使用DSPy和交叉编码器进行自动提示优化

目录
我最近训练了一组新的交叉编码器,基于约翰霍普金斯大学的Ettin编码器。该集合中的编码器基于ModernBERT,这是一种为计算高效推理而更新的BERT架构。虽然原始ModernBERT系列只包含基础模型和大型模型,但Ettin将模型大小增加到更小的尺寸(小至17M参数)。这对于**CPU推理**来说再完美不过了!
为了展示这些模型的一种用途,我将演示我最喜欢的应用之一——使用DSPy进行评估和自动提示优化。告别凭感觉推理的日子,开始评估您的AI程序。将LLM带回您项目中的机器学习领域。

交叉编码器
交叉编码器是BERT模型,它将文本对作为输入,并使用分类器头部,通常用于比较分类。常见用途包括STS(语义文本相似度)、NLI(自然语言推理)或用于检索的重排。与嵌入模型不同,嵌入模型需要您单独计算嵌入然后计算相似度(例如使用余弦相似度),交叉编码器将两个句子都作为输入,并且Transformer注意力会同时关注这两个句子。分类器头部会为您提供任务的分类或分数。
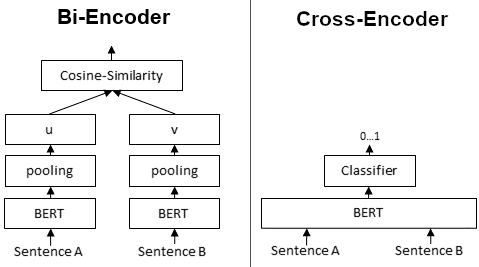
交叉编码器通常针对特定任务进行训练。它们表现通常非常好,但代价是计算复杂性增加(令牌输入和输入序列因配对而加倍,复杂性为N^2)。它们也不生成您可以存储和重用的向量。
ModernBERT 使用局部注意力和全局注意力的交错层,可以处理最长达 **8192 个令牌**的输入。这使其成为交叉编码器的一个良好架构。局部注意力通过减小注意力窗口大小来提高效率,仅在必要时使用少量全局注意力层。
作为评估器的交叉编码器
交叉编码器,特别是STS模型,我最喜欢的用途之一是自动提示优化。当您有自然语言输出,并且希望对LLM的答案进行评分(它可能正确但措辞不同)时,STS模型非常有用。当您使用它们评估LLM的响应时,您可以查看提示的表现如何。然后,使用MIPROv2等优化器,您可以合成生成更好的指令、引导示例并找到好的示例以添加少量提示。
DSPy优化
在此示例中,我们将加载 HotPot QA 数据集。此数据集在答案**正确性**方面可能不会看到巨大的收益,但我们仍然可以使用我们的评估器来指导 LLM 如何响应。例如,我们可以使用示例来使输出格式与我们的黄金示例(来自数据集的“正确”答案)相似,并确保任务提示指令编写良好。优化对于演示示例对提高性能非常有用的任务(例如分类、信息提取等)尤其有效。
为什么选择DSPy?
如果你的目标只是简化LLM推理代码的编写,那么市面上有很多选择。然而,当你第一次开始使用DSPy时,重要的是要认识到你不再学习一个LLM框架,而是一个**机器学习**框架。这意味着所有常见的要素——评估、训练/开发/测试集和优化。当你将这种心态带入AI应用开发领域时,你很快就会意识到这是一条熟悉且成熟的道路:与专家合作、评估你的输出、开发数据集和监控模型性能。
当你开始这样思考时,你会意识到许多好处
- 自信地切换模型(成本与性能优化)
- 有助于向业务方传达解决方案的质量
- 实现性能漂移监控
- 放弃“提示工程”,回归常规工程
最难的部分是弄清楚如何评估你的输出,这通常需要一些思考和创造力。有很多方法可以做到这一点,例如使用另一个DSPy程序作为LLM-as-a-Judge。或者更简单地,使用交叉编码器。
设置评估指标
首先,我们创建一个函数,该函数使用交叉编码器来提供黄金示例和预测示例之间的评估分数。
def cross_encoder_metric(cross_encoder_model, example, pred, trace=None):
"""Metric function using EttinX cross-encoder for semantic similarity evaluation"""
gold_answer = example.answer.strip()
pred_answer = pred.answer.strip() if hasattr(pred, 'answer') else str(pred).strip()
sentence_pairs = [(gold_answer, pred_answer)]
scores = cross_encoder_model.predict(sentence_pairs)
similarity_score = float(scores[0])
return similarity_score >= SIMILARITY_THRESHOLD if trace is not None else similarity_score
我们使用`dleemiller/EttinX-sts-xs`。这个交叉编码器非常小,在CPU上运行速度很快(我在2019年的i5笔记本电脑上使用它)。
加载数据
现在我们需要加载数据集的拆分。我们使用 3 个拆分:`train`(用于演示、引导演示和提出指令),`dev`(用于评估这些内容的组合)和 `test`(用于优化前后独立评分)。
def load_dataset(train_size=TRAIN_SIZE, dev_size=DEV_SIZE, test_size=TEST_SIZE):
"""Load HotPotQA dataset with specified splits"""
console.log(f"Loading HotPotQA dataset (train:{train_size}, dev:{dev_size}, test:{test_size})")
dataset = HotPotQA(
train_seed=1, train_size=train_size,
eval_seed=2023, dev_size=dev_size, test_size=test_size
)
# Set input keys as required by DSPy
splits = {
'train': [x.with_inputs('question') for x in dataset.train],
'dev': [x.with_inputs('question') for x in dataset.dev],
'test': [x.with_inputs('question') for x in dataset.test]
}
console.log(f"Loaded {len(splits['train'])} train, {len(splits['dev'])} dev, {len(splits['test'])} test examples")
return splits['train'], splits['dev'], splits['test']
DSPy签名和预测器
DSPy“签名”很像pydantic模型,您可以在其中指定输入和输出。值得注意的是,文档字符串、字段描述和类型注释都是组成“提示”的重要部分。签名的文档字符串实际上是“主提示”。
你经常会看到这样的写法
class QASignature(dspy.Signature):
"""Answer questions clearly and concisely"""
question: str = dspy.InputField(desc="The question to answer")
answer: str = dspy.OutputField(desc="The answer to the question")
predictor = dspy.ChainOfThought(QASignature)
简单的签名甚至可以使用简写方式
predictor = dspy.ChainOfThought("question -> answer")
不过在实际操作中,前者更明确的声明提供了更大的灵活性。一旦你添加了一个预测器,比如`dspy.ChainOfThought`(用于思维链响应)、`dspy.Predict`(用于简单预测)或`dspy.ReAct`(用于代理工具使用),你就可以开始对LLM进行推理了。
训练DSPy程序
设置训练相当简单。需要设置一些参数
teleprompter = MIPROv2(
metric=metric,
auto="light", # Can be "light", "medium", or "heavy"
num_threads=1,
verbose=True
)
optimized_program = teleprompter.compile(
student=initial_program,
trainset=trainset,
valset=devset,
requires_permission_to_run=False,
)
MIPROv2的工作原理
MIPROv2 分三个阶段系统地优化您的程序。
**阶段1:引导示例** - 在训练数据上多次运行您的程序,仅保留与您的指标得分良好的输入/输出对。这将创建高质量的少量示例池,这些示例实际上是有效的。
**阶段2:生成指令** - 通过分析您的训练数据模式、程序结构和引导示例,创建多个指令变体。它会添加随机的“提示”,例如“要有创意”,以探索不同的指令风格。
**阶段3:贝叶斯搜索** - 这是关键:您的训练集仅用于阶段1和阶段2。您的验证集专门用于优化期间的评估。贝叶斯优化测试指令+少量示例的不同组合,学习哪些组合效果良好,而不是仅仅尝试随机组合。
结果是,每个预测器都获得了最适合您的特定任务和数据的指令和示例组合。
结果
以下是我们的优化在HotPot QA数据集上的表现。MIPROv2从一个使用基本指令的简单预测器开始,通过其优化过程系统地提高了性能。
优化进度
优化经过 10 次试验,测试了指令和少数样本示例的不同组合。
- **试验 1(基线)**:45.02% - 默认程序,使用基本指令“用分步推理回答问题”
- **试验 2**:50.67% - 采用更详细的专家系统指令,性能更好
- **试验 6**:60.52% - 通过恢复简单指令但使用优化后的少数样本示例,实现了**最佳性能**
- **最终试验**:持续探索但未发现进一步改进
最终表现
Performance Comparison
┏━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┓
┃ Metric ┃ Score ┃
┡━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━┩
│ Initial Program │ 36.75 │
│ Optimized Program │ 43.52 │
│ Improvement │ +6.77 │
│ Relative Improvement │ +18.42% │
└──────────────────────┴─────────┘
改进示例
查看具体示例,我们可以看到优化如何改变了不同类型的问题
- **答案格式**:优化后的模型学会给出更简洁的答案(短响应 vs. 完整句子解释)
- **多跳推理**:在提示中添加了有用的思维链推理演示。
18.42% 的相对改进表明,即使在像 HotPot QA 这样具有挑战性的多跳推理数据集上,系统优化也简单、有效,并且无需手动调整提示即可量化性能提升。
**注意:** 语义相似度与**正确性**不同;然而,它对于提高响应的一致性非常有效,并且通常与正确性高度相关。STS 与 LLM-as-a-judge 结合使用时,通过添加快速、稳定的信号来指示主题/词汇对齐,可以作为更完整的评估指标。
结论
就是这样!通过几个简单的步骤,我们设置了评估并用它来实际优化我们的程序。我们看到了输出的显著改进,并且在少量示例真正有助于任务时,许多应用程序可以获得更大的成功。
总结
- **交叉编码器可用作语义相似性任务的评估器**,在精确字符串匹配失败时表现良好
- **DSPy的系统方法优于手动调整** - 如果没有评估,提示工程既耗时又烦人。MIPROv2找到了本来需要大量尝试和希望才能找到的组合。
- **小模型效果出奇地好** - 32M参数的EttinX特小型模型在CPU上运行速度快,同时提供了可靠的评估。
- **正确的机器学习实践至关重要** - 训练/开发/测试集和系统优化确实能带来改变,从长远来看还能节省时间。
这在玩具示例之外具有很好的扩展性。对于生产应用,您可以使用更大的验证集,运行更多的优化试验,并混合多种评估指标。该框架为您构建可实际部署的可测量AI系统提供了坚实的基础。
我希望您能从本次演练中有所收获,并受到启发,在自己的项目中采用系统的方法进行提示优化。
此博客的完整脚本可以在这里找到:https://github.com/dleemiller/auto-prompt-opt-dspy-cross-encoders