Hugging Face 社区建设是什么?







深入探讨开源 AI 生态系统
关于人工智能发展的叙述通常围绕少数主要参与者及其旗舰大型语言模型展开。但是,这种观点忽略了全球数千个组织、研究人员和开发者所进行的丰富、多样化的创新生态系统。Hugging Face Hub 为这一更广泛的趋势提供了一个独特的窗口——作为最大的人工智能模型、数据集和应用程序存储库,它汇集了来自不同开放程度和不同人工智能开发方法的组织的贡献。
Hub 上托管着超过 180 万个模型、45 万个数据集和 56 万个应用程序,我们对人工智能领域的构建情况拥有前所未有的可见性。与其他专注于特定领域或要求特定许可的平台不同,Hub 涵盖了人工智能开发的方方面面:从完全开放的研究到主要科技公司的成果,从尖端的大型语言模型到针对特定行业的专业时间序列模型。
让我们来探索这些数据揭示的人工智能发展的真实状态、令人惊讶的贡献多样性以及显而易见的研究机会。
探索中心:数据揭示了什么
Hub 收集了每个模型、数据集和应用程序的丰富元数据:下载量、点赞量、用户与组织贡献、创建日期以及派生关系。虽然像历史下载量或最近点赞量这样的单个指标只说明了部分情况,但没有一个单一的衡量标准能够捕捉人工智能开发模式的全部复杂性:一个下载量不大的模型可能会催生数百个衍生模型,或者一个点赞量很少的数据集可能对整个研究领域至关重要。为了理解这种复杂性,我们构建了几个分析工具:模型宇宙探索器映射了组织对模型开发的贡献,数据集宇宙探索器对数据集进行了同样的操作,而组织热力图则可视化了不同贡献者随时间的活动模式。
模型宇宙:一个比你想象中更分散的生态系统
ModelVerse Explorer 揭示了各组织在模型贡献方面引人入胜的模式。尽管头条新闻聚焦于 OpenAI、Google 和 Anthropic,但数据显示了一个更加分散的局面:
小型模型占据下载主导地位:即使组织发布同一模型系列的大型和小型版本,小型版本也始终获得更高的下载量。这表明实际部署考虑通常优先于追求最大能力。
遗留模型依然存在:GPT-2 和 BERT 尽管已有数年历史,但仍位居下载量最高的模型之列,这表明现代聊天界面只是人工智能应用的一小部分。
社区响应迅速:像 DeepSeek 最近发布的模型可以在发布几天内积累数千个点赞和分支,这表明社区迅速采用了有前景的新方法。

DeepSeek-R1 发布后不久就成为 Hugging Face 上最受欢迎的模型。
数据集宇宙:基础层
DataVerse Explorer 讲述了一个关于人工智能发展分散性质的更有趣的故事:
评估数据集占主导地位:所有时间下载量最大的数据集都是评估基准,这反映了社区对严格测试和比较的优先考虑。
开放参与者主导基础数据:虽然封闭公司可能在专有数据上进行训练,但作为大多数人工智能开发基础的数据集来自大学、研究机构和开放组织。
领域特定专业化:除了登上头条的通用数据集之外,还有针对金融、医疗保健、机器人和其他领域的专业数据集组成的蓬勃发展的生态系统。
组织活动:主要贡献者
组织热力图揭示了哪些实体在 Hub 上贡献最频繁:
AI2 遥遥领先:艾伦人工智能研究所成为最活跃的贡献者之一,这表明研究机构的重要性持续存在。
大型科技公司的不同方法:IBM、NVIDIA 和 Apple 等公司展示了主流人工智能讨论中可能不明显的显著活动。微软通过其各种研究部门的存在增加了另一层复杂性。
国际多样性:来自中国、欧洲和其他地区的组织贡献巨大,突显了人工智能的全球性。
人们正在研究什么:隐藏的见解
Hub 不仅仅是一个存储库,它还是一个活生生的人工智能研究实验室。以下是一些超越大型语言模型之外可见的研究方向。
领域特定创新
时间序列模型:亚马逊和 Salesforce 在时间序列预测领域处于领先地位,其中蒙纳什大学、Hugging Face 的 LeRobot 团队和 AutoGluon 项目做出了重要贡献。这代表了数十亿美元的经济价值,而这些价值很少能登上人工智能的头条。
生物学和生命科学:剑桥大学、微软研究院以及众多生物技术初创公司正在默默地构建可能彻底改变药物发现和生物学研究的模型。
机器人技术:开源机器人项目与 NVIDIA 的贡献一起,正在为下一代自主系统奠定基础。
音频和语音:虽然 OpenAI 的 Whisper 备受关注,但下载模式显示,在许多应用程序中,人们更倾向于开源替代方案。
模型演变和衍生品
模型树统计空间使我们能够通过自报告的父模型标签,调查 AI 模型如何通过社区贡献而演变。
- 不同组织从衍生作品中获益不同。
- 一些模型成为创新的平台,而另一些则保持孤立。
- 最成功的模型,例如 Qwen、Llama 和 Gemma 模型,催生了整个专业变体生态系统。
有关从单个模型派生的多代模型的更全面分析,请查看基础模型探索器空间。
研究机会
数据表明有几个尚未充分探索的研究方向:
跨领域迁移学习:随着模型涵盖数十个领域,有机会研究不同领域之间能力的迁移方式。
协作开发模式:衍生模型网络揭示了分布式团队如何实际协作进行人工智能开发。
模型长期可行性:通过跟踪下载量和使用量随时间的变化,我们可以了解哪些模型架构具有持久性。
深入探索的资源
交互空间
- 累计 Hub 统计数据:追踪随时间变化的增长趋势!
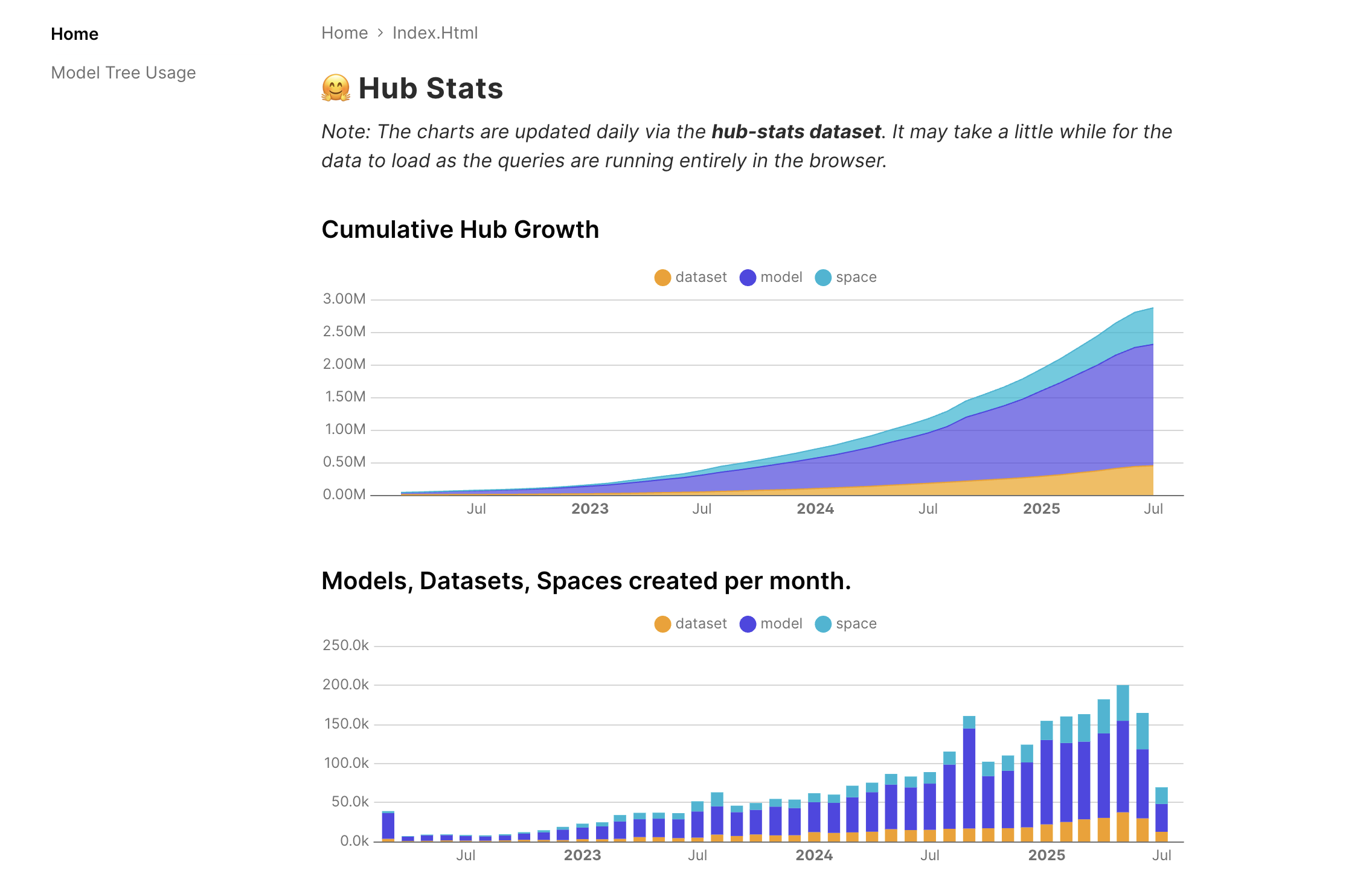
截至 2025 年 7 月 14 日的累计 Hub 统计数据空间
- 语义搜索:使用自由文本搜索按功能探索模型和数据集!
- 模型图谱:通过交互式图形可视化探索模型及其关系。
研究数据集
供研究人员深入挖掘
- Hub 统计数据:完整的统计数据集,请访问 https://huggingface.co/datasets/cfahlgren1/hub-stats
- 每周快照:用于趋势分析的纵向数据,请访问 https://huggingface.co/datasets/hfmlsoc/hub_weekly_snapshots
- 带元数据的模型卡:结构化模型文档,请访问 https://huggingface.co/datasets/librarian-bots/model_cards_with_metadata
- 带元数据的数据集卡:全面的数据集文档,请访问 https://huggingface.co/datasets/librarian-bots/dataset_cards_with_metadata
学术研究
一些学术论文已经开始使用 Hub 数据来了解人工智能的发展:
- “开放模型的短暂而奇妙的生命”
- “构建未来的 AI 社区?Hugging Face Hub 上开发活动的定量分析”
- “32,111 个人工智能模型卡的系统分析揭示了人工智能中的文档实践”
- “驾驭人工智能中的数据集文档:Hugging Face 上数据集卡的大规模分析”
- “机器学习模型如何变化?”
- “开放生态系统中的负责任人工智能:协调创新与风险评估和披露”
- “我们应该绘制全球所有模型的图谱”
展望未来:这对人工智能意味着什么
数据显示,人工智能发展远比流行的说法更分散、多样和协作。虽然人们的注意力集中在尖端模型和价值数十亿美元的公司上,但真正的创新通常发生在专业领域,通过社区协作,以及通过现有模型的迭代改进。
对于研究人员来说,这提供了一个机会,可以研究人工智能实际发生的发展情况——而不仅仅是新闻稿中描述的样子。对于开发者来说,这强调了除了最新模型发布之外,寻找真正解决实际问题的工具的重要性。对于政策制定者来说,这表明要了解人工智能的影响,需要审视整个生态系统,而不仅仅是最引人注目的参与者。
Hub 继续作为研究平台发展,新工具和数据集不断添加。无论您是研究创新模式、分析模型能力,还是探索人工智能发展的社会动态,数据都在这里等待探索。
您会发现什么?我们很乐意听到使用 Hub 数据的激动人心的项目!探索上面提到的空间和数据集,开始您自己的分析,并发布论文或博客,或者在社交媒体上标记我们,分享您的发现!





