ZML LLMD 推理引擎试驾 🚀
社区文章 发布于 2025 年 7 月 18 日







ZML 刚刚发布了其新推理引擎 LLMD 的技术预览版,值得一试。以下是我对此感到非常兴奋的原因
- ⚡️ 轻量级 — 容器仅 2.4GB,体积小巧,这意味着启动时间快,自动扩缩容效率高。
- 🧠 优化 — 内置 Flash Attention 3(NVIDIA)和 AITER 内核(AMD)。
- 🛠 设置简单 — 只需挂载您的模型并运行容器。
- 🎮 跨平台 GPU 支持 — 可在 NVIDIA 和 AMD GPU 上运行。
- 🏎 高性能
- 🧡 用 Zig 编写 — 献给所有 Zig 粉丝。
如何(轻松)测试
我没有配备 NVIDIA GPU 的强大远程机器可以 SSH 登录,也许您也没有。因此,这里有一个在 Hugging Face 推理端点 🔥 上轻松试用它的方法。
1. 前提条件
- 您需要一个 Hugging Face 账户并设置有效的付款方式。
- 准备就绪后,前往 endpoints.huggingface.co
2. 选择模型
点击 "New" 开始一个新的推理端点。
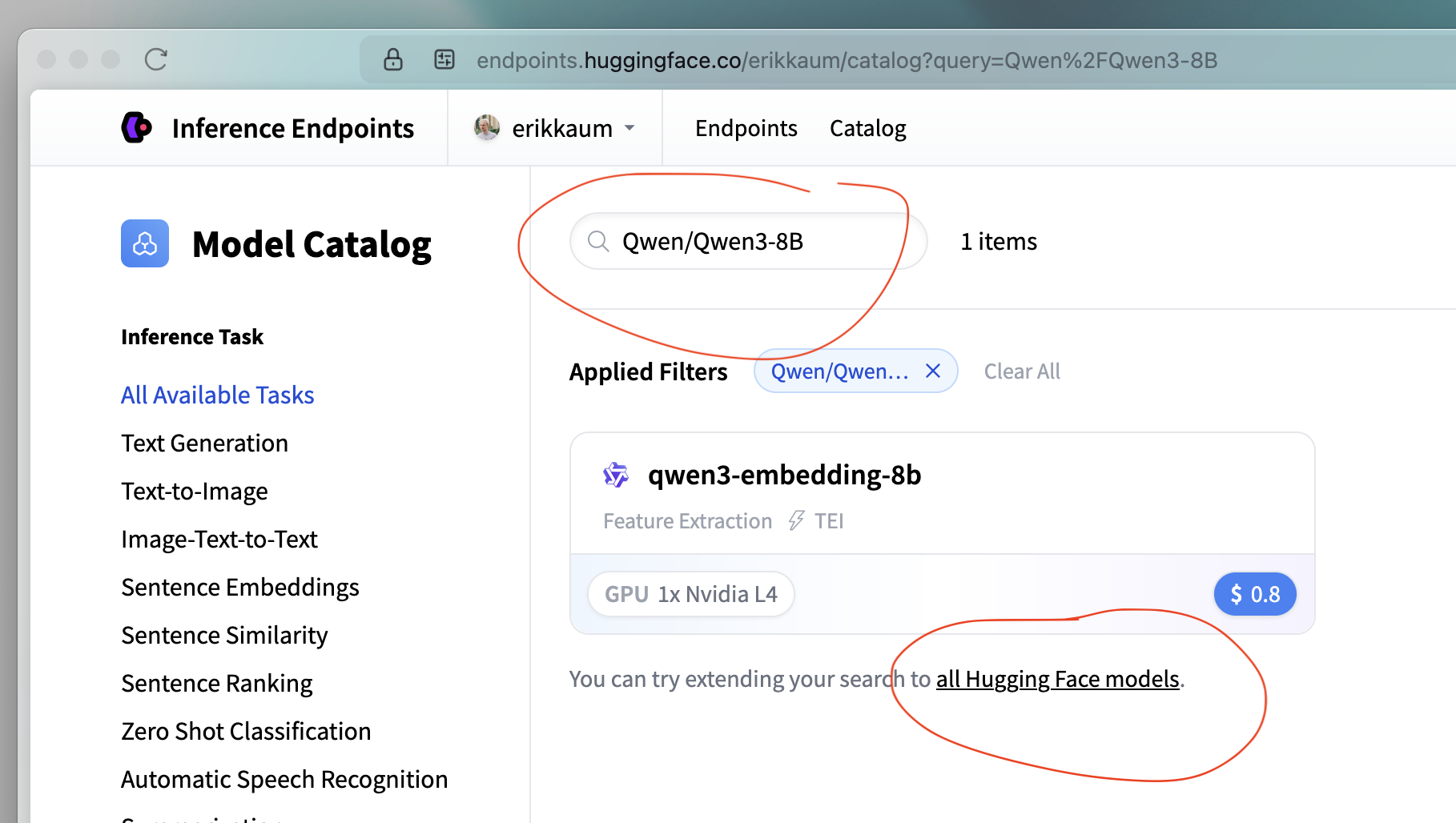
在筛选栏中,搜索
Qwen/Qwen3-8B。它不会立即显示,所以点击 “尝试将搜索范围扩展到所有 Hugging Face 模型。”
在弹出的模态框中,您应该会看到
Qwen3-8B作为首个结果。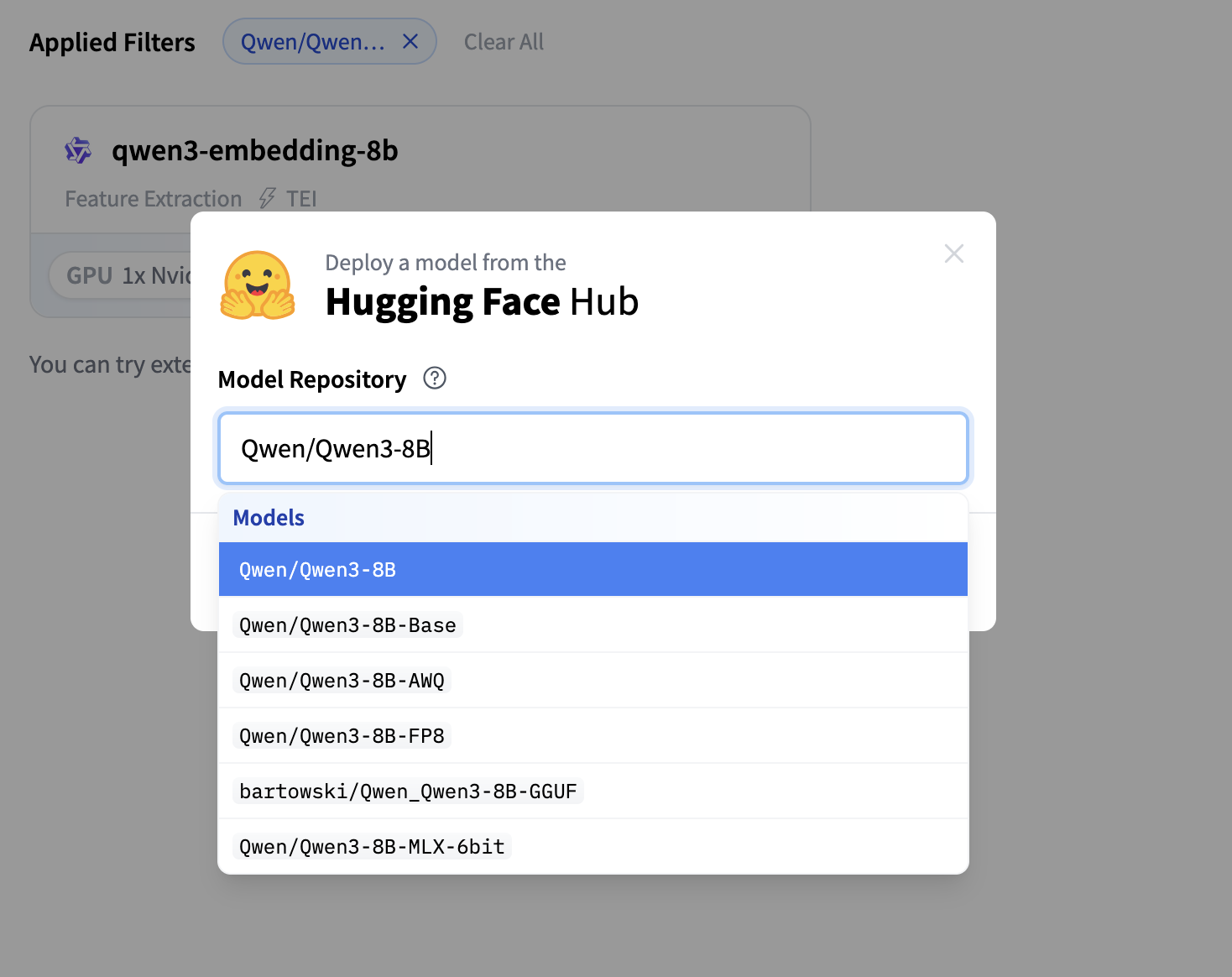
点击 "部署模型" 🚀
3. 配置端点
GPU: 选择 NVIDIA L4。足以测试 Qwen3-8B 而无需花费太多。
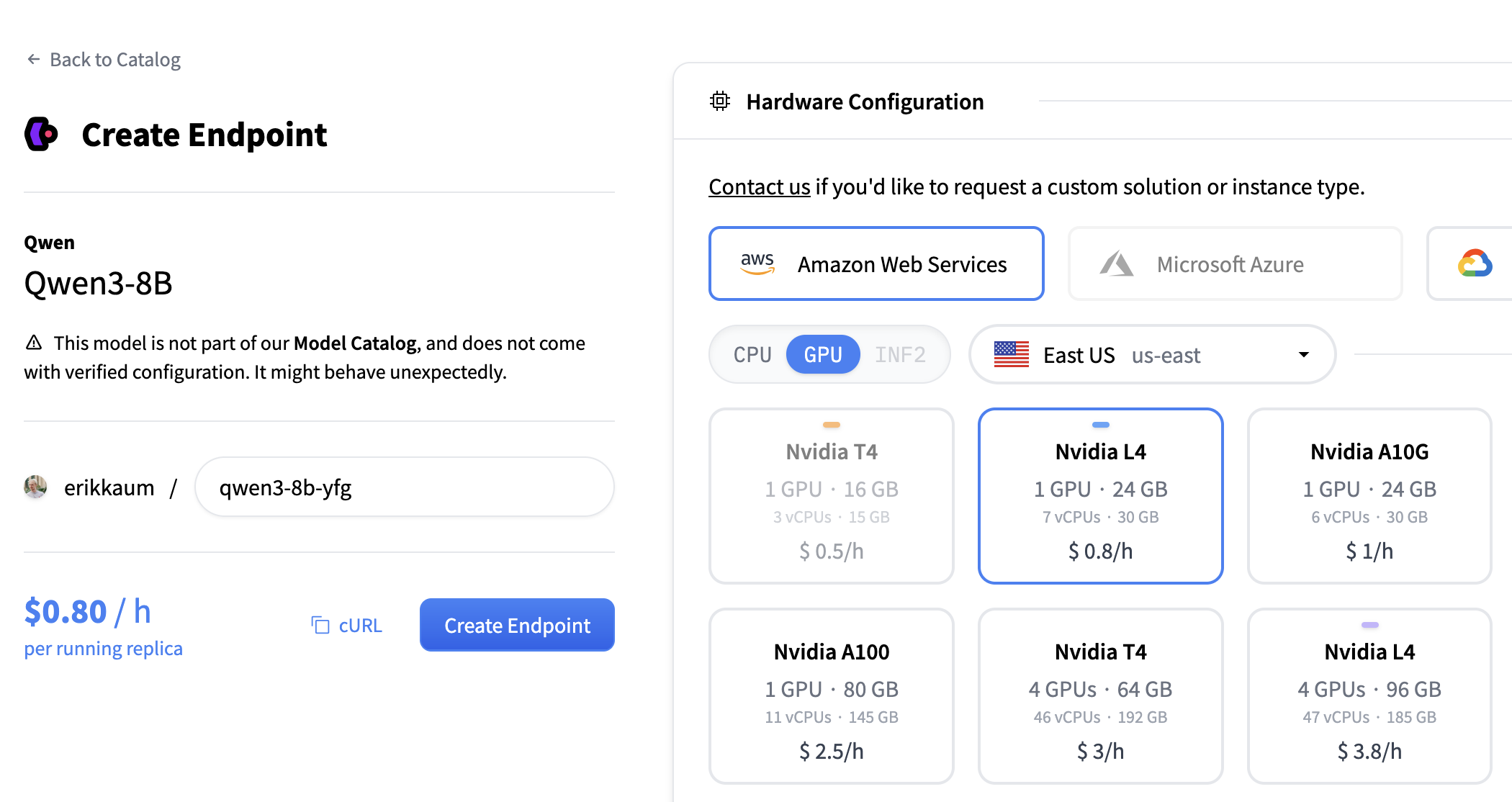
容器配置:
- 选择 “自定义”
- 容器 URL:
zmlai/llmd:latest - 容器端口:
8000 - 健康检查路由:
/v1/models(据我所知 LLMD 没有暴露专门的健康检查路由,但这个路由对于 Kubernetes 就绪探针来说运行良好。)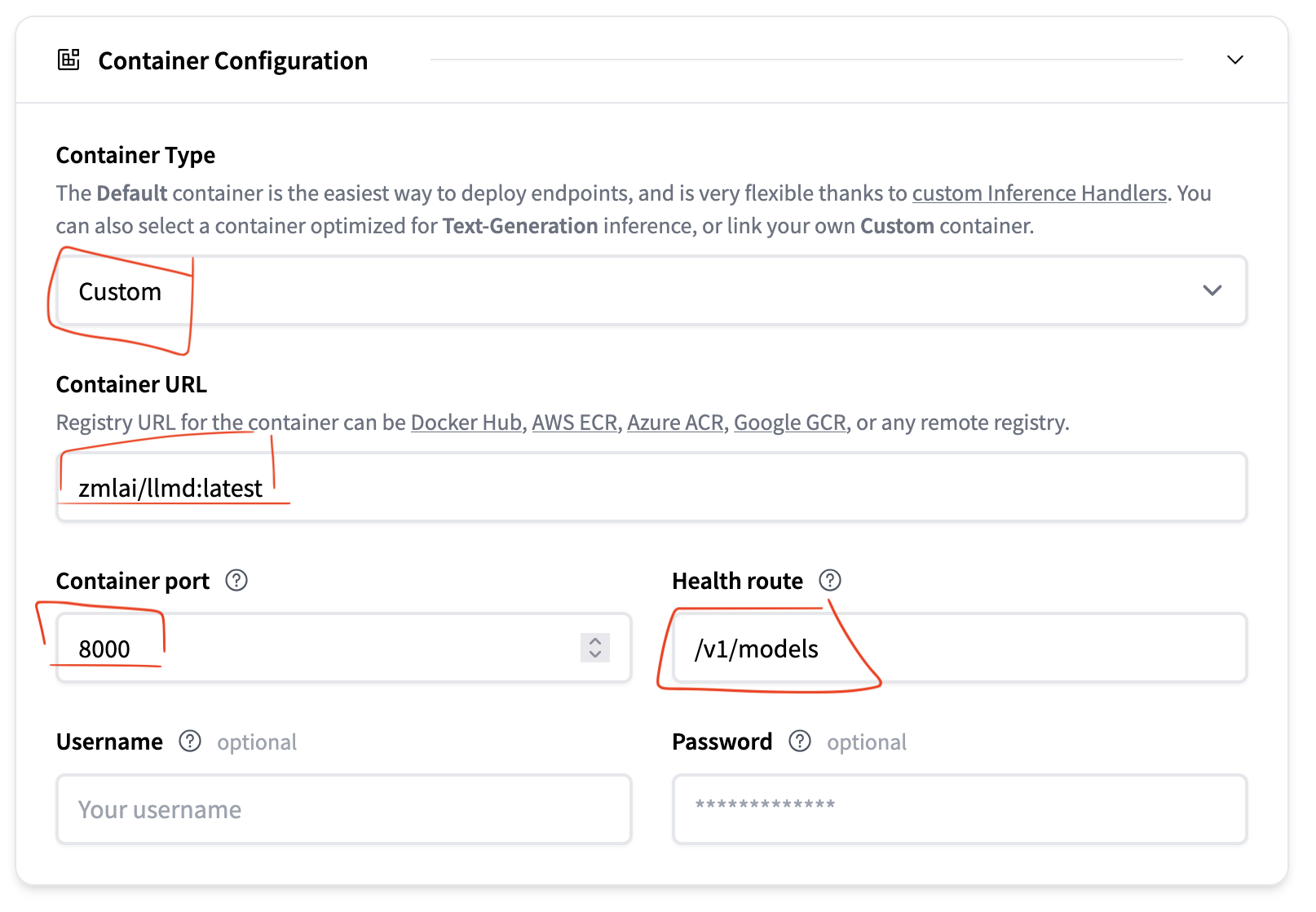
高级配置:
- 将容器参数设置为
这会告诉 LLMD 在哪里找到模型权重(它们将自动挂载到--model-dir=/repository/repository)。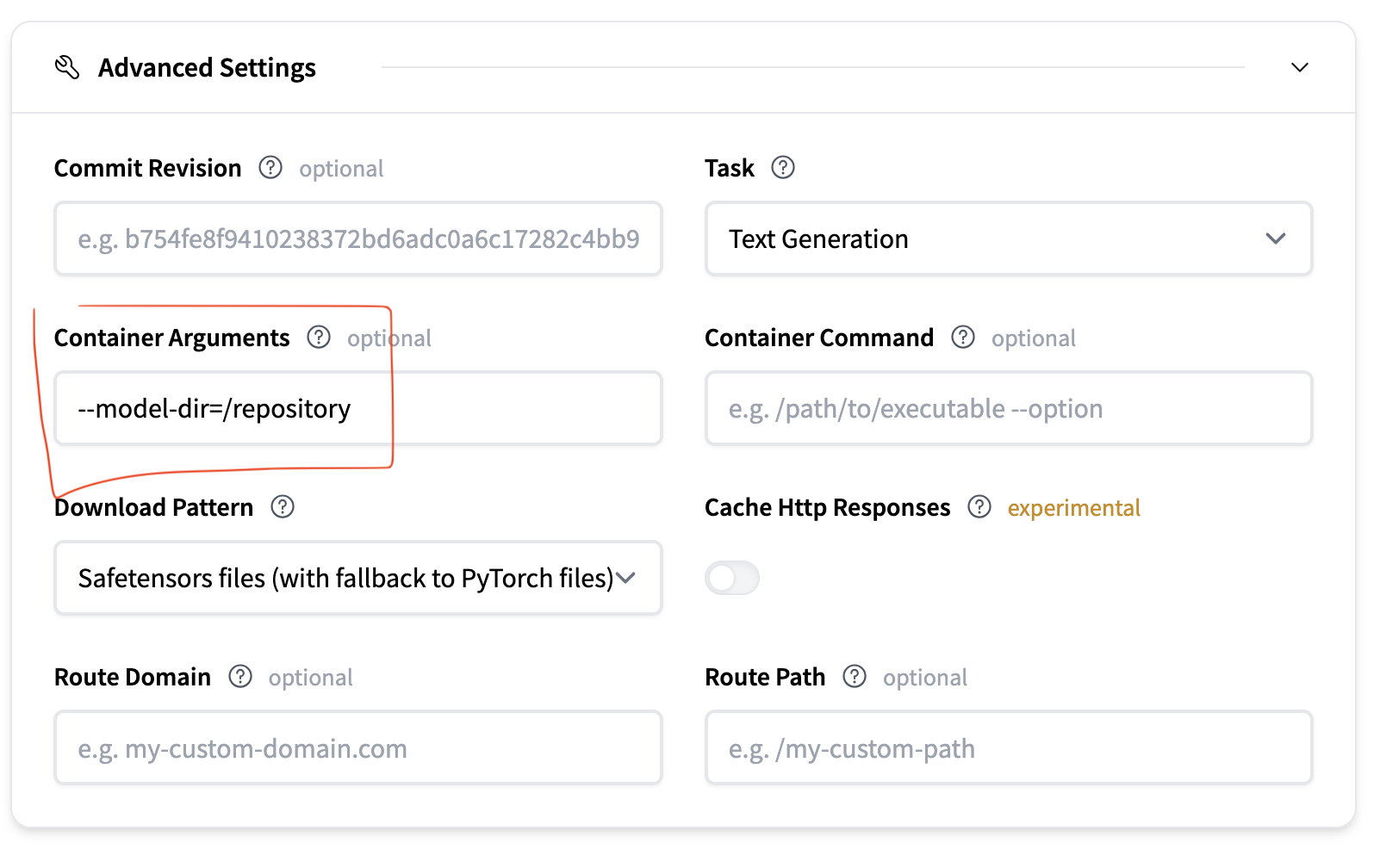
- 将容器参数设置为
点击 "创建端点",即可开始!
4. 调用模型
几分钟后,您的推理端点状态将从初始化中变为运行中。您可以查看日志以确保一切正常 👍 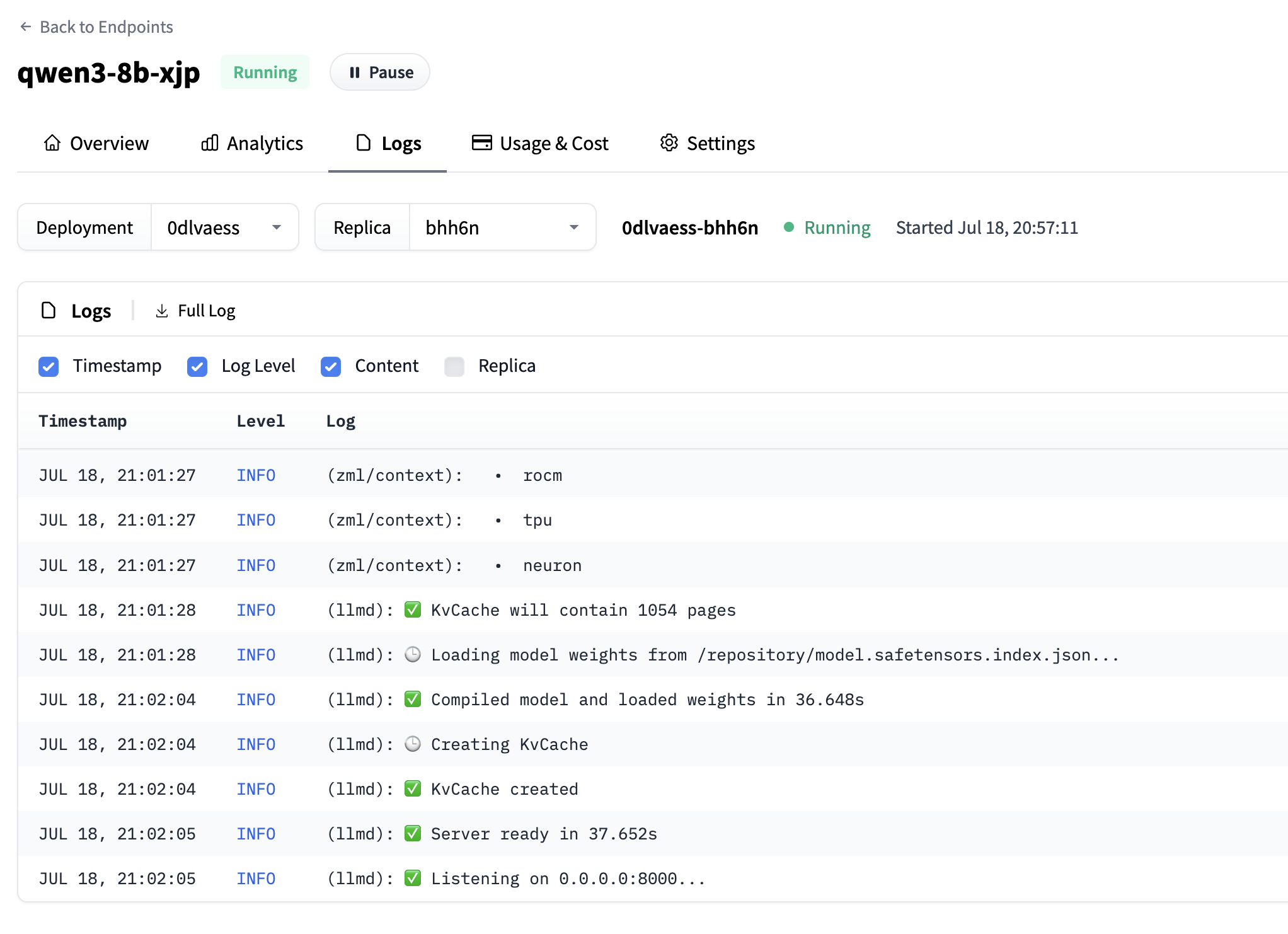
现在获取推理 URL。然后启动您的终端并发出请求
curl https://<your-url>.endpoints.huggingface.cloud/v1/chat/completions \
-X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer hf_xxx" \
-d '{
"model": "qwen3",
"messages": [
{ "role": "user", "content": "Can you please let us know more details about your " }
],
"max_tokens": 150
}'
The result should be something like:
```json
{
"id": "id",
"choices": [
{
"finish_reason": "length",
"index": 0,
"message": {
"content": "<think>\nOkay, the user is asking for more details about me, but their message is cut off. They wrote, \"Can you please let us know more details about your\" and then it ends. I need to figure out how to respond appropriately.\n\nFirst, I should acknowledge that their message is incomplete. Maybe they intended to ask about my capabilities, features, or something else. Since they mentioned \"more details about your,\" it's possible they were going to ask about my functions, how I work, or my purpose.\n\nI should respond politely, letting them know that their message is incomplete and ask them to clarify their question. That way, I can provide a helpful answer. I need to make sure my response is friendly and encourages them",
"refusal": null,
"role": "assistant"
},
"logprobs": null
}
],
"created": 1752865521425,
"model": "qwen3",
"system_fingerprint": "",
"object": "chat.completion",
"usage": {
"completion_tokens": 150,
"prompt_tokens": 40,
"total_tokens": 40,
"completion_tokens_details": null,
"prompt_tokens_details": null
}
}
太棒了 🔥
下一步
请记住,这仍然是技术预览版,尚未准备好投入生产。可能会遇到一些粗糙之处或出现故障。
当前限制
- 目前仅支持 llama 和 qwen3 模型类型。
- 只能在单个 GPU 上运行,因此需要分片到多个 GPU 的大型模型将无法工作
- 最大批量大小为 16。
- 不支持前缀缓存
如果您试用它,ZML 团队可能会很乐意收到您的任何反馈。我们也是一样,如果您对推理端点有任何想法或反馈,请在下方留言 🙌
祝您玩得开心!






