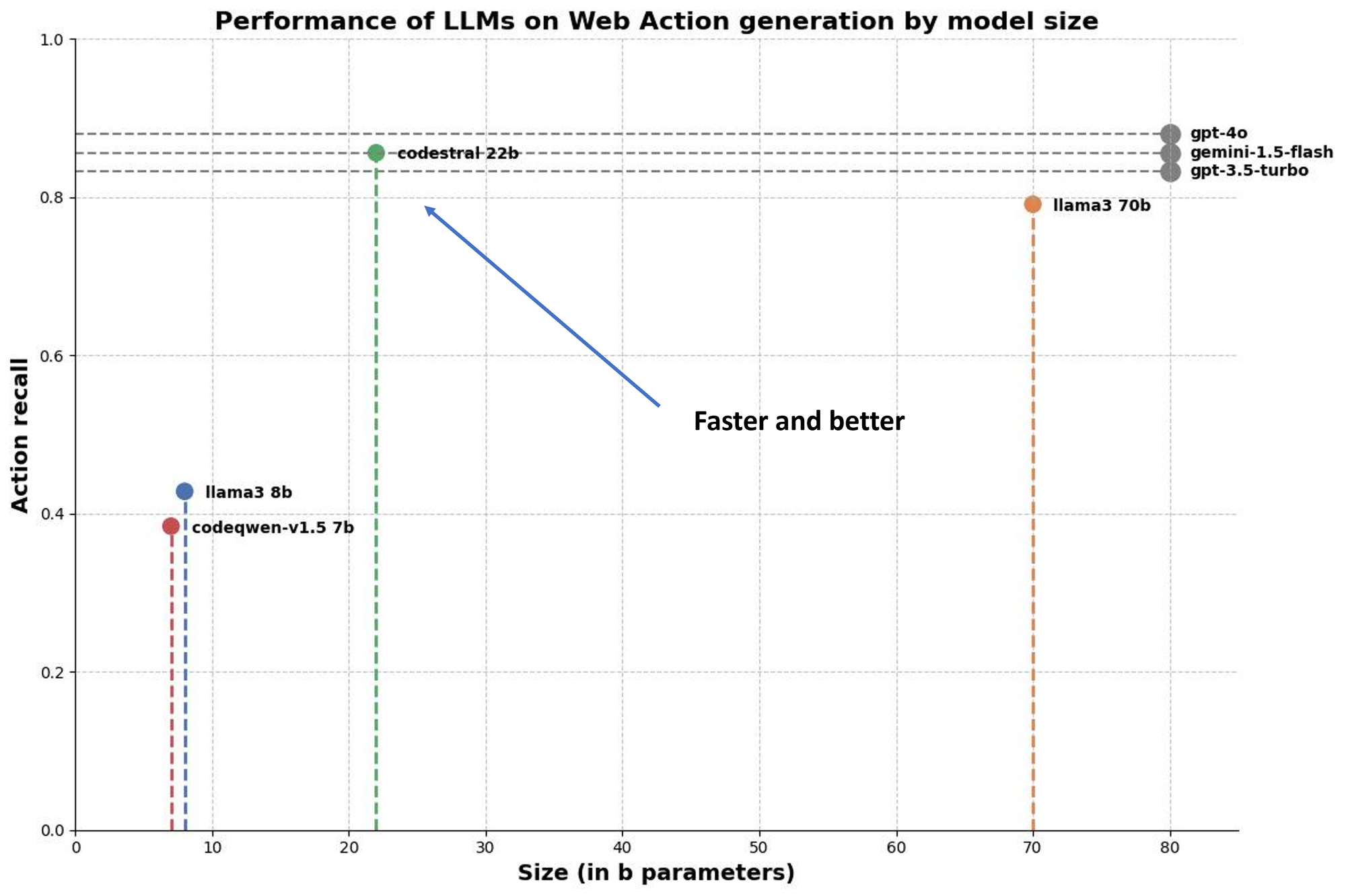
LLM代码生成性能与规模的比较
我们的发现:
🥇GPT-4o仍稳居榜首
🥈Codestral与Gemini-1.5 Flash不相上下!
🥉Codestral表现优于GPT-3.5和Llama 3 70b,两者性能大致相同。
模型越靠近左上方,其性能/成本比越好。
💡有趣现象:似乎存在一类模型,其性能与规模之间存在一定的比例关系(我们可以在Llama 3 8b和Llama 3 70b之间画一条线)。
然而,Codestral似乎独树一帜:它以更少的参数超越了Llama 3 70b!
结论
本文展示了LaVague如何利用LLM构建大型动作模型,仅通过自然语言指令即可自动控制浏览器。
这是通过对当前HTML进行RAG(检索增强生成)实现的:我们首先提取相关HTML片段来回答给定指令,然后将其注入到LLM中以生成所需动作。
我们还定义了相关评估指标,并使用专门为网络动作生成设计的数据集,对不同模型进行了测试。
我们发现本地模型在网络导航方面颇具竞争力:
- 嵌入模型:bge-small的性能可以与Gemini或OpenAI媲美,同时更快、更便宜。
- LLM:Codestral的性能可以与Gemini 1.5 Flash相匹敌,甚至优于GPT-3.5。
这些数据点非常有前景,它们表明未来可以设想运行本地、私有和可定制的AI网络代理来为我们与互联网交互。
仍然有大量工作要做。我们在这里只关注了导航引擎,但世界模型是我们架构的关键部分。不幸的是,在我们的实验中,我们发现没有开源模型能与GPT-4o媲美,而且也没有任何一个开源模型在实践中可用。
这似乎源于开源多模态LLM在训练上仍然具有挑战性,并且开源社区尚未找到系统且可靠的方法来利用LLM的视觉和文本输入。
然而,我们相信一个可行的开源多模态LLM将会出现,我们将尽快将其集成到世界模型的默认配置中。
希望您喜欢这篇文章。我们很高兴能有您加入我们的社区!如果您对大型动作模型、自动化和代理感兴趣,您可以加入我们的Discord与我们交流、提问,或为我们的开源项目贡献。
