在 Hub 上发布评估功能









此项目已归档。如果您想在 Hub 上评估 LLM,请查看此排行榜集合。
TL;DR:今天我们推出了Hub 上的评估功能,这是一个由AutoTrain驱动的新工具,让您无需编写一行代码,即可在 Hub 上的任何数据集上评估任何模型!
人工智能的进步令人惊叹,以至于现在有些人认真地讨论人工智能模型在某些任务上是否会比人类更出色。然而,这种进步并非平衡:对于几十年前的机器学习者来说,现代硬件和算法可能令人难以置信,我们可支配的数据和计算量也同样令人惊叹,但我们评估这些模型的方式却大致保持不变。
然而,毫不夸张地说,现代人工智能正处于评估危机之中。如今,适当的评估涉及衡量许多模型,通常是在许多数据集上,并使用多种指标。但这样做不必要地繁琐。如果我们关注可复现性,情况尤其如此,因为自报结果可能存在无意的错误、细微的实现差异,甚至更糟。
我们相信,如果我们(社区)建立一套更好的最佳实践并努力消除障碍,就能实现更好的评估。在过去的几个月里,我们一直在努力开发Hub 上的评估功能:只需点击一下按钮,即可在任何数据集上使用任何指标评估任何模型。为了开始,我们评估了数百个模型,使用了几个关键数据集,并使用 Hub 上巧妙的新拉取请求功能,在模型卡上打开了大量 PR,以显示其经过验证的性能。评估结果直接编码在模型卡元数据中,遵循 Hub 上所有模型的一种格式。查看DistilBERT的模型卡,看看它是什么样子!
在 Hub 上
Hub 上的评估功能为许多有趣的用例打开了大门。从需要决定部署哪个模型的数据科学家或高管,到试图在新数据集上重现论文结果的学者,再到希望更好地理解部署风险的伦理学家。如果我们要挑选三个主要的初始用例场景,它们是:
为您的任务找到最佳模型
假设您确切地知道您的任务是什么,并且您想为这项工作找到合适的模型。您可以查看代表您任务的数据集的排行榜,其中汇总了所有结果。这很棒!如果您感兴趣的那个花哨的新模型还没有在该数据集的排行榜上怎么办?只需在不离开 Hub 的情况下为其运行评估即可。
在新数据集上评估模型
现在,如果您有一个全新的数据集,您想对其进行基准测试怎么办?您可以将其上传到 Hub,并根据需要评估任意数量的模型。无需代码。更重要的是,您可以确保您在您数据集上评估这些模型的方式与它们在其他数据集上评估的方式完全相同。
在许多其他相关数据集上评估您的模型
或者假设您有一个全新的问答模型,在 SQuAD 上训练的?有数百个不同的问答数据集可以评估:😱 您可以直接从 Hub 选择您感兴趣的那些数据集并评估您的模型。
生态系统
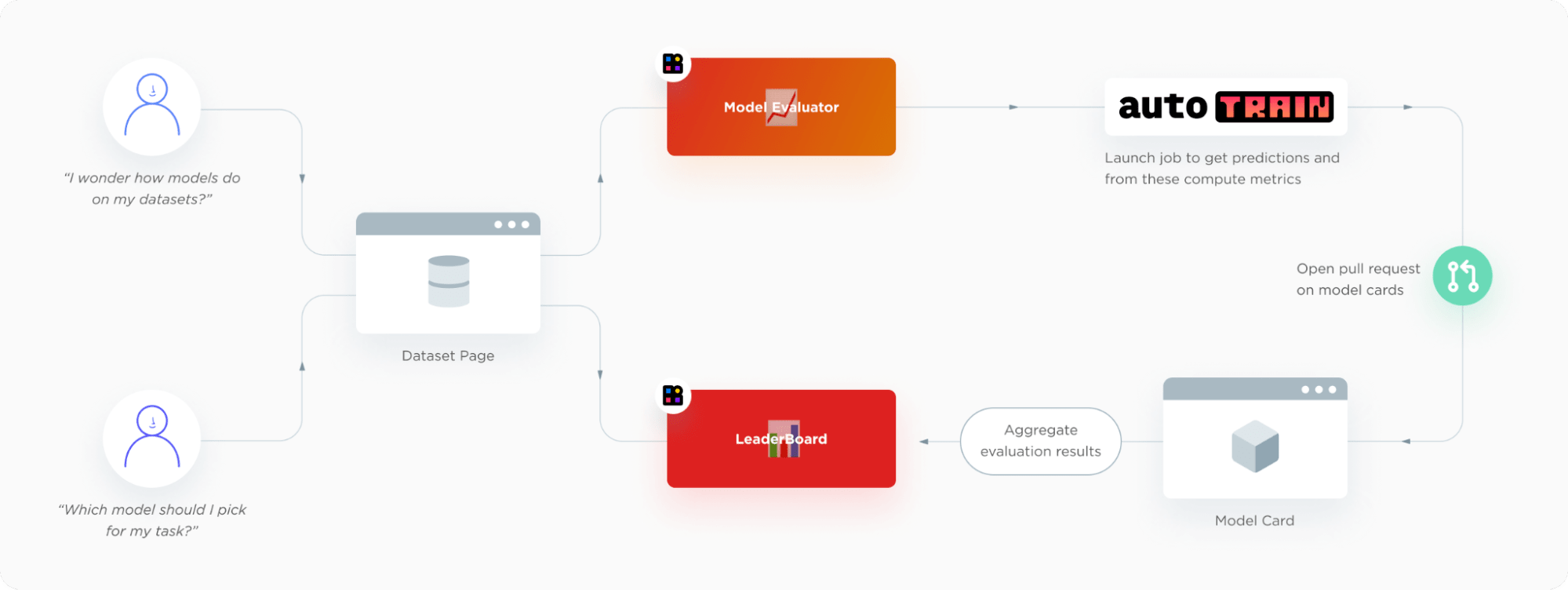
Hub 上的评估旨在让您的生活更轻松。当然,幕后发生了很多事情。我们真正喜欢 Hub 上的评估功能的原因是:它与现有的 Hugging Face 生态系统完美契合,我们几乎必须这样做。用户从数据集页面开始,可以在那里启动评估或查看排行榜。模型评估提交界面和排行榜是常规的 Hugging Face Spaces。评估后端由 AutoTrain 提供支持,它会在给定模型的模型卡上打开一个 PR。
内部测试 - 区分狗、松饼和炸鸡
那么它在实践中是怎样的呢?让我们来看一个例子。假设您的业务是区分狗、松饼和炸鸡(也称为内部测试!)。

如上图所示,要解决这个问题,您需要
- 包含狗、松饼和炸鸡图片的真实数据集
- 在该图片上训练的图像分类器
幸运的是,您的数据科学团队已将一个数据集上传到 Hugging Face Hub,并在其上训练了几个不同的模型。现在您只需选择最好的一个——让我们使用 Hub 上的评估功能,看看它们在测试集上的表现如何!
配置评估任务
要开始,请访问 model-evaluator Space 并选择您要评估模型的数据集。对于我们的狗和食物图像数据集,您将看到类似下图的内容:
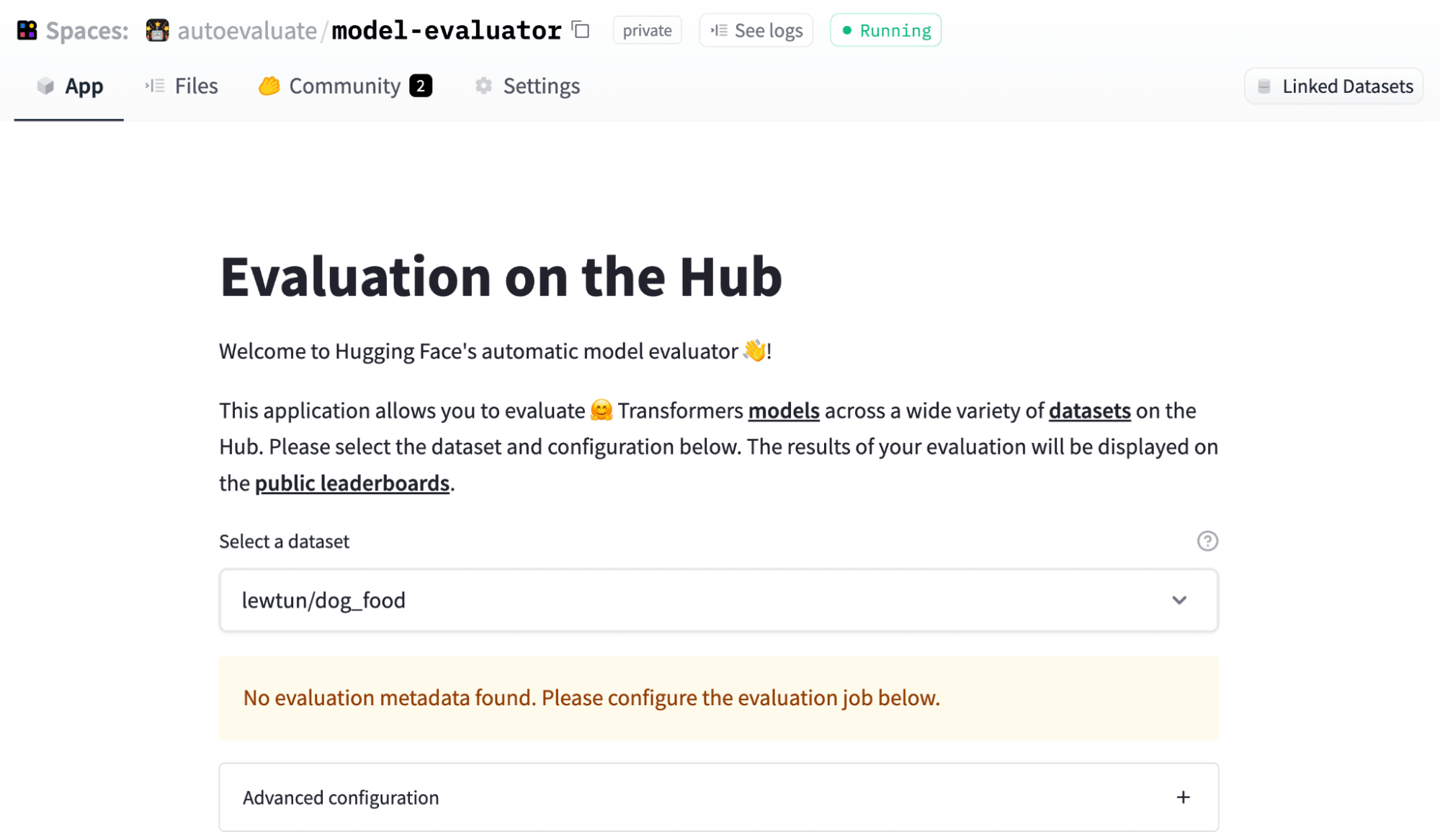
现在,Hub 上的许多数据集都包含指定如何配置评估的元数据(请查看acronym_identification以获取示例)。这使您可以通过单击评估模型,但在我们的例子中,我们将向您展示如何手动配置评估。
单击“高级配置”按钮将显示各种设置供您选择
- 任务、数据集和拆分配置
- 数据集列到标准格式的映射
- 指标选择
如下图所示,配置任务、数据集和要评估的拆分非常简单

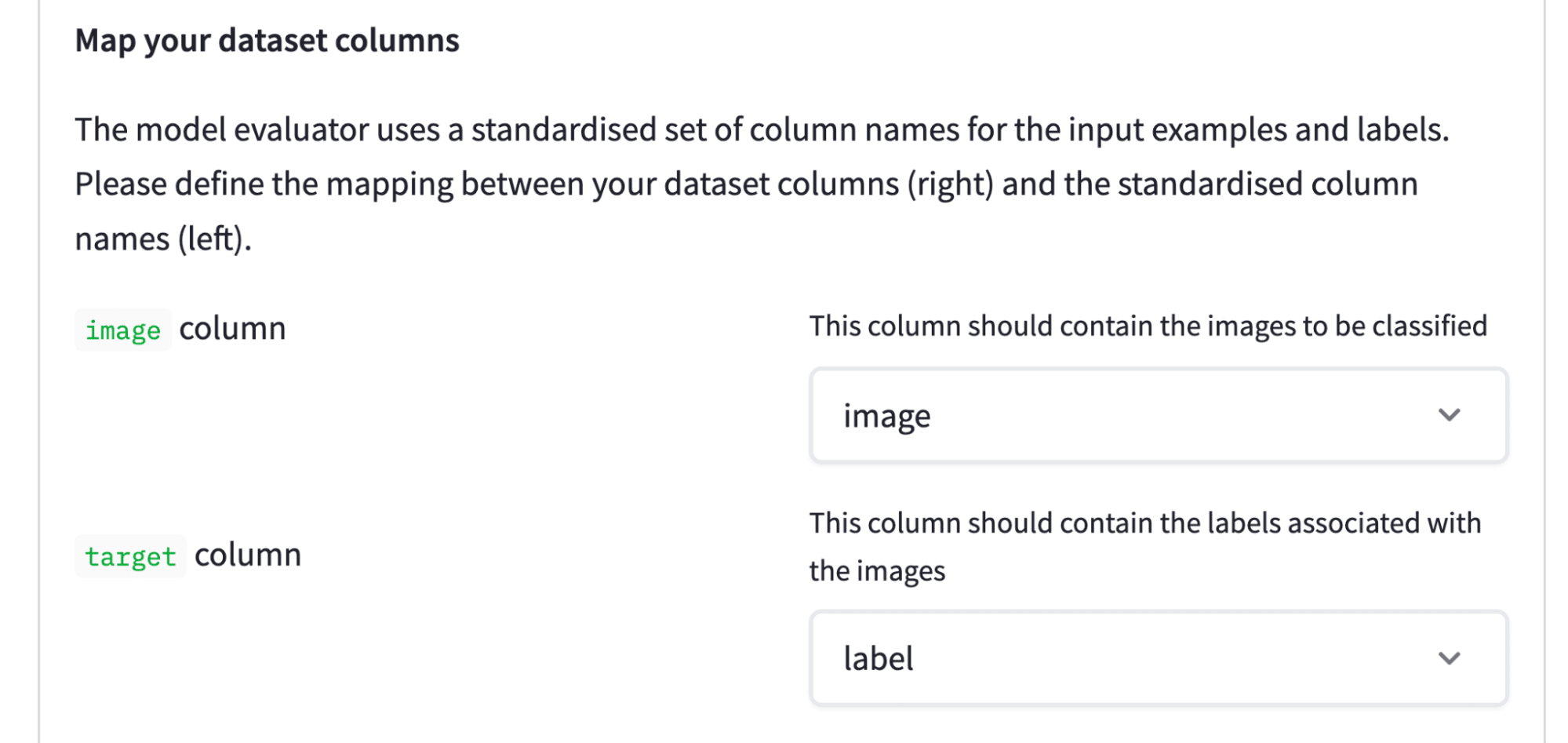
下一步是定义哪些数据集列包含图像,哪些列包含标签
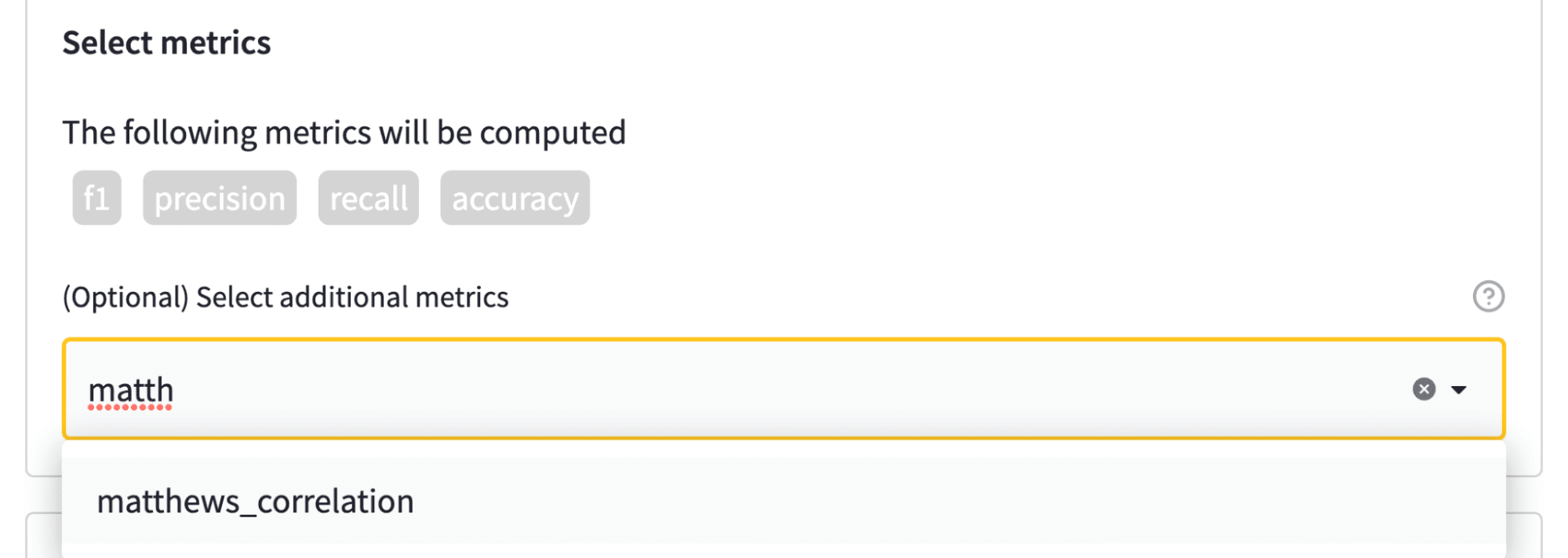
任务和数据集配置完成后,最后(可选)一步是选择要评估的指标。每个任务都与一组默认指标相关联。例如,下图显示 F1 分数、准确度等将自动计算。为了增加趣味性,我们还将计算马修斯相关系数,它提供了分类器性能的均衡衡量标准
配置评估任务就这么简单!现在我们只需选择一些要评估的模型——让我们来看看。
选择要评估的模型
Hub 上的评估通过模型卡元数据中的标签链接数据集和模型。在我们的示例中,我们有三个模型可供选择,所以让我们将它们全部选中!
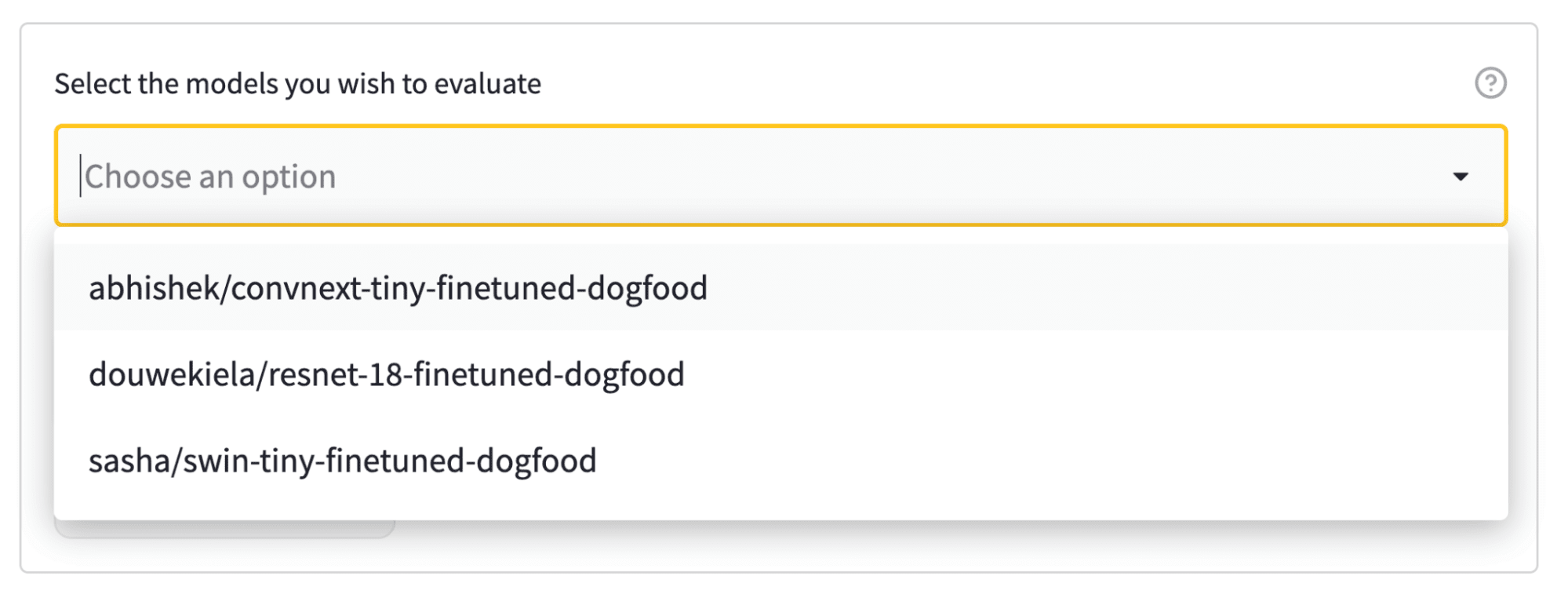
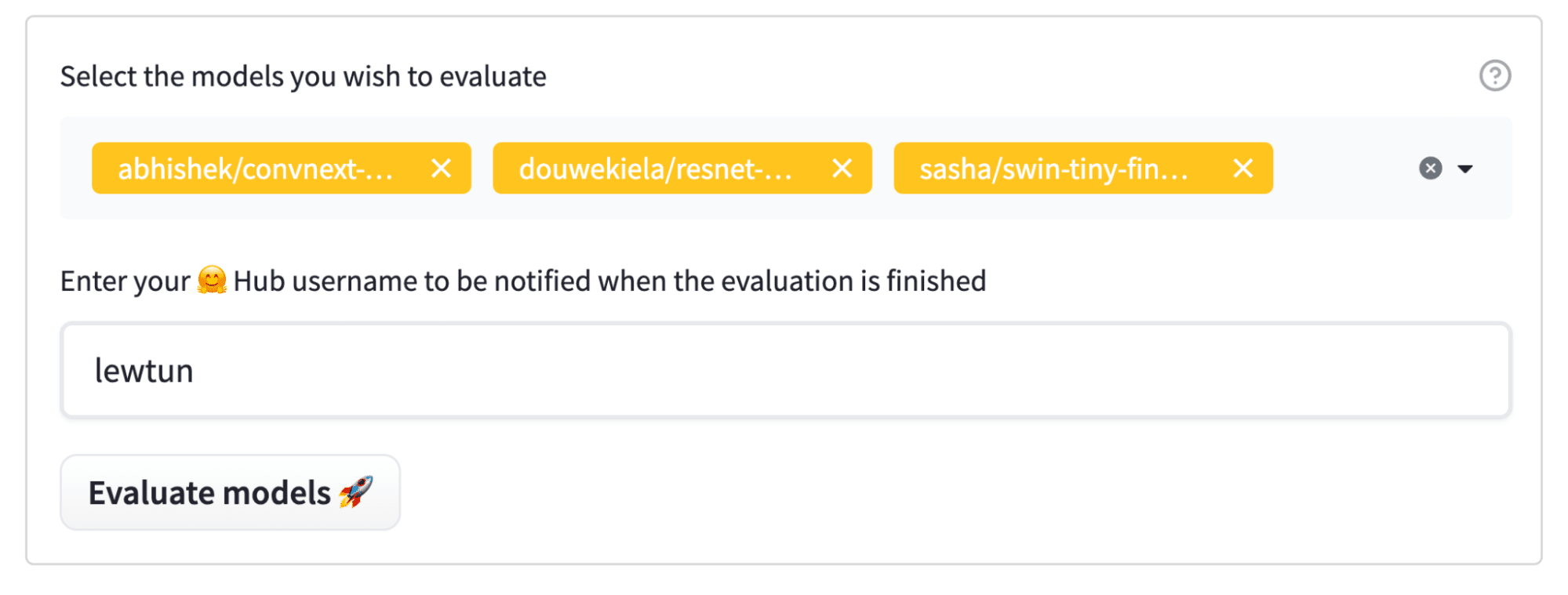
选择模型后,只需输入您的 Hugging Face Hub 用户名(以便在评估完成时收到通知),然后点击大大的“评估模型”按钮
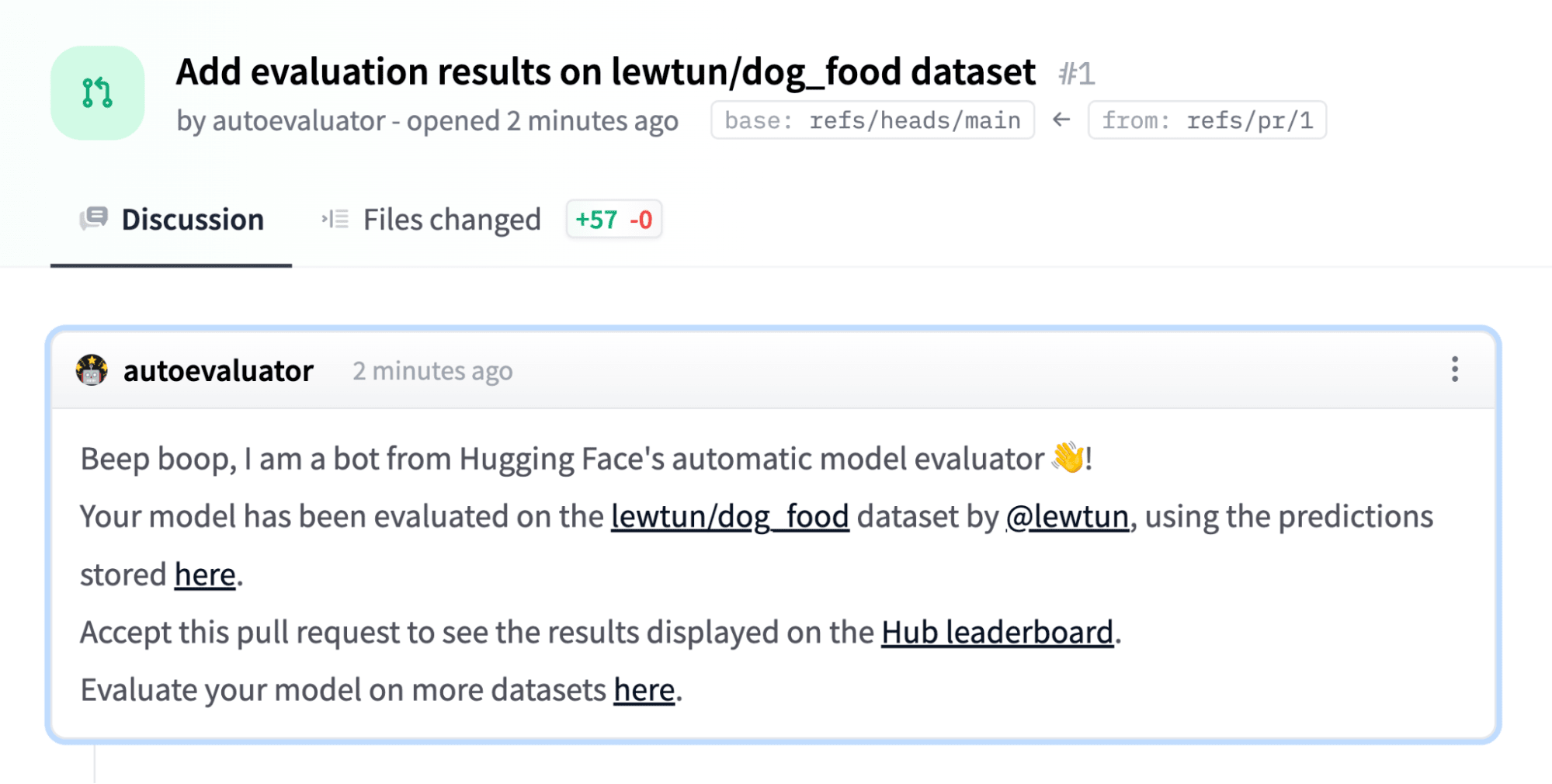
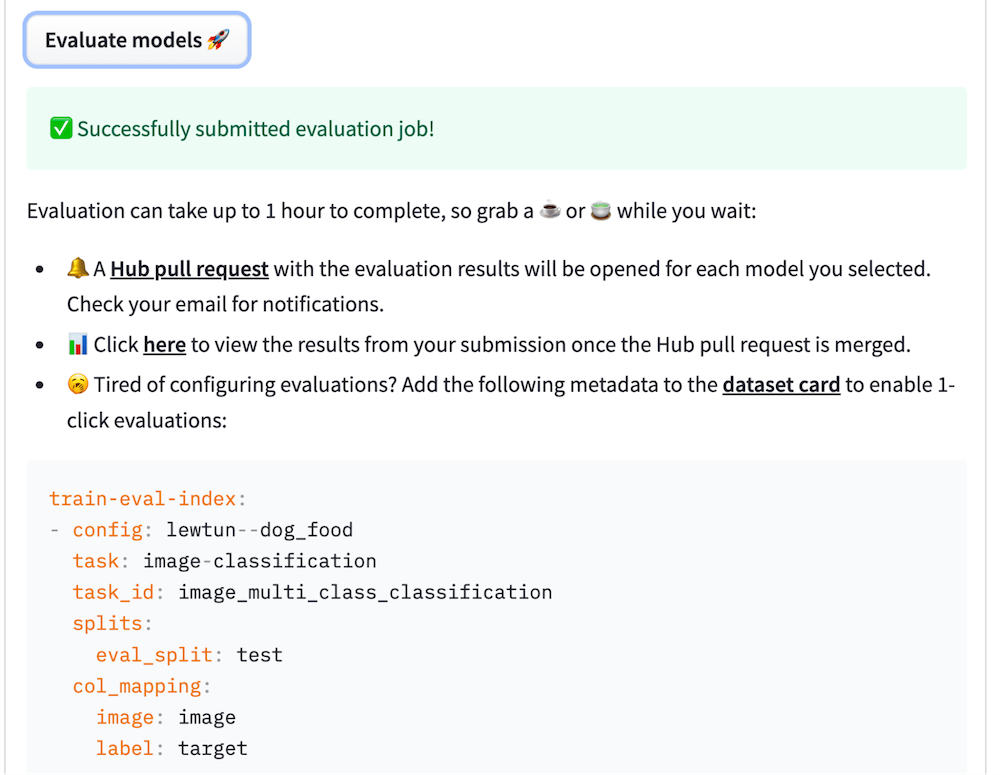
任务提交后,模型将自动评估,并且将打开一个 Hub 拉取请求,其中包含评估结果
您还可以将评估元数据复制粘贴到数据集卡中,以便您和社区下次可以跳过手动配置!
查看排行榜
为了便于模型比较,Hub 上的评估还提供了排行榜,让您可以查看哪些模型在哪个分割和指标上表现最佳
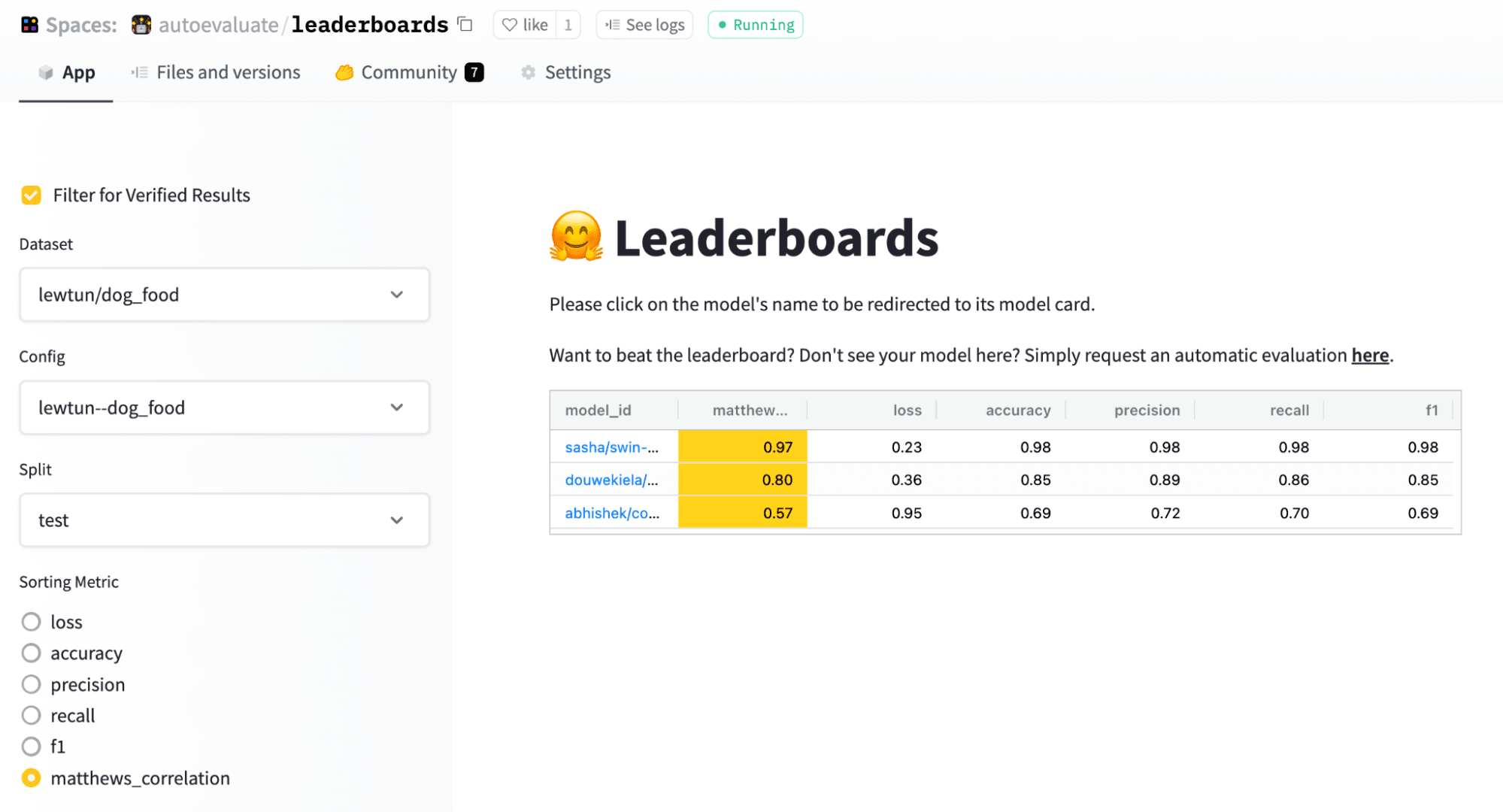
看来 Swin Transformer 脱颖而出!
亲自尝试!
如果您想评估自己选择的模型,请查看以下热门数据集,尝试使用 Hub 上的评估功能:
- 情感 (Emotion) 用于文本分类
- MasakhaNER 用于命名实体识别
- SAMSum 用于文本摘要
更大的图景
自机器学习诞生以来,我们一直通过计算在假定独立同分布的保留测试集上计算某种形式的准确率来评估模型。在现代 AI 的压力下,这种范式现在开始出现严重的裂痕。
基准测试正在趋于饱和,这意味着机器在某些测试集上的表现几乎比我们提出新的测试集更快。然而,众所周知,AI 系统脆弱且容易受到甚至放大严重的恶意偏见。可复现性不足。开放性被事后才考虑。当人们专注于排行榜时,部署模型的实际考虑因素(例如效率和公平性)往往被忽略。数据在模型开发中扮演的巨大作用仍然没有得到足够的重视。更重要的是,预训练和基于提示的上下文学习实践模糊了“分布内”的含义。机器学习正在慢慢追赶这些方面,我们希望通过我们的工作帮助该领域向前发展。
下一步
几周前,我们发布了 Hugging Face Evaluate 库,旨在降低机器学习评估最佳实践的门槛。我们还举办了基准测试,例如 RAFT 和 GEM。Hub 上的评估是我们努力实现未来模型以更全面、多维度、可信赖且可复现的方式进行评估的合乎逻辑的下一步。请继续关注即将发布的更多功能,包括更多任务,以及一个全新改进的数据测量工具!
我们很高兴看到社区将如何利用这一点!如果您想提供帮助,请在尽可能多的数据集上评估尽可能多的模型。一如既往,请通过社区选项卡或论坛给我们提供大量反馈!
